




文章目录
写在前面
在Project 3中,我们将实现数据库的查询执行部分。它包括了:
- 不同算子的具体执行逻辑
- 编写优化规则,转换查询计划,以提高其执行效率
相比于Projcet 2,本次项目侧重于源码阅读,我们需要看懂BusTub的查询执行逻辑,弄清楚每个组件之间的关系,否则我们将无从下手。
此外,ButTub提供了Live Shell,我们可以在网页上运行SQL,或是用来debug。由于不同学期实现的BusTub在细节上略有不同,我们需要修改url中的学期字段,以访问相应的Live Shell:
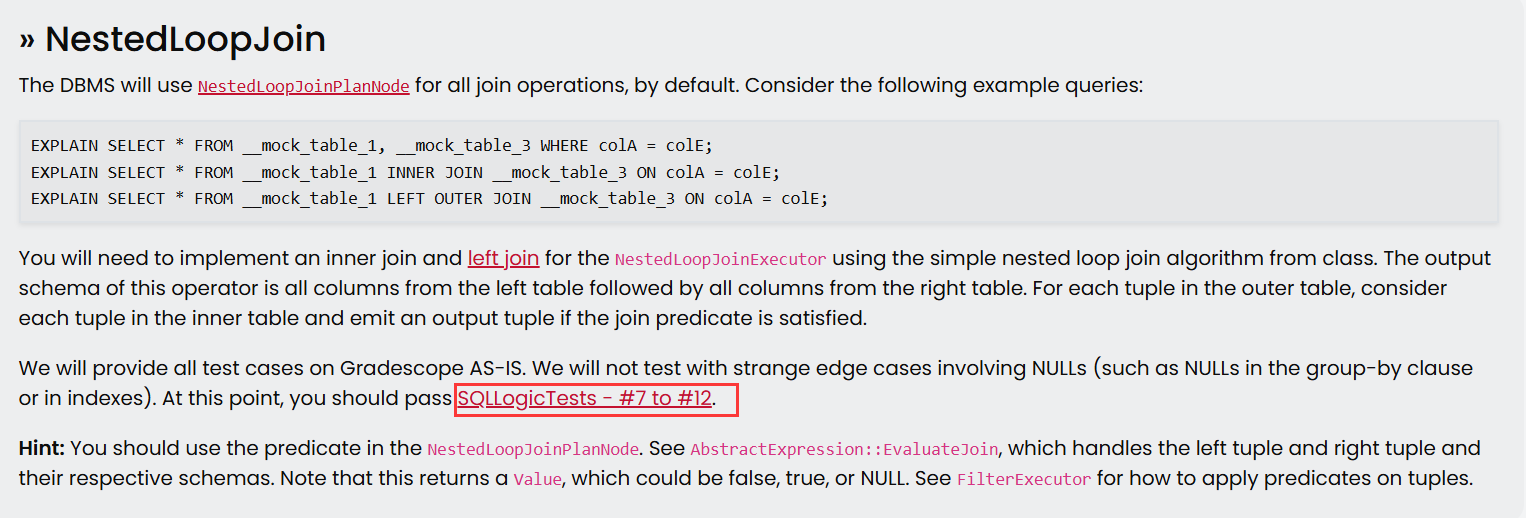
最后Project 3没有隐藏用例,官方将所有测试用例提供给了我们,它们在test/sql/目录下。每当你完成一个Task,文档都会提示你相应的测试用例,你需要通过测试再完成后续Task:
而测试用例的运行方法在文档的最后Testing部分:

make -j$(nproc) sqllogictest
./bin/bustub-sqllogictest ../test/sql/p3.00-primer.slt --verbose
Task 0 - Read the Source Code
首先,我们需要了解一条SQL将如何被数据库执行?官方给出的执行流程图如下:
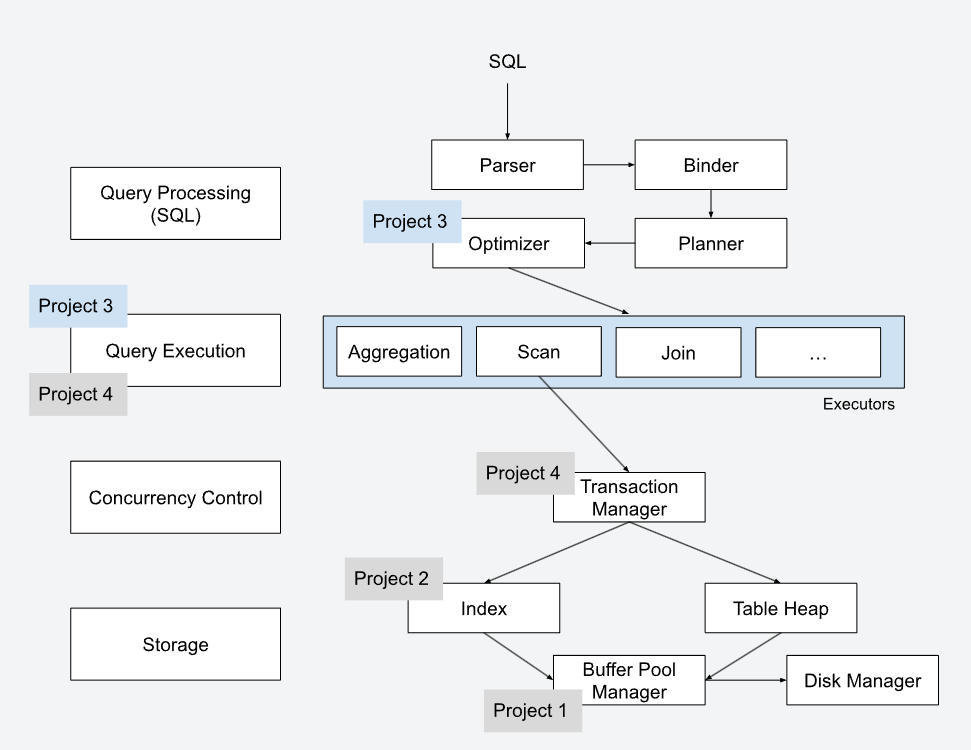
SQL语句的执行将经历五个模块:Parser, Binder, Planner, Optimizer以及Executors
lecture提到了每个模块的具体行为:
- Parser:将SQL文本转换成抽象语法树(如果你学过了编译原理,就能很好的理解)
- Binder:将抽象语法树中的符号(表名、列名、索引名等)转换程DBMS认识的符号(ID、标识符)。转换的同时会进行检查,判断用户的SQL是否合法
- Planner(Tree Rewrite):将抽象语法树转换成树状执行计划,作为优化器优化的起点
