







当我们的手机微信打不开链接,比如小程序的链接分享,公众号的文章链接,甚至是微信团队的反馈链接,有的公众号头像都不显示。就像下面这样:
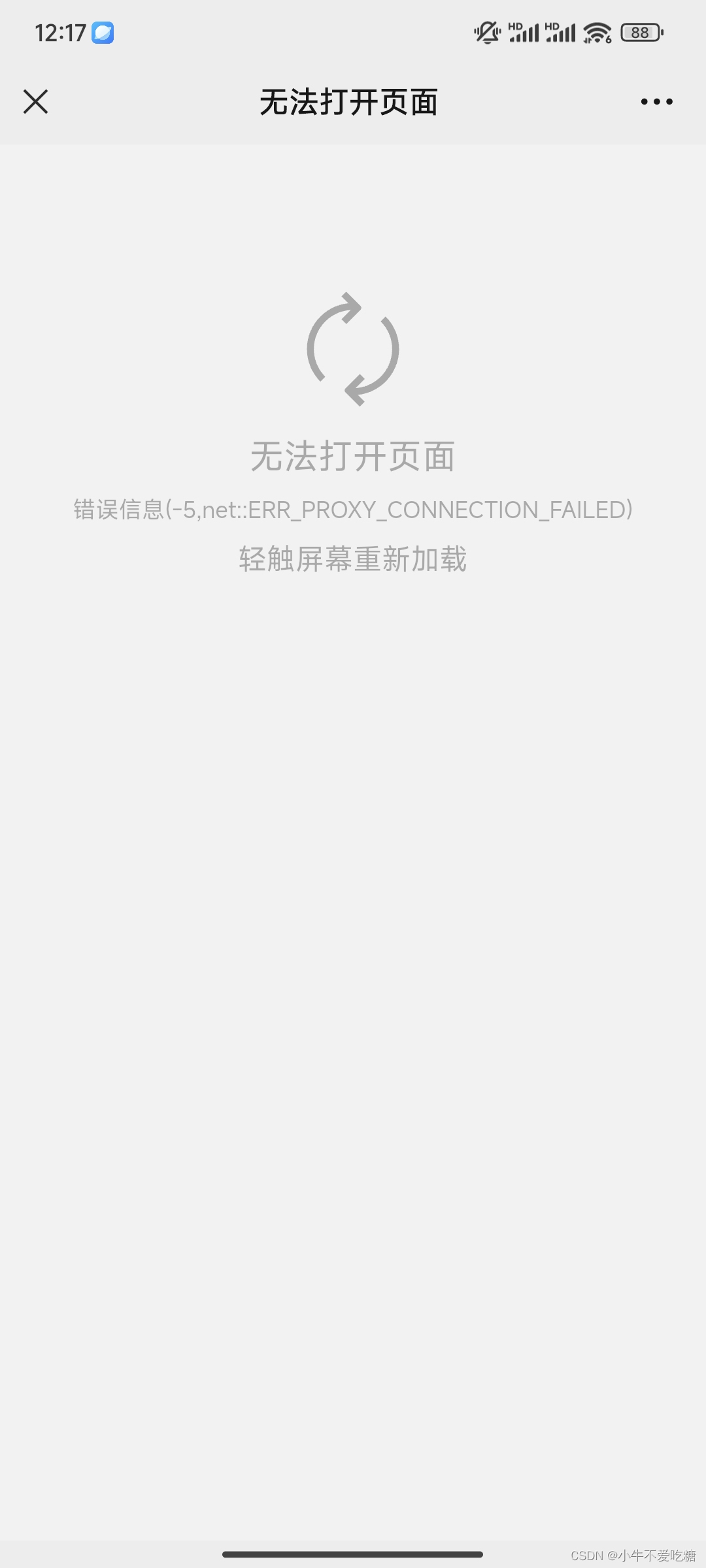
可能是以下情况导致的:
1、网页链接本身有问题
解决办法:尝试以下其他网页链接能不能打开,如果其他链接能打开,说明是链接有问题解决不了。
2、微信版本问题
解决办法:更新微信到最新版本。
3、网络权限问题
没有给微信授权使用网络,也可能导致这种情况,去手机【设置】找到网络权限管理,授权给微信允许使用网络。
4、以上都没问题,说明是微信出现了BUG,需要我们修复一下。这种情况可能在换新手机将微信聊天记录迁移的时候发生。
解决办法:打开微信【设置】找到【帮助与反馈】
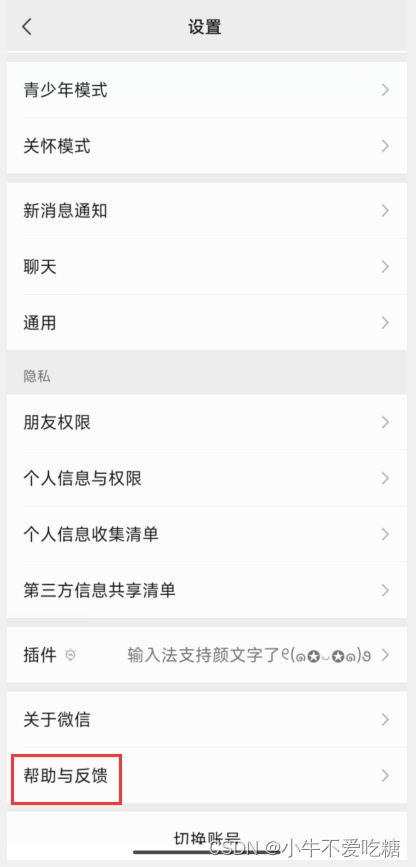
打开之后会出现“网页无法加载”的页面。没关系点击右上角的【扳手】图标。
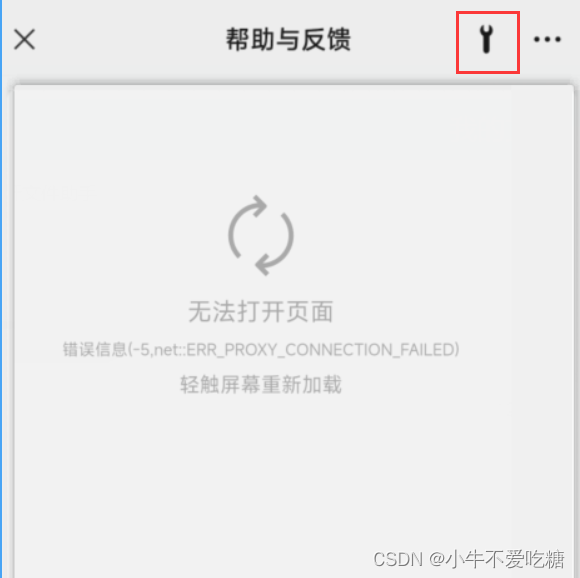
进入到如下页面: 点击【修复搜索故障】

