







目录
前言
本文主要介绍 Posix API 与 网络协议栈 之间的关系;三次握手、数据传输、四次挥手的过程。
Posix API的意思就是可移植性操作系统接口,也就是linux下的可移植到别的系统的API接口。
无论是现在的哪种高级语言,涉及到的网络编程底层都会追溯到linux下的网络编程原理。
posix api 准备工作
这里介绍常用的网络编程posix api。如果对网络编程没有任何概念的可以先看我前面的一篇socket编程 服务器
socket
socket就是插座的意思大致看我之前的文章,使用socket之后会创建出1个文件描述符和两个缓冲区,任何我们能对 socket 进行操作的地方都是对这个文件描述符fd 进行操作。每个fd连接背后都有一个TCB(tcp控制块,tcp control block)。TCB是tcp协议栈里面的。一个fd对应一个TCB,经常用到的读缓冲区和写缓冲区就是在这个TCB里面。我们操作fd,调用send,其实就是将数据放到TCB里面。调用recv,就是从TCB里拷贝出来。
一般数据都是先到协议栈,到了协议栈之后再转到物理网卡再通过网卡传输,再转到连接端的协议栈,然后连接端再操作这个协议栈。
bind
刚开始创建socket的时候,其底层的TCB是没有被初始化的,没有任何数据,TCB里面的状态机的状态也是close的,发送不了数据,也接收不了数据。
这里需要介绍一下新的概念:五元组,五元组确定了一个TCB,那也就是确定了唯一的一个fd,因为一个fd对应一个TCB。有了五元组就知道是谁连接过来的,通过哪个端口连接进来的。
< 源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 >
bind的作用就是绑定本地的ip和端口,还有协议。也就是将TCB的五元组填充 <目的IP地址,目的端口,协议> ,注意客户端可以不使用bind函数,但其会默认分配。
三次握手建立连接
我们知道TCP是要通过三次握手进行确立连接的,那么我们来了解下是从哪个函数开始的,发生在哪个时间段。
connect
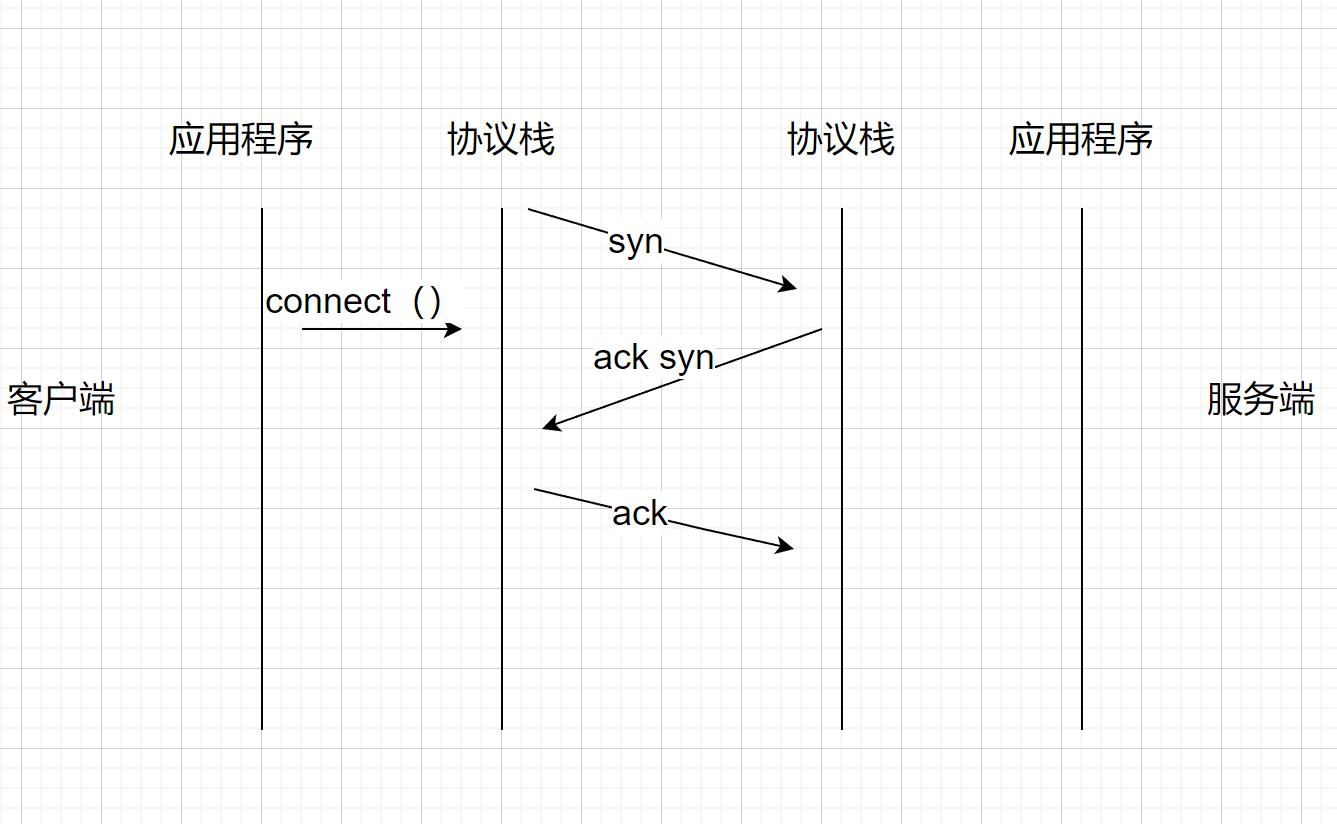