- Optimizer(数据库中最难实现的模块):对执行计划进行优化,生成更高效的执行计划
- Executors:依照执行计划,对数据进行查询与处理
BusTub已经实现了前三个模块以及后两个模块的框架,我们只需要阅读Optimizer和Executors模块即可。你需要弄懂的类包括但不限于:
- TableInfo, TableHeap, TablePage, Tuple, Schema, Column, Value, RID, TupleMeta
- AbstractExecutor, AbstractPlanNode, AbstractExpression, ExecutorContext, Catalog
你需要带着问题阅读源码,想一想SQL的运行过程涉及哪些逻辑概念?我给你提供了以下两个问题,当然,我也会做出相应的解答:
- 算子(executor)如何获取数据,BusTub如何描述算子?
- BusTub如何存储表的数据,描述表的结构?
在阅读源码之前,你可能会感到无从下手,官方为我们提供三个实现好的Executor,分别是:
- Projectioin
- Filter
- Values
所有的算子实现在src/execution/目录下,而相应定义在src/include/executor/execution目录下(按着Ctrl再左击类名,会跳转到类的定义,一般编辑器都有这个功能),不妨读一读以上三个算子的实现吧。
以下是我对问题的解答,你应该一边对照着代码,一边往下阅读。不然会一头雾水的: )
算子(executor)如何获取数据,BusTub如何描述算子?
首先你需要知道SQL的处理模型,它一般是树形结构,BusTub使用了火山模型:
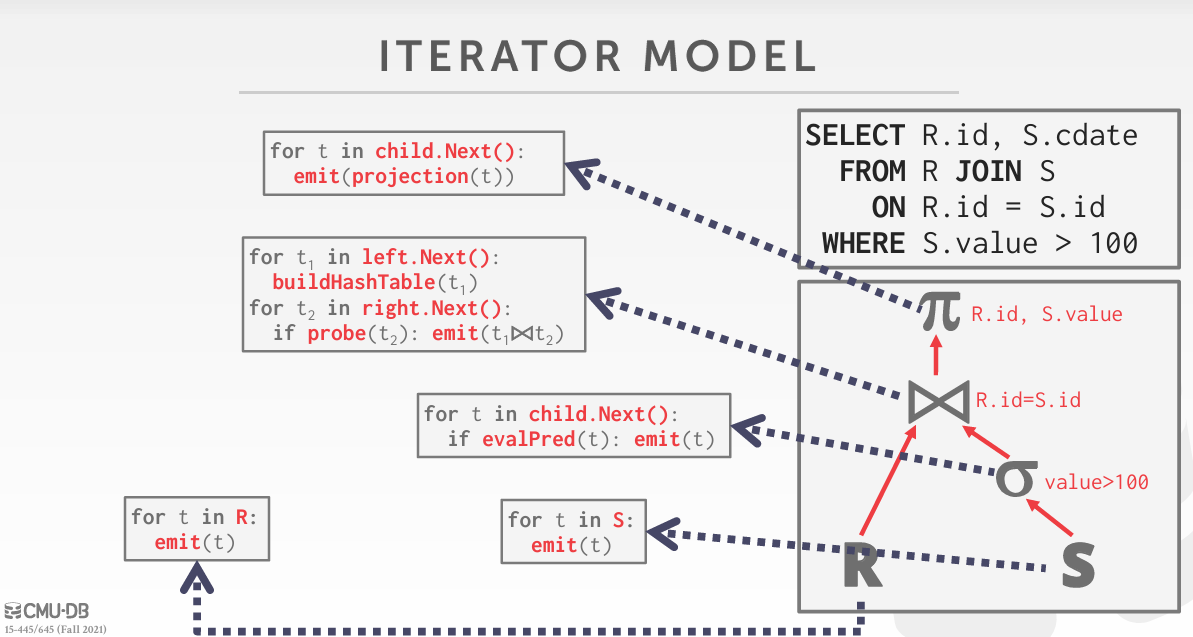
Optimizer将优化逻辑执行计划。上图右下角就是一个逻辑执行计划,它描述了SQL语句要做的事(抽象的),如scan, join, project.
