







文章目录
写在前面
Project 4需要我们为数据库实现MVOCC, 也就是基于时间戳的多版本并发控制(OCC + MVCC). 这是一种乐观的控制并发的手段,其原理类似CAS(Compare and Swap). 只不过在compare失败时,事务将被回滚。
Task 1 - Timestamps
1.1 Timestamp Allocation
我们需要为事务赋予两个时间戳(ts),分别是:read ts与commit ts.
理解了read ts和commit ts的关系后,你需要阅读src/include/concurrency/transaction_manager.h并修改src/concurrency/transaction_manager.cpp中的Being()和Commit(). 其中,你会用到last_commit_ts_成员,唯一需要注意的是:我们需要先获取last_commit_ts_ + 1作为当前txn的commit ts, 当前txn完成了对tuple ts更新后,再更新last_commit_ts_.
1.2 Watermark
Watermark用来追踪所有处于RUNNING状态的最小txn read ts, 这将为Task3的GC提供支持。
我们需要实现 O ( l o g N ) O(logN) O(logN)的算法,更新最小read ts.
- 事务提交后,应该从Watermark中移除read ts(RemoveTxn)
- 事务开启后,应该向Watermark中添加read ts(AddTxn)
关于Watermark的成员std::unordered_map<timestamp_t, int> current_reads_: 其表示RUNNING状态的txn read ts, 由于read ts为last commit ts,所以可能存在多个read ts. 因此current_reads_的value为read ts的数量。
你可能对Watermark.commit_ts_感到疑惑,该成员用来表示上一个提交的txn commit ts, 当没有read ts时,将返回commit_ts_. 此外还有一个验证逻辑的用处,我们将在begin txn时,调用AddTxn(),因此read ts一定>= commit_ts_, 否则就是系统的逻辑出现了问题。
你可以使用有序集合set维护最小read ts:
--current_reads_[read_ts] = 0时删除read ts到集合中++current_reads_[read_ts] = 1时添加read ts到集合中
至此,你的实现应该通过测试:/test/txn/txn_timestamp_test.cpp.
Task 2 - Storage Format and Sequential Scan
2.1 Tuple Reconstruction
BusTub在undo log中存储数据的“delta增量”,其表示:你需要对tuple做某些修改,才能得到上一版本的tuple. 因此我们需要完成tuple的重建函数(ReconstructTuple())。
值得注意的是BusTub将undo log存储在内存中,这使得MVOCC更容易实现,但是容灾能力差。
我们可以通过txn mgr的PageVersionInfo获取tuple的版本链,你需要先理清version_info_与prev_version_的关系。在版本链(VersionUndoLink)中,undo log以时间降序存储,越往后修改时间越早。
接下来你需要弄清的问题:如何应用undo log?关于undo log的成员,文档已经给出了详细的说明:
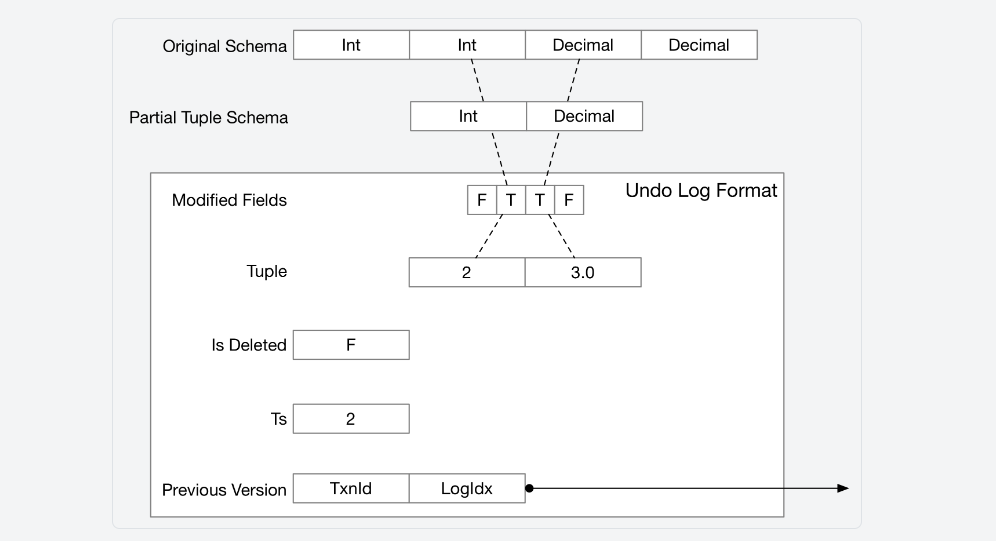
你需要根据undo log的bool数组,得到tuple的schema, 以获取Value. 用这些Value替换原tuple中的Value就能得到tuple的上一版本。如果你认真完成了PJ 3,就能很快地实现以上操作。
值得注意的是:你需要根据undo log的is_delete_以及TupleMeta的is_delete_判断此时重建是否成功。成功重建的情况有:
- undo logs为空但tuple没有被删除
- undo logs不为空且最后一个undo log没有被删除(无需考虑tuple是否被删除)
在遍历undo logs时,你也无需考虑undo log是否被删除,只需应用修改。
2.2 Sequential Scan / Tuple Retrieval
你需要基于刚才实现的ReconstructTuple()实现SeqScan, 此时将重写PJ 3的大部分逻辑。
你需要基于txn read ts构造undo logs, 以调用ReconstructTuple(). 在比较ts时,会遇到三种情况:
- table heap中的tuple已经是最新的(时间戳相等),此时直接返回
- table heap中的tuple(1)被另一个未提交的事务updata,或者(2)tuple的rs大于事务的read ts(这是一个未来的数据),此时需要继续往前回溯(继续遍历)
- table heap中的tuple被未提交的事务updata,但该事务就是自己,此时直接返回即可
那么bustub如何表示:该tuple被一个未提交的事务update?
