






排序:快排,归并
二分:整数二分,浮点数二分
有单调性一定可以二分
浮点数二分
本质上也是一个边界,区间在 [ l,r ] 之间,找一个性质,使得整个区间左半边是满足这个性质的,右半边是不满足这个性质的,就可以通过二分把这个边界找出来

浮点数二分没有整数,每次区间长度一定可以严格缩小一半,不需要处理边界,一定要时时刻刻保证答案在区间内部,一开始可能在 l ~ r,每次通过中间点判断答案落在哪一半边,只要保证每一次答案落在区间中就可以了,当区间长度很小的时候,就可以认为我们找到了答案
当整个浮点数二分区间的长度 r - l 已经 ≤ 10^-6(就可以把它当做一个数了),可以用 l 或者 r 当做答案
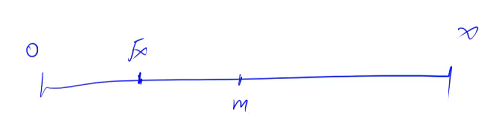
输入一个正的浮点数,求它的平方根
在计算机中并不能很好地表示一个浮点数:总会有误差,为了防止误差出现,可以把精度提高一些
如果题目要求保留四位小数:1e-6 保留五位小数:1e-7 保留六位小数:1e-8
至少要比要求的有效位数多 2
注意:如果所求的数小于 1,需要把右边界 + 1
答案在 [ 0,x ] 内部,每次找中间点,如果 mid * mid >= x,说明 mid 在 [ √x,x ] 这个区间内部,就把答案从 [ 0,x ] 缩小成 [ 0,m ]
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
double x;
cin >> x;
//答案区间
double l = 0, r = x;
//如果 x 小于 1
if (x < 1) r += 1;
//区间长度大于1e-8就一直做
while (r - l > 1e-8)
{
//每次找中间点
double mid = (l + r) / 2;
//不需要处理边界
if (mid * mid >= x) r = mid;
else l = mid;
}
printf("%lf", l);
return 0;
}不用精度来表示迭代,直接循环 100 次( 相当于把整个区间的长度 / 2^100 )也可以
循环 n 次,相当于把整个区间的长度 / 2^n
#include <iostream>
#include <cstdio>
using namespace std;
int main()
{
double x;
cin >> x;
double l = 0, r = x;
if (x < 1) r += 1;
for(int i = 0;i < 100;i++ )
{
double mid = (l + r) / 2;
if (mid * mid >= x) r = mid;
else l = mid;
}
printf("%lf", l);
return 0;
}快排
基于分治的思想
假设要排序的区间为 L ~ R
①确定分界点 x:在数组中找一个值作为分界点,取左边界q[ L ]、取中间值 q[( L + R ) / 2]、取右边界q[ R ]、随机
②调整区间:把整个区间根据 x 的值划分为两个部分,这两部分划分的长度不一定相等,使得第一个区间里面的所有的数都 ≤ x ,第二个区间里面的所有的数都 ≥ x,分界点的数不一定是 x(如果这个数和 x 相等,在左边和右边都是可以的)
③递归处理左右两段
递归给左边排序,然后递归给右边排序,左、右两边排好序后,整个区间就是有序的(左边的最大值小于右边的最小值,左右两边分别排好序,整个区间就是有序的)

实现方式 1
不需要开辟额外的空间:用两个指针,一个左指针 i,一个右指针 j,这两个指针分别往中间走,i 先往中间走,只要 i 指针指向的这个数如果小于 x 的话,就往中间走,(说明这个数最终应该在左半边,不需要移动,i 就往后移动一位),i 一直移动,直到某一次 i 所指向的数大于等于 x(说明这个数应该放在右半边),i 就停止移动;再去移动 j,如果 j 指向的数要大于 x 的话(这个数就应该放在右半边,不需要移动),j 就一直往中间走,直到 j 所指向的数小于等于 x 为止( j 指向的就应该放在左半边)

此时,两个指针指向的数:i 指针指向的数需要放在右半边,j 指针指向的数需要放在左半边,两个数都错位了,只需要把两个数的位置交换就可以了,交换后,i 指向的数就变成小于等于 x 的数,j 指向的数就变成大于等于 x 的数,此时两个指针指向的数都已经放好位置了,i 和 j 继续往中间走,直到 i 和 j 相遇为止,相遇后就可以把整个区间一分为二了

