






&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞
Map Join
Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另外一种是Hive优化器根据参与join表的数据量大小,自动触发。
1)Hint提示
用户可通过如下方式,指定通过map join算法,并且ta将作为map join中的小表。这种方式已经过时,不推荐使用。
hive (default)>
select /*+ mapjoin(ta) */
ta.id,
tb.id
from table_a ta
join table_b tb
on ta.id=tb.id;2)自动触发
Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。
之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
但有些Common Join任务所需的表大小,在SQL的编译阶段是未知的(例如对子查询进行join操作),所以这种Common Join任务是否能转换成Map Join任务在编译阶是无法确定的。
针对这种情况,Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。最终具体采用哪个计划,是在运行时决定的。大致思路如下图所示:
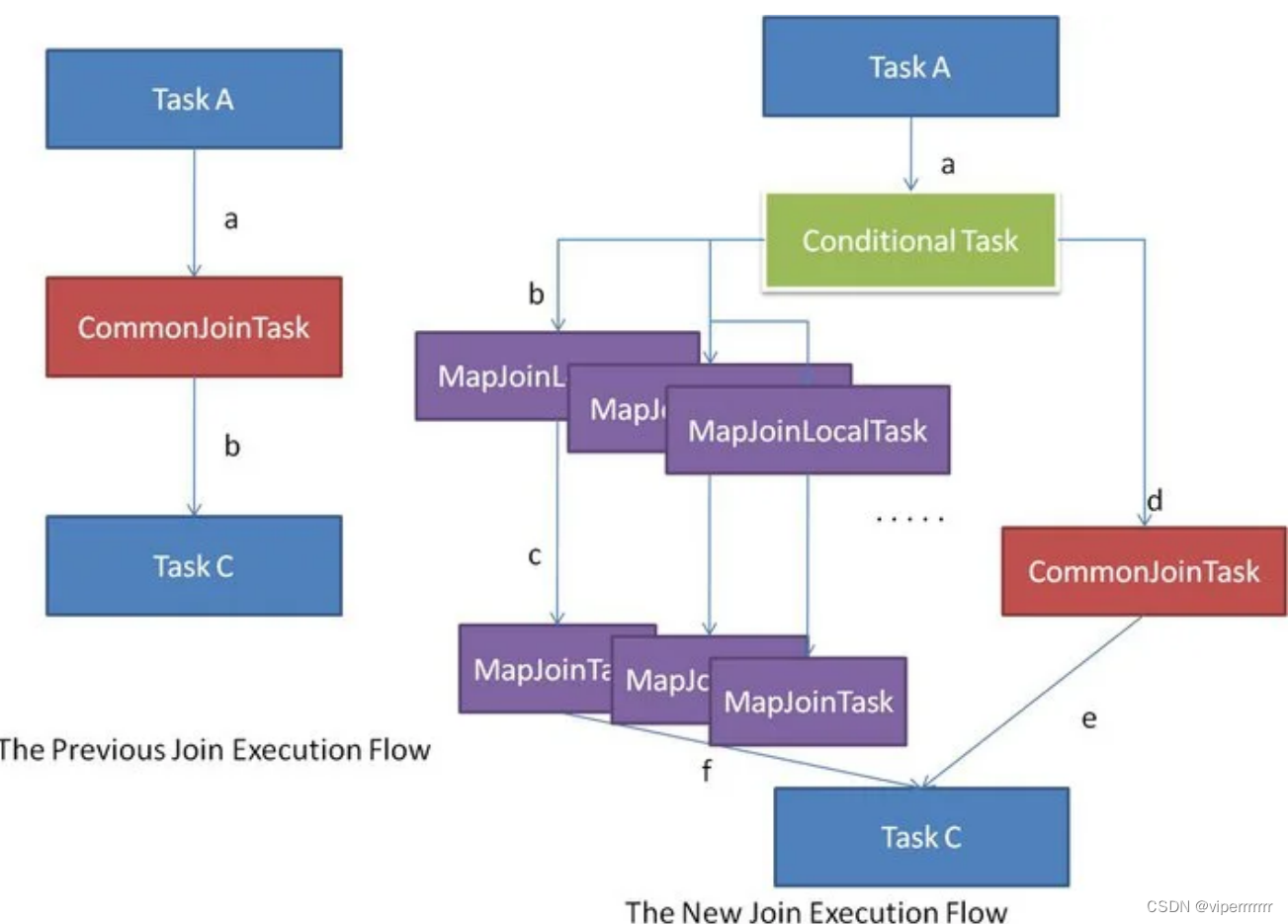
可参考参数:
--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;Bucket Map Join
Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用。
1)Hint提示
hive (default)>
select /*+ mapjoin(ta) */
ta.id,
tb.id
from table_a ta
join table_b tb on ta.id=tb.id;2)相关参数
--关闭cbo优化,cbo会导致hint信息被忽略
set hive.cbo.enable=false;--map join hint默认会被忽略(因为已经过时),需将如下参数设置为false
set hive.ignore.mapjoin.hint=false;--启用bucket map join优化功能
set hive.optimize.bucketmapjoin = true;Sort Merge Bucket Map Join
Sort Merge Bucket Map Join有两种触发方式,包括Hint提示和自动转换。Hint提示已过时,不推荐使用。下面是自动转换的相关参数:
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;12.5.4.2 优化案例
1)示例SQL语句
select
*
from(
select
*
from order_detail
where dt='2020-06-14'
)od
join(
select
*
from payment_detail
where dt='2020-06-14'
)pd
on od.id=pd.order_detail_id;2)优化前
上述SQL语句共有两张表一次join操作,故优化前的执行计划应包含一个Common Join任务,通过一个MapReduce Job实现。
3)优化思路
经分析,参与join的两张表,数据量如下
| 表名 | 大小 |
| order_detail | 1176009934(约1122M) |
| payment_detail | 334198480(约319M) |
