







前言
Python操作mysql数据库,第三方模块pymysql简介
数据分析时,直接使用pandas模块读取mysql数据库数据
代码实现
Python源代码
import requests # 爬虫,采集数据--惠农网南瓜价格
from fake_useragent import UserAgent # 请求头
from lxml import etree # 数据提取,Xpath语法
import pymysql # 连接数据库
import pandas as pd # 数据处理,读取MYSQL数据
def spider_database():
# 连接数据库
db = pymysql.connect(host='127.0.0.1',
user='root',
password='123456',
database='ng')
cursor = db.cursor() # 建立一个游标
"""---------------爬虫----------------"""
ua = UserAgent()
url = "https://www.cnhnb.com/hangqing/cdlist-2001233-0-0-0-0-3/"
responce = requests.get(url=url, headers={"user-agent": ua.Chrome})
responce.encoding = "utf-8"
result = responce.text
tree = etree.HTML(result)
quotation_content = tree.xpath("//div[@class='quotation-content']//div[2]/ul/li")
for it in quotation_content:
print(it.xpath("./a/span/text()")[:-1])
result_ = it.xpath("./a/span/text()")[:-1]
time = result_[0]
kind = result_[1]
adress = result_[2]
price = result_[3]
"""---------------存入数据库----------------"""
