







 本文介绍了书生·浦语大模型系列,包括轻量级InternLM-7B到1230亿参数的高性能模型,强调了它们的训练数据、模型能力、微调技术以及全链路开源体系。文章详细讨论了数据处理、模型训练优化、多模态融合以及部署技术挑战。
本文介绍了书生·浦语大模型系列,包括轻量级InternLM-7B到1230亿参数的高性能模型,强调了它们的训练数据、模型能力、微调技术以及全链路开源体系。文章详细讨论了数据处理、模型训练优化、多模态融合以及部署技术挑战。
-
书生·浦语大模型系列
- 轻量级:InternLM-7B
- 70亿模型参数
- 1000亿训练token数据
- 长语境能力,支持8K语境窗口长度
- 通用工具调用能力,多种工具调用模板
- 中量级:InternLM-20B
- 200亿模型参数,在模型能力与推理代价间取得平衡
- 采用深而窄的结果,降低推理计算量但提高推理能力
- 4K训练语境长度,推理时可外推至16K
- 重量级:1230亿模型参数,强大的性能
- 极强推理能力、全面的知识覆盖面、超级理解能力与对话能力
- 准确的API调用能力,可实现各类Agent
- 轻量级:InternLM-7B
-
从模型到应用流程
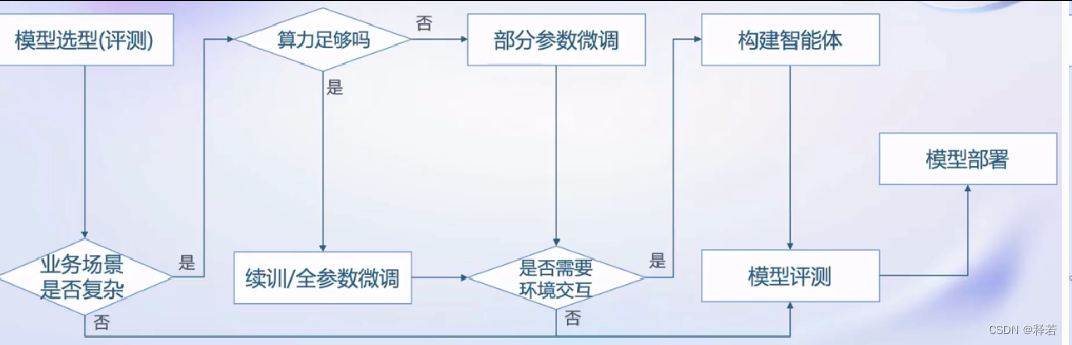 - 浦语大模型全链路开源体系生态
- 浦语大模型全链路开源体系生态- 数据:书生·万卷
- 2TB数据,涵盖多种模态与任务
- 预训练:InternLM-Train
- 并行训练,极致优化速度达到3600 Tokens/sec/gpu
- 微调:XTuner
- 支持全参数微调
- 支持LoRA等低成本微调
- 部署:LMDeploy
- 全链路部署,性能领先
- 每秒生成2000+tokens
- 评测:Open
- 数据:书生·万卷
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