为什么这样分析是正确的?
在任何时刻,i 左边所有的数一定是小于等于 x 的(如果这个数小于 x 的话,i 就会直接跳到下一个数,如果交换完之后,交换过来的数也一定是小于等于 x 的),同理,j 右边所有的数都是大于等于 x 的,因此当两个指针相遇后,这两个指针左边的数都是小于等于 x,右边的数都是大于等于 x
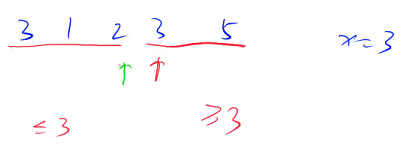
分析示例
分界点 x = 3,一开始两个指针分别指向第一个数和最后一个数
i 指针指向的这个数 3 不满足小于 3,i 指针停下来,看 j 指针指向的这个数大于 3,因此 5 就已经放好位置了,j 往前移动一位,移动一位后,j 指针指向的这个数不大于 3,停下来,把 i 指针指向的数 3 和 j 指针指向的数 3 交换,交换后两个指针分别往中间移动一位,再看 i 指针指向的数是 1,满足小于 3,因此 1 就已经放好位置了,i 指针往后移动一位,两个指针同时指向 2,2 也满足小于 3,i 指针继续往后移动一位,i 指针指向 3 的时候,3 不满足小于 3,i 指针停止移动,再看 j 指针,2 不满足大于 3,j 就会停下来,两个指针都已经穿过了,因此此时不能交换这两个数

左边所有的数都是小于等于 3,右边所有的数都是大于等于 3,可以发现 i 指针前面所有的数都是小于等于 3 的(不包括 i),并且 j 指针后面所有的数都是大于等于 3 的
实现方式 2
①开两个额外的数组 a[ ]、b[ ]
②扫描整个区间 q[L~R],扫描区间中的每一个数,如果当前这个数 ≤ x,就把它插到 a[ ] 里面,如果当前这个数 > x,就把它插到 b[ ] 里面
③先把 a[ ] 中的数放到 q[ ] 里面,再把 b[ ] 中的数放到 q[ ] 里面,满足 a[ ] 里面所有的数都 ≤ x,b[ ] 里面所有的数 > x
暴力做法:由于需要用到两个额外的空间,但是从时间复杂度上讲也是线性的,虽然一共扫描了两遍,但是两遍也是 O( n ) 的(时间复杂度不考虑常数)
当输入的数据范围比较多的时候,要选择一种比较快的输入方式,建议用 scanf,不建议用 cin

两个指针分别指向两个边界的两侧:为什么不是 i 指向 l,j 指向 r ?每次交换完两个指针后,这两个指针都需要往中间移动一格,循环的时候可以先把两个指针往中间一格再进行判断,因此两个指针需要先放在两个边界的左右两侧一格,再往中间移动一格之后,才可以指到真正的边界
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int n;
int q[N];
void quick_sort(int q[],int l,int r)
{
//如果区间里面没有数或者只有一个数的话就不用排序了:一定是有序的
if(l >= r) return;
//确定分界点x 两个指针分别指向两个边界的两侧
int x = q[l],i = l - 1,j = r + 1;
//每次移动再交换
while(i < j)
{
//q[i] < x说明q[i]已经站好位置 i一直往后移动 直到q[i] > x为止
do i++ ; while(q[i] < x);
do j-- ; while(q[j] > x);
//如果两个指针还没有相遇就把它们交换一下:i指针指向的数放在后面 j指针指向的数放前面
//swap交换两个数
if(i < j) swap(q[i],q[j]);
/*
{
int t = q[i];
q[i] = q[j];
q[j] = t;
}
*/
}
//递归处理左右两段
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
int main()
{
//读入所有的数据
scanf("%d",&n);
for(int i = 0;i < n;i++ ) scanf("%d",&q[i]);
//调用模板
quick_sort(q,0,n-1);
for(int i = 0;i < n;i++ ) printf("%d ",q[i]);
return 0;
}归并
基于分治,但是分治的方法和快排不一样
快排:用一个数作为分界点,分完之后,左边都是小于等于这个数,右边都是大于等于这个数的
归并排序以中间点作为分界线,先递归处理,分成左边和右边,再做合并
①确定分界点 mid = (left + right) / 2,分界点是整个数组中间的位置:下标的中间值,快排的分界点是随机数组里面一个值
②递归排序 left、right,排序后左右两边就变成两个有序的序列
③归并 把两个有序数组合并成一个有序数组

