







文章目录
堆排序序言
什么是堆排序?为什么要用堆排序?堆排序的优势是什么?这些都是值得我们思考的问题,在讲解堆排序之前,我们需要理清这些问题,熟悉堆的概念。
堆是什么?
想要详细了解可以看这个网页
这里我可以大概说说:
堆可以分为两种,分别是大根堆和小根堆,二者有什么区别呢?
最大堆:
在最大堆中,父节点的值比其每一个子节点的值都要大,如图所示:
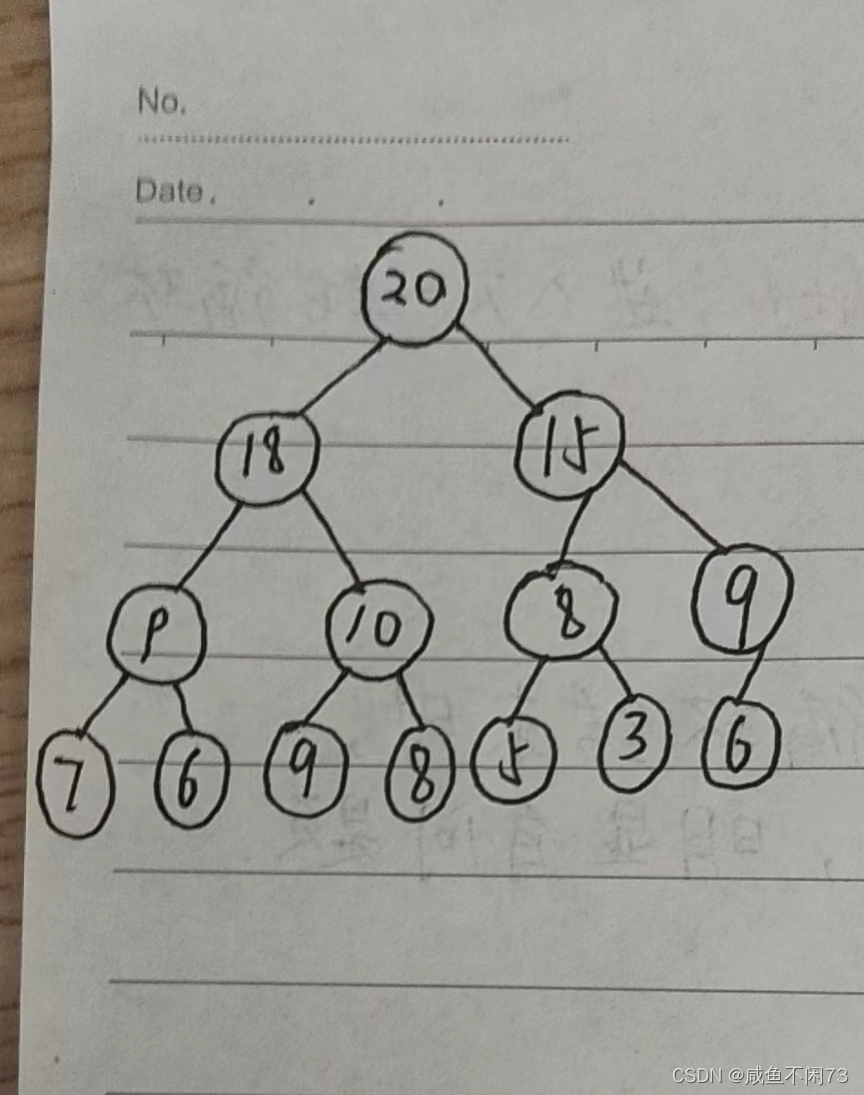
由图易得,20比18和15大,18比9和10大,15比8和9大。
最小堆:
最小堆的性质与最大堆相反,父节点的值比其每一个子节点的值都要小,这里不再举例。
为什么要用堆排序?
堆排序是一个很重要的排序算法,它是高效率的排序算法,复杂度是O (nlogn),堆排序不仅是面试进场考的重点,而且在很多实践中的算法会用到它,比如经典的TopK算法、小顶堆用于实现优先级队列。
堆排序的有什么优势?
