







文章目录
更好的阅读体验
前言
爬虫爬的好牢饭吃的早,爬虫启动!本博客为记录b站尚硅谷爬虫的一些笔记和代码
爬虫简介
1、首先我们需要知道爬虫是什么?爬虫实际上是一段程序,我们可以通过这段程序从互联网上获取到我们想要的数据,这里还有另外一种解释是我们使用程序来模拟浏览器向服务器发送请求,来获取响应信息
2、爬虫的核心:
(1)、爬取网页:爬取整个网页,包含网页中的所有内容
(2)、解析数据:将网页中我们得到的数据解析,因为网页中有众多数据我们只想要我们期望得到的数据,解析也就是得到我们期望数据的过程
(3)、难点:爬虫与反爬虫之间的博弈
3、爬虫的用途
(1)、数据分析/人工数据集
(2)、社交软件的冷启动
(3)、舆情监控
(4)、竞争对手的监控
urllib库的使用
如何获取网页的源码
# 使用urllib获取百度首页的源码
import urllib.request
# 1、定义一个url 要访问的地址
url = 'http://www.baidu.com'
# 2、模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# 3、获取响应中的页面的源码 content 内容的意思
# read方法返回的是字节形式的二进制数据
# 由于二进制的数据我们是看不懂的,所以我们需要将二进制的数据转换为字符串(我们把二进制转换到字符串这一过程称为解码)
# 解码decode('编码的格式')
content = response.read().decode('utf-8')
# 4、打印数据
print(content)
一个类型六个方法
一个类型
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
print(type(response))
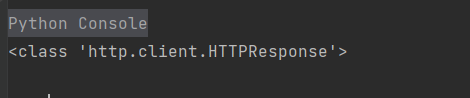
反应的类型是HTTPResponse
六个方法
1、read()方法
首先关于read()方法我们要清楚的是read()方法读取数据时是一个字节一个字节的读取的,read()方法可以传入参数,代表读的字节数,例如read(5)就是读5个字节
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
#print(type(response))
content = response.read()
2、readline()方法
只能读取一行,优点是读取速度比较快
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
#print(type(response))
content = response.readline()
print(content)

3、readlines()方法
content = response.readlines();
print(content)
readlines()方法还是一行一行地读数据不过会将所有数据读完,并且读出来的结果依然是二进制的
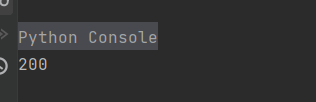
4、getcode()
getcode()是返回的状态码, 如果返回的是200就证明我们写的逻辑没有错误,如果是404,或者一些的奇奇怪怪的数字就证明存在一些问题,所以这个方法常用来进行检验我们的逻辑是不是有错误
import urllib.request
url = 'http://www.baidu.com'
print(response.getcode())
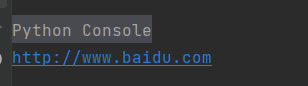
5、geturl()
返回我们的url地址
import urllib.request
url = 'http://www.baidu.com'
print(response.geturl())
6、getheaders()
获取一些状态信息
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
#print(type(response))
# content = response.readline()
# print(content)
# content = response.readlines();
# print(content)
print(response.getheaders())

urllib下载
下载网页
主要用到的是urlretrieve(url, filename)方法,这个方法里面有两个参数,一个是我们要要在网页的路径,另一个是我们保存所下载网页的文件的路径
import urllib.request
# 下载网页
url_page = 'http://www.baidu.com'
urllib.request.urlretrieve(url_page, 'baidu.html')
下载图片
import urllib.request
# # 下载网页
# url_page = 'http://www.baidu.com'
#
# urllib.request.urlretrieve(url_page, 'baidu.html')
# 下载图片
url_img = "https://tse4-mm.cn.bing.net/th/id/OIP-C.GftfIjm472xuHpMaGb7BsgAAAA?w=167&h=180&c=7&r=0&o=5&dpr=1.3&pid=1.7"
urllib.request.urlretrieve(url_img, '锦木千束.jpg')
# 下载视频
下载视频
import urllib.request
# # 下载网页
# url_page = 'http://www.baidu.com'
#
# urllib.request.urlretrieve(url_page, 'baidu.html')
# # 下载图片
# url_img = "https://tse4-mm.cn.bing.net/th/id/OIP-C.GftfIjm472xuHpMaGb7BsgAAAA?w=167&h=180&c=7&r=0&o=5&dpr=1.3&pid=1.7"
# urllib.request.urlretrieve(url_img, '锦木千束.jpg')
# 下载视频
url_vedio = 'http://vod.v.jstv.com/video/2023/7/28/20237281690548460345_505_1366.mp4'
urllib.request.urlretrieve(url_vedio, '视频.mp4')
由于pycharm没有内置的播放器所以我们不能直接再pycharm内部观看视频,可以找到文件保存的路径用本地播放器观看

















 2075
2075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