ts是一个64位的数,而txn id也是一个64位的数。如果tuple的ts最高非符号位为1,说明该tuple被一个未提交的事务update. 而1 << 62是一个非常巨大的数,txn id和ts不会增长到这么大。bustub将1 << 62设置为TXN_START_ID,用TXN_START_ID + txn id作为ts,表示该tuple被id为txn id的事务update. 我们将ts的最高非符号位翻转就能得到一个可读的txn id.
在比较ts时,有两点需要注意:
- 只要遇到可读版本,就无需继续往后遍历,就算该版本被删除
- 可以直接读取tuple, 此时就无需遍历版本链
重建完成后,你还需要根据filter_predicate_判断tuple是否满足过滤条件。
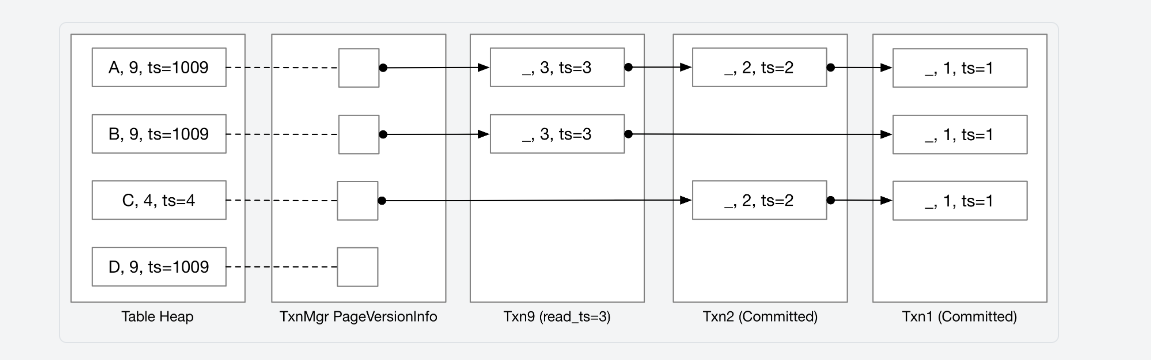
在这个任务中,你还应该理清UndoLog, UndoLink和txn之间的关系,关于文档中的图:
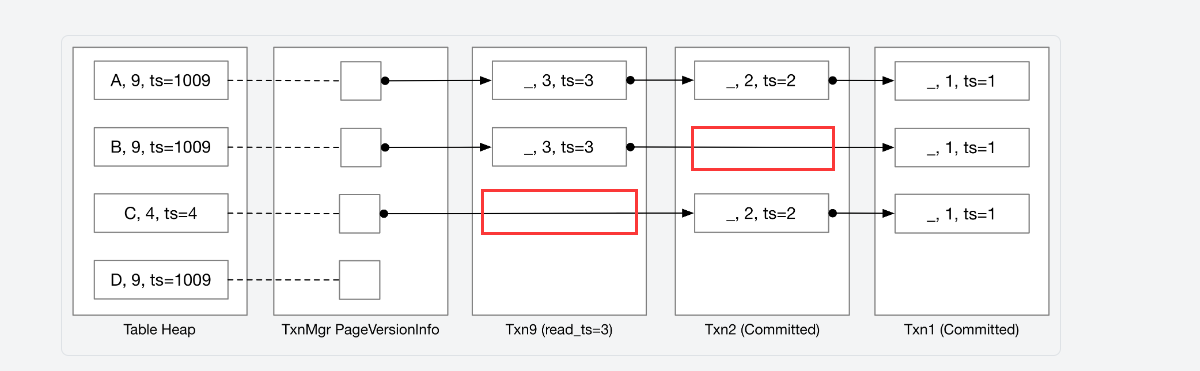
为什么我框出的地方没有undo log? 这是因为undo log被存储在txn中,undo log以txn为单位保存。txn具有成员std::vector<UndoLog> undo_logs_,当txn修改了tuple, 就需要保存相应的undo log到undo_logs_中。再看UndoLink的成员
