









目录
二、Selenium WebDriver基于Python实现脚本
一、Selenium简介
Selenium 是一款基于Web应用程序自动化测试的工具集合,Selenium 测试直接运行在浏览器中,本质是通过驱动浏览器,模拟用户的操作。工具的主要功能包括:测试与浏览器的兼容性,进行系统功能测试。
1、Selenium工具组件介绍
-
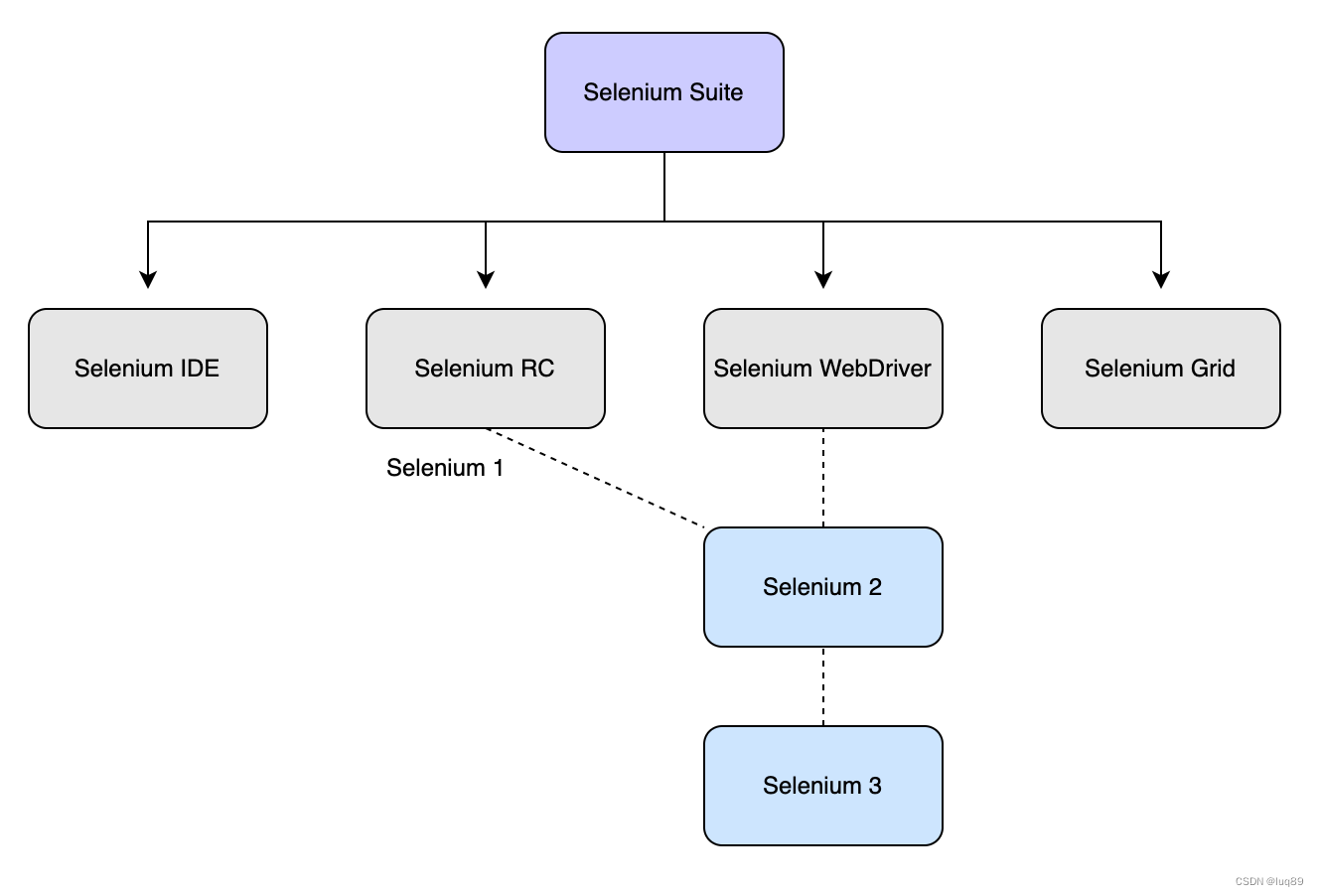
Selenium IDE:是嵌入到FireFox浏览器的插件,用于在Firefox上录制和回放Selenium脚本,虽然只能在Firefox下使用,但它能将录制好的脚本转换成各种Selenium WebDriver支持的程序语言,进而扩展到更广泛的浏览器类型;
-
Selenium RC:主要由两部分组成:selenium Server+Client Libraries;其中Selenium Server负责控制浏览器的行为,而Client Libraries则是给测试人员编写测试案例时用来控制selenium Server的库。Selenium RC也被称为Selenium 1后来和WebDriver合并带来Selenium 2;在Selenium 3.0版本中Selenium RC已经不存在。
-
Selenium WebDriver:用于操作浏览器的一套API;可支持多种语言,支持各类型浏览器,跨操作系统,WebDriver为诸多语言提供完备的,用于实现web自动化测试的第三方库;Selenium WebDriver目前包括两个版本Selenium 2和Selenium 3。
-
Selenium Grid:是一种动态工具,它可以在多个物理/虚拟机中并发地分发和运行Selenium测试。可以显著加快跨不同浏览器的测试进程,并通过提供快速和准确的结果来缩短测试周期。
2、Selenium WebDriver 介绍及实现原理
Selenium WebDriver 是业界通用的测试框架,不仅是web测试的标准,同时在移动测试领域也是底层的核心驱动框架
-
特点:
-
1、支持多浏览器操作:Chrome、IE、Firefox、Safaria等
-
2、支持夸平台:Windows、Linux、Mac等
-
3、支持多语言:Python、Java、Ruby、C#等
-
-
Selenium脚本执行时后端实现的流程:
-
1.对于每一条Selenium脚本指令,都会创建一个HTTP请求并且发送给浏览器的驱动
-
2.WebDriver启动浏览器驱动程序,建立HTTP Server,用来接收这些http请求
-
3.HTTP Server接收到请求后根据请求来具体操控对应的浏览器
-
4.浏览器执行具体的测试步骤,将步骤执行结果返回给HTTP Server
