







前言
跳表是一种用来查询的结构,它的本质是有序链表的变形,而单链表却是一个非常不适合用来查找的结构,只能不断的遍历每一个节点,无法随机访问,无法直接访问中间的节点,这些都是链表的痛点。那么跳表是怎样对单链表进行变形,使得它适合用来查找的呢?
我们知道链表的节点分为数据域和指针域,指针域一般存储了指向下一个节点的指针。这是问题所在,节点的指针域只连接了下一个节点,从数量看,一个节点太少了,从距离上看,每次只能访问我的下一个节点,这太短了。跳表的设计者围绕这个问题,提出了指针域存储多个指针的概念,即我们可以通过一个节点访问它的下一个,也可以访问它的下下一个,还可以访问它的下下下一个…甚至访问到最后一个节点,具体看下面这张图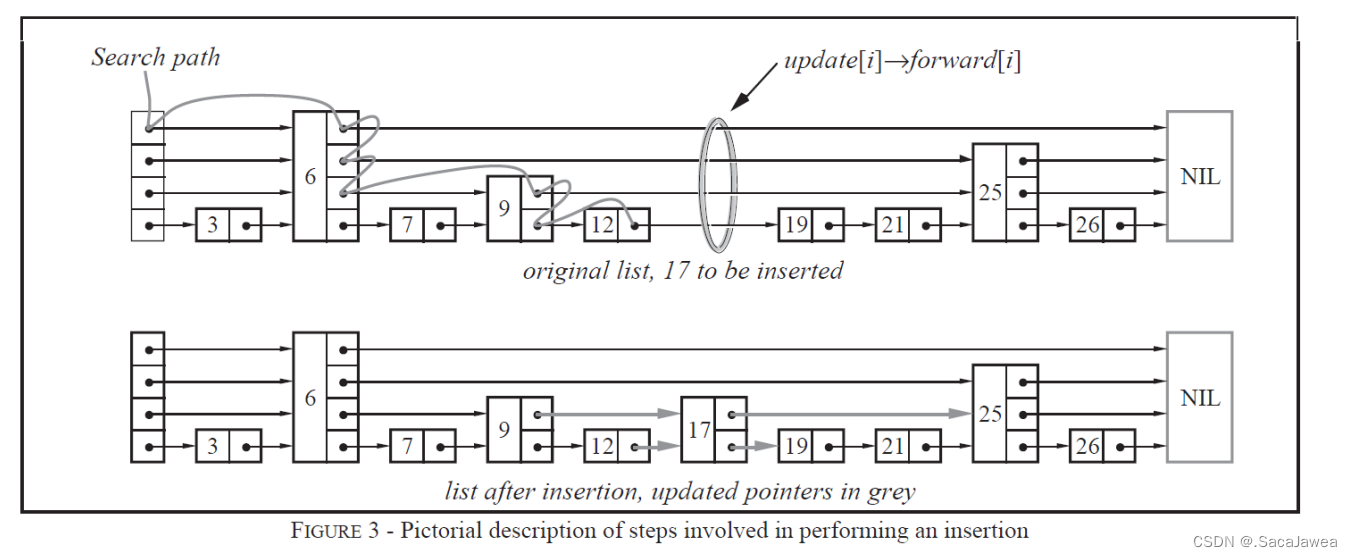
每个节点指针域存储的指针数量是随机的,但至少存储了一个指向下一个节点的指针,可以理解为这是最低一层的节点。跳表中存在一层,两层,三层…的节点,对于每一层来说,同层的节点之间也是一种单链表关系,最低一层的节点就是我们熟悉的单链表。那么现在的问题是:指针域要以什么形式存储多个指针?每个节点的指针数量都是不相同的,这个大小无法提前确定,所以这里用可以动态分配空间的vector存储指针。
template <class T>
struct SlistNode
{
T _data;
vector<SlistNode*> _vnext;
// 为vnext开辟n个空间,并用nullptr初始化
SlistNode(const T& data, size_t n)
:_data(data)
,_vnext(n, nullptr)
{}
};
当初始化一个节点时,用随机函数生成一个随机数,以该随机数做为节点指针域的指针数量(节点的层数)。
搜索逻辑讲解
跳表有一个头节点,它不存储任何有效的数据,它的层数与最高的节点层数一样。所以我们从头节点的最高层开始(vnext数组的最后一个元素),判断该指针指向的下一节点的值与我们要查找的值target之间的关系。如果target大于下一节点的值(假设链表是升序的),继续往右遍历。如果target小于下一节点的值或者下一节点为空,往下遍历。比如现在要查找12,从头节点开始,下一个节点的值为6,12大于6,向右遍历到6,6的下一个节点为空,向下遍历。此时6的下一个节点为25,12小于25,向下遍历。此时6的下一个节点为9,12大于9,向右遍历到9。9的下一节点为17,17大于12,向下遍历,此时9的下一节点为12,查找完成。
总结一下,查找只有两种方向,向右和向下,当target大于下一节点的值,向右。当下一节点为空或者target小于下一节点的值,向下。至于为什么不用当前节点进行数据比较,而是用下一个节点进行数据比较,这是因为在传统的单链表中,如果节点的next指针指向空,那么这个节点就是尾节点,但是在跳表中,next指针指向空的节点不一定是整个链表的尾节点,其可能是某一层的尾节点。比如在最高层中,6的下一节点指向空,但6并不是整个链表的尾节点,而是最高层链表的尾节点。因此我们不能根据当前节点值是否为空来判断是否遍历完了所有节点,这样的判断不利于我们查找节点,更低层可能还有其他的节点。
bool search(const T& target)
{
Node* cur_node = _head;
int level = _head->_vnext.size() - 1;
// level要保持在最低层以上,才能进行查找
while (level >= 0)
{
// target大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && target > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// 下一节点为空或者target小于下一节点的值,向下
else if (cur_node->_vnext[level] == nullptr || target < cur_node->_vnext[level]->_data)
{
--level;
}
// 找到返回true
else
{
return true;
}
}
return false;
}
插入逻辑讲解
插入一个节点时,需要对其进行构造,构造之前就要确定节点的层数,所以这里得有一个随机函数,先生成一个随机数,才能进行节点的构造。我们要设置一个概率p,只有生成的数小于随机数最大值乘以p的结果,层数才会加1,也就是说构造n层节点的概率是:p的n-1次方 * (1-p)
size_t RandomLevel()
{
size_t level = 1;
while (rand() < RAND_MAX * _p && level < _max_level)