三次握手发生在协议栈和协议栈之间,而posix api connect 只是一个导火索。调用connnect,客户端先发三次握手的第一次数据包,这时候里面带有一个同步头syn,seq=x,这是由客户端内核协议栈发送的数据包。服务端接收到之后,返回三次握手的第二个数据包(这个返回也是协议栈做的)syn=1,ack=1,seq=y,ack=x+1 。其中ack=x+1代表确认了x+1以前的都收到了,也就是说告诉对端,你发送的数据包,序号在x+1之前的我都收到了。同样也携带自己的一个同步头给对端。再往下面走,就是三次握手的第三次,客户端返回一个ack确认包给服务器。
A给B发syn,B回一个ack,这里确定了B是存在的,这里两次。A回一个ack,这里确定了A是存在的,这里三次。客户端发送一次syc,服务器返回一个ack并且携带自己的syn,这时候能确定服务器存在,客户端再返回一个ack,这时候能确定客户端存在,这时候就确定了这个双向通道是ok了。
为什么说connect就是个导火索呢?只负责引发连接,之后就不是它的事情了,是协议栈的事情了。调用connect之后,协议栈开始三次握手。那么connect函数到底组不阻塞呢,取决于传进去的fd,如果fd是阻塞,那么直到第三次握手包发送之后就会返回。如果fd是非阻塞,那么返回-1的时候说明连接建立中,返回0代表连接建立成功。
listen
listen就是让服务器进入监听状态,之后会创建出两个队列,一个半连接队列和一个全连接队列。
服务器内核协议栈在接收到三次握手的第一次syn包的时候,从这个sync包里面可以解析出来源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 ,那么五元组五元组 < 源IP地址 , 源端口 , 目的IP地址 , 目的端口 , 协议 > 就可以确定下来了,从而构建出来一个TCB,只不过目前这个TCB还不能用,因为还没有分配socket,还没有分配fd。这时候会将TCB加入到半连接队列(sync队列)里面。所以在第一次收到syn包的时候,服务端做两件事,1返回ACK,2创建一个TCB结点,加入半连接队列里面。
当第三次握手收到ACK之后,也有一个队列,叫做全连接队列。当第三次握手的时候会把在半连接队列里面的TCB结点拿到全连接队列。怎么在半连接队列里面查找到相应的节点呢?通过五元组查找。