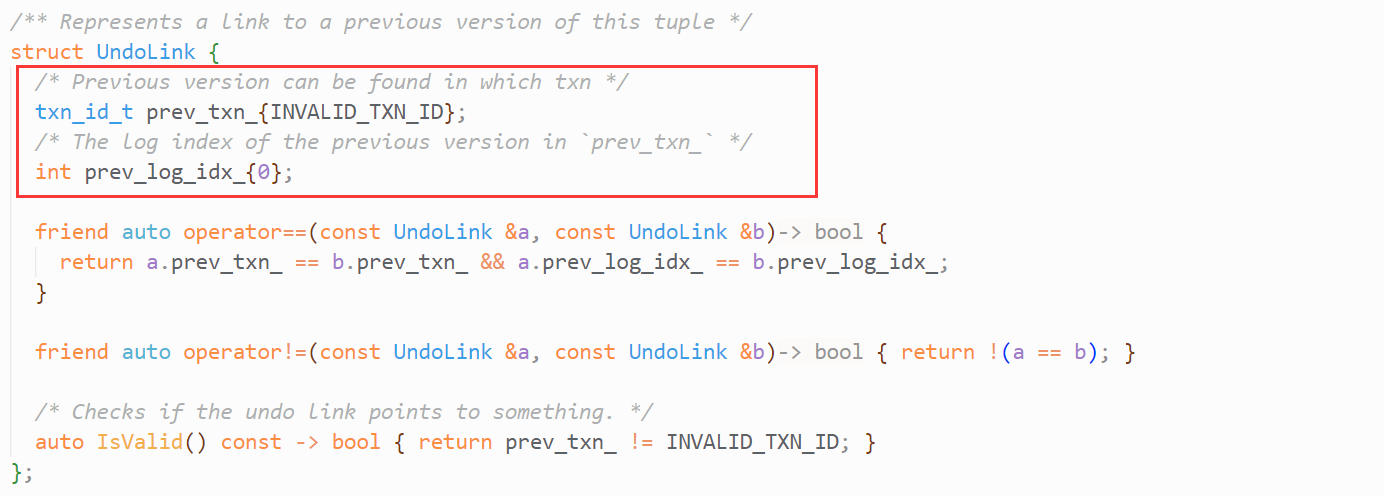
- prev_txn_为事务id, 指向了一个事务
- prev_log_idx_是Transaction的undo_logs_数组下标
通过这两个参数,UndoLink就能指向某个事务中的UndoLog, 你可以将UndoLink理解为单链表中的指针,将UndoLog则是单链表中的节点。而UndoLog呢?
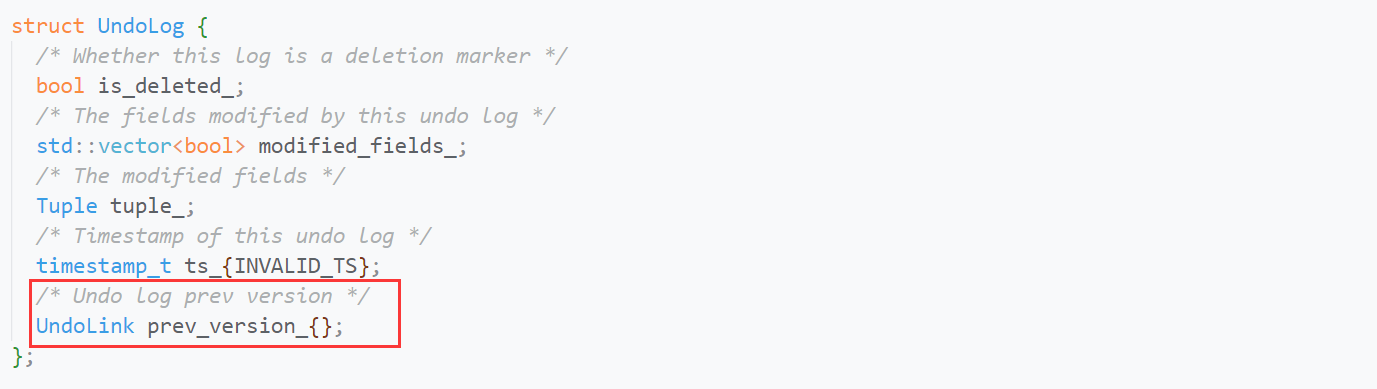
它保存了UndoLink, 用来指向下一个UndoLink. 这不就是我们熟悉的单链表吗: )
此时你再看看文档中的图,就能明白为什么要这么画了:
至此,你的实现应该通过测试:/test/txn/txn_scan_test.cpp.
Task 3 - MVCC Executors
在这个任务中,你需要实现三个涉及修改的Executor, 以及Commit()逻辑,且不需要索引的维护。
3.1 Insert Executor
我们需要使用UpdateUndoLink与UpdateLinkVersion这两个函数,来更新版本链。暂时不同关心check参数,你需要明白这两个函数将如何更新?
UpdateUndoLink最终将调用UpdateLinkVersion, 不管UpdateUndoLink对check做的封装,直接看UpdateLinkVersion.
