







== 1. 创建数据库:==
create database<数据库名>
on[primary]
(name=<数据库逻辑文件名>,
filename=‘<数据库物理文件名>’,
size=<文件初始大小>,
maxsize=<文件最大长度>,
filegrowth=<文件容量增长速度>)['(次要数据文件的定义)]
log on(日志文件的定义)
ps:定义物理文件名即定义存储文件的路径,在文件名后加上扩展名。主要数据文件(.mdf)必须包含,且只能包含一个主数据文件;次要数据文件(.ndf)可以没有也可以有很多个;日志文件(.ldf)至少512kb。数据库里至少包含一个日志文件,可以有多个。
案例1:

2. sp_helpdb:查看当前服务器上指定数据库信息。
3. sp_database:查看当前服务器上所有可用的数据库。
4. sp _helpfile:查看当前数据库上所有的文件(数据文件、日志文件)。
5. sp_helpfilegroup:查看当前数据库上所有的文件组信息。
6. 日期函数应用例题:datepart (datepart,data)
d:表示日期
dy:一年中的第几天
w:表示周几
ww:一年中的第几周
m:月
yy:年
SELECT YEAR(‘2019-9-3’) 年份,
MONTH(‘2019-9-3’) 月份,
DATEPART(w,‘2019-9-3’)-1 星期,
DATEPART(dy,‘2019-9-3’) 本年度第多少天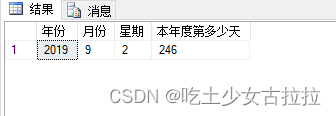
7. select ==round 按四舍五入保留小数点后n位有效数字,总位数保持不变,即32.475600 ==(32.475623,4),sign(32,3)信号函数,大于或等于1返回1小于0返回-1
8. 修改数据库:
语法格式:
sp_dboption ‘数据库名’,’修改选项‘,’修改后值‘
修改选项:single:单用户,read only:只读模式
修改后值只有如下情况:on/off ,true/false
on,true:表示启用单用户模式/只读模式,off/false:表示单用户模式/只读模式无效。
T-SQL语句:sp_dboption ‘company’,‘single’,‘true’
9. 修改数据库结构:
修改数据文件和日志文件
增加或者删除数据文件
语法结构:
alter database<数据库名>
add[log]file/filegroup<文件组>
/remove file<文件名> 删除文件
/modify file 修改文件参数
(name=<文件名>,
filename=<路径>,
size=<初始大小>,
maxsize=<最大长度>,
filegrowth=<增长速度>)
[to filegroup<文件组名>] 将新增文件加入到某个文件组中
例题:

-
数据库更名:sp_renamedb
-
压缩数据库:
dbcc shrinkdatabase(<数据库名>,<缩小后剩余的自由空间>,
(ps:被释放的文件空间依然保持在数据库范围内)/(ps:将所有未使用的数据空间释放由操作系统回收利用))
压缩数据库某文件大小:
dbcc shrinkfile (<数据库文件名>,<将文件缩小到指定长度>,
[(将指定文件上的数据全部搬运到其他文件上)],<no…>/<tr…>) -
创建备份设备:
T-sql语句:
sp_addumpdevice<‘指定设备类型’>,
<‘指定设备逻辑名’>,
<‘指定设备物理名’>
设备类型:disk(磁盘),tape(磁带),tape(命名管道)
全面备份:backup database<数据库名>
to<备份设备逻辑名>
增量/差异备份:
backup database<数据库名>
to <备份设备逻辑名>
with differential
事务日志备份:
backup log<数据库名>
to <备份设备逻辑名>
[with no_truncate]
备份后不清空原有日志数据
事务:是数据库系统中执行的一个工作单位,它是由用户定义的一组操作序列
生成冗余数据常用的技术:等级日志文件和数据转储
日志文件:用了来记录事务对数据的更新操作的文件;目的:是为数据库的恢复保留详细的数据
文件和文件组备份:
backup database<数据库名>
file <文件名>/filegroup<文件祖名>
to <备份设备逻辑名> -
数据恢复:
完整备份还原:
restore database <数据库名>
from <备份设备名>
with [<norecovery/recovery>(恢复操作是否回滚所有未提交事务)]/[replace(覆盖所有现有数据库及相关文件)]
日志备份恢复:
restore log<数据库名>
from <设备名>
with [<norecovery/recovery>]/[stopat=‘<时间>’]
数据库三类故障恢复比较:
事务故障:采用撤销未提交的事务方法来恢复数据库
系统故障:采用重做已提交的事务,撤销未提交的事务的方法恢复
介质故障:采用重新装入转储的数据库副本和重做已提交的事务的方法恢复 -