-
5.HTTP Server又将结果返回给Selenium的脚本,如果是错误的http代码我们就会在控制台看到对应的报错信息
-
-
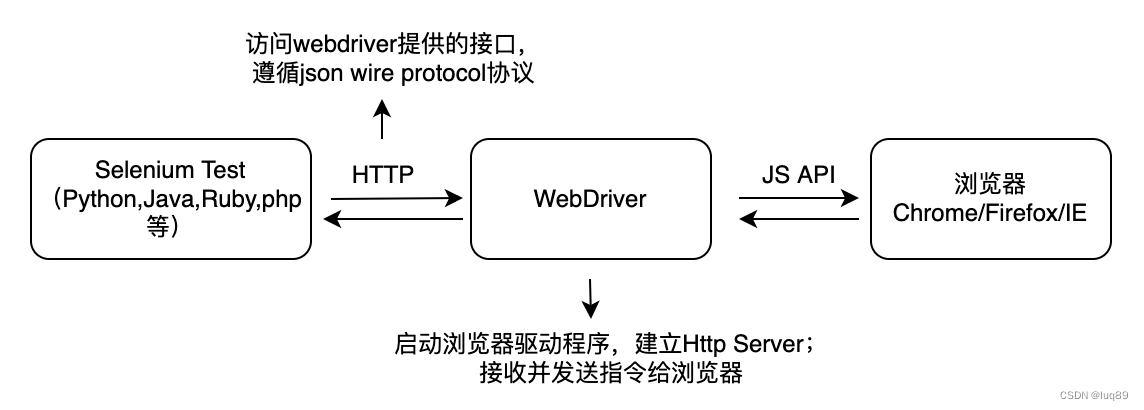
WebDriver是按照Client/Server模式设计的
-
Client:编程语言客户端;
-
Server:浏览器驱动程序。用来接收客户端的请求并驱动浏览器执行操作,然后返回结果;
-
-
WebDriver基于的协议:JSON Wire protocol
-
JSON Wire protocol是在http协议基础上,对http请求及响应的body部分的数据的进一步规范。body部分主要传送具体的数据,而且在WebDriver中这些数据都是以JSON的形式存在并进行传送的。所以在Client和Server之间,只要是基于JSON Wire Protocol来传递数据,同一个浏览器的驱动就可以处理不同语言的脚本。
-
二、Selenium WebDriver基于Python实现脚本
1、Selenium 环境安装
-
安装selenium
-
pip install selenium
-
-
安装WebDriver驱动程序
2、Selenium 操控浏览器的常用操作
-
页面基础操作
-
获取网址:get(url)
-
窗口最大化:maximize_window()
-
窗口最小化:minimize_window()
-
后退、前进、刷新:back()、forword()、refresh()
-
关闭浏览器:quit()
-
网页标题:title
-
网页URl:current_url
-
窗口句柄
-
当前窗口句柄:current.windows.handles
-
所有窗口句柄:windows.handles
-
-
当前页面源代码:page_source
-
对当前页面进行截图:get_screenshot_as_file(path)
-
-
元素八大定位方式
-
id定位:find_element_by_id()
-
name定位:find_element_by_name()
-
class定位:find_element_by_class_name()
-
link定位:find_element_by_link_text()
-
partial link定位:find_element_by_partial_link_text()
-
tag定位:find_element_by_tag_name()
-
xpath定位:find_element_by_xpath()
-
css定位:find_element_by_css_selector()
-
-
元素等待的三种方式
-
强制等待:通常使用在系统间的交互
-
time.sleep()
-
-
