






关于Linux中的网卡名字
不知道大家注意没有,Linux的网卡名字有很多种,这都是网卡驱动定义的。
RHEL7利用 systemd 的可预测网络接口命名方案来分配网络接口名称。
在引导时,内核始终为接口分配 ethX 式的名称,按照设备在这次引导事件中检测到的顺序来分配编号。由于内核不能确保每次都能以相同的顺序发现驱动程序或接口,因此需要实施额外的 OS 功能才能以可预测的方式重命名接口,让每个接口在以后引导时被分配相同的名称。在 RHEL 7 中,这一功能由 systemd 的可预测网络接口功能来提供。可预测设备命名利用 udev 规则按照如下顺序选择设备名称:
-
板载设备使用固件提供的索引编号(例如:eno1)
-
附加的设备使用固件提供的 PCIe 插槽编号(例如:ens1)===>RHEL7默认用这种
-
设备利用物理连接器位置命名(例如:enp2s0)
-
设备名称中融入接口的 MAC 地址(例如:enx78e7d1ea46da)
-
最后,典型的不可预测内核原生命名(例如:eth0)
传统Linux网络驱动的问题
-
中断开销突出,大量数据到来会触发频繁的中断(softirq)开销导致系统无法承受
-
需要把包从内核缓冲区拷贝到用户缓冲区,带来系统调用和数据包复制的开销
-
对于很多网络功能节点来说,TCP/IP协议并非是数据转发环节所必需的
-
NAPI/Netmap等虽然减少了内核到用户空间的数据拷贝,但操作系统调度带来的cache替换也会对性能产生负面影响
注:
NAPI 是 Linux 上采用的一种提高网络处理效率的技术,它的核心概念就是不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收的服务程序,然后 POLL 的方法来轮询数据(https://sites.google.com/site/emmoblin/smp-yan-jiu/napi)
DPDK VS RDMA
DPDK(Kerrnel Bypass,放弃CPU中断,协议上移)与RDMA(绕过Linux Kernel直接内存拷贝、负载下沉)的对比
DPDK
DPDK网络层:
从:硬件中断->到:放弃中断流程;
用户层通过设备映射取包->进入用户层协议栈->逻辑层->业务层;
上图的PMD是Poll Mode Driver的缩写,即基于用户态的轮询机制的驱动。PMO is an open-source upstream driver embedded within dpdk.org releases that’s designed for fast packet processing and low latency. It achieves this by providing a kernel bypass for send and receive queues and by avoiding the performance overhead of interrupt processing.
DPDK核心技术:
1)将协议栈上移到用户态,利用UIO技术直接将设备数据映射拷贝到用户态(PMD)
2)利用大页技术,降低TLB cache miss,提高TLB访问命中率
3)通过CPU亲和性,绑定网卡和线程到固定的core,减少cpu任务切换
4)通过无锁队列,减少资源的竞争
优势:
1)减少中断次数;
2)减少内存拷贝次数
3)绕过linux的协议栈,用户获得协议栈的控制权,能够定制化协议栈以降低复杂度;
劣势:
1)内核栈转移至用户层增加了开发成本