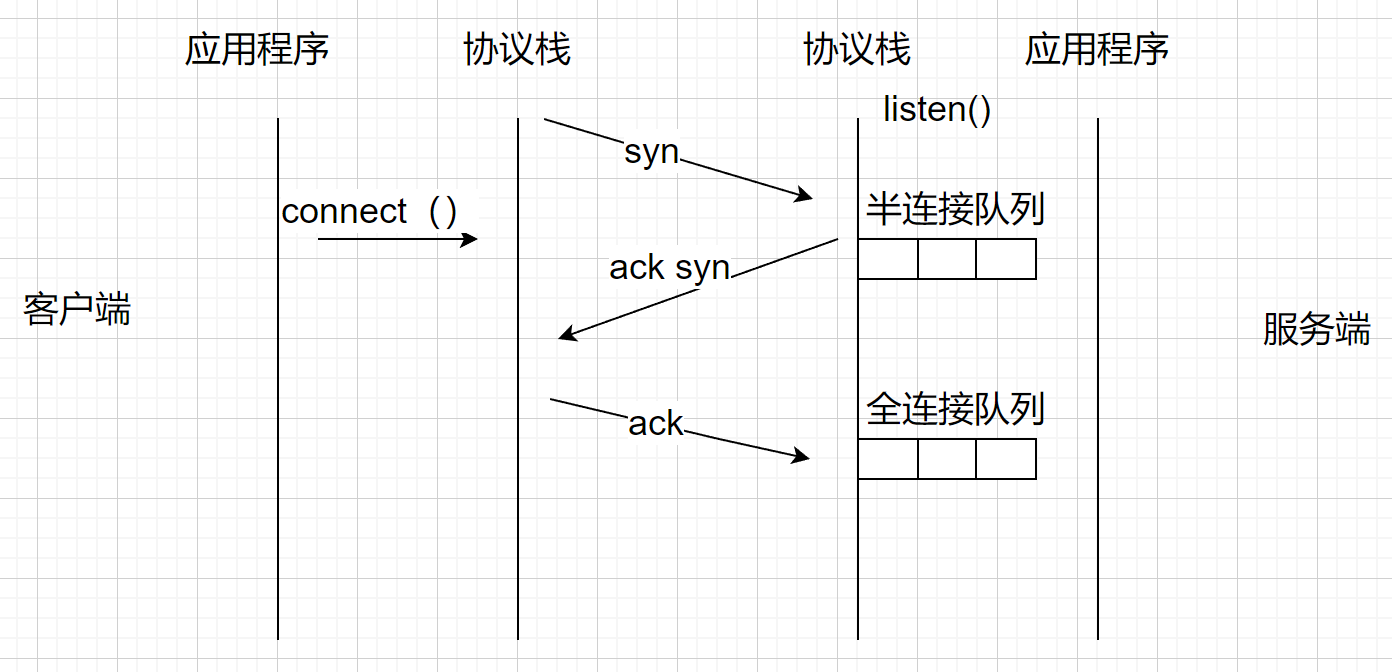
listen()函数的第二个参数backlog,设置的就是连接队列,不同的操作系统设置的效果不同。
在unix,mac系统里面,半连接队列与全连接队列的总和 <= backlog
在Linux系统里面, 全连接队列<=backlog
accept
accept就是对全连接队列进行操作的。先从全连接队列中取出一个TCB结点,为这个TCB结点分配一个fd,把fd和TCB做一个一对一对应的关系。直到现在这个TCB才能用,因为分配了fd。
到现在应该明白的三次握手发生在哪了吧,三次握手发生在调用connect之后,accept之前。
数据交换
send & recv
我们经常使用send来发送数据,recv来接收数据。实际上send只是把数据拷贝到协议栈里对应的TCB中的写缓冲区。至于真正数据发送的时机,什么时候发送的,发送的数据有没有与之前的数据粘在一起,都不是由应用程序决定的,应用程序只能将数据拷贝到内核buffer缓冲区里面。然后协议栈将sendbuffer的数据,加上TCP的头,加上IP的头,加上以太网的头,一起打包发出去。
对端网络协议栈接收到数据,同样开始解析,以太网的头mac地址是谁,ip地址从哪里来的,源端口是多少,目的端口是发到哪个进程里面,然后将数据写进对应的TCB里。recv只是把协议栈里对应的TCB中的读缓冲区内容拷贝到内存中供用户使用。拷走之后系统会把相应读缓冲区清空,写缓冲区同理。
如果不停的send,直到sendbuffer缓冲区满了,这个时候send会返回-1,代表内核缓冲区满了,send的copy失败。而如果recvbuffer缓冲区满了而应用程序没有去接收,这时候TCP协议栈会告诉对端,我的缓冲区空间还有多大,超过这个大小就不要发。
粘包和分包
多个数据包被连续存储于连续的缓存中,在对数据包进行读取时由于无法确定发生方的发送边界,而采用某一估测值大小来进行数据读出,若双方的size不一致时就会使数据包的边界发生错位,导致读出错误的数据分包,进而曲解原始数据含义。
解决的方法有两种:
第一种:在数据包前面加上这个包有多长
第二种:为每一个包加一个特定的分隔符
延迟确认ACK
上面两种解决方法有一个很大的前提,就是这个数据包是顺序的。先发的先到,后发的后到。那这个顺序是怎么来确定的呢?