{
level++;
}
return level;
}
其中的概率与最大层数是跳表的成员
template <class T>
class Skiplist
{
typedef SlistNode<T> Node;
private:
Node* _head;
double _p = 0.25;
size_t _max_level = 32;
};
构建完节点后就是插入,假设要插入的节点有n层高,那么在n层,n-1层,n-2层…1层的单链表都要维护,每一层的维护就是一个单链表的插入,我们要保存插入位置的前一个节点,将前一个节点指向自己,自己指向后一个节点,所以这里需要一个prev保存前一节点,但是每一层都需要一个prev,为了更好的实现,这里用一个长度为n的vprev数组保存每一层的prev。先不进行插入操作,先得到每一层的prev,构建vprev数组,最后再遍历vprev数组进行节点的插入。但是要注意的是只构造一个节点,所谓在每一层插入节点实际上是节点的vnext数组的维护
void add(const T& num)
{
// 先生成随机数,将其作为节点的层数
int level = RandomLevel();
// 如果新节点的层数高与头节点,更新头节点的层数
if (level > _head->_vnext.size())
{
_head->_vnext.resize(level, nullptr);
}
// 节点的构造
Node* new_node = new Node(num, level);
// vprev数组的创建,长度(层数)是level
vector<Node*> vprev(level, nullptr);
// 用cur_node遍历跳表
Node* cur_node = _head;
level -= 1;
while (level >= 0)
{
// num大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// 如果下一节点为空,或者num小于等于下一节点,保存当前节点,进行下一层遍历
else
{
vprev[level] = cur_node;
--level;
}
}
// vprev构建之后,遍历vprev进行节点的插入
for (size_t i = 0; i < new_node->_vnext.size(); ++i)
{
// 每一层都是单链表的插入操作
new_node->_vnext[i] = vprev[i]->_vnext[i];
vprev[i]->_vnext[i] = new_node;
}
}
删除逻辑讲解
由于跳表是允许数据冗余的,这就会导致一个问题,一不小心就内存泄漏。
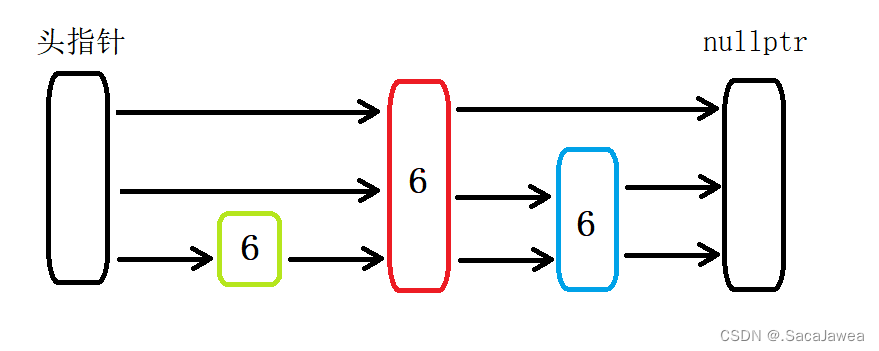
比如连续插入3个6,最高的6有3层的高度,最矮的只有一层高度。现在要删除6,如果按照搜索的逻辑:从最高层开始找,遇到比6小的向右走,直到遇到6,如果遇到的数比6大,就是找不到,返回false。
按照这个逻辑,很容易内存泄漏,你看,和插入一样,删除也需要维护vprev数组,知道链表的前一个节点才能删除指定的节点,那么vprev保存的最高层prev节点就是头节点,因为6在头节点之后。中间那一层的prev也是头节点,但是最后一层呢?prev还是头节点,因为头节点的后一个也是6,就算它们的层数不同。虽然这样可以维护链表,但是必定会有一个节点的内存泄漏,仔细看了一下,像上面这种情况,连链表的维护都做不到。所以说,我们要重新设计删除的搜索算法
上面的问题,本质上是值比较造成的,要删除同一个节点,我们只能通过地址比较。先从最高层开始向下查找,用值进行判断,找到一个值为6的节点,保存要删除节点的地址以及它的prev节点,然后退出遍历,以当前层数为数组的长度构造vprev数组,并用prev初始化最后一个值,接着从保存的prev位置重新进入遍历,以地址比较的方式更新vprev数组。更新完vprev数组后,就是每一层的链表删除操作,最后释放节点的资源
bool erase(int num)
{
// vprev数组的创建
vector<Node*> vprev;
// 用cur_node遍历跳表
Node* cur_node = _head;
// del_node的初始化
Node* del_node = nullptr;
int level = _head->_vnext.size() - 1;
// 先找到节点的地址
while (level >= 0)
{
// num大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// num等于下一个节点的值,找到了
