







我们常常需要在一段字符串或者一个文件里寻找匹配的字符串
比如我们要从下面这段字符串里面打印出所有的工资数据
"""
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
""" 类似这样
2
2.5
2.8
2.5
怎么做?大家可以尝试一下
我们将上面的字符串数据赋值给 content , 剩下的代码这样写:
# 将文本内容按行放入列表
lines = content.splitlines()
for line in lines:
# 查找'万/月' 在 字符串中什么地方
pos2 = line.find('万/月')
if pos2 < 0:
# 查找'万/每月' 在 字符串中什么地方
pos2 = line.find('万/每月')
# 都找不到
if pos2 < 0:
continue
# 执行到这里,说明可以找到薪资关键字
# 接下来分析 薪资 数字的起始位置
# 方法是 找到 pos2 前面薪资数字开始的位置
idx = pos2-1
# 只要是数字或者小数点,就继续往前面找
while line[idx].isdigit() or line[idx]=='.':
idx -= 1
# 现在 idx 指向 薪资数字前面的那个字,
# 所以薪资开始的 索引 就是 idx+1
pos1 = idx + 1
print(line[pos1:pos2])一、正则表达式的作用
上面那个题,用正则表达式这样写:
import re
for one in re.findall(r'([\d.]+)万/每{0,1}月', content):
print(one)怎么样?是不是很方便?
这个里面字符串前面加一个 r 是为了防止python将引号里面的字符转义
二、正则表达式规则
正则表达式是独立于任何语言的,虽然不同的语言中其语法略有不同。
(1)、普通字符
写在正则表达式里面的普通字符都是表示: 直接匹配它们。
但是有些特殊的字符,术语叫 metacharacters(元字符)。
它们出现在正则表达式字符串中,不是表示直接匹配他们, 而是表达一些特别的含义。
元字符包括:
. * + ? \ [ ] ^ $ { } | ( )
(2)、元字符的含义
1、 .
. 表示要匹配除了 换行符 之外的任何 单个字符。
2、 *
* 表示匹配前面的子表达式任意次,包括0次。
3、+
+ 表示匹配前面的子表达式一次或多次,不包括0次。
4、 ?
? 表示匹配前面的子表达式0次或1次。
5、{ }
{ } 花括号表示 前面的字符匹配 { }内的指定次数
6、贪婪模式
我们要把下面的字符串中的所有html标签都提取出来,
source = '<html><head><title>Title</title>'
得到这样一个列表:
['<html>', '<head>', '<title>', '</title>']
很容易想到使用正则表达式 <.*>
写出如下代码
source = '<html><head><title>Title</title>'
import re
p = re.compile(r'<.*>')
print(p.findall(source))但是运行结果,却是
['<html><head><title>Title</title>']
怎么回事? 原来在正则表达式中, ‘*’, ‘+’, ‘?’ 都是贪婪地,使用他们时,会尽可能多的匹配内容,
所以,<.*> 中的 星号(表示任意次数的重复),一直匹配到了 字符串最后的 </title> 里面的e。
解决这个问题,就需要使用非贪婪模式,也就是在星号后面加上 ? ,变成这样 <.*?>
代码改为
source = '<html><head><title>Title</title>'
import re
# 注意多出的问号
p = re.compile(r'<.*?>')
print(p.findall(source))7、\ 对元字符转义
\ 是转义字符,可以实现对原本字符的转义;第一种是将元字符回归到字面意思:
比如, 我们要在下面的文本中搜索 . 前面的字符串,也包含 . 本身。
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
假如我们这样写 .*. 你觉得对不对?是不是感觉哪里有问题?
因为 点 是一个 元字符, 直接出现在正则表达式中,表示匹配任意的单个字符, 不能表示 . 这个字符本身的意思。
如果我们要搜索的内容本身就包含元字符,就可以使用 反斜杠进行转义。
这里我们就应用使用这样的表达式: .*\.
demo应该这么写:
import re
content = "苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的"
p = compile(r'.*\.')
print(p.findall(content))运行结果如下:
苹果.
橙子.
香蕉.