在协议栈里有一个200ms的定时器,当有数据包到来之后就重置这个定时器的时间,然后再200ms开始倒数。
假设有五个数据包ABCDE,当第一个包B到来的时候就会启动定时器,然后C到了,重置定时器继续倒数,200ms里A又到了,再重置,E到了,继续重置,然后200ms过去了超时了D包还没来。这个时候就回一个ACK=D,代表D之前的都收到了,接下来D以及D以后的数据包都会重发。为什么选择后面的都重发,因为如果是穿插着丢的,还需要通过一系列算法等来找到那几个丢了,太麻烦了,索性后面的就都一起发了,不需要这么麻烦的判断。
这样就解决了包的无序的问题,这里的操作都是TCP协议栈来做的。
udp使用场景
延迟ACK确认时间长,超时重传的时候,重传的包较多,很费带宽。于是udp的机会就来了。随着带宽越来越高,udp的使用场景在不断减少,但是在弱网的环境下,做大量数据传输的时候,TCP就不合适了,因为一旦出现丢包的情况,后面的包都要重传了,很浪费时间,没办法保持实时性。
udp的使用场景:1.弱网环境下 2.实时性要求高的环境(比如王者荣耀、英雄联盟等游戏,每一秒都很关键)。
四次挥手断开连接
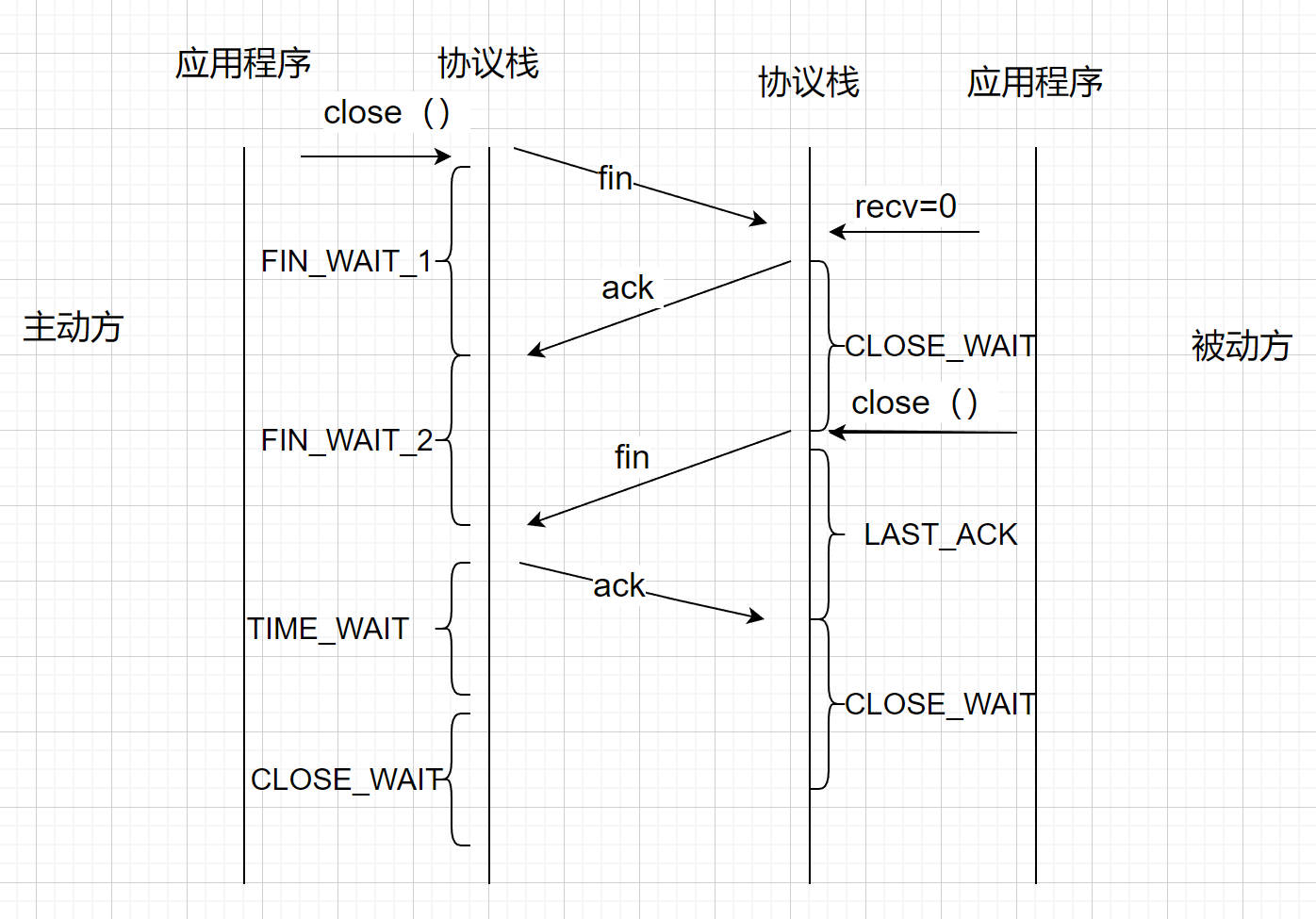
在四次挥手的过程中,没有客户端和服务器之分,只有主动方和被动方之分。主动方首先发送一个fin,被动方返回一个ack。被动方再发送一个fin,主动方返回一个ack。
第一次的fin由谁来发取决于谁调用的close(),协议栈会将最后一个包fin位,置1,被动方接收之后,会触发一个可读事件,然后调用recv得到返回值0。主动方会做两件事情,第一件事情推给应用程序一个空包,第二件事情直接返回一个ack的包返回给对端。然后被动方recv=0读到之后,应用程序会调用close,这时候被动方也会发送一个fin,对端收到fin会回复一个ack,至此四次挥手完毕。

主动方在调用close之前它的状态是确定的ESTABLISHED状态,发送fin后,进入FIN_WAIT_1状态,收到ack以后进入FIN_WAIT_2状态。简单来说就是没收到被动方发的东西,收到一个后,就进入FIN_WAIT_2状态,收到数据fin以后就不再是FIN_WAIT_2状态,就进入TIME_WAIT状态。进入TIME_WAIT状态之后,再等待2MSL后,进入CLOSED状态。TIME_WAIT存在的原因避免最后一个ack丢失,而对端一直超时重发fin,导致连接得不到释放。
