







搭建环境:windows10、VMware16.2.3、centOS7.9、jdk-8u162-linux-x64.tar.gz、hadoop3.1.0
Hadoop各个版本链接Hadoop
jdk8下载链接jdk
1.基本配置准备工作
1.1静态ip地址等配置
注:若提示权限不足则需要使用root权限
1.1.1非克隆机配置静态IP地址
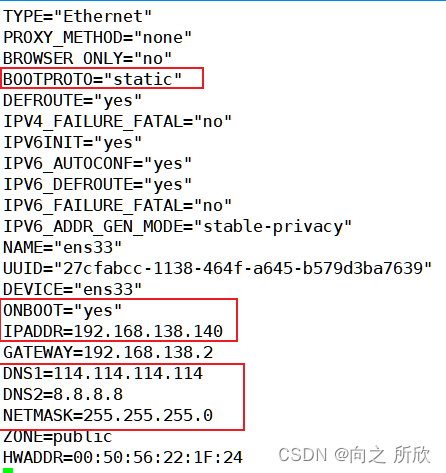
####1.1.2克隆机配置静态ip地址
Mac修改方式:网络适配器–>高级设置–>生成
UUID可以使用以下命令生成
uuidgen
执行命令(需要root权限) vim /etc/sysconfig/network-scripts/ifcfg-ens32 修改生成的Mac、UUID,并修改静态ip地址,不要与其他虚拟机的ip重复,如下:
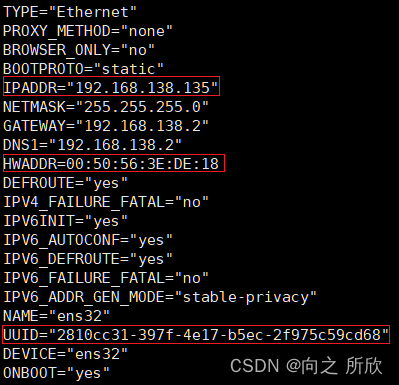
注:所有静态地址配置参数如图所示,若不同,需要修改对应变量(本虚拟机克隆而来,有克隆机配置好的变量),非克隆虚拟机可以查找网上的静态ip配置文章进行操作。
1.1.3主机名修改
主机名修改方式:vim /etc/hostname (reboot后生效)
centOS7中可以使用以下命令直接更改主机名
hostnamectl set-hostname hadoop #这里主机名更改为了 hadoop
1)修改ip地址和主机名的映射关系
vim /etc/hosts
2)添加一行新的映射,然后保存退出
192.168.138.135 hadoop #配置的静态ip地址 修改过的主机名
3)验证
ping hadoop
不丢包就是映射成功
1.1.4关闭防火墙
查看防火墙运行状态
firewall-cmd --state
关闭防火墙命令
systemctl stop firewalld #关闭防火墙服务网
systemctl disable firewalld #设置防火墙服务开机不启动
1.2创建hadoop用户
创建hadoop用户
su #以root用户登录
useradd -m hadoop -s /bin/bash #创建新用户hadoop,并使用/bin/bash作为shell
为hadoop用户设置密码
passwd hadoop
为hadoop用户添加管理员权限,方便部署,执行visudo
找到root ALL=(ALL) ALL然后在其后添加一行内容hadoop ALL=(ALL) ALL
注:虽然给了hadoop用户管理员权限,但在修改核心文件时还是需要申请root权限或直接切换到root用户进行修改。
2.安装ssh并配置ssh无密码登录
注意:在hadoop用户下进行ssh配置
centOS7默认安装了ssh,执行如下命令进行验证:
rpm -qa | grep ssh
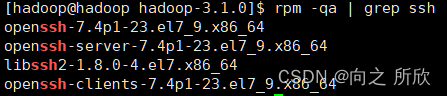
若未安装,使用yum进行安装:
sudo yum install openssh-clients
sudo yum install openssh-server
执行登录命令测试
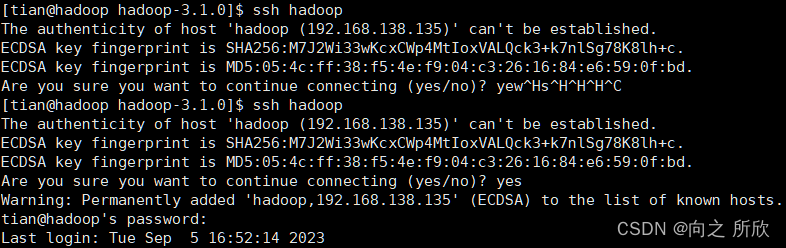
ssh localhost 或 ssh hadoop
1)测试登录
ssh localhost或ssh hadoop
2)exit退出登录
3)配置ssh无密码登录
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
4)测试
