









得益于 RisingWave 和 Kafka 等流处理工具, 数据工程师能实时洞察流数据中的重要信息。这能够助力制定决策,并在多个层面改善用户体验,包括推荐系统、金融、物流、汽车、制造业、 IIOT 设备和零售。
在这篇博客中,我们会把 RisingWave 和部署在 Instaclustr 云上的 Kafka 以及 Apache Superset 结合起来,用于监控维基百科编辑情况。我们将深入了解这三个工具如何无缝集成、合作实现监控目标。
RisingWave 是一个与 PostgreSQL 兼容的流数据库,具有真正的云原生架构,拥有低成本高效益、可扩展等特点。基于 RisingWave,用户仅使用 SQL 就能从流数据中获取目标信息。
Instaclustr 是一个集成了众多流行开源工具(如 Kafka、PostgreSQL、Cassandra 和 Redis)的完全托管平台。它提供了方便的 Kafka Connect 集成,包括专用的 ZooKeeper 服务。通过这种 100% 开源方案,Instaclustr 提供了无缝使用 Kafka 的体验。
技术栈
我们将从 Wikipedia API 获取实时数据,捕获维基百科文章的编辑和贡献者信息,然后将它们发布到 Kafka Topic。
随后,数据将被导入 RisingWave。基于这些数据,我们将创建物化视图来执行一系列操作,如聚合、时间窗口操作、数据转换等,以从数据中提取有价值的信息。
最后,我们会把处理后的数据从 RisingWave 导出到 Apache Superset,从而将数据可视化,用更具体直观的方式查看贡献者们对维基百科的实时编辑。

技术栈
在 Instaclustr 云上部署 Kafka
为开始生成事件,我们需要一个 Kafka 集群。在本文的演示中,我们将用 Instaclustr 云创建一个 Kafka 集群。
创建 Kafka 集群
首先,请注册免费的 Instaclustr 账号以获得访问 Kafka 服务的权限。您可以通过访问 [Instaclustr 云] 平台来创建账户。
Instaclustr 云账户注册
接着,请参考 Instaclustr 云提供的 Apache Kafka 快速上手指南,在 Instaclustr 云上创建一个 Kafka 集群。
成功创建 Kafka 集群后,请添加您计算机的 IP 地址到集群中,以便产生和使用数据。
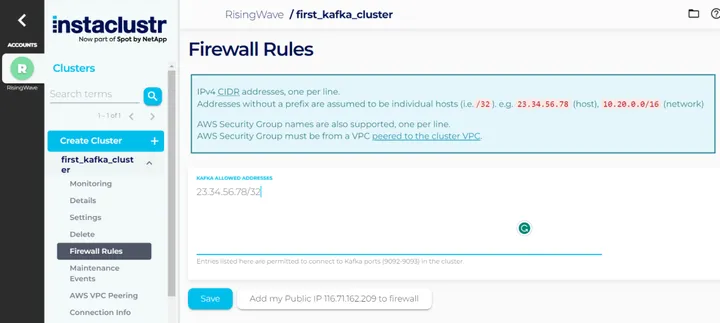
添加计算机 IP 地址到集群
将维基百科编辑数据传输到 Kafka
我们将首先使用维基百科 Python API 来获取各种信息,如用户贡献、用户详细信息和最近更改。
随后,我们会把这些数据传输到 Instaclustr 云上的 Kafka 集群中,以便后续将数据导入 RisingWave。
我们的 JSON 消息将遵循以下 schema:
"contributor": 维基百科贡献者的名字。
"title": 所编辑的维基百科文章的标题。
"edit_timestamp": 编辑的时间戳。
"registration": 该维基百科用户的注册日期。
"gender": 该维基百科用户的性别。
"edit_count": 该维基百科用户的编辑次数。
以下是一个发送到 Kafka Topic 的消息样本:
{
"contributor": "Teatreez",
"title": "Supreme Court of South Africa",
"edit_timestamp": "2023-12-03 18:23:02",
"registration": "2006-12-30 18:42:21",
"gender": "unknown",
"edit_count": "10752"
}
连接 RisingWave 与 Kafka Topic
要使用 RisingWave,请参考快速上手指南创建一个 RisingWave 集群。