2)低负荷服务器不实用,会造成cpu空转
RDMA
网卡硬件收发包并进行协议栈封装/解析,然后将数据存放到指定内存地址,而不需要CPU干预。
核心技术:
协议栈硬件offload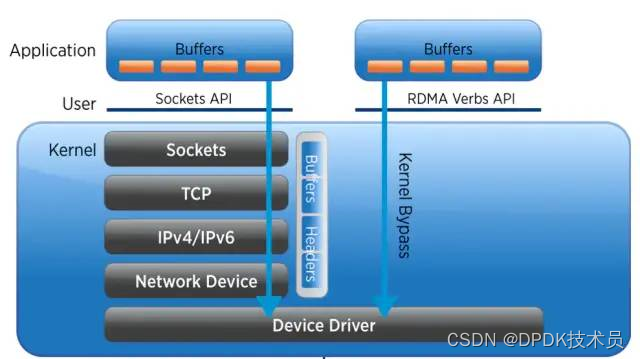
优势:
1)协议栈offload,解放cpu
2)减少了中断和内存拷贝,降低时延
3)高带宽
劣势:
1)特定网卡才支持,成本开销相对较大;
2)RDMA提供了完全不同于传统网络编程的API,一般需要对现有APP进行改造,引入额外开发成本
总结
相同点:
1)两者均为kernel bypass技术,可以减少中断次数,消除内核态到用户态的内存拷贝;
相异点:
1)DPDK是将协议栈上移到用户态,而RDMA是将协议栈下沉到网卡硬件,DPDK仍然会消耗CPU资源;
2)DPDK的并发度取决于CPU核数,而RDMA的收包速率完全取决于网卡的硬件转发能力
3)DPDK在低负荷场景下会造成CPU的无谓空转,RDMA不存在此问题
4)DPDK用户可获得协议栈的控制权,可自主定制协议栈;RDMA则无法定制协议栈
DPDK的优势实现原理:
-
PMD用户态驱动:DPDK针对Intel网卡实现了基于轮询方式的PMD(Poll Mode Drivers)驱动,该驱动由API、用户空间运行的驱动程序构成,该驱动使用 无中断方式直接操作网卡的接收和发送队列(除了链路状态通知仍必须采用中断方式以外)。目前PMD驱动支持Intel的大部分1G、10G和40G的网卡。PMD驱动从网卡上接收到数据包后,会直接通过DMA方式传输到预分配的内存中,同时更新无锁环形队列中的数据包指针,不断轮询的应用程序很快就能感知收到数据包,并在预分配的内存地址上直接处理数据包,这个过程非常简洁。如果要是让Linux来处理收包过程,首先网卡通过中断方式通知协议栈对数据包进行处理,协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否本机的socket,满足条件则会将数据包拷贝一份向上递交给用户socket来处理,不仅处理路径冗长,还需要从内核到应用层的一次拷贝过程。 -
hugetlbfs: 这样有两个好处:第一是使用hugepage的内存所需的页表项比较少,对于需要大量内存的进程来说节省了很多开销,像oracle之类的大型数据库优化都使用了大页面配置;第二是TLB冲突概率降低,TLB是cpu中单独的一块高速cache,采用hugepage可以大大降低TLB miss的开销。DPDK目前支持了2M和1G两种方式的hugepage。通过修改默认/etc/grub.conf中hugepage配置为“default_hugepagesz=1G hugepagesz=1G hugepages=32 isolcpus=0-22”,然后通过mount –t hugetlbfs nodev /mnt/huge就将hugepage文件系统hugetlbfs挂在/mnt/huge目录下,然后用户进程就可以使用mmap映射hugepage目标文件来使用大页面了。测试表明应用使用大页表比使用4K的页表性能提高10%~15%。 -
CPU亲缘性和独占: 多核则是每个CPU核一个线程,核心之间访问数据无需上锁。为了最大限度减少线程调度的资源消耗,需要将Linux绑定在特定的核上,释放其余核心来专供应用程序使用。同时还需要考虑CPU特性和系统是否支持NUMA架构,如果支持的话,不同插槽上CPU的进程要避免访问远端内存,尽量访问本端内存。-
避免不同核之间的频繁切换,从而避免
