







背景
想象一下,一个数据工程团队在多年的投入下,构建了一套实时流计算链路,数据仓库体系,以及数不清的报表。但随着业务的增长,他们开始不局限于传统的指标,而是希望用 AI/ML 来提供更加深入的数据分析。
MindsDB 就是填补这个需求的桥梁,它将数据库与模型训练串联起来,以一个中间件的形式帮助 AI 开发者们降低开发门槛。
MindsDB 的一个关键能力就是对许多数据源的支持,包括像 PostgreSQL、MySQL 等关系数据库。它统一了数据接入层,这样一来大家就不再需要用好几种不同的工具来处理数据。
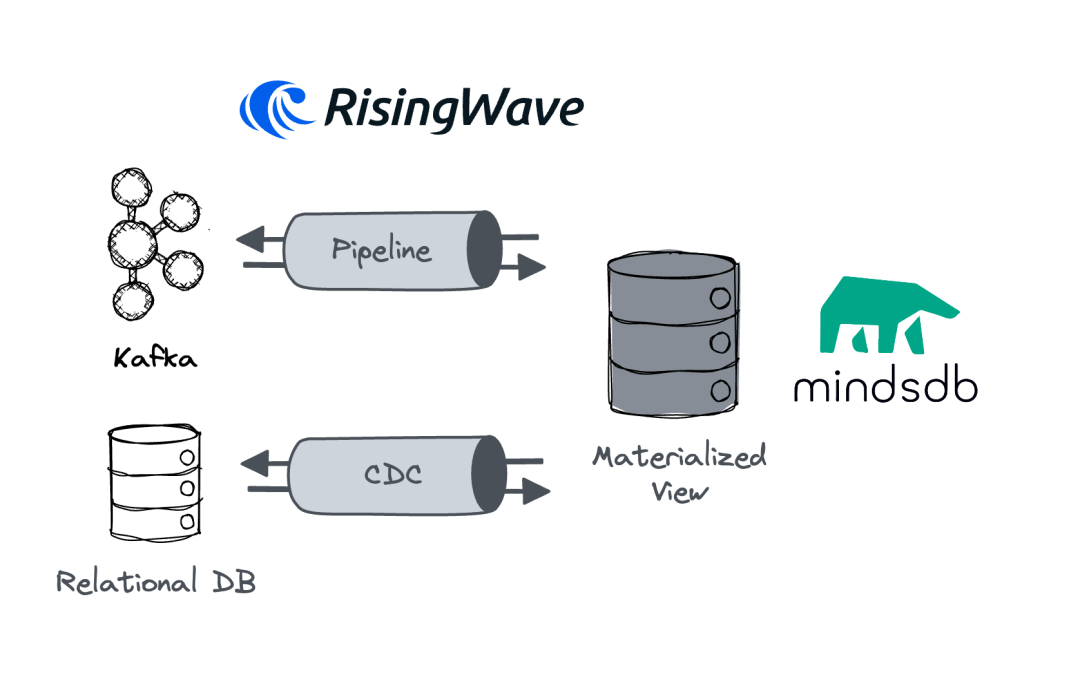
在这一理念下,MindsDB 对 RisingWave 的支持也变得理所应当。对开发者而言,RisingWave 与 MindsDB 的集成打开了一些独特的机会:
-
训练你的流式数据:RisingWave 核心的物化视图概念给予了用户对流处理结果的读取能力。在模型训练阶段前,用户往往会对数据进行实时清洗和加工,或者是与多个数据源相互关联,形成更完整的数据后,再导入到模型中。RisingWave 则是统一了前期的预处理,而 MindsDB 可以通过 Postgres 接口无缝地读取 RisingWave。在这一套架构内只存在 2 个系统,这使得系统维护变得非常轻量。
-
将模型训练的负载与其他业务解耦:在行业普遍的架构中,一个系统往往只服务于一种类型的负载,如 OLAP 分析,流计算,OLTP 处理等。如果在核心的在线数据库上增加模型训练的负载,可能就会对其造成稳定性的影响。RisingWave 的存算分离架构将数据放在远端对象存储(如 S3)中,允许单独配置用于服务查询的节点,这使得后台的流计算能够与模型训练在物理上隔离,相互之间稳定性毫不影响。
接下来,我们将展示 RisingWave 如何与 MindsDB 结合来解决实际的问题。
Demo 1:帮助租房一族了解理想房型的预期租金
我们在这一 Demo 的目标是要分析所有房屋的租赁记录,并总结价格和房型之间的关系。最终,当你给出对理想房型的条件,我们的模型就能推演出预期的租金。
-
准备数据:
首先,我们推荐通过 Docker Compose 来启动 RisingWave 和 MindsDB。如果你想要亲自上手尝试,可以使用我们在这里为您准备的环境。
接着,让我们按以下表结构将一些数据导入到 RisingWave。限于篇幅,让我们先幻想数据已经准备好了吧 😉 。
CREATE TABLE home_rentals ( number_of_rooms integer, number_of_bathrooms integer, sqft integer, location varchar, days_on_market integer, rental_price integer ); -
接着,创建 MindsDB 模型。我们使用 postgres 连接器来访问:
CREATE DATABASE example_data WITH ENGINE = "postgres", PARAMETERS = { "user": "root", "host": "risingwave-standalone", "port": "4566", "database": "dev" }; CREATE MODEL mindsdb.home_rentals_model FROM example_data (SELECT * FROM home_rentals) PREDICT rental_price;在这一步,我们基于