此时再用 ssh localhost 或 ssh hadoop命令,无需输入密码就可以直接登陆了
3.安装java
Hadoop 3.x要求JDK的版本必须是java 8之上,建议使用jdk8
利用xtfp将文件上传至用户hadoop中
3.1卸载系统自带的jdk
1)查看系统是否自带了jdk(一般情况下都会带)
rpm -qa |grep java
rpm -qa |grep jdk
rpm -qa |grep gcj
2)如果有输出信息,批量卸载系统自带
rpm -qa | grep java | xargs rpm -e --nodeps
3.2解压jdk安装包
说明:在安装jdk8之前也可以先卸载centOS自带的jdk,建议阅读过本小节之后自行定夺。
1)到指定目录下解压安装包
tar -zxvf jdk-8u162-linux-x64.tar.gz
2)将解压后的文件夹jdk-8u_162移动到 /usr/local/java下(一般安装的软件都会放到 /usr/local/ 目录下)
mv jdk1.8.0_162/ /usr/local/java 将文件移动到/usr/local/目录下,并将文件夹改名为java
注:不要提前建文件夹。
3.3修改环境变量
vim /etc/profile
注:配置系统环境变量需要root权限,即使之前给了hadoop权限也不能修改
可以使用
sudo vim /etc/profile暂时获得root权限
1)在文件的最后添加JAVA_HOME并将JAVA_HOME下的bin目录添加到PATH中,修改后保存退出
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin:$PATH
如下图:

2)然后重新加载环境变量,执行如下命令
source /etc/profile
3)测试是否配置成功
java -version
javac -version
注:并不知道版本提示不相同会有何后果,在配置完成hadoop后运行hdfs和yarn并无异常
若提示的java版本不相同,想修改成相同版本可参考以下操作:
注:若提示权限问题,需切换到root用户进行操作
4.安装Hadoop
上传hadoop-3.1.0.tar.gz到hadoop用户目录文件夹下
4.1解压Hadoop安装包
现在根目录下创建一个/bigdata目录用于保存以后要安装的大数据相关程序,然后将hadoop安装包解压到此文件夹下
mkdir /bigdata
tar -zxvf hadoop-3.1.0.tar.gz -C /bigdata/
4.2修改Hadoop的配置文件
进入到hadoop的安装目录,然后查看该目录中的内容
cd /bigdata/hadoop-3.1.0/etc/hadoop/
ll
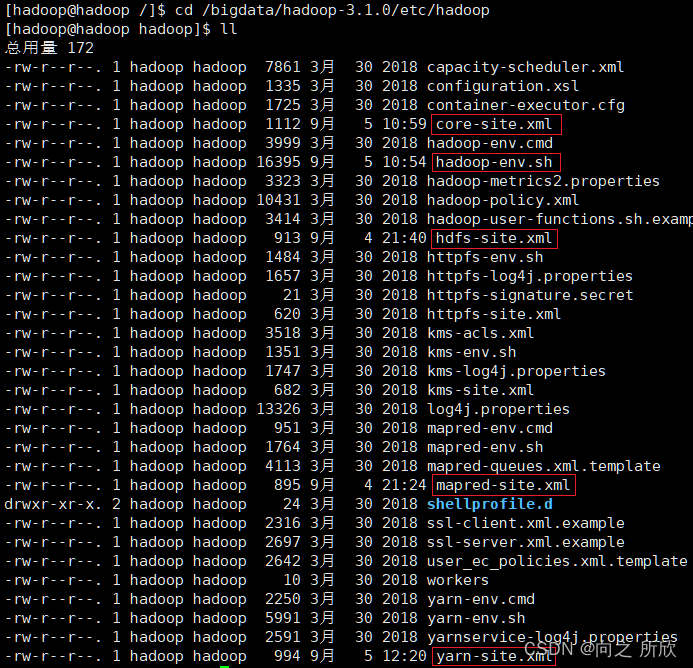
注:红框中标注的是依次需要修改的文件
4.2.1修改hadoop-env.sh
vim hadoop-env.sh

添加彩色字体的内容
export JAVA_HOME=/usr/local/java
4.2.2修改core-site.xml
core-site.xml是Hadoop的核心配置文件,里面可以配置HDFS的NameNode的地址和数据存储目录
vim core-site.xml
修改内容如下:
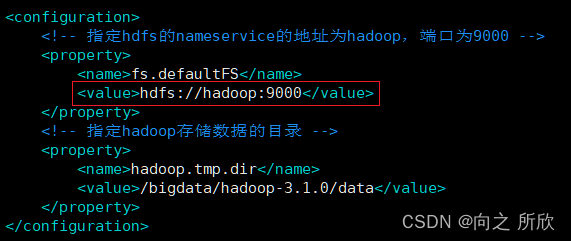
注:红框中的hadoop需替换成之前设置的主机名称
<configuration>