cache miss和cache write back -
避免同一个核内多任务切换开销
-
-
降低内存访问开销:
-
借助大页降低
TLB miss -
利用内存多通道交错访问提高内存访问的有效带宽
-
利用内存非对称性感知避免额外的访存延迟
-
少用数组和指针,多用局部变量
-
少用全局变量
-
一次多访问一些数据
-
自己管理内存分配;进程间传递指针而非整个数据块
-
-
Cache有效性得益于空间局部性(附近的数据也会被用到)和时间局部性(今后一段时间内会被多次访问)原理,通过合理的使用cache,能够使得应用程序性能得到大幅提升 -
避免
False Sharing: 多核CPU中每个核都拥有自己的L1/L2 cache,当运行多线程程序时,尽管算法上不需要共享变量,但实际执行中两个线程访问同一cache line的数据时就会引起冲突,每个线程在读取自己的数据时也会把别人的cache line读进来,这时一个核修改改变量,CPU的cache一致性算法会迫使另一个核的cache中包含该变量所在的cache line无效,这就产生了false sharing(伪共享)问题.Falsing sharing会导致大量的cache冲突,应该尽量避免。访问全局变量和动态分配内存是false sharing问题产生的根源,当然访问在内存中相邻的但完全不同的全局变量也可能会导致false sharing,多使用线程本地变量是解决false sharing的根源办法。 -
内存对齐:根据不同存储硬件的配置来优化程序,性能也能够得到极大的提升。在硬件层次,确保对象位于不同
channel和rank的起始地址,这样能保证对象并并行加载。字节对齐:众所周知,内存最小的存储单元为字节,在32位CPU中,寄存器也是32位的,为了保证访问更加高效,在32位系统中变量存储的起始地址默认是4的倍数(64位系统则是8的倍数),定义一个32位变量时,只需要一次内存访问即可将变量加载到寄存器中,这些工作都是编译器完成的,不需人工干预,当然我们可以使用attribute((aligned(n)))来改变对齐的默认值。 -
cache对齐,这也是程序开发中需要关注的。Cache line是CPU从内存加载数据的最小单位,一般L1 cache的cache line大小为64字节。如果CPU访问的变量不在cache中,就需要先从内存调入到cache,调度的最小单位就是cache line。因此,内存访问如果没有按照cache line边界对齐,就会多读写一次内存和cache了。 -
NUMA:NUMA系统节点一般是由一组CPU和本地内存组成。NUMA调度器负责将进程在同一节点的CPU间调度,除非负载太高,才迁移到其它节点,但这会导致数据访问延时增大。 -
减少进程上下文切换: 需要了解哪些场景会触发
CS操作。首先就介绍的就是不可控的场景:进程时间片到期;更高优先级进程抢占CPU。其次是可控场景:休眠当前进程(pthread_cond_wait);唤醒其它进程(pthread_cond_signal);加锁函数、互斥量、信号量、select、sleep等非常多函数都是可控的。对于可控场景是在应用编程需要考虑的问题,只要程序逻辑设计合理就能较少CS的次数。对于不可控场景,首先想到的是适当减少活跃进程或线程数量,因此保证活跃进程数目不超过CPU个数是一个明智的选择;然后有些场景下,我们并不知道有多少个活跃线程的时候怎么来保证上下文切换次数最少呢?这是我们就需要使用线程池模型:让每个线程工作前都持有带计数器的信号量,在信号量达到最大值之前,每个线程被唤醒时仅进行一次上下文切换,当信号量达到最大值时,其它线程都不会再竞争资源了。 -