rental_price列训练了一个回归模型(注意PREDICT关键词)。模型的训练不会在命令调用结束后立刻完成,而是需要等待一些时间。具体等待的时间取决于数据量和机器性能。您可以用DESCRIBE mindsdb.home_rentals_model命令来查看模型状态。 -
最后一步,按房型要求来推演其租金 💰 吧
SELECT rental_price FROM home_rentals_model WHERE number_of_bathrooms = 2 AND sqft = 1000; --- rental_price --- 3968在这一数据集里,两卫一千平方英尺的房型价格为 3968。
Demo 2:预测未来
相信多数使用 RisingWave 的场景都会与时间打交道。与上述步骤类似,我们同样是准备数据,训练模型,并做出推演。但不同的是,这里我们会使用 MindsDB 的时序模型。
CREATE MATERIALIZED VIEW house_sales AS
SELECT
saledate,
ma,
type,
bedrooms
...;
假设我们在 RisingWave 中已经将房型表与销售记录表进行处理,得到了一个物化视图 house_sales,其包含了过去每个季度销售额的 MA(Moving Average)值。
接下来的步骤,我们让模型预测后续趋势,即按照 saledate,预测往后 4 个季度的 MA。
CREATE MODEL mindsdb.house_sales_predictor
FROM example_data
(SELECT * FROM house_sales)
PREDICT ma
ORDER BY saledate
GROUP BY bedrooms, type
WINDOW 8
HORIZON 4;
当模型创建成功后,我们就可以按需查询。
SELECT m.saledate AS date, m.ma AS forecast
FROM mindsdb.house_sales_predictor AS m
JOIN example_data.house_sales AS t
WHERE t.saledate > LATEST
AND t.type = 'house'
AND t.bedrooms = 2
LIMIT 4;
总结
经由 RisingWave 处理的流数据在许多企业中具有非常高的分析价值。得益于 RisingWave 的存算分离架构,MindsDB 在 RisingWave 之上进行模型训练是可行且稳定的。同时,RisingWave 充分支持 PostgreSQL 接口,所以 MindsDB 能无缝地进行接入。
随着实时流处理以及 AI/ML 两个领域各自释放其动能,相信未来 RisingWave 和 MindsDB 两者的结合会为数据工程团队带来更多的价值。
往期推荐
重新定义流计算:第三代流处理系统 RisingWave 的 2024 年展望
![]()
RisingWave是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于降低流计算使用门槛。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,帮助用户轻松快速搭建稳定高效的流计算系统。使用 RisingWave 处理流数据的方式类似使用 PostgreSQL,通过创建实时物化视图,让用户能够轻松编写流计算逻辑,并通过访问物化视图来进行即时、一致的查询流计算结果。了解更多:
💻 官网: risingwave.com
✨GitHub: risingwave.com/github
📖 教程: risingwavetutorial.com


















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