堆排序的时间复杂度仅为(ologn),样本数据大时展现出极大的优势,而且堆的逻辑思维清晰,与完全二叉树相似。
堆的逻辑结构
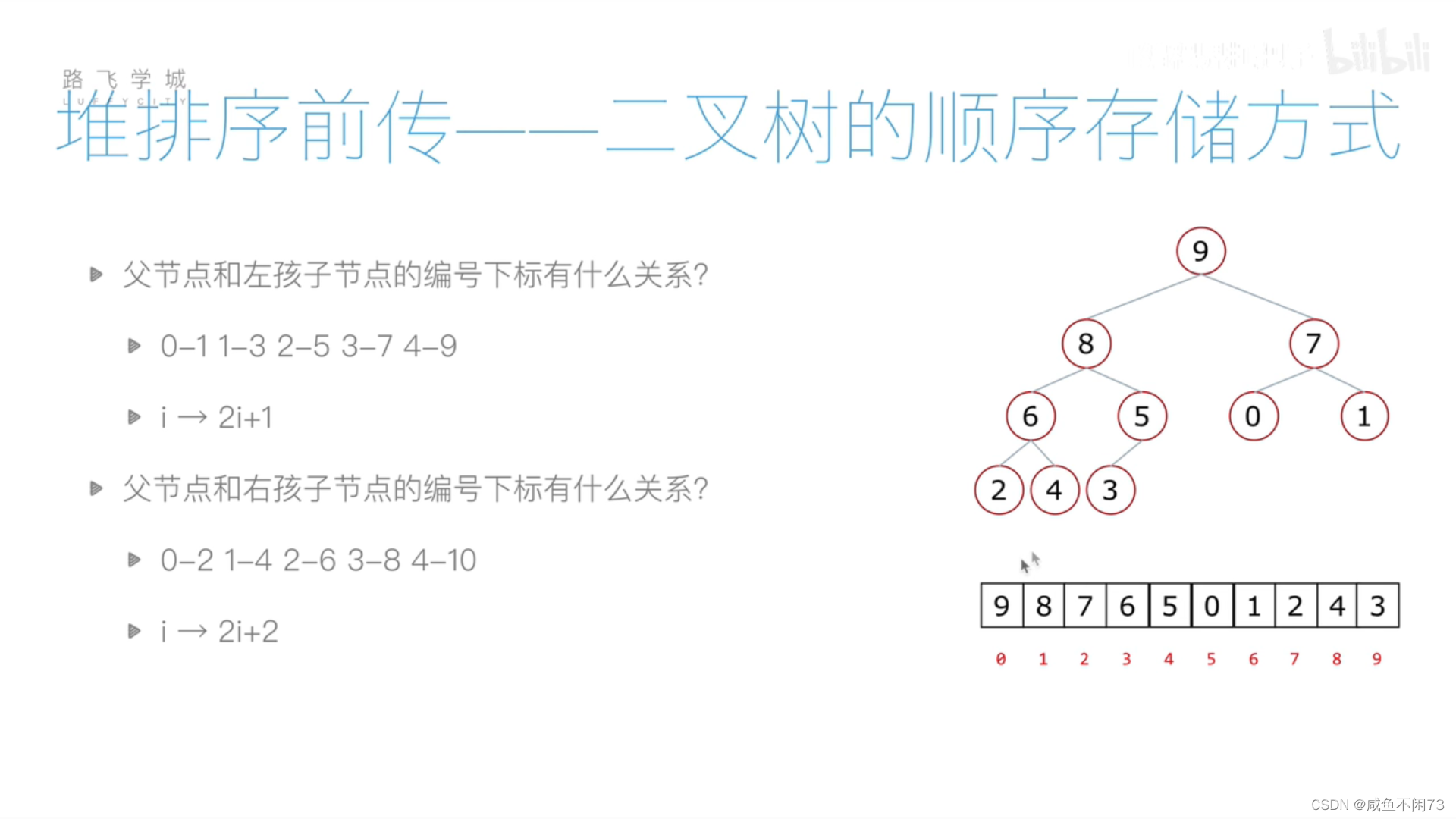
堆的逻辑结构与完全二叉树类似。
左边子节点位置设为 j,右边子节点的位置设为k,其父结点的1位置设为i。