假设已经有两个有序的序列,用两个指针分别指向这两个序列开始的位置,创建一个新数组 res 记录答案,由于第一个数组是从小到大排好序的,因此第一个指针指向这个点就是第一个序列的最小值,第二个指针指向这个点就是第二个序列的最小值,再比较这两个数的大小,较小的那个就是两个序列总共的最小值。
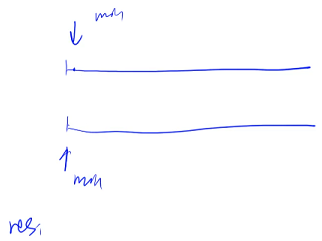
假设第一个指针更小,就把第一个数拿过来放到 res 中,把第一个指针往后移动一位(第一个指针是第一个序列里面剩下的所有数的最小值;第二个指针是第二个序列里面剩下的所有数的最小值),因此,两个最小值再次做比较,这两个指针里面的较小值就是当前剩下的数里面的最小值,把它放到 res 中,以此类推,两个指针一直往后走,直到有一个指针走到终点为止:假设第一个指针到达终点,第二个指针走到了一半的位置,这时,循环就可以退出了,最后再把后面这一段直接补到答案数组中即可
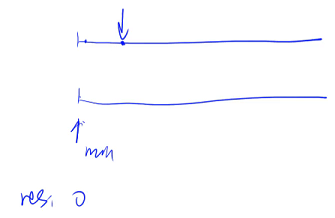
如果第一个数组先循环完,第一个数组的最后一个值一定是小于第二个指针当前指向的这个值(否则的话会把更小的值输出),由于第二个数组是排好序的,第二个数组前面的值一定比后面的值更小,把第二个数组剩余部分的值直接补到 res 后面即可
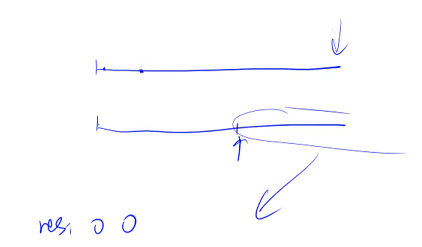
示例
第一个序列是:1 3 5 7 9,第二个序列是:2 4 5 8 10,两个指针分别指向第一个序列和第二个序列,首先这两个指针一开始是 1 和 2,因此把 1 放到 res 数组中,把第一个指针往后移动一位;此时第二个指针比第一个指针更小一些,因此把 2 放到 res 数组中,把第二个指针往后移动一位. . .以此类推,当两个值相同的时候,把两个指针的哪个数移到后面都是可以的,一般情况下是把第一个序列的数移到后面去(归并排序是稳定的)


一个排序算法是稳定的,并不是说它的时间效率是稳定的,稳定是指:如果原序列中两个数的值是相同的,它们在排序之后,它们的位置如果不发生变化的话,那么这个排序就是稳定的;它们的位置如果可能发生会变化的话,这个排序就是不稳定的
快排是不稳定的,归并排序是稳定的,快排也可以把它变成稳定的:双关键字排序,把数组的下标也放进来,此时快排数组里面的每一个数的值都不同,因此一定是稳定的
归并排序:先把左边排好序,再把右边排好序,两个有序序列可以合二为一(把两个有序序列合并成一个有序序列),合二为一的过程当中:每一个指针扫描的时候,第一个指针最多只会扫描左边这半边,第二个指针最多只会扫描右边这半边,因此两个指针扫描的总共的长度是 O( n ),这一步的时间复杂度为 O( n ),每一个元素只会被比较一次、只会被移动一次