之后进入到如下界面:
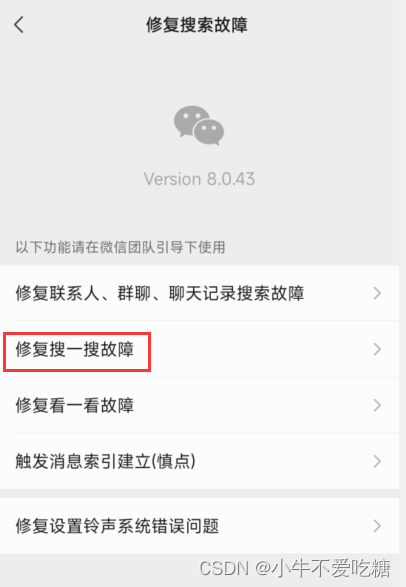
如果其他没有什么问题,只是链接打不开点击【修复搜一搜故障】然后会弹出提示点击【确认】,重新进入微信即可。
当然也可以把其他功能也修复一下。
5、设置微信默认浏览器
微信里面是自带浏览器的,如果不想打开链接使用默认的浏览器,那么也可以是设置微信的默认浏览器为其他,比如设置【百度】【谷歌】打开链接。在【设置】的【通用】里面有一个【设置默认浏览器】功能即可设置。

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