==创建存储过程:
use<数据库名>
go
create procedure<存储过程名>
@参数名 数据类型
[with encryption]
as
<关于存储过程功能的T-sql语句>存储过程中不能使用的T-sql语句:
create default,create rule,create trigger,create view -
查看存储过程:
sp_helptext 查看存储过程的代码
sp_help 查看存储过程的参数信息
sp_depends<存储过程名> 查看存储过程相关性 -
修改存储过程:
alter procedure<存储过程名>
[参数设定]/<其他约束>
as
<T-sql语句> -
创建触发器:
use<数据库名>
go
create trigger<触发器名>
on <表名>/<视图名>
[with encryption]
for [insert/updata/delete]
as
<体现触发器的功能的T-sql语句> -
查看当前服务器上所有账户:
sp_helplogins -
添加登陆账户:exec sp_addlogin ‘<账户名>’,‘<密码>’,
用create语句:create login 登录名
with password=‘<密码>’
修改登录名和密码:
alter login 登录名
with<修改项>
删除:
sp_droplogin’登录名’
drop login登录名
创建用户账户:
sp_grantdbaccess
[@loginame=]‘sql登陆账户名/NT用户’
[@name_in_db=]‘与登陆账户相匹配的用户账户’
eg:use<数据库名>
create user<用户账户名>
for login <登录名>
修改数据库用户:
with<修改项>
删除用户账户:
sp_revoredbaccess’用户账户名’
在固定服务器角色中添加成员:
sp_addsrvrolemember[@loginame=]‘登录名称’,[@rolename=]‘角色名称’
sp_addrole’自定义角色名’
增加数据库角色成员:
sp_addrolememeber’角色名’,‘用户账户名’ -
创建表: use<数据库>
go
create table<表名>
(<字段名><数据类型>[约束],
<字段名><类型>约束)
foreign key(外键约束)
格式:foregin key references<参照表>(参照字段)
check (约束条件)核查约束
default(默认值)默认值约束
修改表结构:
use<数据库名>
go
alter table<表名>
add<新列名><数据类型><完整性约束> 增加某一列
/drop column <字段名> 删除字段
/add constraint <约束名><约束定义> 在某字段增加约束
/drop constraint<约束名> 删除某字段约束
/alter column<字段名><修改后数据类型>修改数据类型
删除表:
drop table <数据库名>.dbo.<表名>
查看:
sp_help<表名> 数据列信息
sp_spaceused<表名> 行数,存储信息
sp_depends<表名> 表与视图,存储过程,触发器依赖关系
查询的格式:
use<数据库名>
go
select <查询对象>
from <查询处>/>多表连接>
[where(查询案件)] ABS升序
[分组/排序/having子句/compute/compute…by…]DESC降序 -
多表连接时的格式:
<表1>join <表2> on <公共字段的连接> join <表3> on <公共…> -
select 查询。输出
-
==表的更新操作:
插入元组:
insert
into<表名>[(列名1)…(列名n)]
values (插入值<1…n>),[(n个元组)]
插入子查询结果:
insert
into<表名>[(列名1)…(列名n)]
<子查询>
修改操作:
updata<修改对象所在表名>
set <列名>(ps:修改对象)=<表达式>(修改结果)
[from<多表连接>]
where<修改条件>
删除操作:
delete<删除对象所在的表>
[from<多表连接>]
where<删除条件>
清空操作:
truncate table<表名>
/Delete from<表名> -
适合创建索引的情况:
- 经常在where语句中出现的列
- 在order by 子句种使用的列
- 是外键或主键的列
- 该列的值唯一的列
-
创建索引:
create <索引类型> index<索引名>
on<表名>(<列名1>[asc/desc]…<列名n>[asc/desc]
with [pad_index(ps:指定索引中间级每个员(节点)上保持开发空间)],[fillfactor=<数据>(ps:指定每个索引员数据占索引页大小百分比)]
索引类型:unique,clustered,nonclustered
删除索引:
drop index <表名>,<索引名> -
创建视图:
use<数据库名>
go
create view<视图名>[(列名1)…(列名n)]
