







 本文深入探讨了分布式存储系统的可靠性,通过分析单服务器和多服务器的硬盘故障概率,以及泊松分布的应用,揭示了存储利用率、故障率和数据丢失率之间的关系。在单副本和多副本(如3副本和EC纠删码)模式下,详细计算了数据丢失概率,并指出随着业务规模扩大,硬件故障概率增加,但软件限制使得额外的服务器并不能显著提高可靠性。此外,还强调了部署策略和软件质量对可靠性的影响。
本文深入探讨了分布式存储系统的可靠性,通过分析单服务器和多服务器的硬盘故障概率,以及泊松分布的应用,揭示了存储利用率、故障率和数据丢失率之间的关系。在单副本和多副本(如3副本和EC纠删码)模式下,详细计算了数据丢失概率,并指出随着业务规模扩大,硬件故障概率增加,但软件限制使得额外的服务器并不能显著提高可靠性。此外,还强调了部署策略和软件质量对可靠性的影响。
阅读《分布式存储系统可靠性:系统量化估算》和《Ceph可靠性的量化分析》文章后,学习和理解了 Ceph 架构的可靠性计算逻辑。基于相关知识,结合实际系统理解,对里面的公式进行展开的解读,并基于数据分析总结几点分布式存储系统可靠性设计的关键点,和大家一起探讨。
一. 可靠性定义
在云存储领域,可靠性是指数据的不丢不错,业界常说的持久度(Durability)是指数据不丢,而数据不错是指数据翻转,例如某位从0翻转为1。数据丢失,包括硬件导致的数据丢失,以及软件 BUG 导致的数据丢失。厂家宣传的设计可靠性为11个9或者12个9,通常是指硬件导致的数据丢失。本文重点分析硬盘故障导致的数据丢失,并量化分析。
二. 单服务器的可靠性计算
(1)单副本极简模式丢数据的场景分析
基于4U36盘服务器,如图-1所示,每块盘容量为12TB,作为基准硬件进行分析。

图-1
极简模式下,数据没有冗余,按顺序存储,也就是按 D1(磁盘1)、D2(磁盘2)、...、D36(磁盘36)存放,先放D1盘,然后是D2盘,以此类推,显然有如下推论:
-
数据放满后,任意1块盘故障都会丢失数据,推论1:数据丢失和“盘故障率”相关。
-
存储量为10TB时,按数据排布算法只会存放在D1盘,只有故障D1盘才丢失数据,其他盘故障不丢失数据,推论2:数据丢失和“存储利用率和排布算法影响的丢失率”相关。
基于上述描述,可以得到如下的数据丢失概率公式:
![]()
-
表示服务器“数据丢失概率”。
-
表示服务器“故障任意一块盘的概率(包括故障多块盘)”。
-
表示服务器“存储利用率影响的丢失率”。
A. 理解年故障率 AFR
根据硬盘厂商 Seagate 的描述,“MTBF 过去被证明有用,但也存在缺陷。为了解决可靠性问题,Seagate 正在改为采用年度故障率 (AFR) 来衡量盘的可靠性”,而 AFR 的值有两个纬度来描述:
-
理论纬度常用 MTBF 来计算,当 MTBF 为2,000,000小时,AFR 为0.438%,公式如下所示:
![]()
-
统计纬度,根据实际线上运行统计的失效率,也就是基于系统的总盘数,统计一年内出现故障的盘数,得到实际的 AFR。不同的厂家、批次、负载类型,有不同的统计故障率。通常来说,“统计纬度 AFR”更具有实际指导意义,它和业务的负载紧密相关,通常在 0.5%~5% 范围内。
基于 4U36盘 服务器,假设理论 AFR为 0.5%,显然不能用“36*0.5%=0.18”来计算故障一块盘的概率,因此本文采用统计纬度 AFR 进行讨论。根据业界研究,硬盘在一定时间内的失败概率符合泊松分布,因此可以用来计算指定时间范围内的盘故障概率。
B. 理解和应用泊松分布
根据“维基百科定义的泊松分布公式”,描述为:
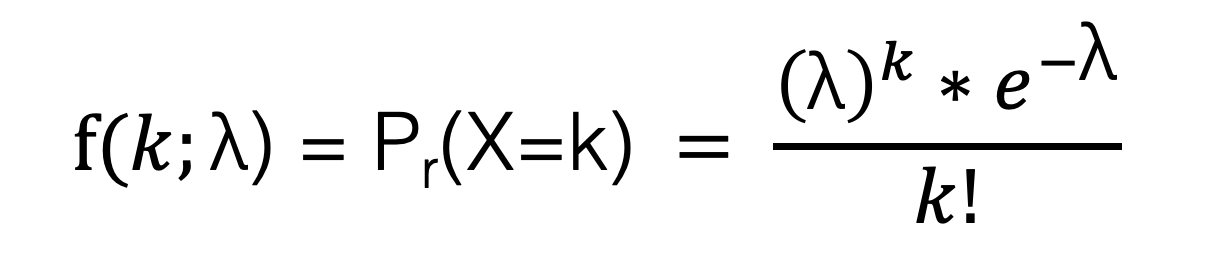
根据“知乎介绍的泊松分布公式”,描述为:
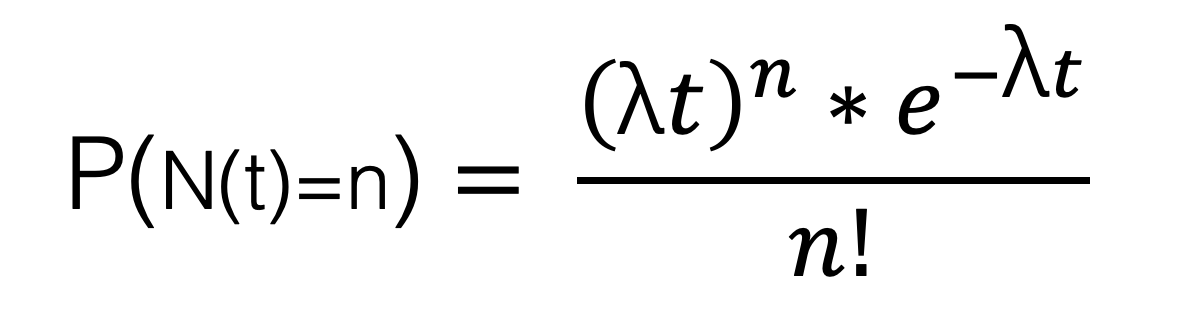
为了便于理解采用知乎的公式。在此公式中,P 表示概率,N 表示某种函数关系,t 表示时间,n 表示数量,例如 1 小时内出生 3 个婴儿的概率,就表示为 P(N(1) = 3) 。而 λ 表示事件的频率,表示为:
![]()
其中 FIT (Failure in Time) 为每小时故障率,公式为 ,所以 λ 可表示为:
![]()
本文不会去推导泊松分布的数学公式,主要是应用到计算可靠性中。由于采用4U36盘服务器,不太容易直接去计算任意一个盘出现损坏的概率 ,但是很容易计算没有盘出现问题的概率
,从而
= 1-
,它表示有1块盘及以上故障的概率。
![]()
也就是说N为36,t 为 24*365(1年的小时数),当 AFR 等于0.5%时,λ为0.005/(24*365)*36 ,所以故障1块盘及以上的概率 为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