隐性等待:全局设置,可以设置超时时间;只能用来等待元素
-
implicitly_wait()
-
-
显性等待:等待某个元素可被点击、可见、窗口是否被打开;每次等待需要单独设置
-
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
-
-
-
三种切换方式
-
窗口切换,窗口句柄
-
获取窗口句柄:windowhandles[-1]
-
switch_to_window()
-
-
iframe切换
-
switch_to.iframe()
-
-
弹窗切换 toast
-
switch_to_alert
-
-
-
鼠标操作(在 webdriver 中 鼠标操作都封装在ActionChains类)
-
点击:click()
-
perform() :执行所有ActionChains中存储的动作
-
双击:double_click()
-
拖拽:drag_and_drop()
-
悬停:move_to_element()
-
右击:content_click()
-
-
-
下拉框操作
-
Select()
-
-
用户输入、键盘操作、文件路径
-
send_keys()
-
-
发送js指令(主要用于弥补selenium无法做到的特定页面操作)
-
页面滚动(例如:滑动到页面底部)
-
修改元素属性
-
-
系统交互上传
-
Win:pywinauto
-
跨平台:pyautogui
-
3、编写一个简单的Selenium脚本
-
启动浏览器
-
get打开指定页面、进行元素定位和操作
from selenium import webdriver
# 启动谷歌浏览器
driver = webdriver.Chrome(executable_path=r"/Users/bytedance/Desktop/chromedriver")
# 设置隐性等待
driver.implicitly_wait(5)
# 打开网页CSDN
driver.get("https://www.csdn.net/?spm=1001.2101.3001.4476")
# 定位"输入框"
input_box = driver.find_element("xpath",'//*[@id="toolbar-search-input"]')
# 输入文本:"Selenium自动化测试框架"
input_box.send_keys("Selenium自动化测试框架")
# 定位"搜索"功能并且点击
driver.find_element("xpath",'//*[@id="toolbar-search-button"]/span').click()
# 关闭浏览器
driver.quit()-
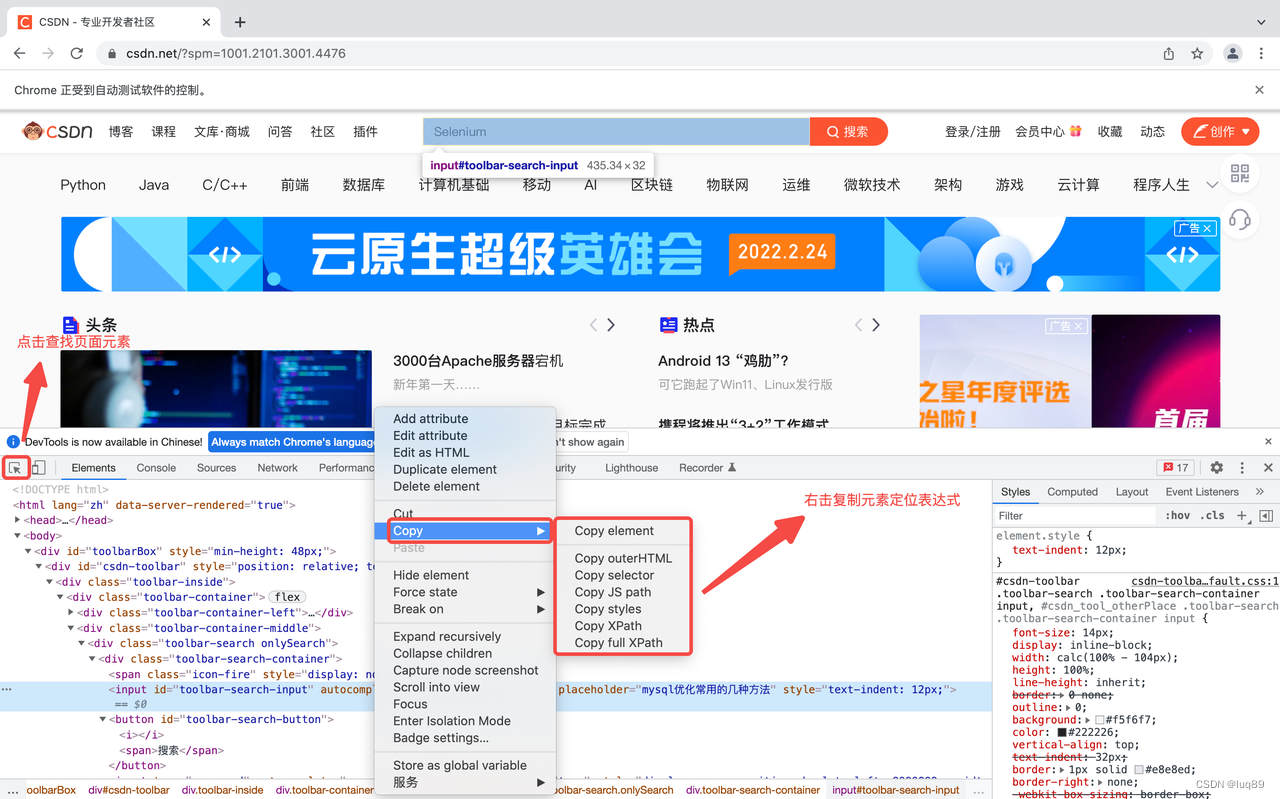