<!-- 指定hdfs的nameservice的地址为node-1.51doit.com,端口为9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定hadoop存储数据的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-3.1.0/data</value>
</property>
</configuration>
4.2.3修改hdfs-site.xml
hdfs-site.xml是HDFS的配置文件,由于当前是在一台机器上配置Hadoop伪分布式,所以这里只将HDFS保存的副本数设置为1,即只保存一份数据。
vim hdfs-site.xml
修改内容如下:
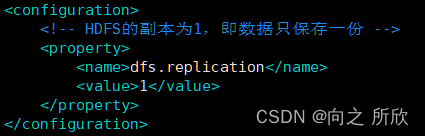
<configuration>
<!-- HDFS的副本为1,即数据只保存一份 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4.2.4修改mapred-site.xml
mapred-site.xml里面可以配置MapReduce框架运行在YARN资源调度系统上。
vim mapred-site.xml
修改内容如下:

补:后续使用中运行MapReduce wordcount 报错,解决方法如下:
输入命令:hadoop classpath
将输出的内容添加到配置文件中,如下图:
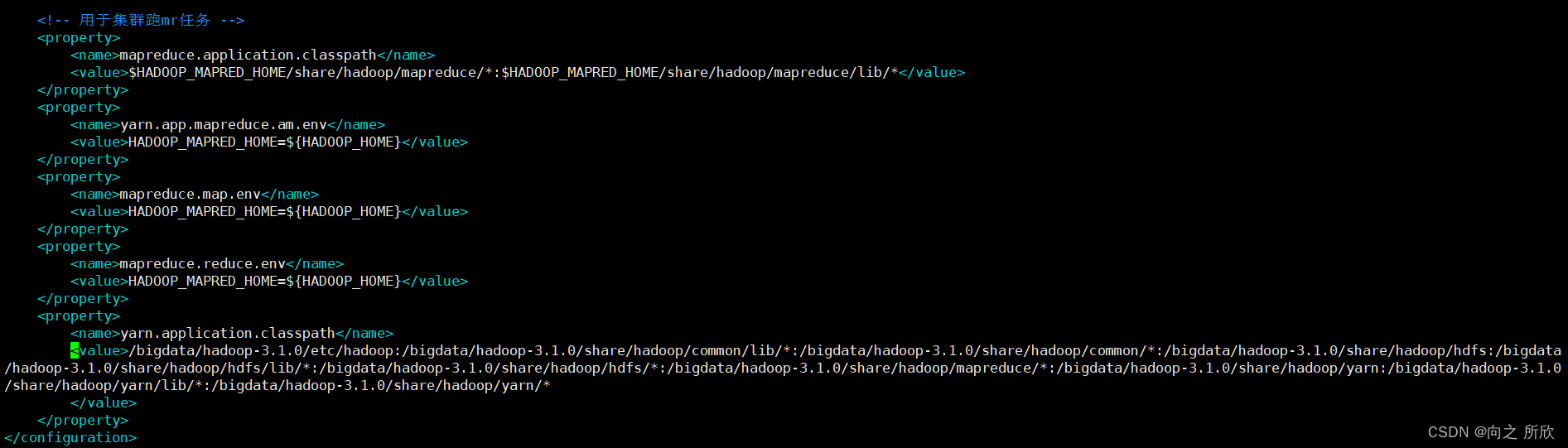
<property>
<name>yarn.application.classpath</name>
<value>/bigdata/hadoop-3.1.0/etc/hadoop:/bigdata/hadoop-3.1.0/share/hadoop/common/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/common/*:/bigdata/hadoop-3.1.0/share/hadoop/hdfs:/bigdata/hadoop-3.1.0/share/hadoop/hdfs/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/hdfs/*:/bigdata/hadoop-3.1.0/share/hadoop/mapreduce/*:/bigdata/hadoop-3.1.0/share/hadoop/yarn:/bigdata/hadoop-3.1.0/share/hadoop/yarn/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/yarn/*
</value>
<property>
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/bigdata/hadoop-3.1.0/etc/hadoop:/bigdata/hadoop-3.1.0/share/hadoop/common/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/common/*:/bigdata/hadoop-3.1.0/share/hadoop/hdfs:/bigdata/hadoop-3.1.0/share/hadoop/hdfs/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/hdfs/*:/bigdata/hadoop-3.1.0/share/hadoop/mapreduce/*:/bigdata/hadoop-3.1.0/share/hadoop/yarn:/bigdata/hadoop-3.1.0/share/hadoop/yarn/lib/*:/bigdata/hadoop-3.1.0/share/hadoop/yarn/*