则 j =2i +1 ; k=2i+2 ;这里我引用《清华Python》讲解。
堆的向下调整结构:
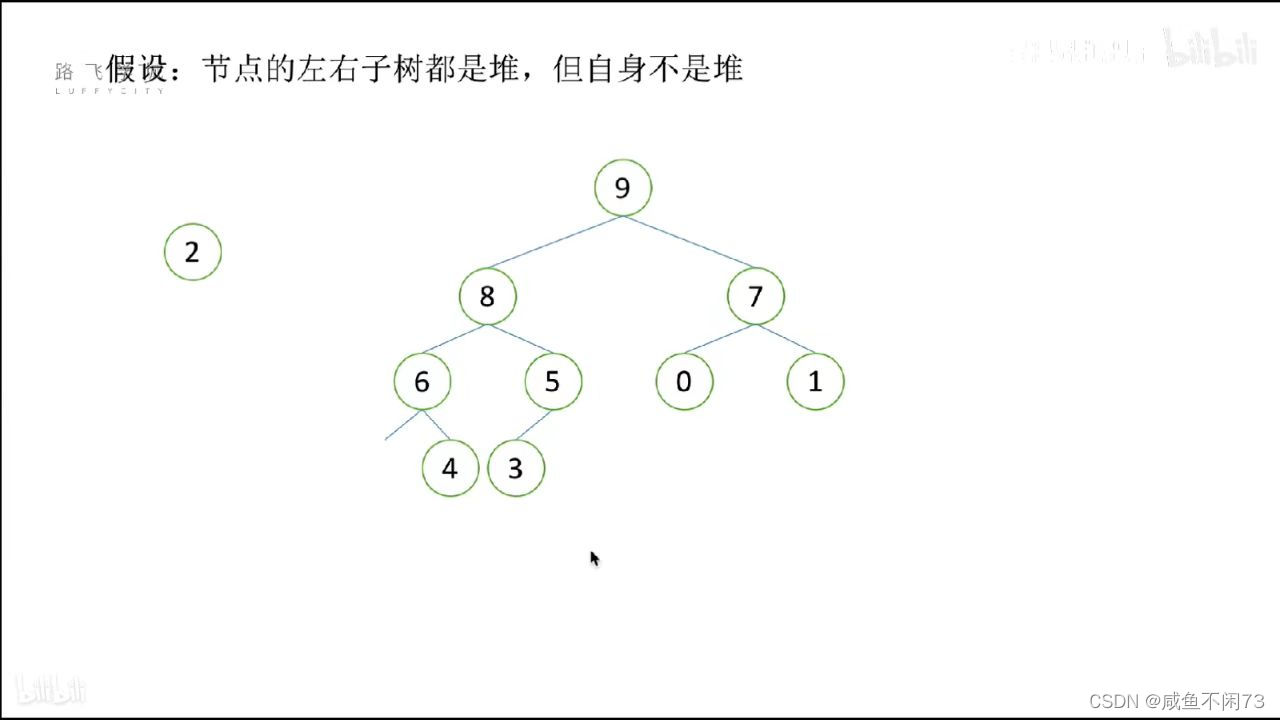
首先,有一个没有构建好的堆:
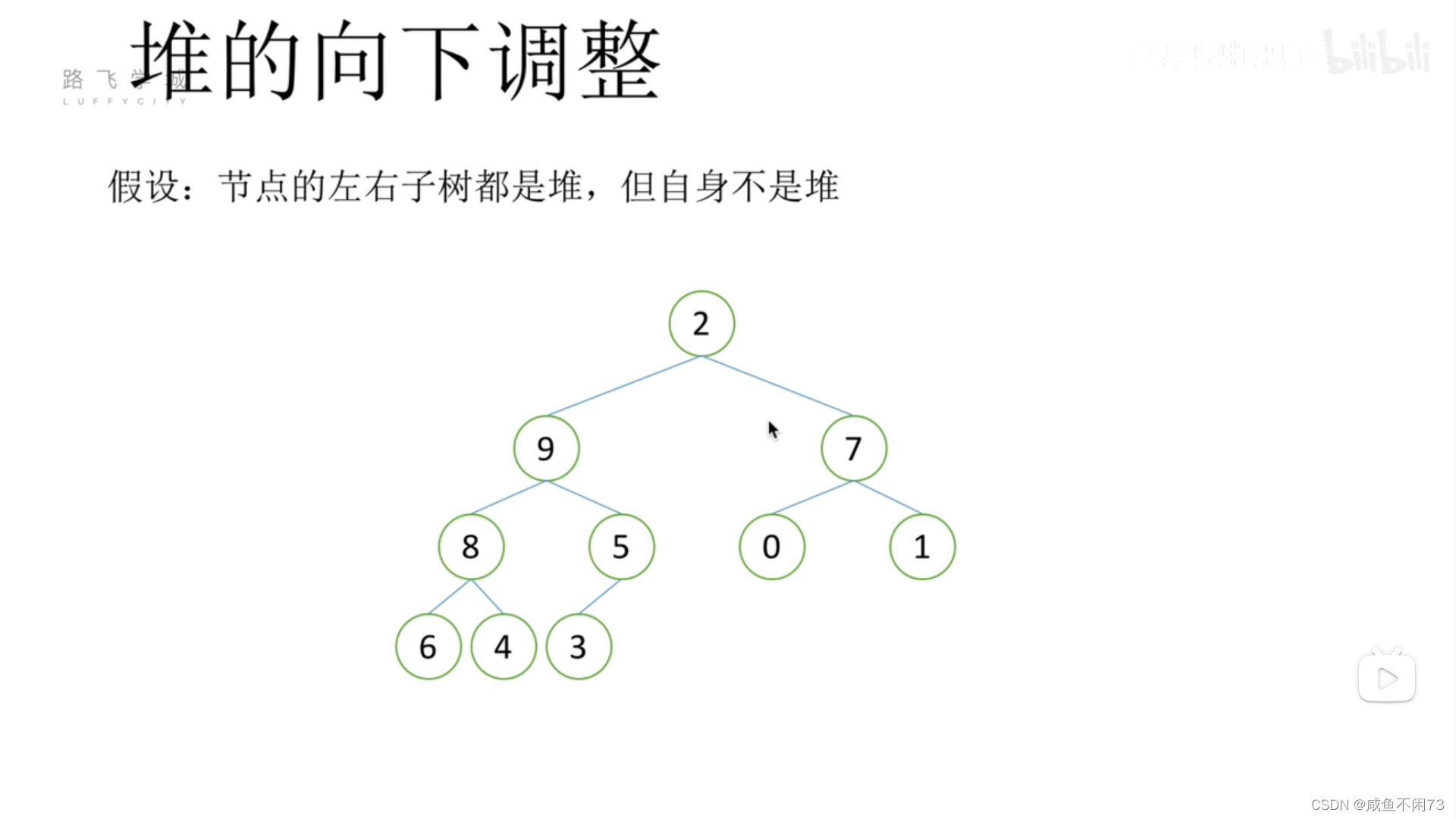
可以看出,2不能放在堆的根部!