被动方在接收到fin后,进入CLOSE_WAIT状态,之后调用close发送fin后,进入LAST_ACK状态,收到ack之后,进入CLOSED状态。
(2MSL就是一个发送和一个回复所需的最大时间。)
特殊情况
有一种特殊情况是主动方调用close,被动方也调用close,同时调用。
那么双方就会在双方的FIN_WAIT1状态期间接收到fin,这时候就进入CLOSING状态,之后收到ack就进入TIME_WAIT状态,然后进入CLOSE_WAIT状态。
本来等着都收ack的,结果先收到了fin,就知道遇到了同时的这种情况,就进入CLOSING状态。

状态图
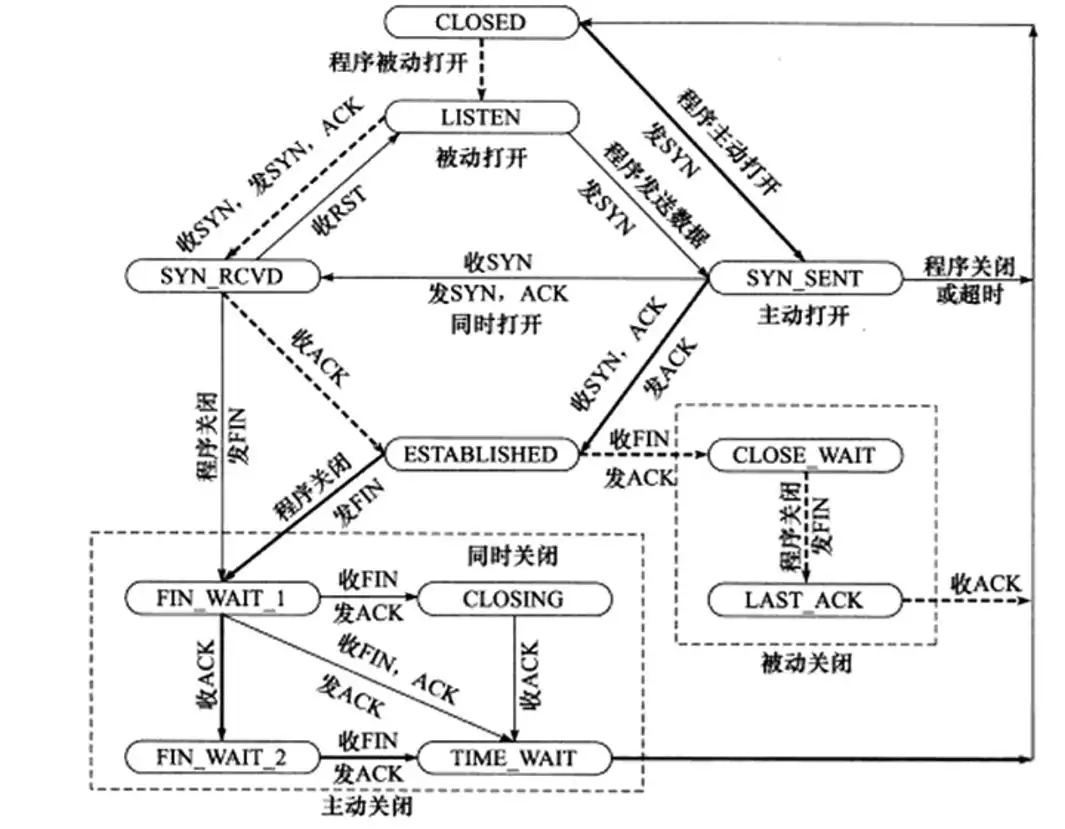
上面没有讲ESTABLISHER以上状态,首先服务器进入被动监听状态LISTEN,当收到第一次握手的syn数据时创建一个新的TCB,这个新创建出来的TCB进入SYN_RCVD状态,此时这个发送第一次握手syn包的客户端进入SYN_SENT状态。
上面说过第一次握手的时候会把TCB加入到半连接队列中,也就是说半连接队列里面的TCB全部都是SYN_RCVD状态。当三次握手第三次握手收到客服端发送的ack时,会将半连接队列的结点拿到全连接队列,这时候三次握手成功,从SYN_RCVD状态变成ESTABLISHER状态。客户端在发送第三次握手ACK时候,也会从SYN_SENT状态变成ESTABLISHER状态。
ESTABLISHER状态就是建立的状态了,就是可以数据交互的状态。
常见问题
现在假设客户端连接进入FIN_WAIT_1状态,会在这个状态很久吗?
不会,因为即使没有收到ack,也会超时重传fin,进入FIN_WAIT_2状态。
如果连接停在FIN_WAIT_2状态的时间很久怎么办呢?
客户端停在FIN_WAIT_2状态,那么服务器就停在CLOSE_WAIT状态。服务器出现大量CLOSE_WAIT状态,造成这一现象是因为客户端调用关闭,而服务器没有调用close,再去分析,其实就是业务逻辑的问题。