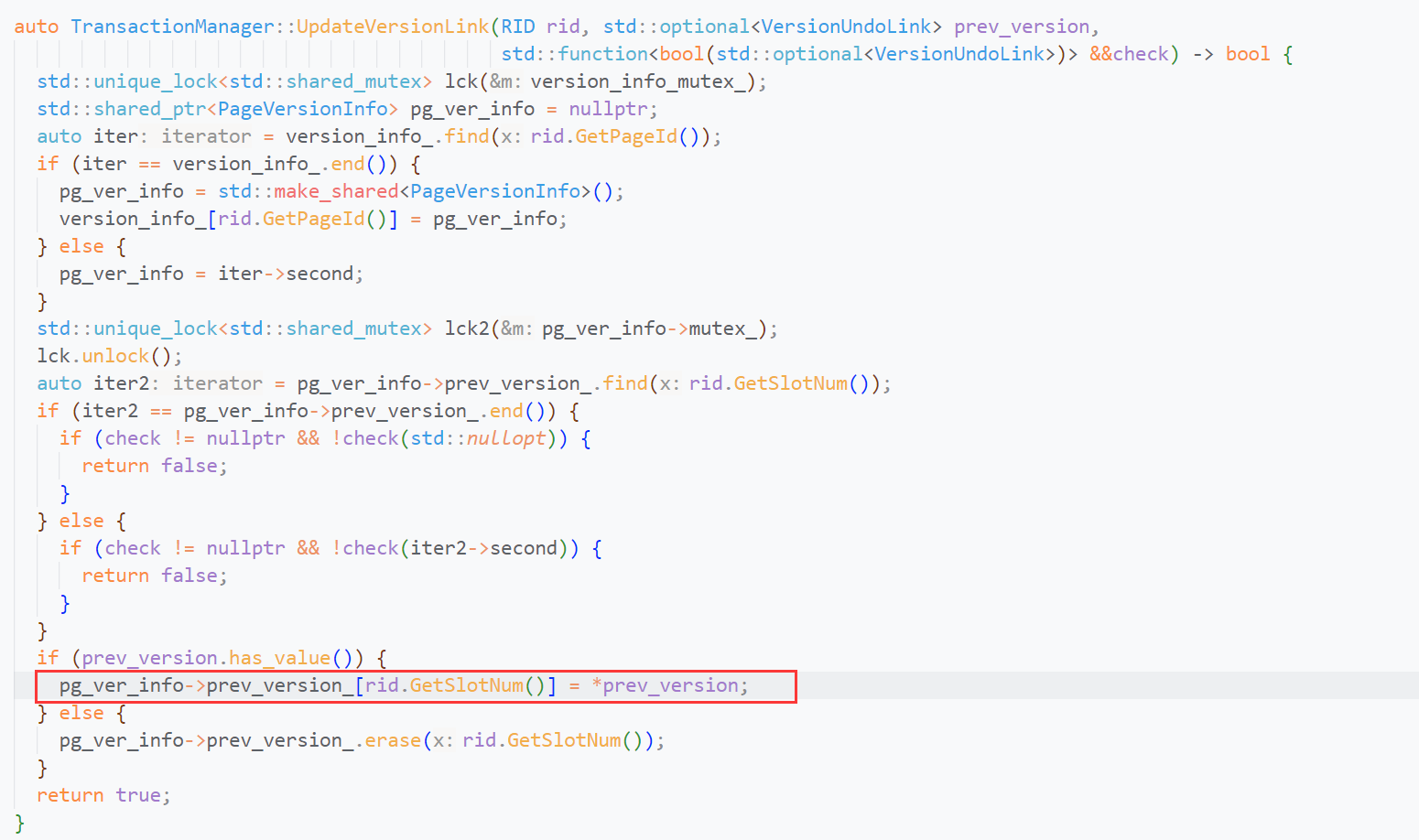
你会发现UpdateLinkVersion最终将用你传入的prev_version更新txn mgr的prev_version_.