使用 selenium 定位页面元素的前提是需要了解基本的HTML页面布局和各种标签含义,通过【F12】开发者工具,从页面源码中定位获取我们需要的元素;
-
快捷方式:找到元素之后,可以右击Copy元素定位表达式。
-
三、自动化测试框架 及 架构设计 的选择
1、基于Python语言比较流行的测试框架
公共方法的封装及对脚本及配置文件怎么组织的设计就叫做框架。
-
Unittest: Python自带,最基础的单元测试框架
-
Nose: 基于Unittest开发,易用性好,有许多插件
-
Pytest: 同样基于Unittest开发,易用性好,信息更详细,插件众多
-
Robot Framework:一款基于Python语言的关键字驱动测试框架,有界面,功能完善,自带报告及log清晰美观
-
总体来说,Unittest比较基础,二次开发方便,适合高手使用;Pytest/Nose更加方便快捷,效率更高,适合小白及追求效率的公司;Robot Framework由于有界面及美观的报告,易用性更好,灵活性及可定制性略差。

2、PO设计模式
对于一个优秀的框架,不可或缺的当属是分层思想,而在Web UI自动化测试中,PO模式(Page Object)是十分主流的一项技术;PO设计模式提供了一种页面元素定位和业务操作流程分离的模式。当页面元素发生变化时,只需要维护对应的page层修改定位,不需要修改业务逻辑代码。
-
PO核心思想是分层:实现脚本可复用性,易维护性,可读性,可扩展性;主要分三层:
-
对象库层:Base(基类),封装页面一些公共的方法,如初始化方法、查找元素方法、点击元素方法、输入方法、获取文本方法、截图方法等。
-
操作层:page(页面对象),封装对元素的操作,将一个页面封装成一个对象。
-
业务层:business(业务层),将一个或多个页面操作组合起来完成一个业务功能测试。比如登录:需要输入帐号、密码、点击登录三个操作。
-
-
基于分层思想和PO设计模式,我们可以设计出基本的框架模型:
-
cases测试用例层:存放所有的测试用例
-
common公共层:存放一些公共的方法,如封装page页面基类、捕获日志等
-
datas测试数据层:存放测试数据
-
logs日志层:存放捕获到的所有日志和错误日志,便于问题定位
-
pages页面对象层:存放所有页面对象,一个页面封装成一个对象
-
reports测试报告层:存放产出的测试结果数据,失败截图
-
run用例执行层:存放测试执行文件
-
requirements.txt:记录当前项目的所有依赖包及其精确版本号,以便后续迁移项目使用。
-















 7562
7562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