快排的时间复杂度是指平均时间复杂度,并不是正好 O( nlogn ),最坏的时间复杂度是 O( n^2 )
归并排序的时间复杂度就是 O( nlogn )
归并排序的时间复杂度分析
归并排序一开始区间长度是 n,整个递归的第二层是两个 2 / n 的区间,第三层是四个 4 / n 的区间. . .以此类推,最后是 n 个长度是 1 的区间
n / logn = 1,因此总共有 logn 层,每一层的时间复杂度都是 O( n ),总共的时间复杂度 O( nlogn )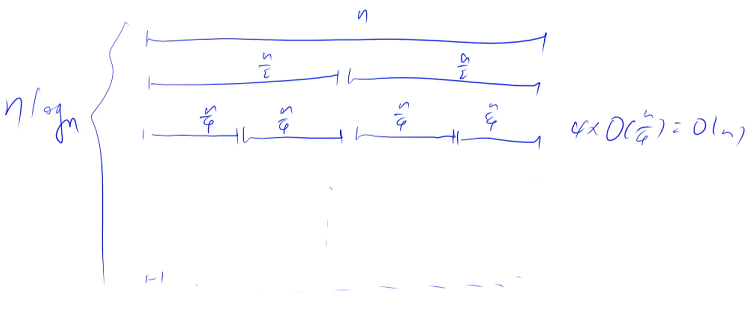
快排的时间复杂度分析
虽然我们每次划分的区间不一定是恰好 2 / n,但是期望是 2 / n,整个递归的层数也是期望是 logn,每一层是 O( n ),一共 logn 层,总共的时间复杂度是 O( nlogn )

#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 100010;
int n;
//需要一个数组存储最终把两个序列合并成一个序列之后的结果
int q[N],tmp[N];
//q[]要排序的数组 l左边界 r右边界 i指向左半边有序序列的起点 j指向右半边有序序列的起点
void merge_sort(int q[],int l,int r)
{
//如果区间里面没有数或者只有一个数的话就不用排序了:一定是有序的
if(l >= r) return;
//确定分界点:取整个区间的中点
int mid = l + r >> 1;
//递归排序左边、递归排序右边:排序后左右两边都有序了
merge_sort(q,l,mid),merge_sort(q,mid + 1,r);
//归并过程:把两个有序的序列归并成一个有序的序列 结果存储到tmp[]中
//k表示当前tmp里面有多少个数
//两个序列合并的时候已经合并了多少个数 i和j是两个指针分别指向左半边和右半边的起点
int k = 0,i = l,j = mid + 1;
//i<=左半边的边界 j<=右半边的边界
//左半边和右半边都没有循环为空的时候
while(i <= mid && j <= r)
//判断哪个数更小 如果q[i] <= q[j] 就把小的那个q[i]放到答案数组中
if(q[i] <= q[j]) tmp[k++] = q[i++];
//否则就把q[j]放到答案数组中
else tmp[k++] = q[j++];
//退出循环后左右两边有一边没有循环完 可能左边没有循环完或者右边没有循环完 两边都做判断 把剩下的数直接接到tmp[]后面去
while(i <= mid) tmp[k++] = q[i++];
while(j <= r) tmp[k++] = q[j++];
//由于结果存储在tmp[]中 最后还需要把结果tmp[]赋值到q[]中
for(i = l,j = 0;i <= r;i++,j++) q[i] = tmp[j];
}
int main()
{
//读入数据
scanf("%d",&n);
for(int i = 0;i < n;i++) scanf("%d",&q[i]);
merge_sort(q,0,n-1);
/* sort(q,q + n); */
for(int i = 0;i < n;i++) printf("%d ",q[i]);
return 0;
}如下图从上往下: sort、快排、归并排序的运行时间差不多