那么我们现在开始调整2的位置,使其放在合适的位置:
首先将2从根部“移走”:
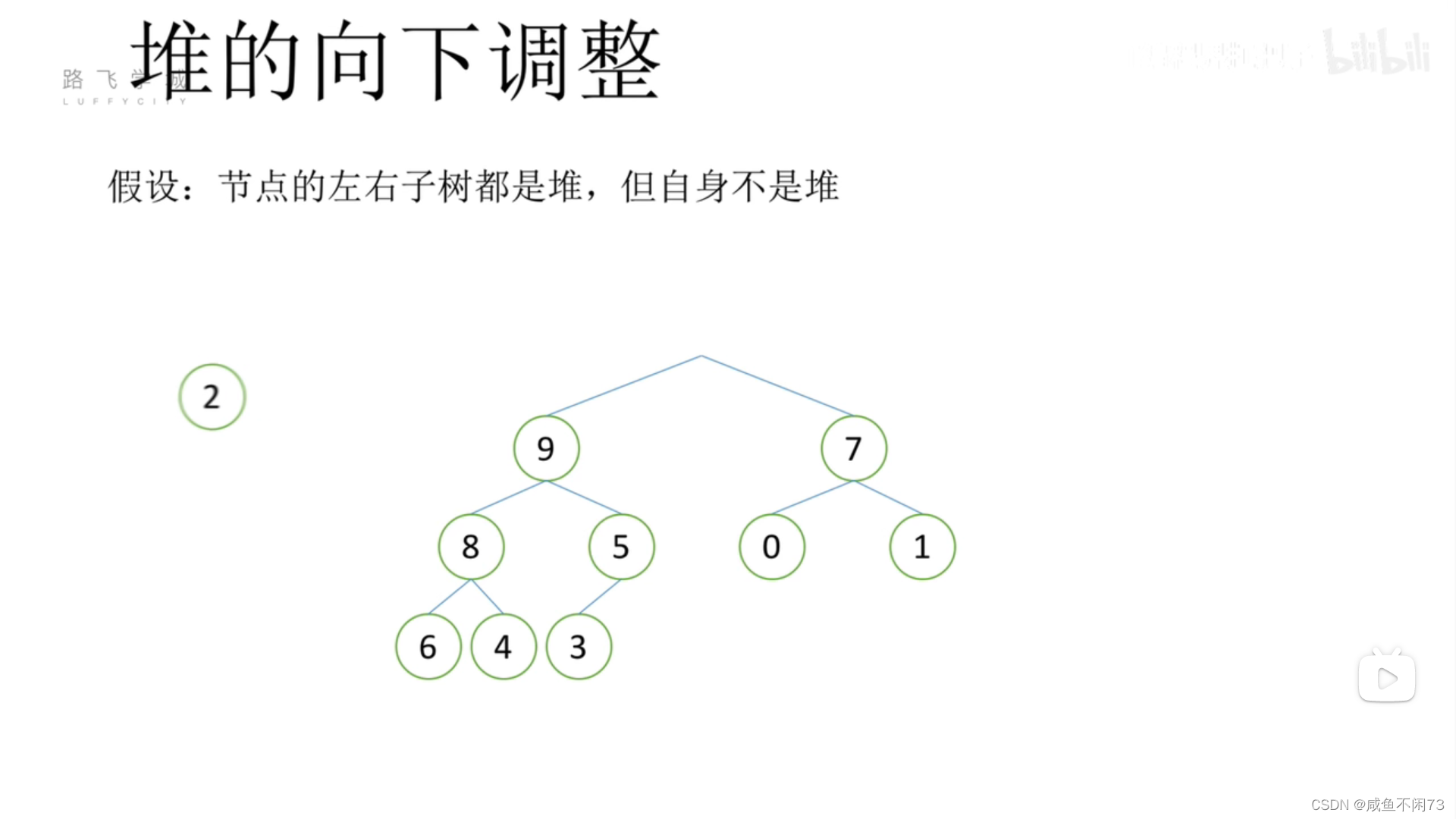
2移走后,那么我们来看看2是否能作为第二级的父节点,显然不可以,但是我们发现,9比2和7都大(所有数里最大),很明显,9可以作为根部的父节点,因此我们现在把9“填补”到上面的空位之中。
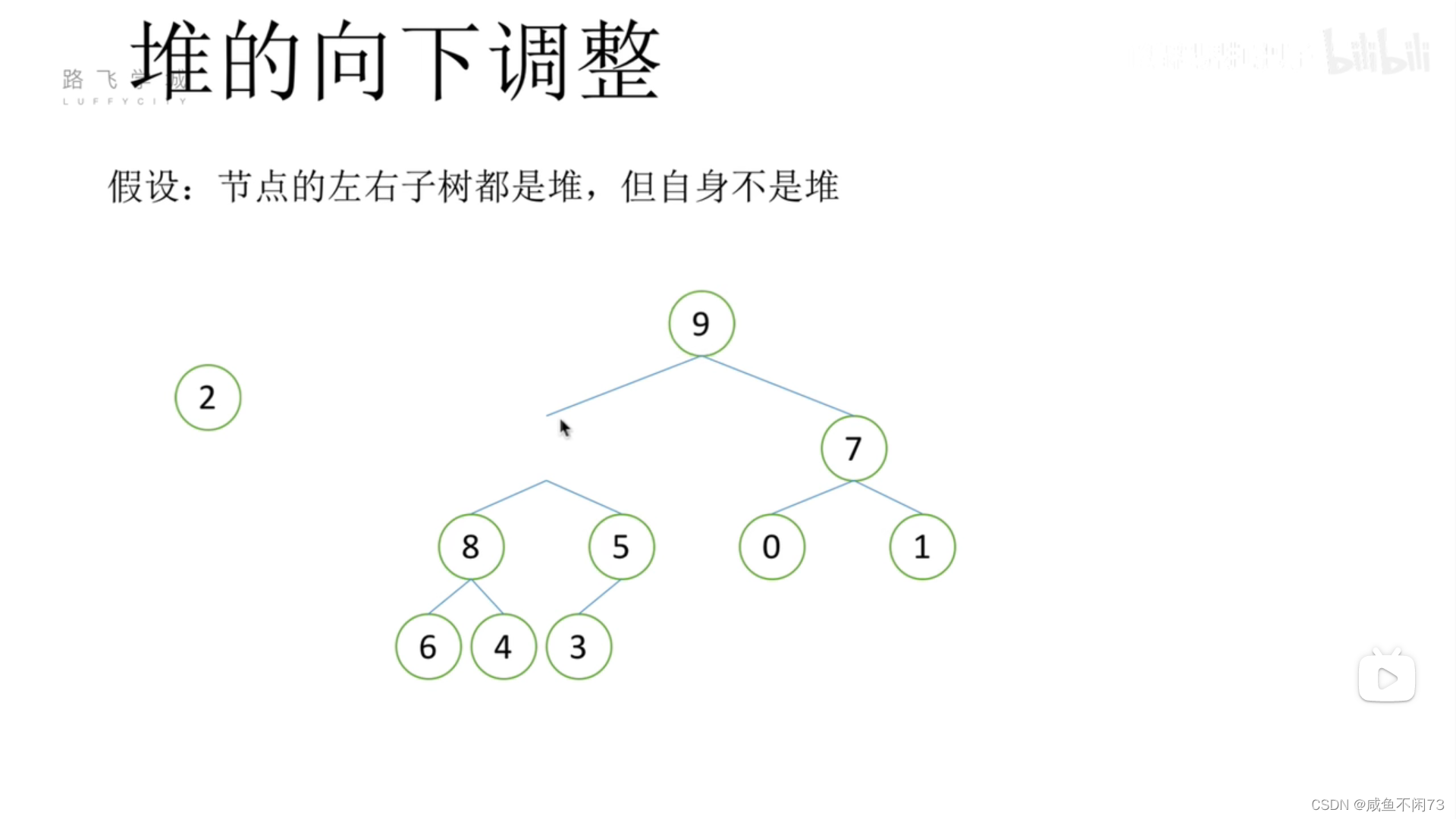
