







 本文介绍了如何从2012年至2016年的地级市政府工作报告中提取经济相关高频词汇,包括数据预处理、txt和docx文件转换、以及使用jieba库进行分词和统计的Python代码。脚本涉及文件操作和Excel数据存储。
本文介绍了如何从2012年至2016年的地级市政府工作报告中提取经济相关高频词汇,包括数据预处理、txt和docx文件转换、以及使用jieba库进行分词和统计的Python代码。脚本涉及文件操作和Excel数据存储。
一、背景和功能
统计2012-2016年间各地级市政府的工作报告中在政治、经济、文化等领域的已指定高频词汇(etc.指定经济类的词汇有发展、经济建设、GDP等)

其中economy文件打开后如下,

二、存储格式
地级市分年份(不分月份了,没有删掉)
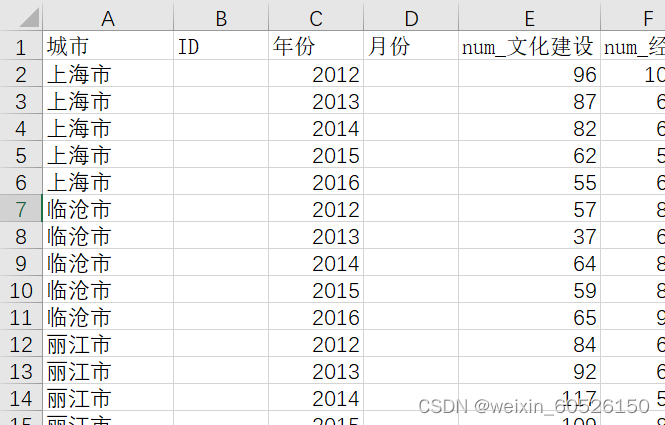
三、数据处理
如果是txt格式文档,可以直接使用,如果是docx格式文档,可以查看我的上一篇文章,有docx批量转txt的代码,转换后就可以直接使用下面的代码。
四、代码
import jieba
import os
import openpyxl
def save_city_year(city_filename, year_num):
# 打开另一个存储的Excel文件
outfile = "finaldata.xlsx"
save_wb = openpyxl.load_workbook(outfile)
save_sheet = save_wb.active
# 存储
year = int(year_num[0:4])
save_sheet.cell(row=year-2010+5*(city_num-1), column=1, value=city_filename)
save_sheet.cell(row=year-2010+5*(city_num-1), column=3, value=year)
# 保存新的Excel文件
save_wb.save(outfile)
def jiebafenci(txt, year_num, city_num):
type_num = 0; # 记录类型数量
for type_path in os.listdir(r'E:\high_frequency_words'):
if type_path.endswith('.txt'):
type_num = type_num+1;
need_words = open(type_path, encoding="utf-8").read() # 这个是要查找的词的txt文件 每个词一行
wordslist = need_words.split()
jieba.load_userdict(type_path)
words = jieba.lcut(txt)#要查找的词
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
lst = []
# 打开另一个存储的Excel文件
outfile = "finaldata.xlsx"
save_wb = openpyxl.load_workbook(outfile)
save_sheet = save_wb.active
type_word_num = 0; # 该类型的词数
for i in range(len(wordslist)):
try:
# print(wordslist[i], counts[wordslist[i]])
type_word_num=type_word_num+counts[wordslist[i]]
except:
lst.append(wordslist[i])
# print('不存在的词:', lst)
#存储
year = int(year_num[0:4])
save_sheet.cell(row=year-2010+5*(city_num-1), column=type_num+4, value=type_word_num)
# 保存新的Excel文件
save_wb.save(outfile)
if __name__ == '__main__':
root_folder = r'E:\high_frequency_words\地级市政府工作报告'
city_num=0;
# 确保指定的文件夹存在
if not os.path.exists(root_folder):
print("指定的文件夹不存在。")
else:
# 遍历Word文档文件夹中的所有Word文档
for province_filename in os.listdir(root_folder):
print(province_filename)
if province_filename.endswith("省") or province_filename.endswith("市") or province_filename.endswith("区"):
province_folder = os.path.join(root_folder, province_filename)
for city_filename in os.listdir(province_folder):
if city_filename.endswith("市"):
city_num=city_num+1;
city_folder = os.path.join(province_folder, city_filename)
for txt_name in os.listdir(city_folder):
# print(txt_name)
if txt_name.endswith('2012.txt') or txt_name.endswith('2013.txt') or txt_name.endswith('2014.txt') or txt_name.endswith('2015.txt') or txt_name.endswith('2016.txt'):
txt_path = os.path.join(city_folder, txt_name)
# print(txt_path)
txt = open(txt_path, encoding="utf-8").read() # 'wuxi.txt' 更换你的文件(txt格式)
jiebafenci(txt, txt_name, city_num)
save_city_year(city_filename, txt_name)















 2843
2843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