8、\ 匹配某种字符类型
\d 匹配0-9之间任意一个数字字符,等价于表达式 [0-9]
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式 [^0-9]
\s 匹配任意一个空白字符,包括 空格、tab、换行符等,等价于表达式 [\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式 [^ \t\n\r\f\v]
\w 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9_]
缺省情况也包括 Unicode文字字符,如果指定 ASCII 码标记,则只包括ASCII字母
\W 匹配任意一个非文字字符,等价于表达式 [^a-zA-Z0-9_]
\ 也可以用在方括号里面,比如 [\s,.] 表示匹配 任何空白字符,或者逗号,或者点
9、[ ]
方括号表示要匹配 指定的几个字符之一 。
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。
[a-z] 中间的 - 表示一个范围从a 到 z。
元字符在 [ ] 里面会恢复本意
[akm.] 匹配 a k m . 里面任意一个字符
如果在方括号中使用 ^, 表示 非 方括号里面的字符集合;[^\d]表示非数字的字符。比如
content = 'a1b2c3d4e5'
import re
p = re.compile(r'[^\d]' )
for one in p.findall(content):
print(one)就会打印出
a
b
c
d
e
10、^
^ 表示匹配文本的 开头 位置。比如:
下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
如果我们要提取所有的水果编号,用这样的正则表达式 ^\d+
上面的正则表达式,使用在Python程序里面,如下所示
content = '''001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80'''
import re
p = re.compile(r'^\d+', re.M)
for one in p.findall(content):
print(one)注意,compile 的第二个参数 re.M ,指明了使用多行模式,
运行结果如下
001
002
003
如果,去掉 compile 的第二个参数 re.M, 运行结果如下
001
就只有第一行了。
因为单行模式下,^ 只会匹配整个文本的开头位置。
11、 $
$ 表示匹配文本的 结尾 位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80
如果我们要提取所有的水果价格,用这样的正则表达式 \d+$
content = '''001-苹果价格-60
002-橙子价格-70
003-香蕉价格-80'''
import re
p = re.compile(r'\d+$', re.MULTILINE)
for one in p.findall(content):
print(one)注意,compile 的第二个参数 re.MULTILINE ,指明了使用多行模式,
运行结果如下
60
70
80
如果,去掉 compile 的第二个参数 re.MULTILINE, 运行结果如下
80
就只有最后一行了,因为单行模式下,$ 只会匹配整个文本的结束位置。
12 、|
竖线表示 匹配 其中之一 。比如 :
特别要注意的是, 竖线在正则表达式的优先级是最低的, 这就意味着,竖线隔开的部分是一个整体
比如 绿色|橙 表示 要匹配是 绿色 或者 橙 ,
而不是 绿色 或者 绿橙
13、( )
括号称之为 正则表达式的 组选择。
组 就是把 正则表达式 匹配的内容 里面 其中的某些部分 标记为某个组。
我们可以在 正则表达式中 标记 多个 组
为什么要有组的概念呢?因为我们往往需要提取已经匹配的 内容里面的 某些部分的信心。
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也 包括逗号本身 。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式 ^.*,
但是,如果我们要求 不要包括逗号 呢?
当然不能直接 这样写 ^.*
因为最后的逗号 是 特征 所在, 如果去掉它,就没法找 逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用 组选择符 : 括号。
我们这样写 ^(.*), 结果如下
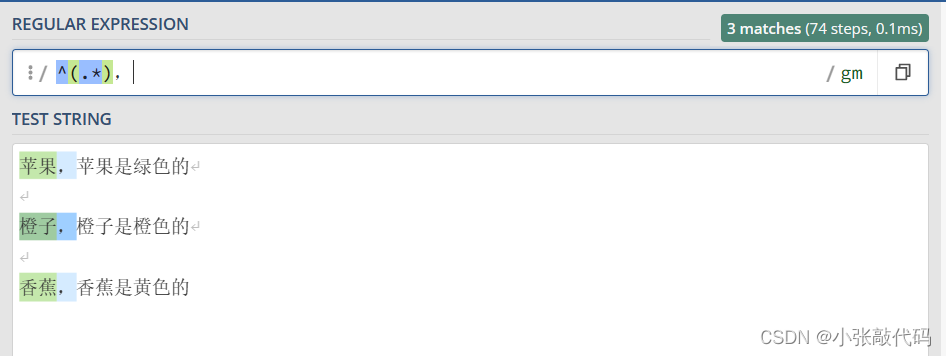
大家可以发现,我们把要从整个表达式中提取的部分放在括号中,这样 水果 的名字 就被单独的放在 组 group 中了。
对应的Python代码如下
content = '''苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的'''
import re
p = re.compile(r'^(.*),', re.MULTILINE)
for one in p.findall(content):
print(one)分组 还可以多次使用。
比如,我们要从下面的文本中,提取出每个人的 名字 和对应的 手机号
张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901
可以使用这样的正则表达式 ^
可以写出如下的代码
content = '''张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901'''
import re
p = re.compile(r'^(.+),.+(\d{11})', re.MULTILINE)
for one in p.findall(content):
print(one) 当有多个分组的时候,我们可以使用 (?P<分组名>...) 这样的格式,给每个分组命名。
这样做的好处是,更方便后续的代码提取每个分组里面的内容
比如:
content = '''张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901'''
import re
p = re.compile(r'^(?P<name>.+),.+(?P<phone>\d{11})', re.MULTILINE)
for match in p.finditer(content):
print(match.group('name'))
print(match.group('phone'))14、让 . 匹配换行
前面说过,点 是不匹配换行的,可是有时候,特征 字符串就是跨行的,比如要找出下面文字中所有的职位名称 :
<div class="el">
<p class="t1">
<span>
<a>Python开发工程师</a>
</span>
</p>
<span class="t2">南京</span>
<span class="t3">1.5-2万/月</span>
</div>
<div class="el">
<p class="t1">
<span>
<a>java开发工程师</a>
</span>
</p>
<span class="t2">苏州</span>
<span class="t3">1.5-2/月</span>
</div>如果你直接使用表达式 class=\"t1\">.*?<a>(.*?)</a> 会发现匹配不上,因为 t1 和 <a> 之间有两个空行。
这时你需要 点也匹配换行符 ,可以使用 DOTALL 参数:
content = '''
<div class="el">
<p class="t1">
<span>
<a>Python开发工程师</a>
</span>
</p>
<span class="t2">南京</span>
<span class="t3">1.5-2万/月</span>
</div>
<div class="el">
<p class="t1">
<span>
<a>java开发工程师</a>
</span>
</p>
<span class="t2">苏州</span>
<span class="t3">1.5-2/月</span>
</div>
'''
import re
p = re.compile(r'class=\"t1\">.*?<a>(.*?)</a>', re.DOTALL)
for one in p.findall(content):
print(one)15、回到开头的例子
从下面的文本里面抓取 所有职位的薪资。
"""
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
""" 我们使用的表达式是 ([\d.]+)万/每{0,1}月
为什么这么写呢?