很好,现在我们完成了根部父节点的填充,但是现在第二层又缺少了一个父节点数值,2比8,5小又填补上,所以就让8上位吧(儿子足够强甚至能当爹):
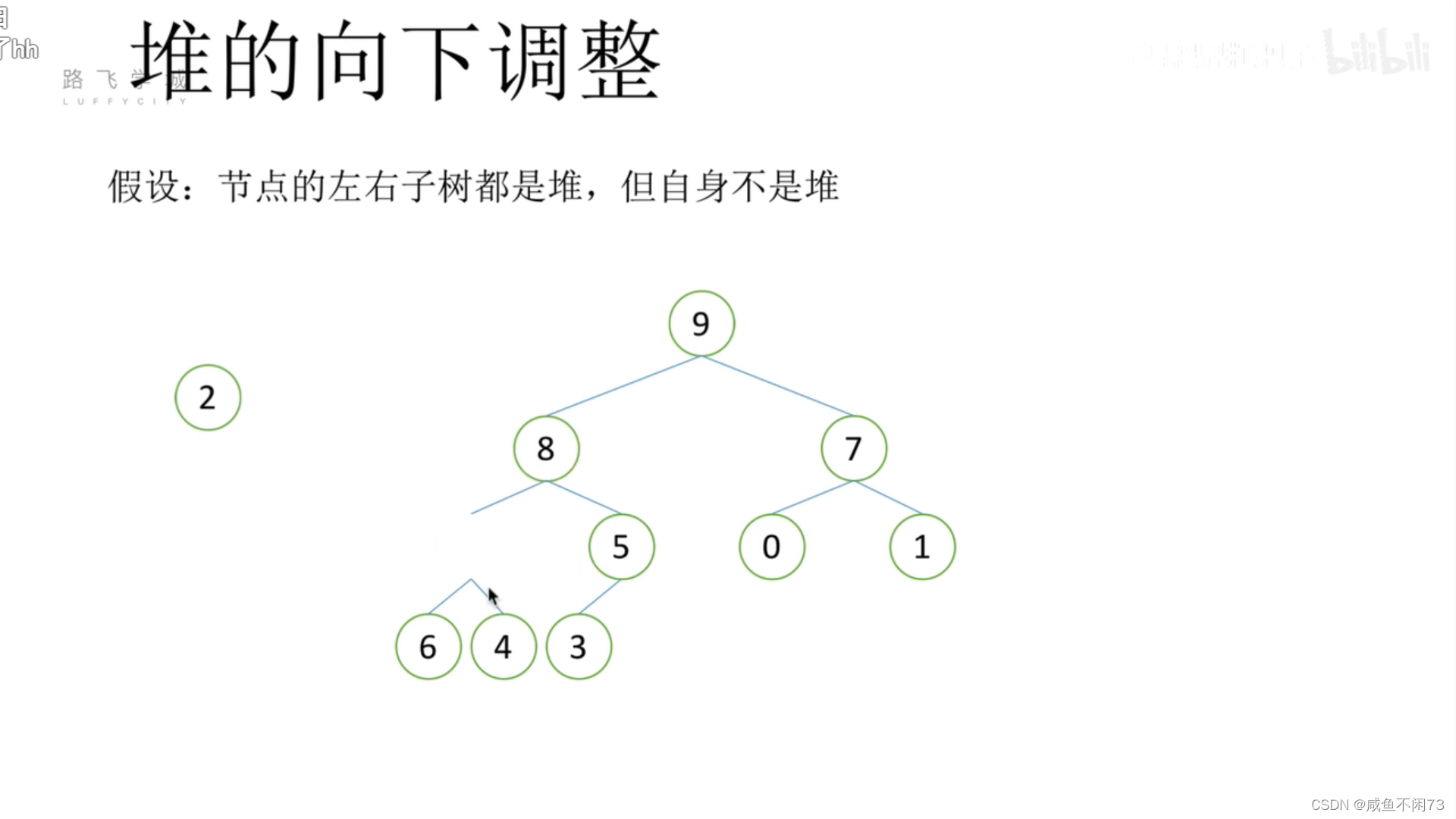
同样的,8原来的位置又缺了,2又比(6,4)小,所以让6填充。
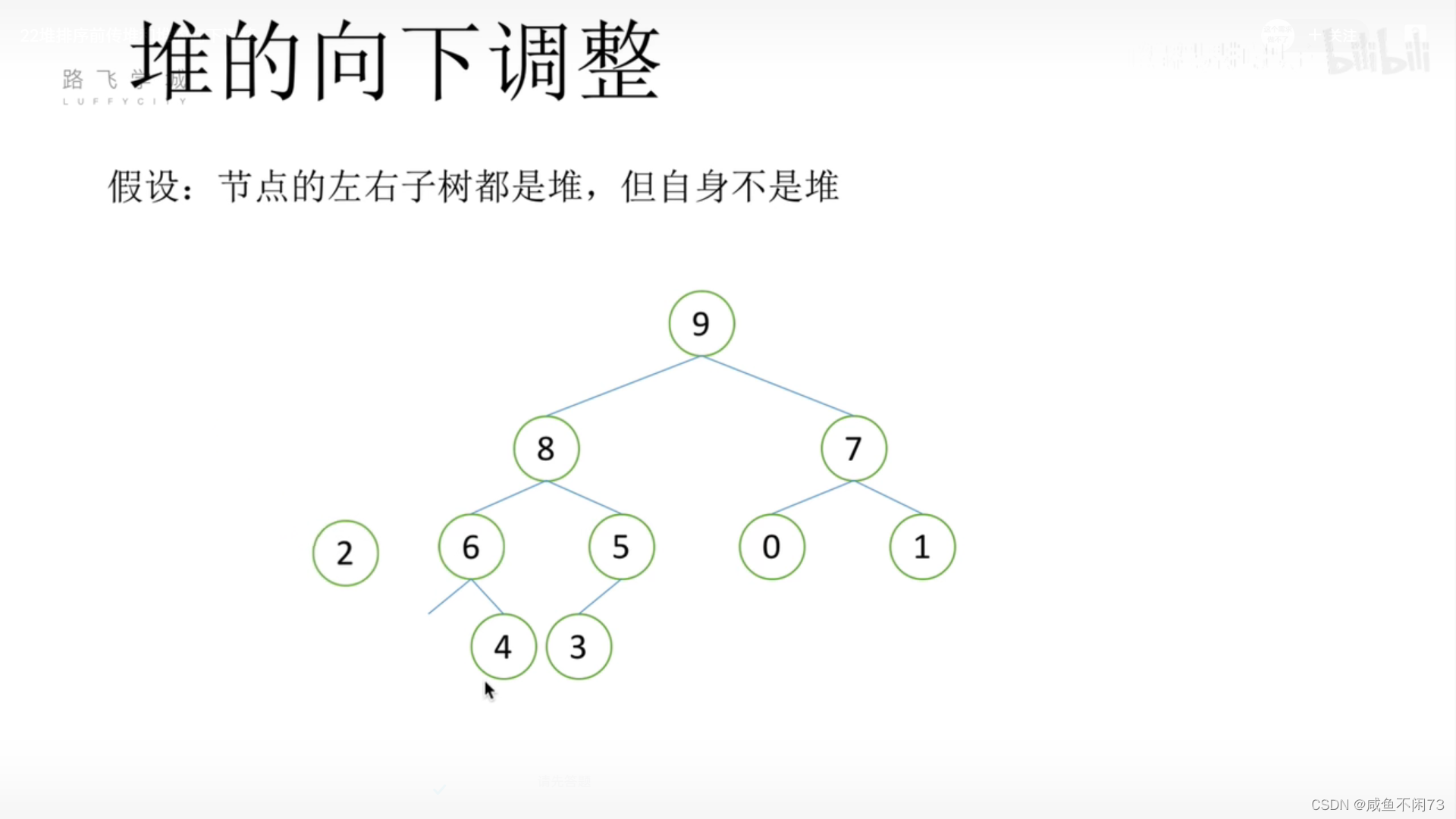
6的位置又缺了,但是6没有儿子欸,2又必须得找一个归宿,那就让2当儿子吧(没实力只能当儿子)。
总结一下,就是这样:
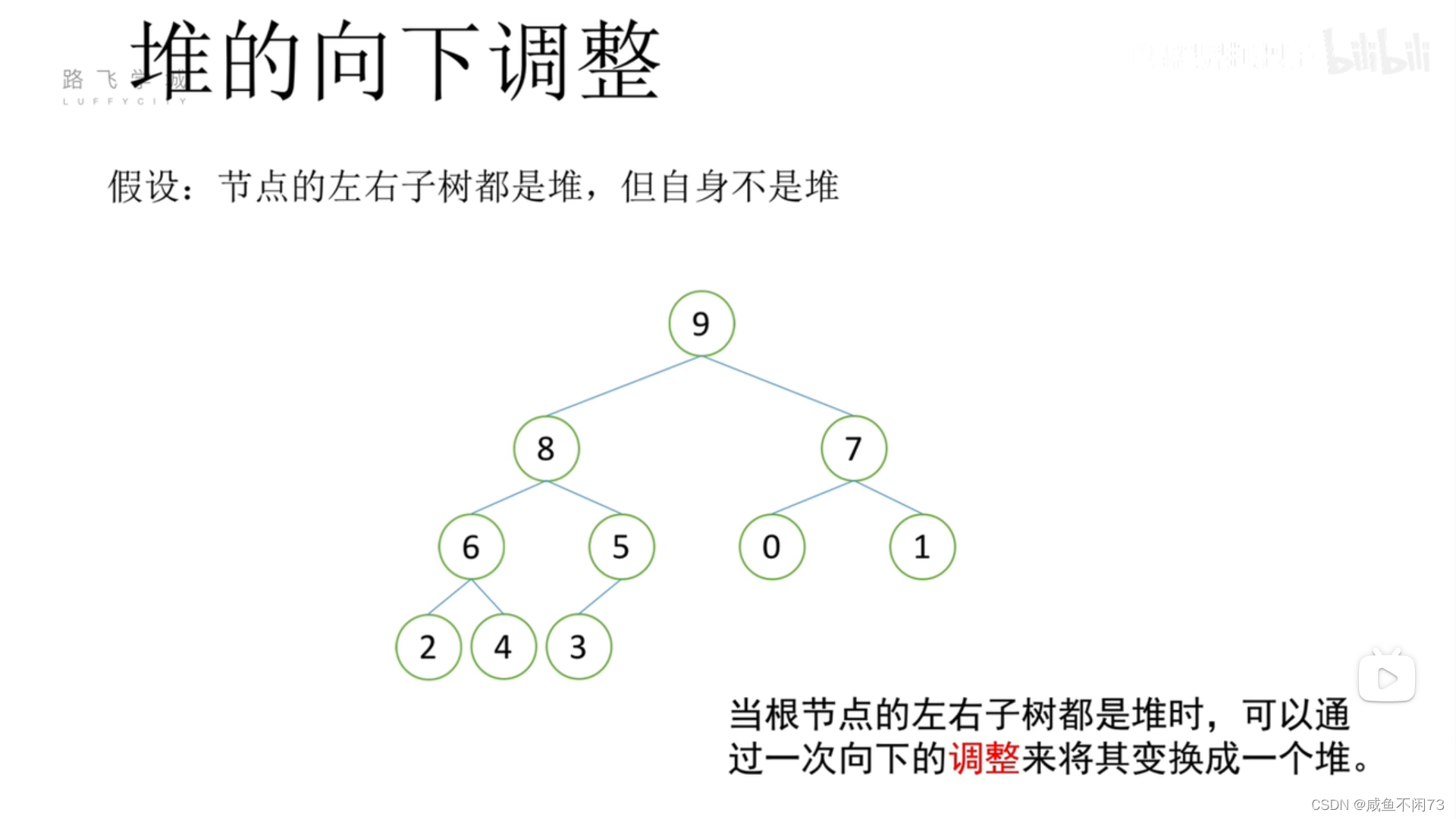
向下调整过程中,任何数值该放在哪里,还是得比较该数值和子节点的大小关系,总之一句话,牛逼儿子能当爹。
堆排序的实现:
1.先建立一个堆,堆顶的元素为最大元素。
2.去掉堆顶的元素(把最大元素提出去)
3.把最后一个元素放到堆顶当中,来一次堆的向下调整,获得堆的第二大元素(此时放在堆顶)。
4.重复操作 2和3,直到把整个堆榨干挖空。
疑惑解答:
为什么这么做?
你们肯定很好奇,为什么要这样子做呢?
