








大数据时代,
数据收集不仅是科学研究的基石,
更是企业决策的关键。
然而,如何高效地收集数据
成了摆在我们面前的一项重要任务。
本文将为你揭示,
一系列实时数据采集方法,
助你在信息洪流中,
找到真正有价值的信息。

01 数据采集
数据采集是数据可视化分析的第一步,也是最基础的一步,数据采集的数量和质量越高,后面分析的准确的也就越高,我们来看一下淘宝网的数据该如何爬取。
淘宝网站是一个动态加载的网站,我们之前可以采用解析接口或者用Selenium自动化测试工具来爬取数据,但是现在淘宝对接口进行了加密,使我们很难分析出来其中的规律,同时淘宝也对Selenium进行了反爬限制,所以我们要换种思路来进行数据获取。
打开开发者模式,开始对网页进行观察后发现,淘宝商品的数据竟然在源网页中存储着。
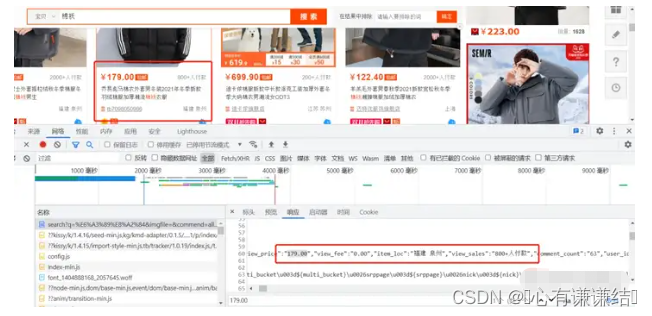
我翻了几页网页之后发现,每翻一页,网页的params参数中的s参数就会增加44(初
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









