







目录
什么是库
我们经常听人说库,有粮库,水库,信息库等,那么在计算机领域的库又是什么呢?
我们日常说的库是存储某类或多类资源的地方,而我们要学习的库也是如此。
那么计算机领域中的库都有什么呢?
静态库(.a):程序在编译的时候把程序所需的代码从库中拷贝到程序代码中。程序运行的时候将不再需要静态库。
动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码。(即将库加载到进程中,保存库中所需代码的地址,运行时再去寻找函数)
在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
我们先来看看库到底是怎么用的,又是怎么做出来的?
静态库与动态库的使用
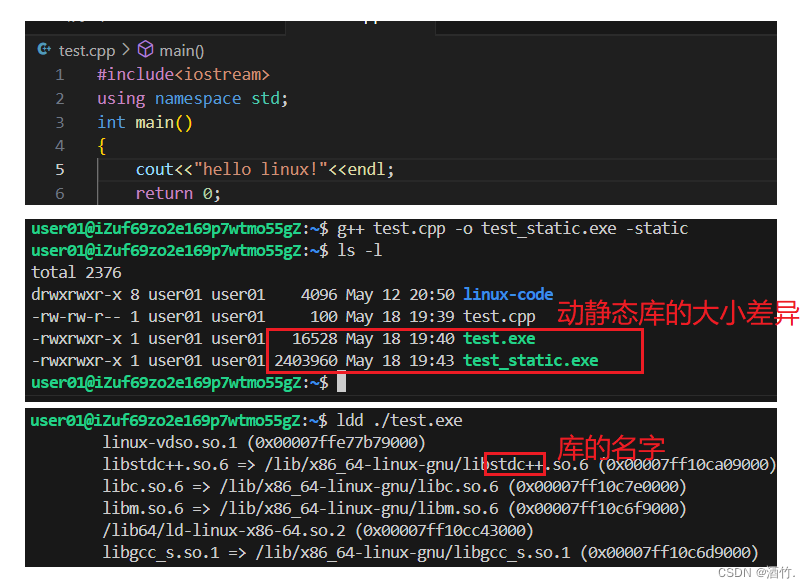
在Linux下,gcc与g++默认是动态链接,如果要静态链接则需要加-static选项。上图我们可以看到,静态链接的可执行程序比动态链接的可执行程序大数十倍,而即便是动态链接的可执行程序也比源代码大数十倍。这是为什么呢?
这是因为编译器在执行预编译,编译,汇编,链接的过程中,会不断的添加程序所需的信息与资源,而由于动静态链接原理的不同,造成了文件大小差异巨大的现象。
静态链接是在编译阶段就将程序所需的库中代码拷贝到程序的代码区,而动态链接仅仅是保存所需代码的地址,如此就造成了这一现象。关于动态链接的过程,我们后面再提。
静态库与动态库的原理与制作
动静态库在我们的眼里似乎一直很神秘,但其实动静态库非常简单,只需要几个头文件,几个目标文件以及main函数,一个简单的库就可以制作完成。
我们一起来做一个简单的库吧。
假设你的同学问你要一份作业的代码,但你又不想把源代码给他,就可以做一个库给他,让他既可以完成代码的运行,又不会看到你的方法实现。
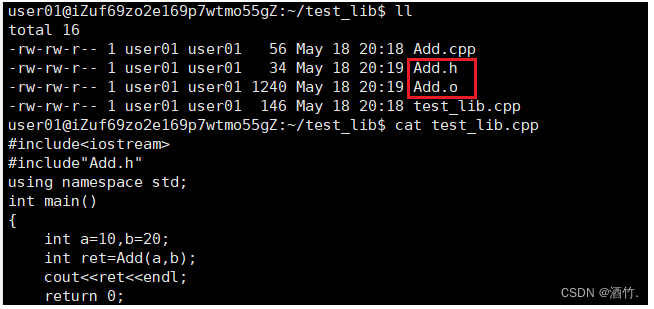
假设有一份作业,求两个整数之和。
你只需要将方法实现的.cpp使用g++ -c编译成目标文件.o,然后将头文件,目标文件与main函数发给他即可。这是一个最原始的库。