随后,为了 RisingWave 和 Instaclustr 能成功连接,请先前往 Instaclustr,将您的 RisingWave 集群的 NAT 网关 IP 地址添加到 Instaclustr 云中 Kafka 集群的防火墙规则(Firewall Rules)中。这一步有利于避免潜在的连接错误。
成功创建 RisingWave 集群后,我们在 RisingWave 中创建一个 Source,用于从 Instaclustr 云中的 Kafka Topic 导入数据到RisingWave。
请使用以下查询创建一个连接到 Instaclustr 云中 Kafka Topic 的 Source,注意,各认证参数需要准确填写对应的值。
CREATE SOURCE wiki_source (
contributor VARCHAR,
title VARCHAR,
edit_timestamp TIMESTAMPTZ,
registration TIMESTAMPTZ,
gender VARCHAR,
edit_count VARCHAR
) WITH (
connector = 'kafka',
topic='Insta-topic',
properties.bootstrap.server = 'x.x.x.x:9092',
scan.startup.mode = 'earliest',
properties.sasl.mechanism = 'SCRAM-SHA-256',
properties.security.protocol = 'SASL_PLAINTEXT',
properties.sasl.username = 'ickafka',
properties.sasl.password = 'xxxxxx'
) FORMAT PLAIN ENCODE JSON;
然后,我们基于 Source wiki_source 创建一个名为 wiki_mv 的物化视图。注意,以下代码中,我们过滤掉了带有空值的行。
CREATE MATERIALIZED VIEW wiki_mv AS
SELECT
contributor,
title,
CAST(edit_timestamp AS TIMESTAMP) AS edit_timestamp,
CAST(registration AS TIMESTAMP) AS registration,
gender,
CAST(edit_count AS INT) AS edit_count
FROM wiki_source
WHERE timestamp IS NOT NULL
AND registration IS NOT NULL
AND edit_count IS NOT NULL;
现在,我们可以查询物化视图,获取 Source 中的最新数据:
SELECT * FROM wiki_mv LIMIT 5;
返回结果将类似如下:
contributor | title | edit_timestamp | registration | gender | edit_count
---------------+-----------------------------+---------------------------+---------------------------+---------+-----------
Omnipaedista | Template:Good and evil | 2023-12-03 10:22:02+00:00 | 2008-12-14 06:02:32+00:00 | male | 222563
PepeBonus | Moshi mo Inochi ga Egaketara| 2023-12-03 10:22:16+00:00 | 2012-06-02 13:39:53+00:00 | unknown | 20731
Koulog | Ionikos F.C. | 2023-12-03 10:23:00+00:00 | 2023-10-28 05:52:35+00:00 | unknown | 691