高精度加法
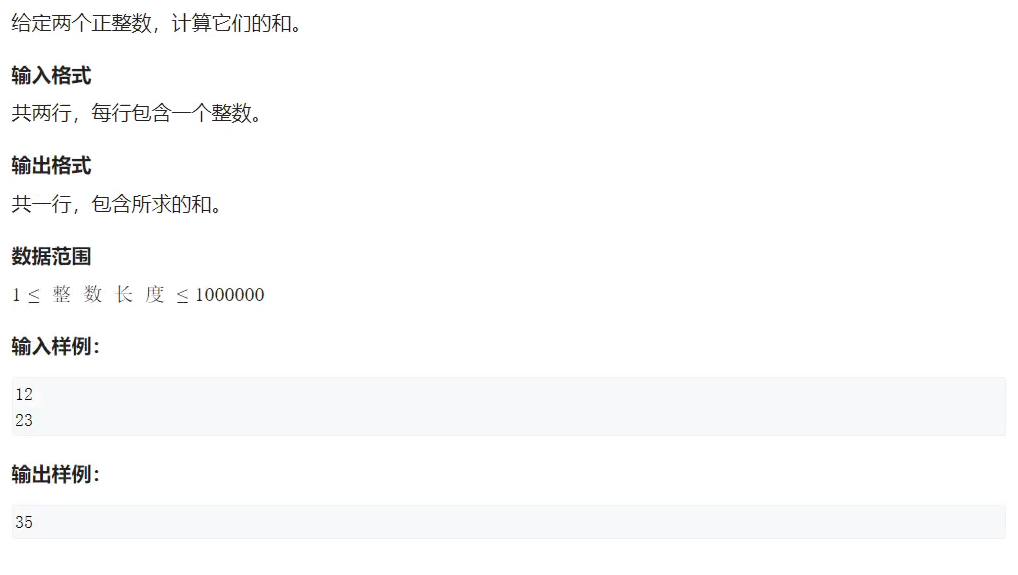
两个较大的整数相加(位数:10^6)
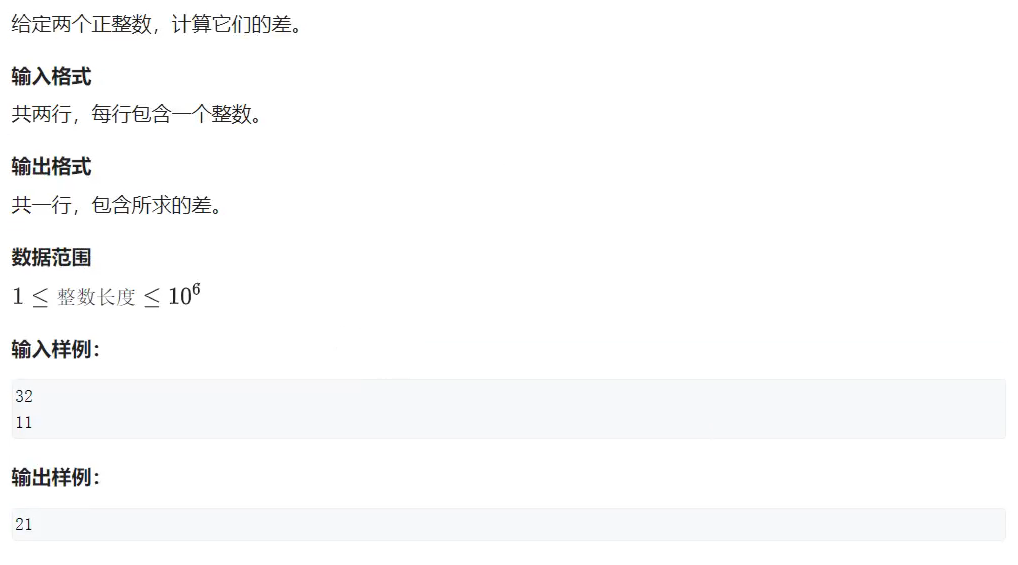
两个较大的整数相减(位数:10^6)
一个大整数 A ( 位数:A ≤ 10^6,数值:a < 10000)乘一个小整数 a
A 除以 B 求商和余数
大整数的存储
把大整数的每一位存到数组中(有一个大整数123456789,选择高位在前还是低位在前)
加减乘除中大整数的存储都是一致的
数字: 1 2 3 4 5 6 7 8 9
数组下标:[0] [1] [2] [3] [4] [5] [6] [7] [8]
存储: 9 8 7 6 5 4 3 2 1
选择低位在前,下标为 [0] 的位置存个位,下标为 [1] 的位置存十位. . .
做整数相加,相乘可能会进位,需要在高位补上一个数,只需要在数组末尾补上一个数即可,如果想在数组开头补上一个数,需要把整个数组全部往后平移一位
模拟加法:先把两个数组的个位相加,十位相加. . .
A3 A2 A1 A0
+ B2 B1 B0
————————————
C2 C1 C0
A0 + B0 大于十进一位,小于十不进位 → (A0+B0) % 10 == C0
A1 + B1 + t (上一位的进位) == C1
没有进位:0 有进位
一般多开 10 个空间,防止出现边界问题:const int N = 1 e6 + 10;
#include <iostream>
#include <cstdio>
#include <vector>
using namespace std;
//C = A + B
vector<int> add(vector<int> &A, vector<int> &B)
{
//存储结果
vector<int> C;
//用于进位-> 第0位没有进位
int t = 0;
//从个位开始遍历-> 只要A或B没有遍历完就一直遍历 A0+B0,A1+B1...
for(int i = 0;i < A.size() || i < B.size();i++ )
{
//计算当前C的值-> 用t来表示A0,B0,t的和C0
if(i < A.size()) t += A[i];
if(i < B.size()) t += B[i];
//当前位
C.push_back(t % 10);
//t>=10进位 t<=10为0
t /= 10;
}
//最高位是否需要进位
if(t) C.push_back(t);
return C;
}
int main()
{
string a,b; //字符串读入
vector<int> A,B;
cin >> a >> b;//a="123456" //逆序遍历字母转数字
//把字符串A的每一位拿出来放在vector数组中
for(int i = a.size()-1;i >= 0;i--) A.push_back(a[i] - '0'); //A=[6,5,4,3,2,1]
for(int i = b.size()-1;i >= 0;i--) B.push_back(b[i] - '0');
auto C = add(A,B);
for(int i = C.size()-1;i >= 0;i--) printf("%d",C[i]); //逆序输出-> 先输出最高位,再输出次高位
}高精度减法
1 2 3
- 8 9
——————
3 4
A3 A2 A1 A0
- B2 B1 B0
———————————
如果 A 数组表示的数 ≥ B 数组表示的数,A - B
如果 A < B,-(B - A)
Ai - Bi - t (借位,t == 0:没有借位,t == 1:有借位) ≥ 0,直接减 Ai - Bi - t