分组预测机制,如果预测的一个分支指令加入流水线,之后却发现它是错误的分支,处理器要回退该错误预测执行的工作,再用正确的指令填充流水线。这样一个错误的预测会严重浪费时钟周期,导致程序性能下降。《计算机体系结构:量化研究方法》指出分支指令产生的性能影响为10%~30%,流水线越长,性能影响越大。
Core i7和Xen等较新的处理器当分支预测失效时无需刷新全部流水,当错误指令加载和计算仍会导致一部分开销。分支预测中最核心的是分支目标缓冲区(Branch Target Buffer,简称BTB),每条分支指令执行后,都会BTB都会记录指令的地址及它的跳转信息。BTB一般比较小,并且采用Hash表的方式存入,在CPU取值时,直接将PC指针和BTB中记录对比来查找,如果找到了,就直接使用预测的跳转地址,如果没有记录,必须通过cache或内存取下一条指令。 -
利用流水线并发: 像
Pentium处理器就有U/V两条流水,并且可以独自独立读写缓存,循环2可以将两条指令安排在不同流水线上执行,性能得到极大提升。另外两条流水线是非对称的,简单指令(mpv,add,push,inc,cmp,lea等)可以在两条流水上并行执行、位操作和跳转操作并发的前提是在特定流水线上工作、而某些复杂指令却只能独占CPU。 -
为了利用空间局部性,同时也为了覆盖数据从内存传输到CPU的延迟,可以在数据被用到之前就将其调入缓存,这一技术称为预取
Prefetch,加载整个cache即是一种预取。CPU在进行计算过程中可以并行的对数据进行预取操作,因此预取使得数据/指令加载与CPU执行指令可以并行进行。 -
充分挖掘网卡的潜能:借助现代网卡支持的分流(
RSS,FDIR)和卸载(TSO,chksum)等特性。
OVS-DPDK
通信服务提供商 (CSP) 和电信公司使⽤的业务关键型应⽤要求服务中断降⾄最低程度。如果达不到 与特制硬件解决⽅案⽔平相当的超⾼吞吐量,则这种业务模型会崩溃⽡解。要为这些提供商部署⽹ 络功能虚拟化,需要达到与特制硬件解决⽅案相当的超⾼⽹络吞吐量。Intel 开发的 OVS-DPDK(数据平⾯开发套件)是⼀个库集合,允许⽤⼾空间应⽤轮询物理 NIC 以 接收或发送数据,从⽽减少虚拟化开销。利⽤环境抽象层 (EAL) 软件架构,DPDK 提供⼀个通⽤ 接⼝,供⽤⼾空间应⽤与不同的物理 NIC 交互。OVS-DPDK 使⽤ Linux ⼤⻚来分配⼤型内存区域,然后允许⽤⼾空间应⽤直接从这些内存⻚⾯访问 数据。轮询模式驱动程序 (PMD) 允许应⽤直接访问物理 NIC,⽽不涉及内核空间处理。
OVS-DPDK ⾼级架构
OVS-DPDK ⾼级架构由下列模块和库组成:

-
ovs-vswitchd
ovs-vswitchd 守护进程在⽤⼾空间内运⾏,并从 ovsdb-server 数据库服务器读取 OVS 配 置。OVS 的其他组件从 OVS 数据库服务器接收配置设置。
-
ofproto
ofproto OVS 库实施 OpenFlow 交换机。该库利⽤ OpenFlow 控制器配置由⽤⼾创建的 OpenFlow 规则。oproto 提供程序⽤于管理这些转发平⾯规则,以及要对数据包采取的操 作。oproto 的提供程序是 dpif-netlink 和 dpif-netdev。
-
netdev
netdev OVS 库提供⼀个抽象层,⽤于与物理 NIC 进⾏交互。OVS 上的每个端⼝都有对应的 netdev 提供程序与之关联,连接到⼀个在虚拟机内部使⽤的硬件或虚拟 NIC。netdev 提供 程序实施⼀个⽤于与⽹络设备交互的接⼝。netdev 的这两个提供程序是 netdev-linux 和 netdev-dpdk。