prev_version_以slot_offset保存了某个页中所有tuple的版本链信息,如下所示:

被更新的VersionUndoLink则是对UndoLink的封装,你可以理解为:单链表的伪头节点,其保存了单链表第一个有效节点。
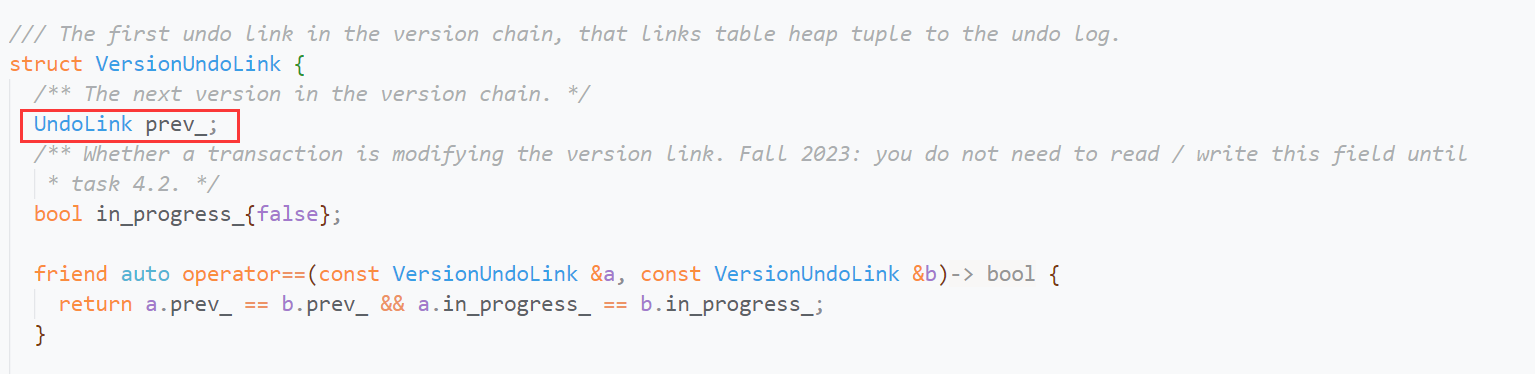
因此我们需要在更新前获取版本链,保存其第一个UndoLog. 将我们的UndoLog.prev_version指向版本链的第一个UndoLog, 再调用UpdateLinkVersion, 更新伪头节点的prev_verion, 使我们的UndoLog成为版本链的第一个UndoLog.
但是insert操作不会生成undo log, 因为不涉及对tuple的修改,所以在UpdateUndoLink时,我们可以传入一个无效的UndoLink. 或者按照文档说的,传入std::nullopt. 对于刚刚insert的tuple, 没有版本链,或是版本链指向无效的UndoLog, 我觉得都是正确的。
你需要在insert后维护txn的write_set_.
3.2 Commit
遍历txn的write_set_, 根据RID更新TupleMeta: 将表示txn id的ts设置为commit ts.
需要注意的是:你不应该修改TupleMeta的is_delete_状态
至此,你的实现应该通过/test/txn/txn_executor_test.cpp中有关insert与commit的测试。
3.3 Update and Delete Executor
update和delete时,tuple已经存在。我们需要获取其TupleMeta, 通过ts判断其是否正在被其他事务修改(tuple ts >= TXN_START_ID && tuple ts != txn id),或是已经被未来的事务修改(read ts < tuple ts < TXN_START_ID)。如果满足了以上条件,则发生了写写冲突,我们需要终止当前事务(throw ExecutionException)。
如果未发生冲突,你需要判断该tuple是否被删除。
如果未被删除,你需要判断(tuple ts == txn id). 如果表达式成立,则说明当前事务之前就操作了tuple, 此时需要进行自我修改。你需要查看该tuple的VersionLink, 第一个undo log是否存在。如果存在,其创建者一定是当前事务,说明之前就对tuple进行了update操作。此时你需要在第一个undo log的基础上生成undo log, 也就是先应用之前的update,再应用当前的update. 如果只根据直接生成undo log, 可能丢失之前的增量信息,无法正确重建tuple. 生成undo log后,替换原来的undo log(txn.ModifyUndoLog()), 再update bast tupple即可。
而如果VersionLink不存在undo log, 说明当前事务之前只进行了insert操作。此时无需维护版本链,直接update bast tuple即可。
如果(tuple ts == txn id)不成立,那么实现正常的update逻辑即可:
- 生成undo log
- 维护txn.write_set_与txn.undo_logs_
- 构建指向undo log的UndoLink, 更新版本链
- 更新base tuple
至于说如何获取更新后的Value以构建tuple, 调用PlanNode的Expression即可。你会发现,target_expressions_的长度和table的列数相同,如果Evaluate()得到的Value与原Value不同,则是发生了更新。如果相同,则是没有更新。
对于delete, 逻辑基本相同,只是undo log需要保存完整的tuple以及update TupleMeta. 至于delete的自我修改,读者可以参考update的自我修改,想想什么情况下会发生delete的自我修改,以及存在有效undo log时,应该怎么更新undo log?
值得注意的是:构建undo log时,其成员ts_应该是txn的read ts还是base tuple的ts? 总不可能是当前的txn id吧。
至此,你的实现应该通过/test/txn/txn_executor_test.cpp中的相关测试用例。
Task 3.4 Stop-the-world Garbage Collection
当所有的事务停止时,将自动触发GC垃圾收集。我们需要根据Task1实现的Watermark获取最小read ts. 接着遍历table heap, 获取tuple的RID. 通过RID获取tuple的VersionLink(GetUndoLink()), 你需要遍历tuple的undo log, 如果undo log ts < watermark, 将undo log的is_delete置为true.