两张表都相对较大,除了可以考虑采用Bucket Map Join算法,还可以考虑SMB Join。相较于Bucket Map Join,SMB Map Join对分桶大小是没有要求的。下面演示如何使用SMB Map Join。
首先需要依据源表创建两个的有序的分桶表,order_detail建议分16个bucket,payment_detail建议分8个bucket,注意分桶个数的倍数关系以及分桶字段和排序字段。
--订单表
drop table if exists order_detail_sorted_bucketed;
create table order_detail_sorted_bucketed(
id string comment '订单id',
user_id string comment '用户id',
product_id string comment '商品id',
province_id string comment '省份id',
create_time string comment '下单时间',
product_num int comment '商品件数',
total_amount decimal(16, 2) comment '下单金额'
)
clustered by (id) sorted by(id) into 16 buckets
row format delimited fields terminated by '\t';--支付表
drop table if exists payment_detail_sorted_bucketed;
create table payment_detail_sorted_bucketed(
id string comment '支付id',
order_detail_id string comment '订单明细id',
user_id string comment '用户id',
payment_time string comment '支付时间',
total_amount decimal(16, 2) comment '支付金额'
)
clustered by (order_detail_id) sorted by(order_detail_id) into 8 buckets
row format delimited fields terminated by '\t';然后向两个分桶表导入数据。
--订单表
insert overwrite table order_detail_sorted_bucketed
select
id,
user_id,
product_id,
province_id,
create_time,
product_num,
total_amount
from order_detail
where dt='2020-06-14';--分桶表
insert overwrite table payment_detail_sorted_bucketed
select
id,
order_detail_id,
user_id,
payment_time,
total_amount
from payment_detail
where dt='2020-06-14';然后设置以下参数:
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
最后在重写SQL语句,如下:
select
*
from order_detail_sorted_bucketed od
join payment_detail_sorted_bucketed pd
on od.id = pd.order_detail_id;优化后的执行计如图所示:
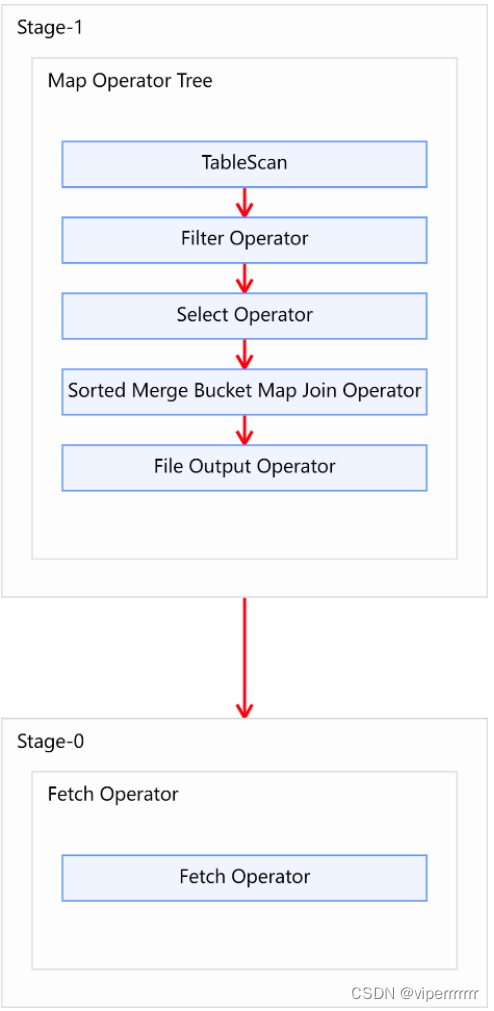
这里的每一个stage都对应一个mapreduce操作或者应该文件系统操作。















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