else if (cur_node->_vnext[level] != nullptr && num == cur_node->_vnext[level]->_data)
{
// 保存被删除的节点地址
del_node = cur_node->_vnext[level];
// 为vprev开辟空间
vprev.resize(level + 1, nullptr);
// 保存当前的prev地址
vprev[level] = cur_node;
--level;
// 跳出循环,准备进行地址比较
break;
}
// 如果出现num小于下一节点值的情况,说明当前层没有找到,进入下一层找
else
{
--level;
}
}
// 如果上面的循环走完了,del_node还是没有更新,说明没有找到该节点,返回false
if (del_node == nullptr)
{
return false;
}
// 用地址进行节点的查找
while (level >= 0)
{
if (del_node != cur_node->_vnext[level])
{
cur_node = cur_node->_vnext[level];
}
else
{
vprev[level] = cur_node;
--level;
}
}
// 每一层的节点删除
for (size_t i = 0; i < vprev.size(); ++i)
{
vprev[i]->_vnext[i] = del_node->_vnext[i];
}
// 注意节点只有一个,不要把delete放到循环里面
delete del_node;
return true;
}
leetcode.设计跳表
题目链接
基于刚刚实现的泛型跳表,改造一下,直接套到这个题上
经过测试,实现的跳表没有问题(就是为啥时间这么慢),下面是改造后的代码,就是在模板的地方修改了一下
template <class T>
struct SlistNode
{
T _data;
vector<SlistNode*> _vnext;
SlistNode(const T& data, size_t n)
:_data(data)
,_vnext(n, nullptr)
{}
};
class Skiplist {
public:
typedef SlistNode<int> Node;
Skiplist() {
srand((unsigned int)(time(NULL)));
_p = 0.25;
_max_level = 32;
_head = new Node(0, 1);
}
size_t RandomLevel()
{
size_t level = 1;
while (rand() < RAND_MAX * _p && level < _max_level)
level++;
return level;
}
bool search(int target) {
Node* cur_node = _head;
int level = _head->_vnext.size() - 1;
while (level >= 0)
{
if (cur_node->_vnext[level] != nullptr && target > cur_node->_vnext[level]->_data)
cur_node = cur_node->_vnext[level];
else if (cur_node->_vnext[level] == nullptr || target < cur_node->_vnext[level]->_data)
--level;
else
return true;
}
return false;
}
void add(int num) {
int level = RandomLevel();
if (level > _head->_vnext.size())
_head->_vnext.resize(level, nullptr);
Node* new_node = new Node(num, level);
vector<Node*> vprev(level, nullptr);
Node* cur_node = _head;
level -= 1;
while (level >= 0)
{
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
cur_node = cur_node->_vnext[level];
else
{
vprev[level] = cur_node;
--level;
}
}
for (size_t i = 0; i < new_node->_vnext.size(); ++i)
{
new_node->_vnext[i] = vprev[i]->_vnext[i];