最后通过txn_map_遍历所有txn,如果txn的所有undo log被删除,则将txn从txn_map_中移除. 但是你不能删除未提交(COMMITTED)的txn
值得注意的是:移除txn将导致UndoLink指向不存在的undo log, 即产生悬空指针。你应该调用GetUndoLogOptional(),通过返回值是否有效来判断是否产生了悬空指针。
至此,你的实现应该通过/test/txn/txn_executor_test.cpp中的所有测试用例。
Task4 - Primary Key Index
最后一个Task, 你需要修改前三个Task实现的代码,使之能够在多线程环境下安全运行。同时,你需要维护主键索引。
4.1 - Inserts
由于主键索引的唯一性约束,你需要检查table是否含有主键索引。如果含有主键索引,且相同主键的tuple已经存在,那么你需要SetTainted+throw ExecutionException, 终止当前事务。
因此你需要在一开始添加检查逻辑,如果不存在主键冲突,你可以将当前tuple插入。但是在多线程环境下考虑:以上逻辑是否存在数据竞争?
检查不存在主键冲突,到实际InsertTuple的这段时间中。由于没有添加访问控制,在这段时间中可能发生:其他事务也通过检查并插入了相同主键的tuple, 导致了你之前的检查无效。这是一个TOCTTOU问题,你无法保证之前的检查一定正确。所以你需要依赖PJ 2实现的线程安全的索引结构。在最后插入索引时判断InsertEntry的返回值,如果失败,SetTainted+throw ExecutionException. 因为存在TOCTTOU问题。
4.2 Index Scan, Deletes and Updates
Index Scan
我们需要先实现index scan执行器,为update和delete提供索引支持。
索引应该始终指向一个RID,即使相应的tuple被删除。这将使得更早的事务能够通过索引访问tuple的历史版本。所以,insert tuple时,可能不需要insert index. 因为相同主键的tuple曾经存在,现在被删除了,我们只需要更新base tuple即可。
以下是文档给出的例子:
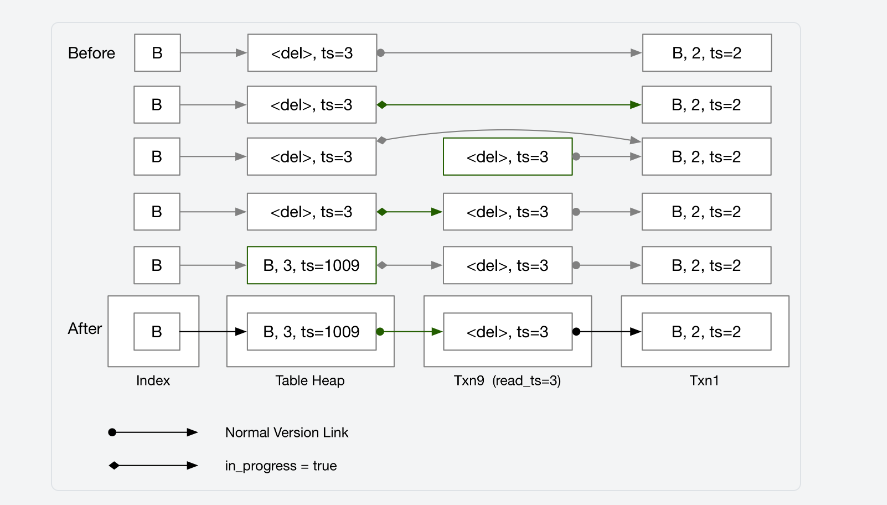
可以看到:发生主键冲突时,我们需要检查tuple是否被删除。如果被删除,更新base tuple即可。如果没有被删除,则是发生了正在的主键冲突。所以,我们还需要修改刚刚写好的insert算子。
回到index scan, 你需要在Init中用primary key扫描索引(ScanKey),并保存结果(rids)。接着在Next中遍历扫描结果,根据txn read ts重建tuple, 这个过程和SeqScan类似。
关于in_progress_
文档介绍了VersionUndoLink的in_progress_字段,修改tuple前需要判断该tuple是否in_progress_, 如果正在被使用,当前事务就不能使用,需要SetTainted+throw ExecutionException.
总之文档的意思就是:使用in_progress_实现tuple lock. 一个很明显的TOCTTOU问题,检查in_progress_为false到修改其为true的这段时间内,无法保证in_progress_总是为true. 可能多个事务通过了检查,将其修改为true.