Fau Tzy | 2023 Liga 3 Maluku | 2023-12-03 10:23:17+00:00 | 2022-07-23 09:53:11+00:00 | unknown | 4697
Cavarrone | Cheers (season 8) | 2023-12-03 10:23:40+00:00 | 2008-08-23 11:13:14+00:00 | male | 83643
(5 rows)
接下来,我们再创建几个查询:
以下查询创建了一个新的物化视图 gender_mv,将物化视图 wiki_mv 中的贡献按一分钟间隔进行聚合。该物化视图计算了多个数据,包括每个时间窗口内的总贡献数、未知性别者的贡献数,以及已知性别者的贡献数。基于此物化视图,我们可以更方便地基于性别对贡献模式进行分析和监控。
CREATE MATERIALIZED VIEW gender_mv AS
SELECT COUNT(*) AS total_contributions,
COUNT(CASE WHEN gender = 'unknown' THEN 1 END) AS contributions_by_unknown,
COUNT(CASE WHEN gender != 'unknown' THEN 1 END) AS contributions_by_male_or_female,
window_start, window_end
FROM TUMBLE (wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
以下查询创建了物化视图 registration_mv ,它同样将物化视图 wiki_mv 中的贡献按一分钟间隔进行聚合,计算的信息包括:总贡献数、2020年1月1日之前注册账户的贡献数,以及2020年1月1日之后注册账户的贡献数。
CREATE MATERIALIZED VIEW registration_mv AS
SELECT COUNT(*) AS total_contributions,
COUNT(CASE WHEN registration < '2020-01-01 01:00:00'::timestamp THEN 1 END) AS contributions_by_someone_registered_before_2020,
COUNT(CASE WHEN registration > '2020-01-01 01:00:00'::timestamp THEN 1 END) AS contributions_by_someone_registered_after_2020,
window_start, window_end
FROM TUMBLE (wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
以下查询创建了物化视图 count_mv,将 wiki_mv 物化视图中的贡献按一分钟间隔进行聚合,然后计算:总贡献数、编辑次数少于 1000 次的贡献者的贡献数,以及编辑次数大于等于 1000 次的贡献者的贡献数。
CREATE MATERIALIZED VIEW count_mv AS
SELECT
COUNT(*) AS total_contributions,
COUNT(CASE WHEN edit_count < 1000 THEN 1 END) AS contributions_less_than_1000,
COUNT(CASE WHEN edit_count >= 1000 THEN 1 END) AS contributions_1000_or_more,
window_start, window_end
FROM TUMBLE(wiki_mv, edit_timestamp, INTERVAL '1 MINUTES')