接下来我们分别实现静态库与动态库,并进行打包压缩。
Add.h
int MyAdd(int a,int b);Sub.h
int MySub(int a,int b);Add.cpp
#include"Add.h"
int MyAdd(int a,int b)
{
return a+b;
}Sub.cpp
#include"Sub.h"
int MySub(int a,int b)
{
return a-b;
}main.cpp
#include<iostream>
#include"Add.h"
#include"Sub.h"
using namespace std;
int main()
{
int a=50,b=20;
int retAdd=MyAdd(a,b);
int retSub=MySub(a,b);
cout<<retSub<<endl;
cout<<retAdd<<endl;
return 0;
}
以上是我们本次实验所用到的代码。

静态库
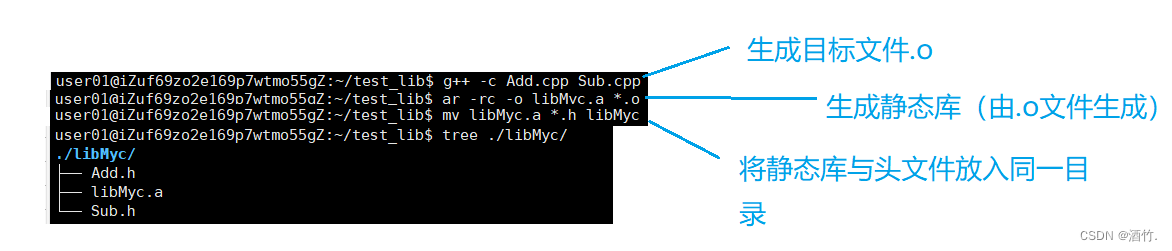
经过如上操作,我们就成功的实现了一个静态库,当然这里并未进行打包,如果有需要,可以进行打包压缩。
-I 索引头文件的目录
-L 指明库的路径之所在
-l 指明使用的库名
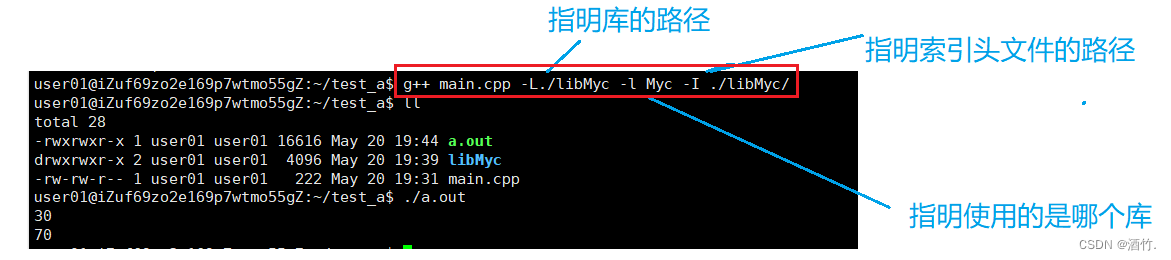
那么难道是用别人的库每次都需要加这么多命令行选项吗? 其实不然,还有一些方法后面再说。
动态库
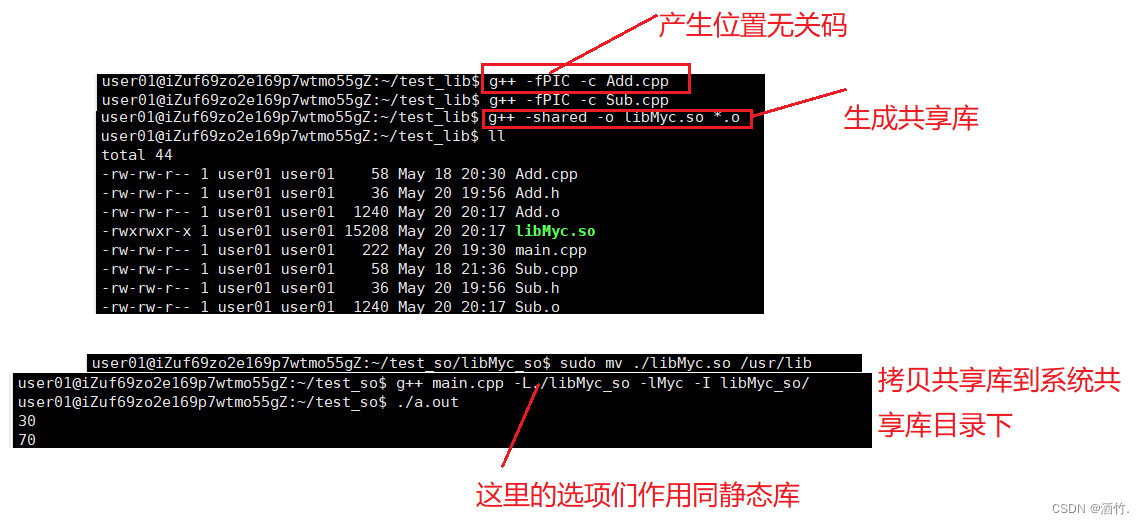
使用外部库的方式
一个报错
 大家可以看到,当我们使用类似静态库的命令进行编译链接生成了可执行程序,可当我们执行可执行程序却报了错。这是为什么呢?
大家可以看到,当我们使用类似静态库的命令进行编译链接生成了可执行程序,可当我们执行可执行程序却报了错。这是为什么呢?
这是因为静态链接仅编译时需要库,而动态链接在运行时同样需要与库进行链接,因此我在上面将自己的库拷贝到了系统共享库的目录下。我们接下来就看看其他动态链接的方式。