本质问题是:check-set这个过程不是原子操作,代码如下:
if (!in_progress_) { /** 检查 */
in_progress_ = true; /** 使用 */
}
大概有两个解决方法:
std::atomic<bool>std::mutex
BusTub选择了后者(严格来说,两个都不是),可能读者会感到疑惑:VersionUndoLink没有mutex啊?这个mutex其实是txn mgr的页锁:
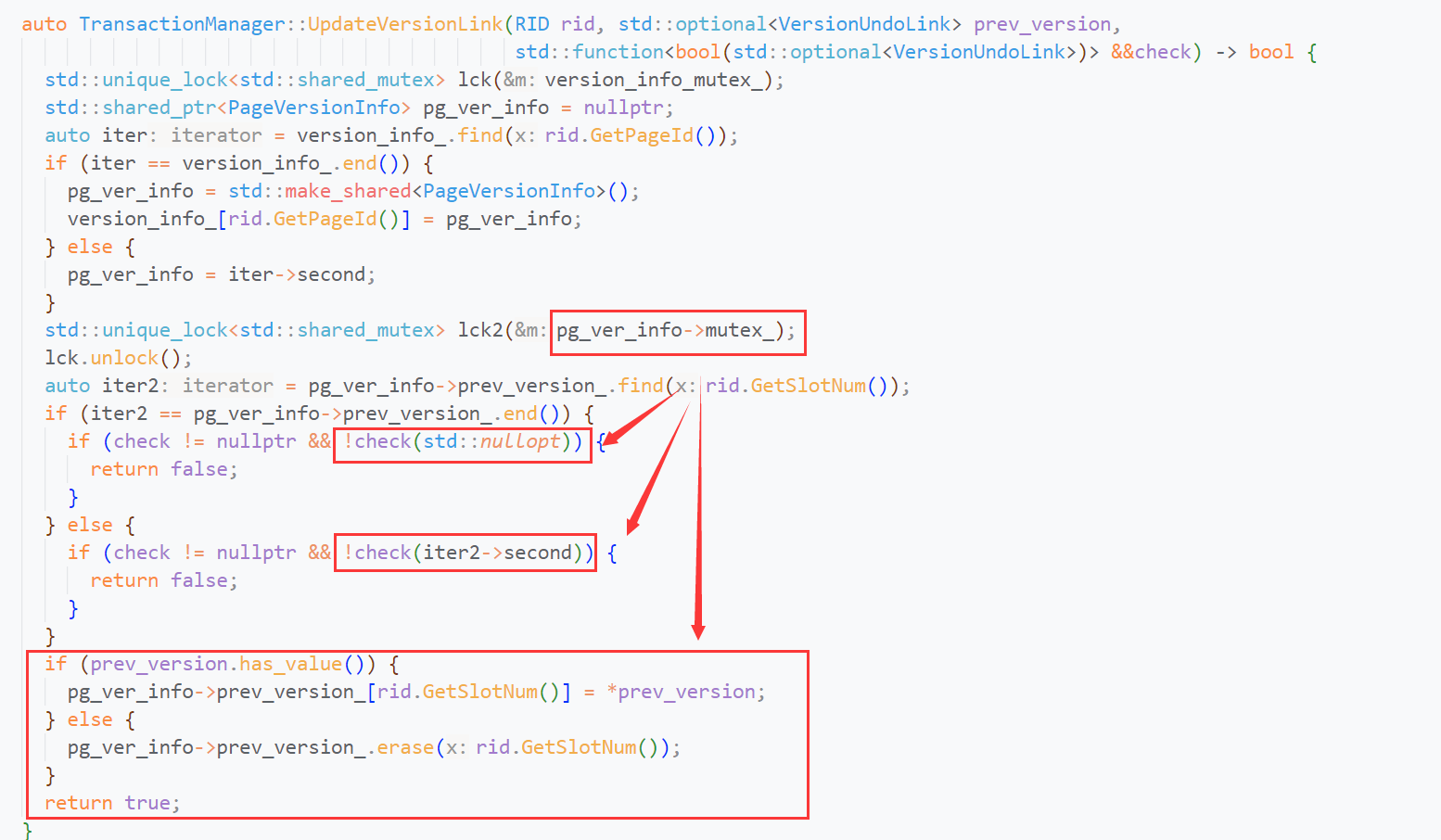
可以看到:在UpdateVersionLink时,需要获取tuple所在page的mutex, 再更新tuple的VersionUndoLink. 再看看这个临界区还进行了什么操作?没错,check().
check什么呢?回到一开始的问题,我们要保证in_progress_的check-set是原子操作。将check-set放到临界区,自然就成了原子操作: )
你可以理解为:在临界区外check一次,又在临界区内check一次,就是为了保证临界区外的check正确。那么我们要check()什么呢?
- in_progress_为false(保证之前的check结果正确)
- VersionUndoLink没有发生变化(虽然之前的check结果正确,但是in_progress_经历了
false-true-false, 那么tuple的版本链一定发生了变化)
综上,check()不仅保证了in_progress_的check-set的原子性,还保证了tuple不被其他事务修改。因此,实现了check()后,我们可以将in_progress_视为tuple lock. 事务修改tuple前,必须获取tuple lock. 如果获取失败,SetTainted+throw ExecutionException.
或许你会对tuple ts与in_progress_感到疑惑,当tuple ts为txn id时,表示tuple正在被某个事务操作。当in_progress_为true时,也表示tuple正在被某个事务操作。不同的是tuple ts将指明哪个事务正在操作,而in_progress_无法指明具体的事务。对于这两个功能类似的字段,其实我也感到疑惑: ) 为何tuple lock要通过in_progress_实现,不能通过tuple ts实现吗?
最后,in_progress_应该在Commit()时设置为false. 毕竟tuple ts也是在Commit()时被设置为commit ts, 就算提前释放了in_progress_, 其他事务也无法访问tuple.