vprev[i]->_vnext[i] = new_node;
}
}
bool erase(int num) {
vector<Node*> vprev;
Node* cur_node = _head;
Node* del_node = nullptr;
int level = _head->_vnext.size() - 1;
while (level >= 0)
{
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
cur_node = cur_node->_vnext[level];
else if (cur_node->_vnext[level] != nullptr && num == cur_node->_vnext[level]->_data)
{
del_node = cur_node->_vnext[level];
vprev.resize(level + 1, nullptr);
vprev[level] = cur_node;
--level;
break;
}
else
--level;
}
if (del_node == nullptr)
return false;
while (level >= 0)
{
if (del_node != cur_node->_vnext[level])
cur_node = cur_node->_vnext[level];
else
{
vprev[level] = cur_node;
--level;
}
}
for (size_t i = 0; i < vprev.size(); ++i)
{
vprev[i]->_vnext[i] = del_node->_vnext[i];
}
delete del_node;
return true;
}
private:
Node* _head;
double _p;
size_t _max_level;
};
hpp文件展示
#pragma once
#include <iostream>
using namespace std;
#include <vector>
#include <time.h>
template <class T>
struct SlistNode
{
T _data;
vector<SlistNode*> _vnext;
// 为vnext开辟n个空间,并用nullptr初始化
SlistNode(const T& data, size_t n)
:_data(data)
,_vnext(n, nullptr)
{}
};
template <class T>
class Skiplist
{
public:
Skiplist()
{
srand((unsigned int)(time(NULL)));
_p = 0.25;
_max_level = 32;
_head = new Node(T(), 1);
}
typedef SlistNode<T> Node;
size_t RandomLevel()
{
size_t level = 1;
while (rand() < RAND_MAX * _p && level < _max_level)
{
level++;
}
return level;
}
void add(const T& num)
{
// 先生成随机数,将其作为节点的层数
int level = RandomLevel();
// 如果新节点的层数高与头节点,更新头节点的层数
if (level > _head->_vnext.size())
{
_head->_vnext.resize(level, nullptr);
}
// 节点的构造
Node* new_node = new Node(num, level);
// vprev数组的创建,长度(层数)是level
vector<Node*> vprev(level, nullptr);
// 用cur_node遍历跳表
Node* cur_node = _head;
level -= 1;
while (level >= 0)
{
// num大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// 如果下一节点为空,或者num小于等于下一节点,保存当前节点,进行下一层遍历
else
{
vprev[level] = cur_node;
--level;
}
}
// vprev构建之后,遍历vprev进行节点的插入
for (size_t i = 0; i < new_node->_vnext.size(); ++i)
{
// 每一层都是单链表的插入操作