其实这样子做,就是在一步步地把堆里面的元素按照从小到大(从大到小)丢出去,不知不觉之中就已经排好序啦,是不是很神奇?
为什么”去掉堆顶元素后,非要把最后一个元素放到堆顶,然后再进行向下调整呢?为什么不直接就向下调整了呢?
好,我们先看看直接向下调整会发生什么事情。
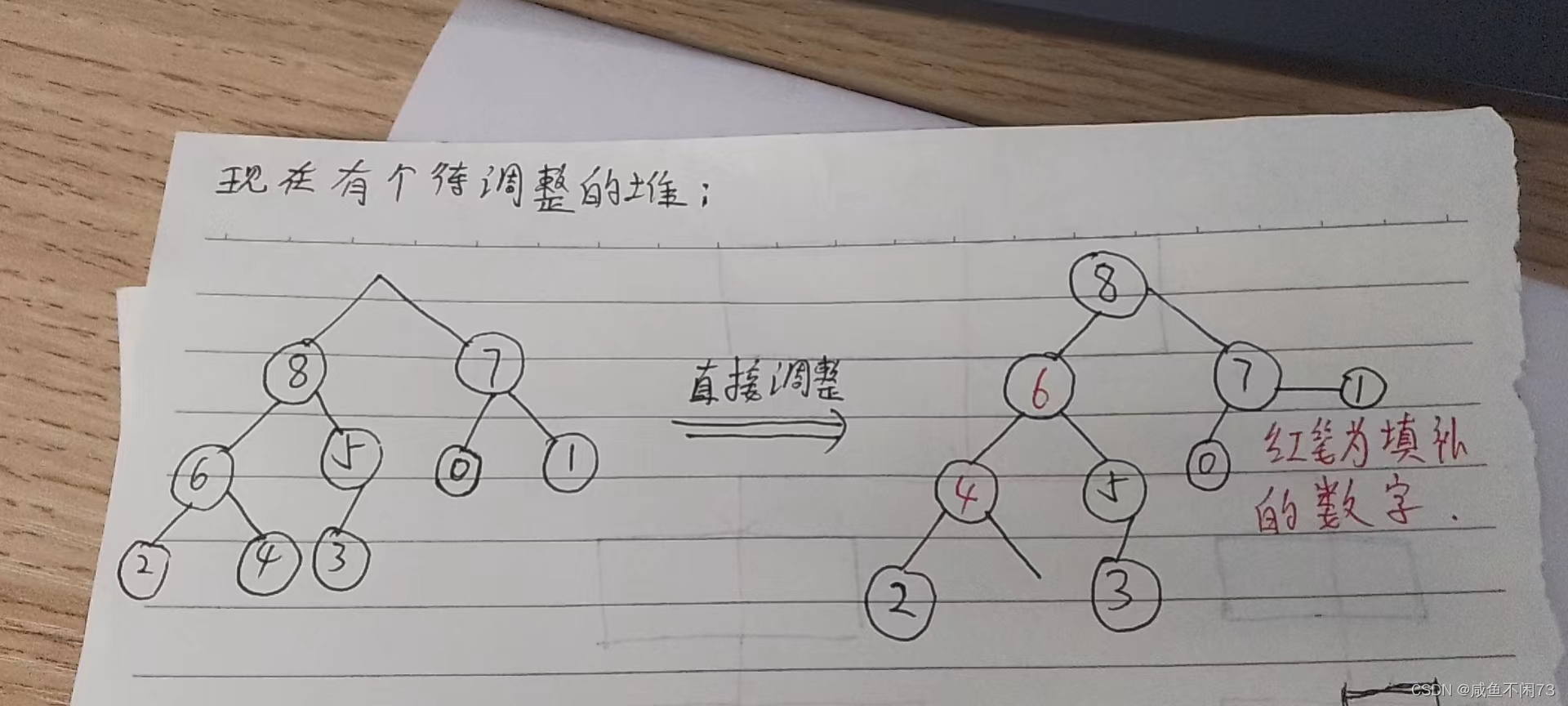
如果直接向下调整,那么就很有可能出现上面的情况,4和5的孩子节点都不完整,已经破坏了堆的结构!