使⽤ OVS-DPDK 时,netdev 模块的 netdev-dpdk 库提供对 DPDK ⽀持的物理 NIC 的访问。三 个软件组件提供三个接⼝:librte_eth、librte_ring 和 librte_vhost。librte_eth 库使⽤ DPDK 轮询模式驱动程序 (PMD) 与物理 NIC 交互。librte_vhost 库通过虚拟机的 virtio 接⼝与 vhost 端⼝通信。librte_ring 库实施环形结构,⽤于维护指向数据包缓冲区的指针。使⽤原⽣ OVS 和 OVS-DPDK 之间的⼀个关键区别在于使⽤轮询模式驱动程序 (PMD)。PMD 使⽤ 轮询⽅法来持续扫描物理 NIC,以了解数据包是否已经到达。
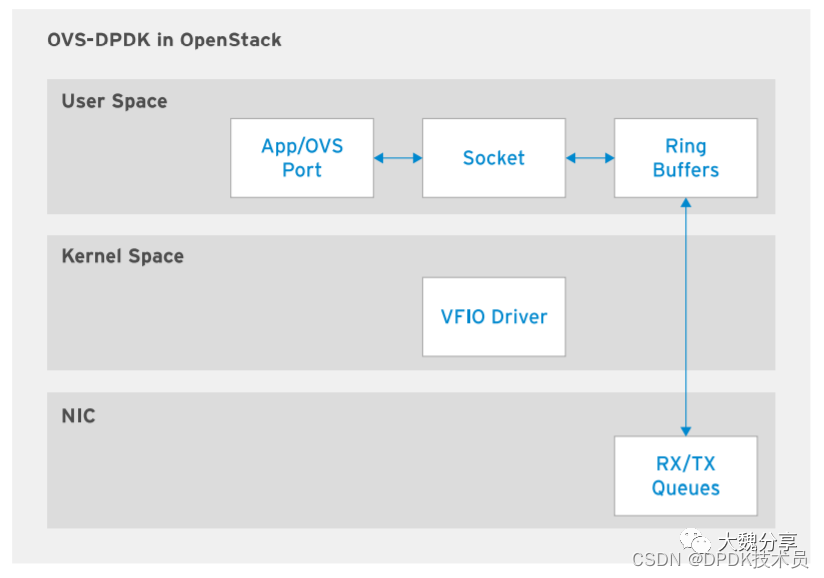
-
物理 NIC 收到数据包后,将其发送到环形缓冲区,后者充当⽤⼾空间内的接收队列。环形缓冲 区维护⼀个含有指向数据包缓冲区的指针的表。⽤⼾空间应⽤访问 DPDK 内存池区域中的数据 包缓冲区。这些内存池是利⽤计算主机提供的⼤⻚创建的。
2. 当数据包不可⽤时,⽤⼾空间应⽤利⽤ PMD 轮询物理 NIC。然后,⽤⼾空间应⽤访问 环形缓冲 区来获取收到的数据包。
使⽤Red Hat OpenStack Platform配置 OVS-DPDK
配置有Red Hat OpenStack Platform计算节点的 OVS-DPDK 通过增加实例或 VNF 之间的⽹络吞吐 量,帮助提升计算节点上运⾏的 OVS 的性能。VNF 内运⾏的应⽤不⼀定需要启⽤ DPDK。管理员 可以在 VNF 内使⽤启⽤ DPDK 的应⽤来引⼊另⼀层优化。此外,不在计算节点上使⽤ OVS 或 OVSDPDK 也可以运⾏启⽤ DPDK 的 VNF。启⽤ DPDK 的 VNF 要求在计算主机上实施 SR-IOV,以利⽤ VF 来访问物理 NIC。这种配置要求使⽤在 VNF 内运⾏的 VF 轮询模式驱动程序 (PMD)。
Red Hat OpenStack Platform中使⽤ TripleO heat 模板在计算节点上部署 OVS-DPDK。根据计 算节点的内存、CPU 和 NUMA 节点,通过⽹络环境 YAML ⽂件传递参数,以配置 OVS-DPDK 来获 得最佳的性能。通过默认参数来使⽤ OVS-DPDK 适合基本部署,但为了发挥多个 NUMA 节点的优 势,通常会需要(实际上也要求)进⾏计算主机调优。
OVS-DPDK CPU 参数
使⽤ OVS-DPDK 时,应当在多个 NUMA 节点之间固定相关的组件,以实现资源利⽤率的最⼤化。通过 OVS-DPDK,主机 CPU 在主机进程、虚拟机之间并为运⾏的 OVS-DPDK PMD 线程进⾏分 区。PMD 需要主机 CPU 提供专⻔的核⼼来运⾏轮询,以便从物理⽹卡接收数据包。如果 PMD 线程 需要扩展,可以添加额外的核⼼,即使流量已在流动。
OVS-DPDK 使⽤Red Hat OpenStack Platform heat 模板中的下列 CPU 分区参数:
-
NeutronDpdkCoreList
-
设置专门供各个 NUMA 节点上的 OVS-DPDK PMD 使用的 CPU 核心。管理员应避免分配所有 NUMA 节点的前几个物理 CPU 核心,因为主机进程会用到它们。必须使用
