






思考题汇总
Thinking 1.1
ld命令
简介
ld命令式二进制工具集GNU Binutils的一员,是GNU连接器,用于将目标文件和库连接为可执行程序或库文件。
命令格式
ld [OPTIONS] OBJFILES
readelf命令
简介
readelf是一个Linux下的命令行工具,用于显示ELF(Executable and Linkable Format)格式的可执行文件、共享库和目标文件的信息,包括头部信息、节区信息、符号表等等。
指令
readelf -h:elf header,头文件信息;
readelf -l:program headers,显示程序头 (段头) 信息;
readelf -S:section headers,显示节头信息;
readelf -s:symbols,显示符号表段中的项;
readelf -r:relocs,显示可重定位段的信息;
readelf -d:dynamic,显示动态段的信息;
readelf -V:version-info,显示版本段的信息;
readelf -A:arch-specific,显示CPU构架信息;
readelf -I:histogram,显示符号的时候,显示bucket list长度的柱状图;
readelf -a,all 显示全部信息,等价于 -h -l -S -s -r -d -V -A -I。
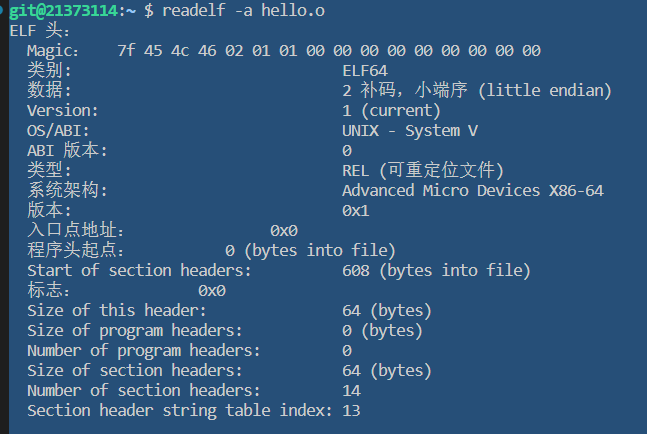
执行
readelf -a hello.o
readelf -S hello.o

objdump命令
简介
objdump命令是Linux下的反汇编目标文件或者可执行文件的命令,它以一种可阅读的格式让你更多地了解二进制文件可能带有的附加信息。
参数选项
以hello.c代码为例

gcc -c hello.c -o hello.o
-a
显示档案库的成员信息,类似于ls -l
-s 显示指定section的完整信息,默认所有的非空section都会被显示
-g 显示调试信息
-j name
仅仅显示指定名称为name的section信息

-d
从objfile中反汇编那些特定指令机器码的section

Thinking1.2
tools/readelf目录下的Makefile文件如下所示

-m32 生成32位的代码
-g 生成调试信息
-static 进行静态链接,是程序不在依赖动态库。
我们使用的linux默认编译的代码为64位。而编译hello的时候为32位。
所以readelf和hello之间的差距在于gcc编译代码的位数。
当运行
readelf -S hello
得到:

运行
readelf -S readelf
得到:

运行
readelf -h hello
readelf -h readelf
可以看到hello位32位,readelf为64位。
在elf.h文件中,对elf文件的定义都是32位,所以readelf.c能读取的elf文件也是32位。根据上面的数据就可以明白为什么可以解析hello而不能解析readelf。
难点分析
在Exercise 1.1中,需要输出所有节头的代表序号和地址,这个的难点主要是明白节表头的意义,节表存放的是每一个节头的信息,包括name、type、addr、offset等等,
Exercise 1.2中,需要补全kernel.lds中空缺的部分,该联系比较简单,只需要明白如何将.text .data .bss 填补到正确的位置即可。
Exercise 1.3 该部分需要设置正确的栈指针,并跳转到mips_init函数中,首先需要找到kernel stack的位置,可以看到kernel stack的最高地址为0x8040_0000,而栈又是往下增长的,所以只需要将sp设置为0x8040_0000即可
lui sp,0x8040

Exercise 1.4需要我们自己完成一个printk函数,其实完成的部分本质上是解析一个字符串,printk格式为:

从最开始进行遍历,如果没有遇到%和\0,那么直接输出,遇到%则开始解析格式符,遇到\0则停止,跳出循环。
该代码容易错的地方在于忽略\0的判断,在碰到\0时没有及时退出循环。
实验体会
本次实验相对来说比较简单,关键是弄明白段和节之间的关系,以及他们的作用。
课上实验
本次课上分为exam和extra,其中exam只要课下没问题,课上就没有问题。
exam
exam让我们添加一个%R的格式符,让遇到该格式符则输出一对数据。比如
printk("%R\n",1023,2023); //输出为(1023,2023)其实也就是输出两个整形的变量,直接将两个变量分别输出就好。(复制一次,粘贴两次)不过在中间多了( ,)三个字符。需要注意的是,两个数的flags、width、length都是一样的,但是neg_flag可能不一样。
比如
printf("%-8R",-1,1);这两个符号不一样,所以在输出的中间需要再将neg_flag置为0,这样才能保证后面的结果正确。
extra
这个实验需要我们自己实现一个sprintf函数。
首先复习一下sprintf函数
int sprintf(char *buf , const char *fmt , ...);发送格式化输出到buf中,需要注意的是这个函数返回的是一个int,而且返回的是buf的字符数(即strlen(buf)),考试的时候,我没注意看题,直接返回0,导致第三个测试点炸了。
实现该函数还是有很多的坑。
很多人犯的错误(包括我)是最后buf的结尾没有加上\0,这个在printk中到不需要我们自己去加,但是在sprintf中必须添加,如果不添加就会让后面的字符串收到污染,举个例子。
char str[100];
sprintf(str,"abcdefg");
printk("%s\n",str);
sprintf(str,"12");
printk("%s\n",str);第一个printk输出肯定是abcdefg,这肯定没有问题,但是第二个输出就会出现问题,按理来说输出的应该是12,但结果输出的却是12cdefg。
添加这个可以在最后解析完fmt之后在buf后加上一个\0,当然还有更简单粗暴的方法:
memset(buf,0,1024);每用一次我就用\0覆盖一次,这就不会出现被污染的问题。














 4009
4009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