</value>
</property>
</configuration>
4.2.5修改yarn-site.xml
yarn-site.xml是配置YARN的相关文件
vim yarn-site.xml
修改内容如下:
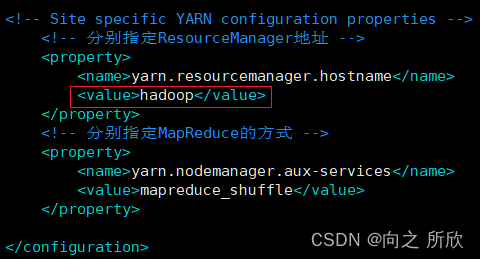
注:红框中同样是主机名
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 分别指定ResouceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- 分别指定MapReduce的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2.6将Hadoop的命令添加到系统环境变量
将Hadoop的命令添加到系统环境变量中的目的是使Hadoop命令可以在任何目录下执行。
vim /etc/profile
修改内容如下:

重新加载环境变量
source /etc/profile
# 添加java的系统环境变量
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
# 添加Hadoop的环境变量
export HADOOP_HOME=/bigdata/hadoop-3.1.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
4.3初始化Hadoop HDFS文件系统
hdfs namenode -format
看到如下信息即初始化成功

4.4启动Hadoop
4.4.1启动HDFS文件系统
如果在root用户中执行启动命令:start-dfs.sh
会出现如下错误:
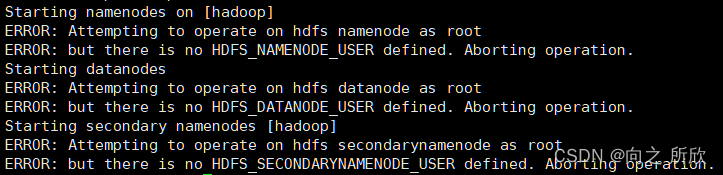
这是因为Hadoop3.x不推荐root用户启动,使用root启动HDFS会出现一系列隐患问题,如果就是想用root用户启动,需要在Hadoop的安装目录sbin的start-dfs.sh命令的最前面添加如下配置 :
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在实际生产环境中时不会使用root用户启动HDFS和YARN的,所以需要切换到之前建立的hadoop用户中启动。
因为需要切换到hadoop用户,所以需要修改Hadoop的安装文件的所属用户和所属组,命令如下:
chown -R hadoop:hadoop /bigdata/
切换到hadoop用户:
su hadoop
注:
su root为切换到root用户,需要root用户密码,而从root用户切换到其他用户则不需要密码。
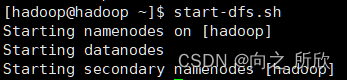
使用hadoop用户启动HDFS
start-dfs.sh
正常情况下如图:
如出现如下提示:
Starting namenodes on [hadoop]
hadoop: Warning: Permanently added 'hadoop,192.168.138.135' (ECDSA) to the list of known hosts.