Ai - Bi - t (借位) <0,Ai - Bi + 10 - t
借位指的是借给下一位
两个大整数相减,如果存在负数,可以转换为 | A | - | B | 或者 | A | + | B | 的情况
用 (t +10) % 10 替换两种情况:
① t ≥ 0,t
② t < 0,t + 10
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
//判断是否A≥B
bool cmp(vector<int> &A, vector<int> &B)
{
//先判断两个数的位数-> 位数不同,如果A的位数大则A>B
if(A.size()!= B.size()) return A.size() > B.size();
//位数相同比较两个数的大小-> 从高位开始比较,高位相同,比较次高位,直到找到一位不相同为止,所有位相同则A == B
//逆序存储-> 高位在最后一位,找到第一位不相等的,如果A比较大则A>B
for(int i = A.size() - 1;i >= 0;i-- )
if(A[i] != B[i])
return A[i] > B[i];
//所有位数的数都相等 A == B
return true;
}
//C = A - B
vector<int> sub(vector<int> &A, vector<int> &B)
{
//存储结果
vector<int> C;
//从个位开始
//已经保证A ≥ B
for(int i = 0,t = 0;i < A.size();i++)
{
//计算当前位的值 t = A[i] - B[i] - t
t = A[i] - t;
//判断B是否存在-> B可能没有这一位,没有就是0,B的位数比A的位数少
if(i < B.size()) t -= B[i];
//当前位
C.push_back((t + 10) % 10);
//判断是否需要借位
if(t < 0) t = 1;
else t = 0;//不需要借位
}
//123 - 120 == 003 如果直接返回,A有多少位C就有多少位,需要去掉前导0
//>1如果123 - 123 == 0 如果结果只有一位是0,需要保留一位 其他情况: 如果最后一位等于0,把最后一位干掉
while(C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
int main()
{
string a,b;//字符串读入
vector<int> A,B;
cin >> a >> b;//a="123456" 把字符串A的每一位拿出来放在vector数组中,逆序遍历,字母转数字
for(int i = a.size()-1;i >= 0;i--) A.push_back(a[i] - '0'); // A= [6,5,4,3,2,1]
for(int i = b.size()-1;i >= 0;i--) B.push_back(b[i] - '0');
//判断哪个大整数更大
if(cmp(A, B))
{
auto C = sub(A,B);
for(int i = C.size()-1;i >= 0;i-- ) printf("%d",C[i]); //逆序输出-> 先输出最高位,再输出次高位
}
else
{
auto C = sub(B,A);
printf("-");
for(int i = C.size()-1;i >= 0;i-- ) printf("%d",C[i]); //逆序输出-> 先输出最高位,再输出次高位
}
return 0;
}















 5541
5541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