new_node->_vnext[i] = vprev[i]->_vnext[i];
vprev[i]->_vnext[i] = new_node;
}
}
bool erase(int num)
{
// vprev数组的创建
vector<Node*> vprev;
// 用cur_node遍历跳表
Node* cur_node = _head;
// del_node的初始化
Node* del_node = nullptr;
int level = _head->_vnext.size() - 1;
// 先找到节点的地址
while (level >= 0)
{
// num大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && num > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// num等于下一个节点的值,找到了
else if (cur_node->_vnext[level] != nullptr && num == cur_node->_vnext[level]->_data)
{
// 保存被删除的节点地址
del_node = cur_node->_vnext[level];
// 为vprev开辟空间
vprev.resize(level + 1, nullptr);
// 保存当前的prev地址
vprev[level] = cur_node;
--level;
// 跳出循环,准备进行地址比较
break;
}
// 如果出现num小于下一节点值的情况,说明当前层没有找到,进入下一层找
else
{
--level;
}
}
// 如果上面的循环走完了,del_node还是没有更新,说明没有找到该节点,返回false
if (del_node == nullptr)
{
return false;
}
// 用地址进行节点的查找
while (level >= 0)
{
if (del_node != cur_node->_vnext[level])
{
cur_node = cur_node->_vnext[level];
}
else
{
vprev[level] = cur_node;
--level;
}
}
// 每一层的节点删除
for (size_t i = 0; i < vprev.size(); ++i)
{
vprev[i]->_vnext[i] = del_node->_vnext[i];
}
// 注意节点只有一个,不要把delete放到循环里面
delete del_node;
return true;
}
bool search(const T& target)
{
Node* cur_node = _head;
int level = _head->_vnext.size() - 1;
// level要保持在最低层以上,才能进行查找
while (level >= 0)
{
// target大于下一个节点的值,向右
if (cur_node->_vnext[level] != nullptr && target > cur_node->_vnext[level]->_data)
{
cur_node = cur_node->_vnext[level];
}
// 下一节点为空或者target小于下一节点的值,向下
else if (cur_node->_vnext[level] == nullptr || target < cur_node->_vnext[level]->_data)
{
--level;
}
// 找到返回true
else
{
return true;
}
}
return false;
}
private:
Node* _head;
double _p;
int _max_level;
};
个人对跳表的理解
总所周知,STL库中是没有跳表的,至于说为什么,我想这是因为跳表的构建需要依赖随机数,随机就代表着不确定,没法确定较高层数的节点分布均匀,这就会导致某些区域全是高节点的情况,某些区域全是矮节点,那这些区域不就退化成了O(n)的单链表了吗。不过经过大量的测试,当p = 0.25,max_level = 32或者p = 0.5,max_level = 16时,高节点分布较为均匀。当然这也只是概率较大,虽然用高节点跳着遍历链表是件很爽的事,但这个爽却是不确定的,最主要是因为节点层数随机,以及大量的删除操作影响高节点的分布情况。那么综上所述,要使用跳表,就要最好准备,承担随机带来的后果















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