hadoop: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting datanodes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting secondary namenodes [hadoop]
hadoop: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
若出现以上提示,则是没有配置ssh无密码登录,需配置ssh无密码登录
4.4.2启动YARN
启动YARN的命令如下:
start-yarn.sh
正常情况下如下:

4.4.3验证
在命令行输入如下命令:
jps
会出现:
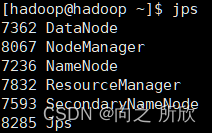
注:若多次进行初始化会没有DataNode进程,需要到 /bigdata/hadoop-3.1.0/中删除data,然后重新执行初始化命令
hdfs namenode -format。注:若缺少任意进程都需要到对应的配置文件中查看配置内容是否出错。
附:相应的,停止命令是
stop-dfs.sh和stop-yarn.sh
5.通过web界面访问Hadoop
在浏览器页面(Linux、Windows均可)输入 192.168.138.135:9870
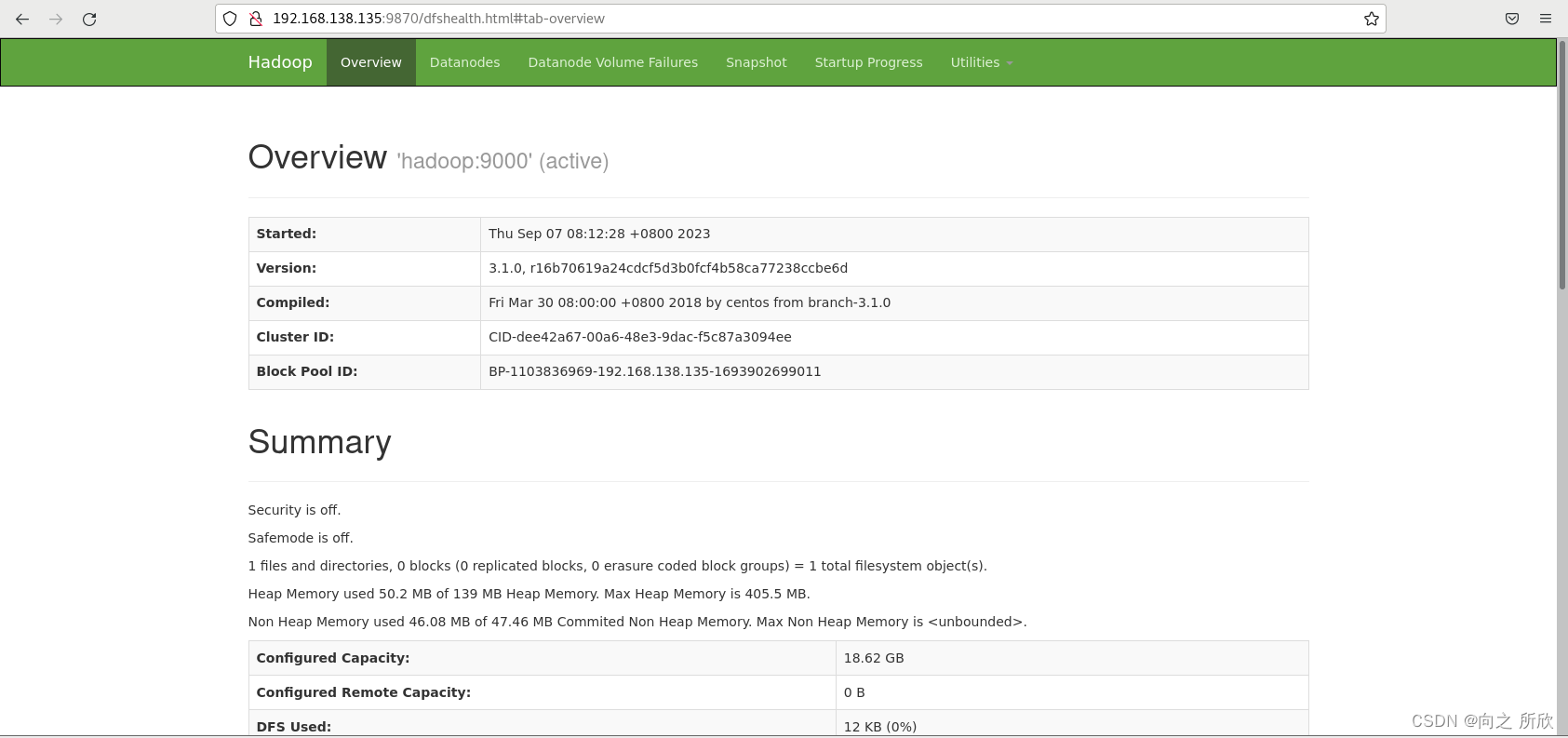
注:192.168.138.135 为主机的ip地址。
访问时要先启动hadoop服务(hdfs和yarn)
1)hadoop端口号 9870 2)yarn端口号 8088
















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