[\d.]+ 表示 匹配 数字或者点的多次出现 这就可以匹配像: 3 33 33.33 这样的 数字
万/每{0,1}月 是后面紧接着的,如果没有这个,就会匹配到别的数字, 比如 Python3 里面的3。
其中 每{0,1}月 这部分表示匹配 每月 每 这个字可以出现 0次或者1次。
聪明的你能想到,还可以用什么来表示这个 每{0,1}月 吗?
对啦,还可以用 每?月 因为问号表示 前面的字符匹配0次或者1次
16、切割字符串
字符串 对象的 split 方法只适用于 简单的字符串分割。 有时,你需要更加灵活的字符串切割。
比如,我们需要从下面字符串中提取武将的名字。
names = '关羽; 张飞, 赵云,马超, 黄忠 李逵'
我们发现这些名字之间, 有的是分号隔开,有的是逗号隔开,有的是空格隔开, 而且分割符号周围还有不定数量的空格
这时,可以使用正则表达式里面的 split 方法:
import re
names = '关羽; 张飞, 赵云, 马超, 黄忠 李逵'
namelist = re.split(r'[;,\s]\s*', names)
print(namelist)正则表达式 [;,\s]\s* 指定了,分割符为 分号、逗号、空格 里面的任意一种均可,并且 该符号周围可以有不定数量的空格。
17、字符串替换——匹配模式替换
字符串 对象的 replace 方法只适应于 简单的 替换。 有时,你需要更加灵活的字符串替换。
比如,我们需要在下面这段文本中 所有的 链接中 找到所以 /avxxxxxx/ 这种 以 /av 开头,后面接一串数字, 这种模式的字符串。
然后,这些字符串全部 替换为 /cn345677/ 。
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
被替换的内容不是固定的,所以没法用 字符串的replace方法。
这时,可以使用正则表达式里面的 sub 方法:
import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
newStr = re.sub(r'/av\d+?/', '/cn345677/' , names)
print(newStr)sub 方法就是也是替换 字符串, 但是被替换的内容 用 正则表达式来表示 符合特征的所有字符串。
比如,这里就是第一个参数 /av\d+?/ 这个正则表达式,表示以 /av 开头,后面是一串数字,再以 / 结尾的 这种特征的字符串 ,是需要被替换的。
第二个参数,这里 是 '/cn345677/' 这个字符串,表示用什么来替换。
第三个参数是 源字符串。
18、字符串替换——指定替换函数
刚才的例子中,我们用来替换的是一个固定的字符串 /cn345677/。
如果,我们要求,替换后的内容 的是原来的数字+6, 比如 /av66771949/ 替换为 /av66771955/
怎么办?
这种更加复杂的替换,我们可以把 sub的第2个参数 指定为一个函数 ,该函数的返回值,就是用来替换的字符串。如下:
import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
# 替换函数,参数是 Match对象
def subFunc(match):
# Match对象 的 group(0) 返回的是整个匹配上的字符串,
src = match[0]
# Match对象 的 group(1) 返回的是第一个group分组的内容
number = int(match[1]) + 6
dest = f'/av{number}/'
print(f'{src} 替换为 {dest}')
# 返回值就是最终替换的字符串
return dest
newStr = re.sub(r'/av(\d+?)/', subFunc , names)
print(newStr)获取组内字符串,如下
match.[0] # 获取整个匹配字符串
match.[1] # 获取第1个组内字符串
match.[2] # 获取第2个组内字符串
上面这个例子中:
正则表达式 re.sub 函数执行时, 每发现一个 匹配的子串, 就会:
-
实例化一个 match对象
这个match 对象包含了这次匹配的信息, 比如:整个字符串是什么,匹配部分字符串是什么,里面的各个group分组 字符串是什么
-
调用执行 sub函数的第2个参数对象,也就是调用回调函数subFunc
并且把刚才产生的 match 对象作为参数传递给 subFunc
















 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