Optimizer还会生成逻辑执行计划对应的物理执行计划。上图中,每个逻辑算子对应一段具体代码,它描述了SQL语句具体要做的事(具体的),比如决定逻辑算子scan应该seq scan还是index scan,join应该hash join还是nested loop loin.
总之,每个逻辑算子都对应着合适的物理算子,如无特别说明,后文所说的算子(executor)指的都是物理算子。
我们发现:逻辑执行计划是一颗树,物理执行计划也是一颗树。在BusTub中,逻辑执行计划树的每个节点为PlanNode,而物理执行计划树的每个节点为Executor。当然Executor存储了相应PlanNode以获取执行过程中需要的信息。
回到火山模型:
- 每个Executor必须具有
Next()方法供上层调用,执行Next()时Executor将返回一条数据或者NULL以表示是否运行完成 - 上层节点不断调用子节点的Next()拽出自身需要的数据
了解了火山模型后,看看Executor的具体代码实现。每个Executor都含有一个成员:PlanNode,以SeqScanExecutor为例,其含有SeqScanPlanNode成员。正如我刚才所说,PlanNode存储了Executor运行时所需的信息,如:table_name_, Expression.
Expression先放在一边,聪明的你应该发现了,Executor还有一个继承自抽象类的成员:ExecutorContext。ExecutorContext保存比PlanNode更多的信息,在Project 3我们只需要关注其Catalog成员。Catalog也有很多成员,这些成员类型我们都认识,无需继续纠结它们。看看Catalog的成员函数,我们发现其管理了所有表和索引。以SeqScanExecutor为例,我们需要用SeqScanPlanNode中的table_name_向Catalog索要表数据,以获取需要扫描的表。
综上,Executor需要访问PlanNode与Catalog,以获取运行时的必要数据。
再捡起Expression,为什么PlanNode要存储它呢?以ProjectionExecutor为例,其Next()方法调用了Expression的Evalute(),这其实是在执行表达式。我们发现BusTub中有以下类型的Expression:

比如这个SQL语句:select col1 from table1,ProjectionExecutor的Expression具体是一个列值表达式,Evaluate()将获取talbe1中的一行数据的col1列。
再以SeqScanExecutor为例,运行SQL语句:select col1 from table1 where col2 = 3时。SeqScanExecutor的Expression就是一个比较表达式,Evaluate()将比较table1中的一行数据的col2列是否等于3。
总之Evaluate()将执行Expression,并返回执行结果。有些Executor可能需要保存执行结果,如Projection的列值。有些Executor可能需要根据执行结果,做下一步判断,如SeqScan的where子句。
综上,我们理清了第一个问题:executor如何获取数据,BusTub如何描述executor?
做个小结:BusTub以AbstractExecutor为抽象类,对于不同executor实现了不同了Executor类。Executor需要通过Catalog和PlanNode获取执行时需要的数据,而Executor通常具有Expression,用于进一步处理获取的数据。
ButTub如何存储表的数据,描述表的结构?
聪明的你在看Catalog时应该发现了,Executor可以通过Catalog的GetTalbe()获取表数据。GetTable()将返回TableInfo,这是一张表的元信息。描述了这张表的结构Schema,名字,表id,以及最重要的TableHeap。
如果你看过Disk Manager那节lecture,你就会知道DBMS的磁盘管理模块的不同管理方式,它们分别是:
- Heap File Organization
- Sequential File Organization
- Hashing File Organization
BusTub使用Heap File的方式管理磁盘,而Heap File又有两种具体实现:
- Linked List
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









