






01
背景
-
高能物理中的计算模型
全球分布,基于网格
-
高能物理的挑战
在分散在世界各地的设施和计算中心之间可靠且高效地传输物理数据集——现在在数PB(10^15字节)范围内,预计在十年内增长到10亿字节。
-
技术趋势
-
网络中的原始传输速度正在迅速增加,微处理技术的进步速度已经在放缓。
-
与网络中数据包传输所花费的时间相比,网络协议处理开销急剧增加。
02
问题
-
网络应用程序的瓶颈是什么?在哪?怎么样?
-
网络?
-
还是网络终端系统?
03
Linux网络数据包的接收过程
-
Linux网络子系统:数据包接收过程

-
阶段1:NIC&设备驱动
网络数据包从网络接口卡传输到ring buffer
-
阶段2:内核协议栈
网络数据包从ring buffer传输到socket接收buffer
-
阶段3:数据结构过程
数据包从socket接收buffer拷贝到应用程序
-
NIC&设备驱动过程

-
NIC&设备驱动过程如下:
1. 数据包通过DMA从NIC传输到ring buffer
2. NIC发起硬件中断
3. 硬件中断句柄通过安排数据包接收软中断
4. 软中断检查其对应 CPU 的 NIC 设备 poll-queue
5. 软中断轮询对应网卡的环形缓冲区
6. 把在接收环形缓冲区的数据包删除,然后送给高层处理;环形缓冲区中的响应槽被重新初始化并重新填充。
-
OSI 7层模型的第1层和2层的功能
接收环形缓冲区的数据包描述符,当没有数据包描述符在初始状态时,后续到来的数据包将会被丢弃。
-
内核协议栈—IP
-
IP处理过程:
-
IP包进行完整性验证
-
路由
-
分片整合将数据包送到更高层协议栈处理
-
内核协议栈—TCP1
-
TCP过程:
-
TCP进程上下文
-
中断上下文:软中断初始化
-
进程上下文:数据接收过程初始化
更高效,更少的上下文对象转换
-
TCP功能:
-
流控制,拥塞避免,应答机制,重传机制
-
TCP队列:
1. 预处理队列:尝试在进程上下文中处理数据包,而不是中断竞争
2. 备份队列:在socket锁定时使用
3. 接收队列:整序,已经ack的数据包,无黑洞数据,准备传输的数据
4. 乱序队列
-
内核协议栈—TCP2


除了预处理队列溢出外,预处理队列和备份队列都是在进程上下文中处理的。
-
内核协议栈—UDP
-
UDP进程
-
比TCP简单多了
-
UDP数据包完整性验证
-
超过socket接收队列,后续的数据全部丢弃
-
数据接收过程
-
通过struct iovec将数据包从socket的接收缓冲区复制到用户空间
-
与socket相关的系统调用
-
对于TCP流,数据接收进程也可能在进程上下文中启动TCP处理
学习更多资料及视频
DPDK 学习资料、教学视频和学习路线图 :https://space.bilibili.com/1600631218
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 上课地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 群909332607备注(XMG) 获取
04
性能分析
符号说明

数据模型如下:

1、令牌算法对网卡和设备驱动程序接收过程进行建模
2、排队过程对接收过程的第2和第3阶段进行建模
-
令牌桶算法-阶段1
接收环形缓冲区表示为深度为Dtoken的令牌桶。处于就绪状态的每个数据包描述符都是一个令牌桶,授予接收一个传入数据包的能力。仅当重新初始化和重新跳虫使用的数据包描述符时,才会重新生成令牌。如果桶中没有令牌,传入的数据包将被丢弃k个。
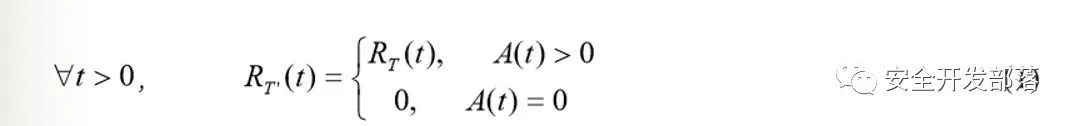
为了允许数据包进入系统而不丢弃,它应该具有:

NIC和设备驱动可能是个潜在的瓶颈!
为了减少成为瓶颈的风险,应该采取什么措施?
1、提高协议包服务率
2、增大系统内存大小
3、增大NIC的ring buffer大小D
D是NIC和驱动程序的设计参数
对NAPI驱动程序,D应满足以下条件以避免不必要的丢包

排队过程—阶段2和阶段3
对于stream i;它满足如下不等式:

通过以上不等式可以推导出:

对于UDP,当接收buffer已满,后续的UDP包将会被丢弃;
对于TCP,当接收buffer就快要满时,流量控制会限制发送方的发送速率;
对于网络应用程序,最好要提高(7)

一个满的接收buffer可能是另一个潜在的瓶颈!
可以采取的措施?
1、提高socket接收buffer的大小QB(i)
可配置,受系统内存限制
2、提高Rdt(t)
受系统负债和数据接收过程的nice值影响
提供数据接收进程的CPU份额:①增大nice值 ②降低系统负债

实验过程和结果
1、通过运行 iperf 在两个计算机系统之间单向发送数据;
2、我们在 Linux 数据包接收路径中添加了工具
3、通过运行make-nj编译Linux内核作为后台系统负载
4、接收buffer大小设置20M


注:发送和接收者特征
-
实验1:接收ring buffer

网卡接收环形缓冲区中的数据包描述符总数为384
接收ring buffer可能会耗尽它的包描述符:性能瓶颈!
-
实验2:各种 TCP 接收缓冲区队列

后台负载0

后台负载10
-
实验3:UDP接收buffer队列
以下在下面3种情况下做实验:
(1) 发送速率:200Mb/s,接收者负载为0;
(2) 发送速率:200Mb/s,接收者负载为10;
(3) 发送速率:400Mb/s,接收者负载为0。
传输时长25s;接收缓冲区大小为20MB。

UDP接收buffer队列

UDP接收buffer提交内存
情况(1)和情况(2)都在接收方的处理范围内,接收缓冲区一般为空,情况(3)的有效数据速率为88.1Mbits,丢包率为670612/862066 (78%)
-
实验4:数据接收过程

发送方向接收方发送一个TCP流,传输时间为25s。在接收端,数据接收过程的nice值和后台负载都是变化的。实验中使用的nice值是:0,-10,-15.
05
结论
1、NIC和设备驱动程序中的接收环形缓冲区可能成为数据包接收的瓶颈;
2、数据接收进程的CPU份额是数据包接收的另一个限制因素。















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









