







线性表分为顺序表和链表
顺序表
顺序表分为静态顺序表和动态顺序表
静态顺序表
#define CAPACITY 10
typedef int SeqDataType;
typedef struct SeqList
{
SeqDataType a[CAPACITY];//最多存储CAPACITY个值
int size;//已存数据个数
};
数组大小固定,存放的数据个数有上限
动态顺序表
#define INIT_CAPACITY 4
typedef int SLDataType;
typedef struct SeqList
{
SLDataType* a;//指向开辟空间的首地址
int size;
int capacity;
}SL;
能够不断扩容
if (ps->size == ps->capacity)
{
SLDataType* tmp = (SLDataType*)realloc(ps->a, sizeof(SLDataType) * ps->capacity * 2);
if (tmp == NULL)
{
perror(" PushBack realloc fail");
//判断后要有返回操作,不然还是会报警告
return;
}
ps->a = tmp;
//容量也发生改变
ps->capacity *= 2;
}
动态顺序表的成员a指向一段新开辟的空间,当空间满的时候可以realloc扩容,增加表的容量
链表
单链表
typedef int SLTDataType;
typedef struct ListNode
{
SLTDataType data;
struct ListNode* next;
}SLTNode;
next指向下一个节点的地址,单链表我们一般不加哨兵位,所以当第一个指针的指向发生改变我们要传二级指针才能改变一级指针的值。

此外还要注意删除操作时,如果只有一个节点,删除后别忘了把头指针的指向也要置成空。
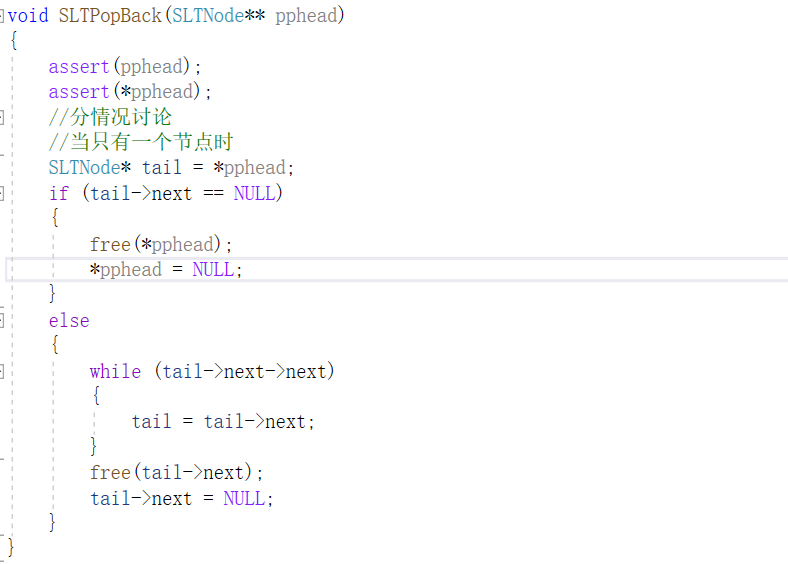
链表有很多容易出错的地方,要仔细判断插入或删除操作时,头指针的指向会不会发生改变。
双向链表
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
双向链表这里我们增加了哨兵位,带哨兵位的好处就是不需要传递二级指针
栈
栈在实现时我们选择的底层数据结构是顺序表(数组)
因为栈是在一端进行操作的,且我们要让使用的数据结构便于增删查改,数组在这里相对于链表的优势就在于,当它删除的时候便于找到最后一个数据的前一个的位置,另外数组的地址是连续的比链表的效率要高。
#define INIT_CAPACITY 4
typedef int STDataType;
typedef struct Stack
{
//struct Stack* a;
int* a;//指针指向的类型为int,不是指向结构体
int top;
int capacity;
}ST;
栈易出错的地方在于top的初值是设为-1还是0,两种都可以但是为了更容易理解我们一般选用初值为0,即top指向的是栈顶元素的下一个位置,top值就是元素的个数

队列
队列实现的底层数据结构是链表,因为它是一端进一端出,用数据组实现的话,再删除一些数据后,前面就空出来了,会造成空间上的浪费,可以删除后让其它数据向前移动,当这样就会增加实践复杂度。而用链表实现的话我们可以设置两个指针一个指向第一个节点一个指向最后一个节点。
#define QDataType int
//队列先进先出
//定义队列单个节点结构
typedef struct QNode
{
struct QNode* next;//指向下一个队列节点
QDataType data;
}QNode;
typedef struct Queue
{
QNode* front;//指向队列的头
QNode* tail;//指向队列的尾
int size;//队列的长度
//为什么不把size直接放到struct QNode结构体中?
//因为如果放到struct QNode这里面size相当于局部变量,每个节点的size都是不相同的,
//我们要的size是队列的总长度
}Queue;
这里我们使用了结构体嵌套,同时保证了size的正确性。
小结
以上几种数据结构如果需要改变原结构体变量的地址就要定义指针变量,从而方便传递二级指针,如果不需要则定义结构体变量即可,只是为了方便,两种都可以
顺序表

单链表

双链表

栈
队列

















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