GROUP BY window_start, window_end;
将数据从 RisingWave 导出到 Apache Superset 进行可视化
Superset 是一个用于创建看板和可视化内容的开源工具。接下来我们将配置 Superset,从 RisingWave 读取数据并导出到 Superset 进行可视化。
连接 RisingWave 和 Superset
请按照 RisingWave 文档中的指南,配置 Superset 从 RisingWave 读取数据。在此过程中,我们会把 RisingWave 作为数据源添加到 Apache Superset 中,并使用其中的表和物化视图创建可视化和看板。
成功将 RisingWave 连接到 Apache Superset 后,您可以按照该指南剩下部分的指导,将 RisingWave 中的物化视图作为数据集进行添加,创建表、图表和整合后的看板。
可视化结果展示:表、图表和看板
下表使用wiki_mv数据集生成,显示了 Wikipedia 贡献者的名字、注册日期、性别、编辑次数以及贡献者编辑过的 Wikipedia 文章等信息。
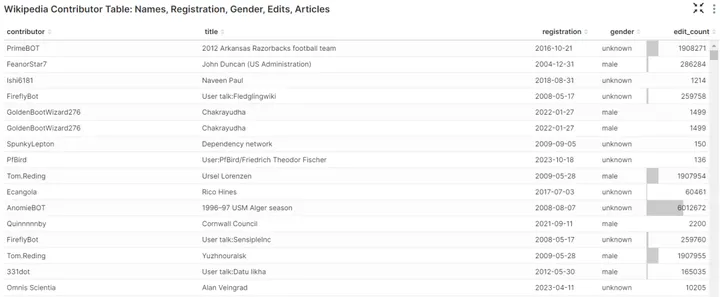
Wikipedia 贡献者表
以下面积图使用count_mv数据集创建,展示了指定时间窗口内的:总贡献数、编辑次数少于 1000 次的贡献者的贡献数,以及编辑次数大于等于 1000 次的贡献者的贡献数。
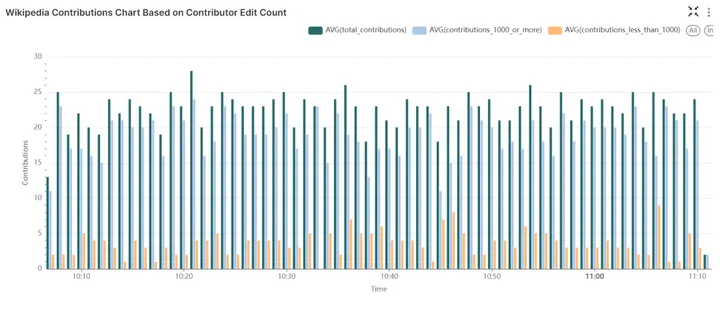
Wikipedia 贡献面积图:根据贡献者编辑次数展示贡献分布
以下折线图基于gender_mv数据集生成,展示了指定时间窗口内的:总贡献数、未知性别者的贡献,以及已知性别者的贡献。
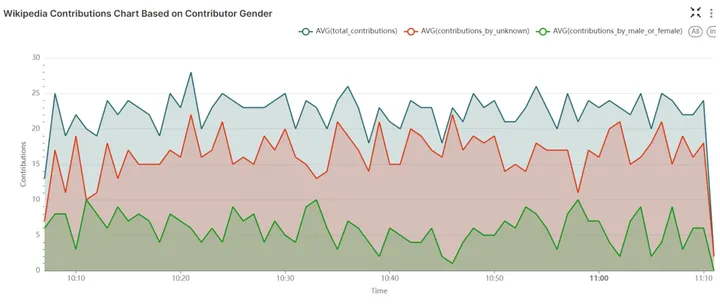
Wikipedia 贡献折线图:根据贡献者性别分析贡献模式
下图则使用registration_mv数据集创建,在 1 分钟的时间窗口内可视化了各种类型的贡献计数,包括:总贡献数、2020年1月1日之前注册的用户的贡献数,以及2020年1月1日之后注册的用户的贡献数。
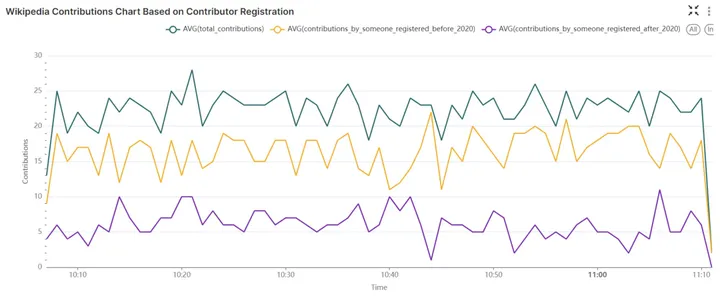
Wikipedia 贡献图:根据贡献者注册日期可视化贡献情况
最后,以下是一个整合了以上各项图表的看板,让您可以全面、实时地监控 Wikipedia 编辑信息,以全面地挖掘贡献者及其所编辑文章相关的重要信息。
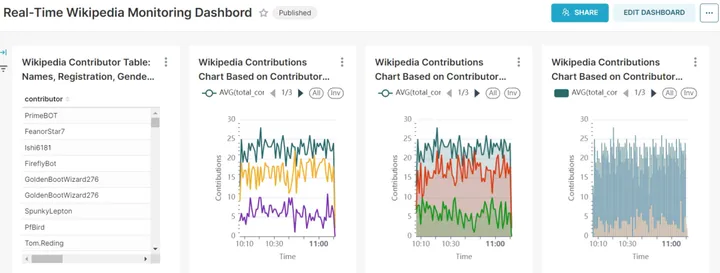
基于贡献者信息的 Wikipedia 编辑实时监控看板
结论
在这篇博文中,我们介绍了一种流处理解决方案,用于实时监控维基百科中不同贡献者对多篇文章的编辑情况。我们从维基百科 API 中提取数据,并将其传输到部署在 Instaclustr 云中的 Kafka Topic。然后,我们在 RisingWave 创建了 Source 以摄取 Kafka 数据,并创建物化视图进行处理分析。为了更具体直观地展示所得信息,我们又利用 Superset 的强大功能对结果进行可视化,生成各类图表和综合看板。至此,我们即可全面且动态地了解维基百科的编辑情况。
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。
了解更多:
官网: risingwave.com
入门教程:快速上手 | RisingWave
GitHub:risingwave.com/github
微信公众号:RisingWave中文开源社区
中文社区用户交流群:risingwave_assistant
英文社区用户交流群:https://risingwave.com/slack


















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