1. 方法一:将库拷贝到系统共享库路径(不推荐)
2. 方法二:将库添加到LD_LIBRARY_PATH

3. 方法三:软链接,生成库的同名软链接,然后放入库内
4. 方法四:将自定义库的路径放入该配置文件中。
动态库与静态库的优先权
动态库与静态库都存在
默认动态链接,如果要静态,加-static选项
只有静态库
静态链接,但不一定整体都是静态链接
只有动态库
只能动态链接,不能静态链接。
理解动态库的加载
动态库的本质
动态库的本质就是一个磁盘级别的文件,是一个可以同时被多个进程使用的文件!
一个文件可以同时被多个文件打开吗?yes!
因此我们的库也是同样的。
进程、可执行程序、库之间的关系
首先,库是一个文件,进程在运行时,需要库,此时库加载到内存中并被进程使用。
那么为什么说程序在编译与运行时都需要动态库?
这里记得程序与进程并不等同。
程序是静态的代码集合,而进程是程序在内存中执行时的实例。程序需要进程来执行,进程是程序的运行状态。
大家有没有想过我们点击可执行程序,随后进程启动,此时进程就已经有了一系列的数据结构。那么进程里的进程地址空间是由谁初始化的?
答案就是可执行程序。我们的可执行程序本身就是有地址的。可执行程序本身也是文件,编译链接形成可执行程序时,可执行程序就已经在划分自身区域了,比如权限,文件属性,代码段等等。
如下图, 可执行程序的文件格式中包含了许多信息,正是由此初始化进程的地址空间。
言归正传,进程是如何加载动态库的呢?
程序在编译链接时,将库的基地址与所需函数在库中的偏移量进行保存,随后在进程启动后,将这一信息保存在进程的地址空间内,(注意,可执行程序的文件格式中会保存该程序所需的动态库),当调用库函数时,直接通过基地址加偏移量就访问到了库函数。
而静态链接,程序在编译阶段就已经将静态库中所需代码拷贝到了目标文件中,因此后续并不需要。
















 7147
7147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









