







目录
process_requests(request,spider)
process_response(request,response,spider)
Scrapy框架初级
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要用少量的代码,就能够快速的抓取。
1.异步和非阻塞的区别
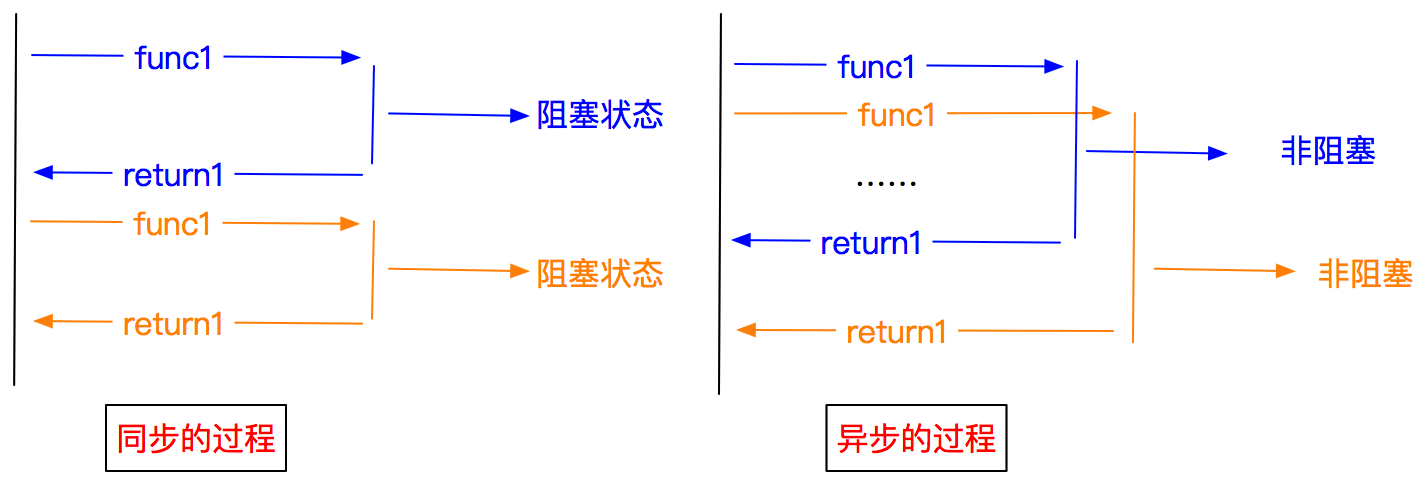
异步:调用在发出之后,这个调用就直接返回,不管有无结果
非阻塞:关注的是程序在等待调用结果时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程。
| Scrapy engine(引擎) | 总指挥:负责数据和信号的在不同模块间的传递 | scrapy已经实现 |
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloads(下载器) | 下载把引擎发过来的requests请求,并返回给引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的reponse,提取数据,提取url,并交给引擎 | 需要手写 |
| ltem Pipline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader | 可以自定义的下载扩展 | 一般不用手写 |
| Spider Middlewares(中间件) | 可以自定义requests请求和进行reponse过滤 | 一般不用手写 |
scrapy startproject mySpider
scrapy genspider demo 'demo.cn'
生成一个爬虫提取数据:完善spider 使用xpath等
保存数据:pipeline中保存
在命令中运行爬虫:
scrapy crawl qb #qb爬虫的名字在pycharm中运行爬虫
from scrapy import cmdline
cmdline.execute('scrapy crawl qb'.split())pipeline使用
从pipeline的字典形可以看出来 ,pipeline可以有很多个,而且确实pipeline能够定义多个。
为什么需要多个pipeline:
1.可能会有多个spider,不同的pipeline处理不同的item的内容;
2.一个spider的内容可以要做不同的操作,比如存入不同的数据库中。
notice:
1.pipeline的权重越小优先级越高
2.pipeline中process_item方法名不能修改为其他的名称’
Scrapy.Request
scrapy.Request(url, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None)
常用参数为:
callback:指定传入的URL交给那个解析函数去处理
meta:实现不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度
dont_filter:让scrapy的去重不会过滤当前URL,scrapy默认有URL去重功能,对需要重复请求的URL有重要用途item的介绍和使用
items.py
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
position = scrapy.Field()
date = scrapy.Field()Scrapy log的认知:

Scrapy CrawlSpider说明
之前的代码中,我们有很大一部分时间在寻找下一页的URL地址或者内容的URL地址上面。
我们可以这样:
1.从response中提取所有的标签对应的URL地址
2.自动的构造自己requests请求,发送给引擎
目标:通过爬虫了解crawlspider的使用
生成crawlspider的命令:
scrapy genspider -t crawl爬虫名字 域名LinkExtractors链接提取器
使用LinkExtrators可以不用自己提取想要的url,然后发送请求。这些工作都可以交给LinkExtractors,他会在所有爬的页面找到满足规则的url,实现自动的爬取。
class scrapy.linkextractors.LinkExtractor(
allow = (), #允许的URL,所有满足这个正则表达氏的URL都会被提取
deny = (),
allow_domains = (), #允许的域名,只有在这个里面指定的域名的URL才会被提取
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (), #严格的xpath,和allow共同过滤链接
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)Rule规则类
定义爬虫的规则类
class scrapy.spiders.Rule(
link_extractor, #一个LinkExtractor对象,用于定义爬取规则
callback = None, #满足这个规则的url,应该要执行那个回调函数,因为CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。
cb_kwargs = None,
follow = None, #指定根据该规则从response中提取的链接是否需要跟进
process_links = None, #从link_extractor中获取链接后会传递给这个函数,用来过滤不需要的爬取链接
process_request = None
)
选择使用scrapy内置的下载文件的方法
下载文件的Files Pipeline
1.定义一个item,在这个item中定义两个属性,分别为file_urls以及files。files_urls是用来存储需要下载的文件的URL链接,需要给一个列表
2.当文件下载完成后,会把文件下载的相关信息存储到item的files属性中,如下载路径,下载的url和文件校验码等
3.在配置文件settings.py中配置FILES_STORE,这个配置用来设置文件下载路径
4.启动pipeline:在ITEM_PIPELINES中设置scrapy.piplines.files.FilesPipeline:1
下载图片的lmages Pipeline
1.定义一个item,在这个item中定义两个属性,分别为image_urls以及images。images_urls是用来存储需要下载的文件的URL链接,需要给一个列表
2.当文件下载完成后,会把文件下载的相关信息存储到item的images属性中,如下载路径,下载的url和文件校验码等
3.在配置文件settings.py中配置IMAGES_STORE,这个配置用来设置文件下载路径
4.启动pipeline:在ITEM_PIPELINES中设置scrapy.piplines.images.Images_Pipeline:1
Scrapy下载中间件
下载中间件是scrapy提供用于在爬虫过程中可修改Request和Response,用于扩展scrapy的功能
使用方法:
编写一个Download Midddlewares和我们编写一个pipeline一样,定义一个类,然后再settings中开启
Download Middlewares默认方法:
处理请求,处理响应,对应两个方法
process_request(self,request,spider):
当每个request通过下载中间件时,该方法被调用
process_response(self,request,response,spider):
当下载器完成http请求,传递响应给引擎的时候调用process_requests(request,spider)
当每个Request对象经过下载中间件时会被调用,优先级越高的中间件,越先 调用;该方法应该返回以下对象:None/Response对象/Request对象/抛出lgnoreRequest异常
返回None:scrapy会继续执行其他中间件相应的方法;
返回Response对象:scrapy不会调用其他中间件的process_request方法,也不会去发起下载,而是直接返回该Response对象
返回Request对象:scrapy不会调用其他中间件的process_request()方法,而是将其放置调度器待调度下载
如果这个方法抛出异常,则会调用process_exception方法
process_response(request,response,spider)
当每个Response经过下载中间件会被调用,优先级越高的中间件,越晚被调用,与process_request()相反;该方法返回以下对象:Response对象/Resquest对象/抛出lgnoreRequest异常。
1.返回Response对象:scrapy会继续调用其他中间件的process_response方法;
2.返回Request对象:停止中间器调用,将其放置到调度器待调度下载;
3.抛出lgnoreRequest异常:Request.errback会被调用来处理函数,如果没有处理,他将会被忽略且不会写进日志。














 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