[with encryption]对试图源代码的加密
as
<包含在视图中属性列的子查询>
[with check option]更新是满足视图定义条件 -
子查询中不含以下语句:
compute,compute by,into,order by,dinstinct短语
create view <视图名>后的列名不能省略情况:
子查询中查询对象有集函数,表达式,常量
子查询是多表查询,视图中引用的表属性列有重名情况
对原表的属性列启用新名字作为视图中列名 -
查看视图定义:
exec sp_helptext<视图名>
exec sp_depends<名>
重命名视图:
sp_rename ‘原’,‘新’
修改视图:
alter view <视图名>[(列名1)…]
[with encryption]
as
<子查询>
[with check option]
删除视图:
drop view <视图名1>… -
所有权限:all privileges
授予权限:
grant<权限1>
[on<对象名>]
to<用户1>
[with grant option]获取权限的用户特权限授予他人
收回权限:
revoke<权限1>
[on<对象名>]
from<用户1>
eg:
use pubs
go
revoke all privileges
on tb_pubinfo
from public
禁止权限:
deny<权限1>
[on<对象名>]
to<用户1> -
在数据库设计过程中的数据需要借助于数据字典来描述,数据和处理的关系用数据流图表达。
数据字典是系统中各类数据描述的集合,时进行详细的数据收集和数据分析所获得的主要成果。 -
数据抽象方法:
分类:分类抽象了对象值和型之间的“成员”的语义。
聚集:抽象了对象内部类型和对象“组成部分”的语义。
概括:抽象了类型之间的“所属”的语义,概括的一个中国要性质是继承性。 -
以下是一些具体的T-SQL查询操作示例:
1. 单表查询: - 查询员工表中的所有数据:`SELECT * FROM Employees` - 查询员工表中的员工姓名和工资:`SELECT Name, Salary FROM Employees` - 查询员工表中工资大于5000的员工:`SELECT * FROM Employees WHERE Salary > 5000` - 查询员工表中姓氏以"Li"开头的员工:`SELECT * FROM Employees WHERE LastName LIKE 'Li%'` - 查询员工表中的员工总数和工资总和:`SELECT COUNT(*), SUM(Salary) FROM Employees` 2. 多表查询: 假设有两个表:Employees(员工表)和 Departments(部门表),它们之间通过 DepartmentId 列进行连接。 - 查询员工表和部门表中所有员工的信息: - `SELECT * FROM Employees INNER JOIN Departments ON Employees.DepartmentId = Departments.DepartmentId` - 查询员工表和部门表中所有员工以及所在部门名称: - `SELECT Employees.*, Departments.DepartmentName FROM Employees INNER JOIN Departments ON Employees.DepartmentId = Departments.DepartmentId` - 查询员工表中的员工以及对应部门的名称,如果没有对应部门则显示"无部门": - `SELECT Employees.*, ISNULL(Departments.DepartmentName, '无部门') FROM Employees LEFT JOIN Departments ON Employees.DepartmentId = Departments.DepartmentId` 3. GROUP BY 和 HAVING: 假设有一个订单表 Orders,其中包含订单号(OrderId)、客户号(CustomerId)和订单金额(Amount)等列。 - 按客户号分组并统计订单数: - `SELECT CustomerId, COUNT(*) FROM Orders GROUP BY CustomerId` - 按客户号分组并统计订单数,只显示订单数大于等于3的客户: - `SELECT CustomerId, COUNT(*) FROM Orders GROUP BY CustomerId HAVING COUNT(*) >= 3` 4. ORDER BY: - 按员工工资升序排序:`SELECT * FROM Employees ORDER BY Salary ASC` - 按员工工资降序排序,并按员工姓名升序排序:`SELECT * FROM Employees ORDER BY Salary DESC, Name ASC`














 3670
3670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