recv=0,但是没有调用close,原因在哪呢?也就是说从recv到调用close这个过程中间,时间太长,为什么时间太长呢,可能在调用close之前,有去关闭一些fd相关联的业务信息,造成比较耗时的情况。调用close之前这个TCB就处于CLOSE_WAIT状态。
那么如何解决呢?1. 要么先调用close 2. 要么把业务信息抛到消息队列里面交给线程池进行处理。把业务的清理当成一个任务交给另一个线程处理。 原来的线程把网络这一层处理好。
作为客户端去连第三方服务,长时间卡在FIN_WAIT_2状态,有没有办法去终止它?
从FIN_WAIT_2是不能直接到CLOSED状态的,所以这个问题要么再起一个连接,要么就杀死进程,要么就等待FIN_WAIT_2定时器超时。
如果服务器在调用close之前宕机了,fin是肯定发不到客户端的,那么客户端一直在FIN_WAIT_2状态,这个时候怎么办呢,如果开启了keepalive,检测到是死链接后会被终止掉。那没有开启keepalive呢?
FIN_WAIT_2 状态的一端一直等不到对端的FIN。如果没有外力的作用,连接两端会一直分别处于 FIN_WAIT_2 和 CLOSE_WAIT 状态。这会造成系统资源的浪费,需要对其进行处理。(内核协议栈就有参数提供了对这种异常情况的处理,无需应用程序操作),也就是说,等着就行。
如果应用程序调用的是完全关闭(而不是半关闭),那么内核将会起一个定时器,设置最晚收到对端FIN报文的时间。如果定时器超时后仍未收到FIN,且此时TCP连接处于空闲状态,则TCP连接就会从 FIN_WAIT_2 状态直接转入 CLOSED 状态,关闭连接。在Linux系统中可以通过参数 net.ipv4.tcp_fin_timeout 设置定时器的超时时间,默认为60s。
资源回收
主动方调用close之后,fd被回收,在time_wait时间到了进入CLOSED后,TCB被回收
被动方调用close之后,fd被回收。在接收到ack以后进入CLOSED后,TCB被回收
简单来说就是:当调用close之后,fd就会被回收。当TCB进入CLOSED状态后,TCB就会被回收。















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









