







Spark-SQL概述
1.1Spark-SQL是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
1.2Spark-SQL的特点
1.2.1 易整合。无缝的整合了 SQL 查询和 Spark 编程
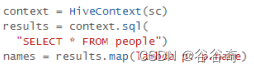
1.2.2 统一的数据访问。使用相同的方式连接不同的数据源

1.3.3 兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL
Spark-SQL概述
1.1Spark-SQL是什么
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
1.2Spark-SQL的特点
1.2.1 易整合。无缝的整合了 SQL 查询和 Spark 编程
1.2.2 统一的数据访问。使用相同的方式连接不同的数据源
1.3.3 兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL
 1462
480
1462
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