/etc/nova/nova.conf文件中的vcpu_pin_set参数,将分配给 PMD 线程的 CPU 核心从计算服务调度中排除。例如,假设一台计算机有两个 NUMA 节点,每个 NUMA 节点的 CPU 总数为 18。网络环境 YAML 中的NeutronDpdkCoreList参数应当具有来自 NUMA0 的核心 4,6 和来自 NUMA1 的核心 5,7:此参数设置 OVS-DPDK 的
pmd-cpu-mask选项。该参数将以下约束用于提供给此参数的值:

OVS-DPDK 内存参数
OVS-DPDK 使用内存池来存储数据包缓冲区。它由用户空间应用访问。这些内存池区域使用在所有 NUMA 节点之间分配的大页。因此,务必要向所有将会关联 DPDK 接口的 NUMA 节点分配大页内存。
OVS-DPDK 使用Red Hat OpenStack Platform tripleo heat 模板中的下列内存参数:
以下屏幕显示了 OVS-DPDK 部署的示例网络环境文件,该部署中使用了一个计算主机和两个 NUMA 节点:
-
NeutronDpdkSocketMemory
-
设置要分配给各个 NUMA 节点的内存池的内存量,单位为 MB。该值取决于多个不同因素,如每个 NUMA 节点的 DPDK 物理 NIC 数,以及 MTU 等。该属性是每个 NUMA 节点的逗号分隔值。第一个 NUMA 节点的默认值为
1024 MB。此参数设置 OVS-DPDK 的
dpdk-socket-mem选项。
OVS-DPDK 内核参数
计算节点上需要多个包含内核参数的配置:
-
ComputeKernelArgs
-
大页配置:要分配的大页数。
-

IOMMU配置:当物理 NIC 首先收到数据包时,会将它发送给 OVS-DPDK 端口的接收队列。从那里通过直接内存访问 (DMA) 机制将数据包复制到主内存。需要使用一个输入输出内存管理单元 (IOMMU)从用户空间安全地驱动支持 DMA 的硬件。将内核参数设置为intel_iommu=on(Intel 系统)或amd_iommu=on(AMD 系统)。此外,还建议使用iommu=pt选项来提高这些设备的输入输出性能。
OVS-DPDK 其他参数
配置 OVS-DPDK 时需要的其他参数包括:
-
NeutronDpdkDriverType
-
设置由 DPDK 网络接口卡使用的驱动程序类型。在安装过程中,红帽 OpenStack director 将
vfio-pci驱动程序分配给主机上的 OVS-DPDK 端口。 -
NeutronDpdkType
-
设置 OVS 数据路径类型。默认值为
netdev,表示使用用户空间数据路径。 -
NeutronVhostuserSocketDir
-
设置 vhost-user 套接字目录。
-

接下来,我们验证在OpenStack一个计算节点上启用DPDK的环境。
我们看到是一个Numa node,4个CPU。
-
查看大内存:
-



查看pmd状态:

查看vm状态:
参考文档:
https://www.jianshu.com/p/09b4b756b833
https://tonydeng.github.io/sdn-handbook/dpdk/ovs-dpdk.html
原文链接:https://mp.weixin.qq.com/s/_nKt9KiPL45oG4vid6HDrQ














 3713
3713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