sql = "insert into ngprice(time,kind,adress,price) values(%s,%s,%s,%s)"
cursor.execute(sql, (time, kind, adress, price))
db.commit()
db.close()
print("插入数据成功!")
def select_sql():
db_conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='123456',
database='ng',
charset='utf8'
)
print(db_conn)
data = pd.read_sql("select * from ngprice", con=db_conn) # 读取mysql数据表
print(data)
data.to_excel(r"ngPrice.xlsx", index=False) # 将查询的结果存为Excel文件,不要index(纵列)索引
if __name__ == "__main__":
spider_database()
select_sql()
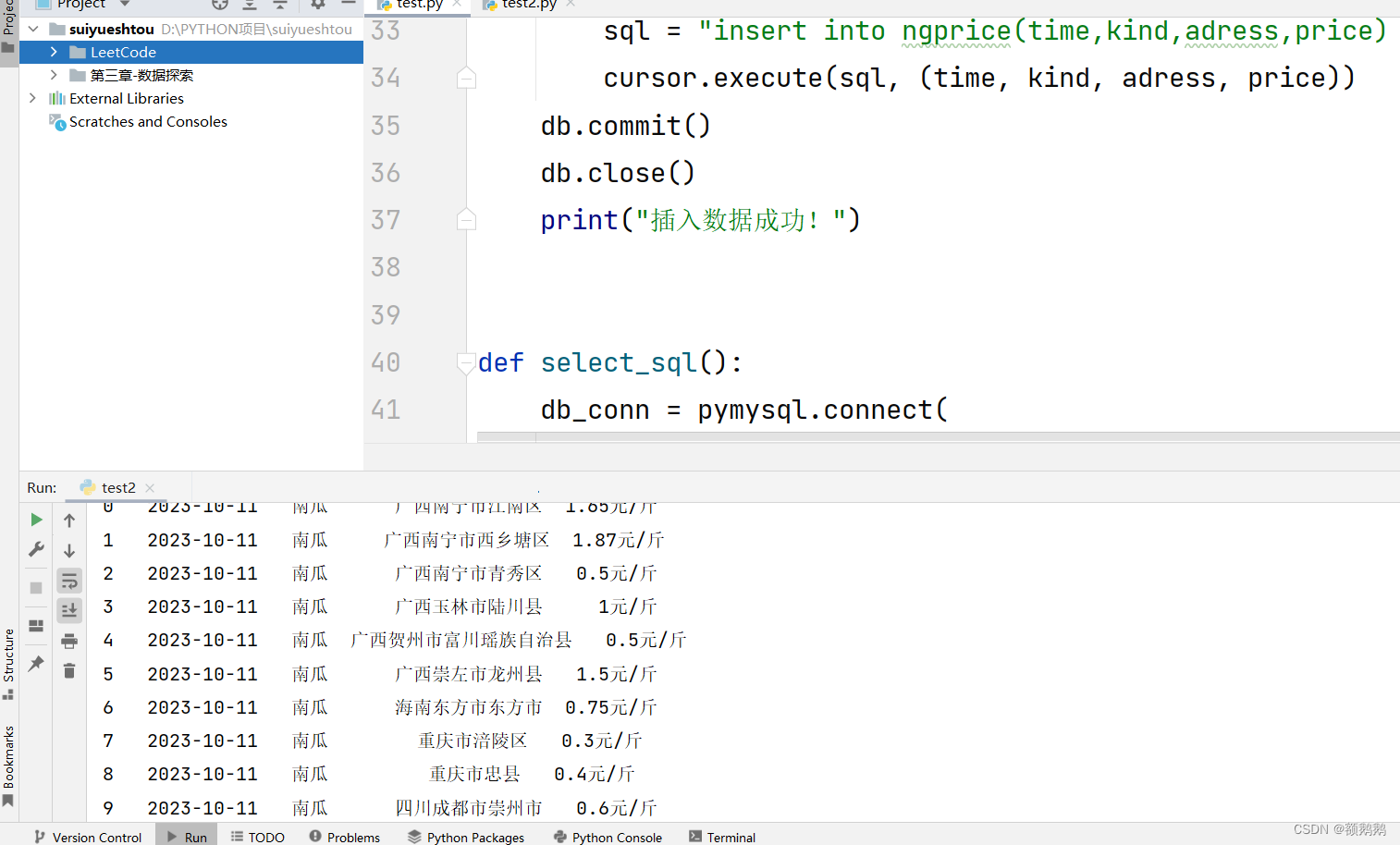
程序运行结果
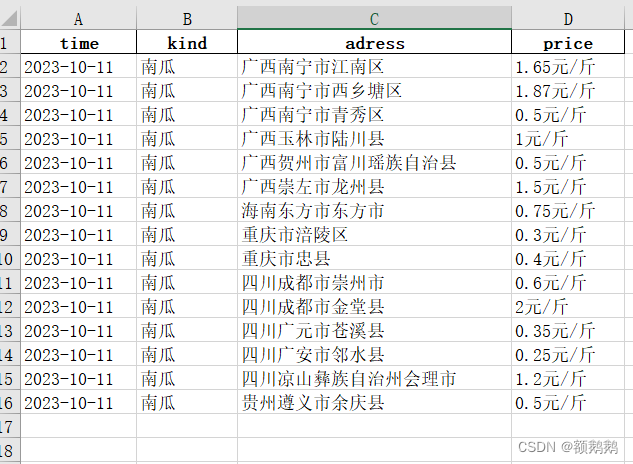
MYSQL数据结果
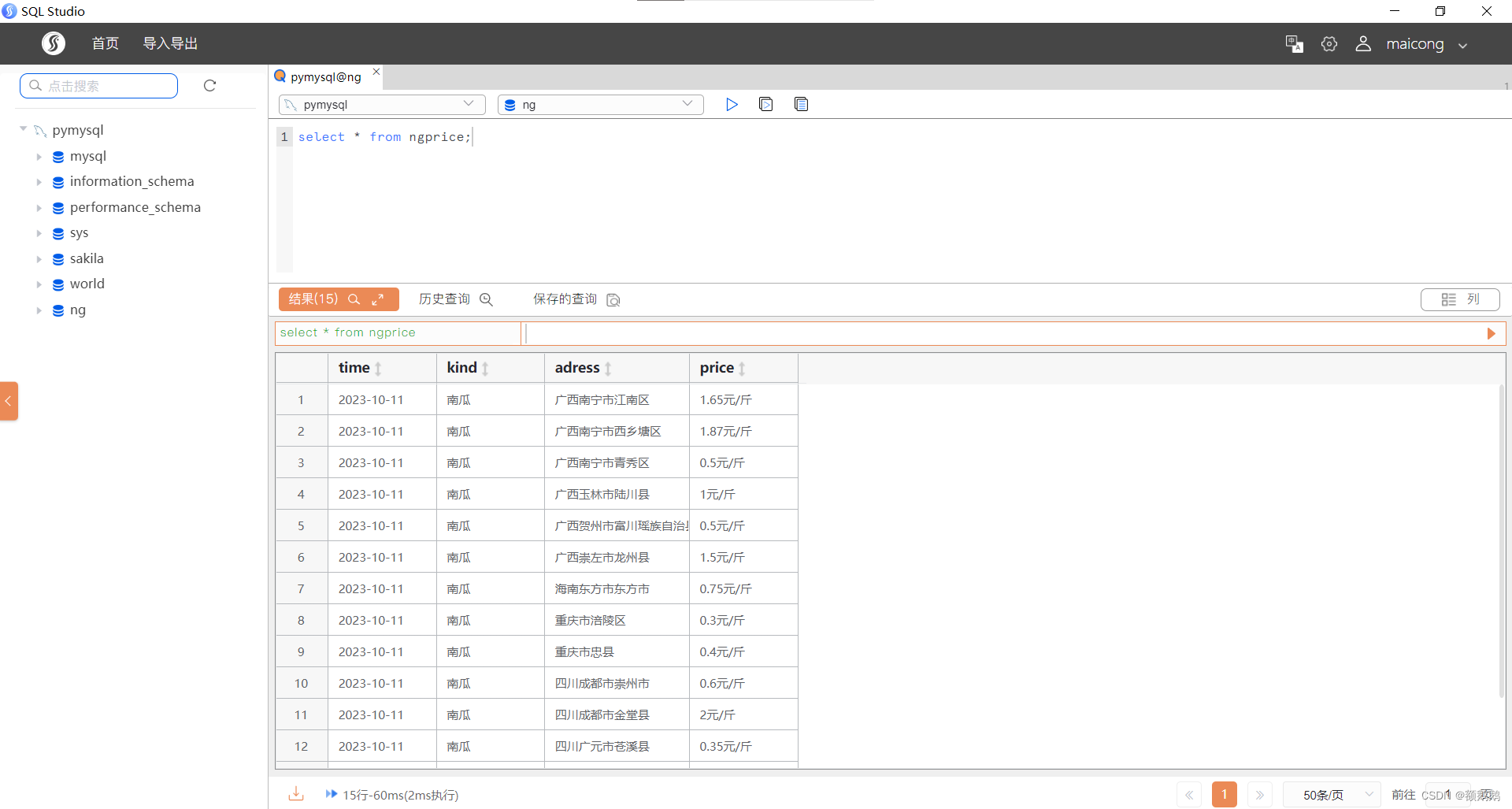
国产数据库可视化工具—SQLstudio
SELECT
`time`,
`kind`,
`adress`,
`price`
FROM
`ng`.`ngprice`
总结
python读取数据库,还有其他函数:
pd.read_sql_query(“show database”,con) # 查看数据表数目
pd.read_sql_table(“表名”,con) # 查看数据详情表
存取位数据库
data.to_sql_table(name="ng", con=db_conn, index=False,if_exists="fail")
















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