Inserts
实现了check()后,你可以将其封装为GetTupleLock(), 然后试着重写insert算子。如果你的实现无法通过测试,可以参考我的insert逻辑:
·检查唯一性冲突
·存在唯一性冲突
·检查tuple ts, 判断是否是自我修改(只有可能是先delete再insert)
·如果是自我修改,更新base tuple即可
·检查tuple ts, 不能操作(1)未被删除(2)其他事务正在操作(3)被未来事务修改过的tuple
·通过检查后,GetTupleLock(), 构建UndoLog, 维护txn的write_set_, undo_logs_, update VersionUndoLink, update base tuple
·不存在唯一性冲突
·table中没有相同主键的tuple, 执行正常的insert逻辑
以上,存在一个“让我调试了9小时的bug”。当然,这是一个细节问题:你应该在GetVersionLink()后GetTuple().
如果你在GetTuple()后获取GetVersionLink(),在GetTuple()~GetVersionLink()这段时间内,其他事务对tuple进行了修改,更新了版本链。那么你获取的tuple就是更新前的, 而VersionUndoLink确是更新后的,这其实又是一个TOCTTOU问题(多线程环境下,真的处处充满了TOCTTOU啊)。聪明的你不妨停下来想想这样会发生什么问题?
没错,这样会覆盖其他事务的修改。所以你应该在GetVersionLink()后GetTuple(), 因为之后的check()保证了之前获取的VersionUndoLink没有变化,那么base tuple也一定没有变化。要是实在不放心,你可以在GetTupleLock()后,再调用一次GetTuple(). 如果与之前获取的base tuple不同,SetTainted+throw ExecutionException.
以及,你需要先维护txn的undo_logs_再维护版本链(UpdateVersionLink()). 先维护版本链可能导致undo_logs_的越界访问。
最后,UndoLog的is_delete_字段需要与base tuple的is_delete_保持一致(在Task4前,将其设置为false即可)。
Deletes
deletes时,不应该删除索引。引入主键索引和check()后,deletes的逻辑为:
·检查是否自我修改
·如果是自我修改,检查是否存在UndoLog
·若存在UndoLog且未被删除, 应用它(撤销之前的update), 以构建新的UndoLog, 最后更新txn的undo_logs_与TupleMeta
·若不存在,只需更新TupleMeta
·检查tuple ts, 不能操作(1)正在被其他事务操作,(2)被未来事务修改过的tuple
·若通过检查,GetTupleLock(), 构建UndoLog, 更新txn的write_set_与undo_logs_, 以及TupleMeta与VersionUndoLink
Updates
在Task4.2中,你不需要考虑主键更新的情况。引入主键索引和check()后,updates的逻辑为:
·检查是否自我修改
·如果时自我修改,检查是否存在UndoLog
·若存在UndoLog且为被删除,基于该UndoLog生成新的UndoLog, 更新txn的undo_logs_与base tuple
·若不存在UndoLog,只需要更新base tuple
·检查tuple ts, 不能操作(1)正在被其他事务操作,(2)被未来事务修改过的tuple
·若通过检查,GetTupleLock(), 构建UndoLog, 更新txn的write_set_与undo_logs_, 以及base tuple与VersionUndoLink
似乎逻辑和deletes相同: ) 由于你的实现与我不同,所以请认真检查是否存在TOCTTOU问题:检查代码中所有类似“检查–修改/更新”的操作,因为“修改/更新”一定在GetTupleLock()后,所以你只需关心GetTupleLock()前的“检查”是否正确即可。你可以在脑海中模拟极端场景:当前线程执行完“检查”就被调度走,并且在很长一段时间无法得到执行,当线程恢复执行后,你的保护手段是否能防止数据竞争的出现?
当然,除了难以处理的多线程bug,你也需要保证单线程环境下,基本的逻辑没有问题。总的来说,你需要考虑:
- 将要操作的tuple是否正在被其他事务使用?
- 如果是的话,tuple是否正在被自己使用?
- 自我修改时,是否存在UndoLog? 如果存在UndoLog, 一定是当前事务创建的吗?你需要应用它吗?
- GetUndoLog()是否会因为GC的清理而访问野指针?
- …
4.3 Primary Key Updates
在Task4.3中,你需要为updates添加新的逻辑,以支持主键的更新。
根据文档的实例讲解,你会发现:不能一条tuple一条tuple地更新,这会触发写写冲突,使得原本能update成功的语句执行失败。因此,你需要在updates时,一条一条地删除tuple, 同时记录新的tuple, 在最后将新的tuple一并插入到table中。
以上,删除与插入的逻辑和已经实现的deletes与inserts完全相同,你可以将deletes与inserts的逻辑抽出,封装成函数到executor_common.h中。
写在最后
完结撒花~ 原来写代码是件这么爽的事哈哈,感谢Andy与TAs的辛勤付出,(主观的说)这几乎是最好的数据库入门课程了。
2023 Fall的PJ 1大概有240人完成,最后的PJ 4只有不到160人完成,我没算错的话,少了三分之一的人: ( “行百里者半九十”,希望各位读者能有始有终,坚持到最后捏: )
如果你对文章的某些描述感到疑惑,或是发现了文章的错误,欢迎在评论区提出: )















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