那么我现在再来展示以下“3”的做法:
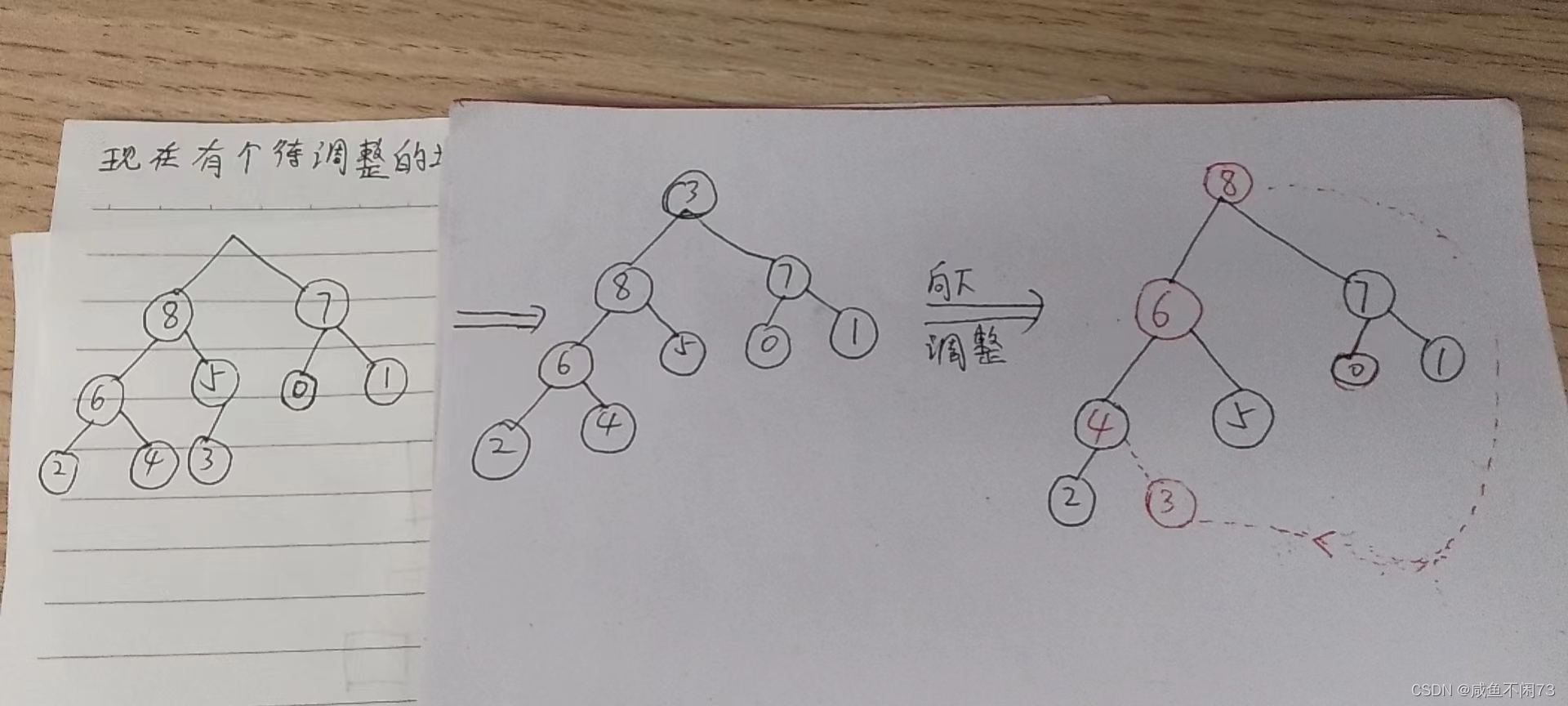
这种做法既能够把最大数提取到堆顶,也能够不破坏堆的原本结构。数字3变成了4的孩子节点。
是不是要开辟一个新的空间去存放丢出来的数据呢?
数据量小的话倒还好,如果数据量一大,那么占用的空间就忒大了,你还不如用快速排序呢,而且堆排序的优势更是体现在大数据的情况下,所有更不能开辟新的空间去储存序列数据了。
不开辟新的空间那么我们该怎么办?
解决办法还是会有的,虽然我们不开辟新的空间去储存,但是我们可以把”丢出来“的数据存到”被放到堆顶的数据“的位置,只要我们下一次堆排序时,忽略该位置就好了,如图所示:
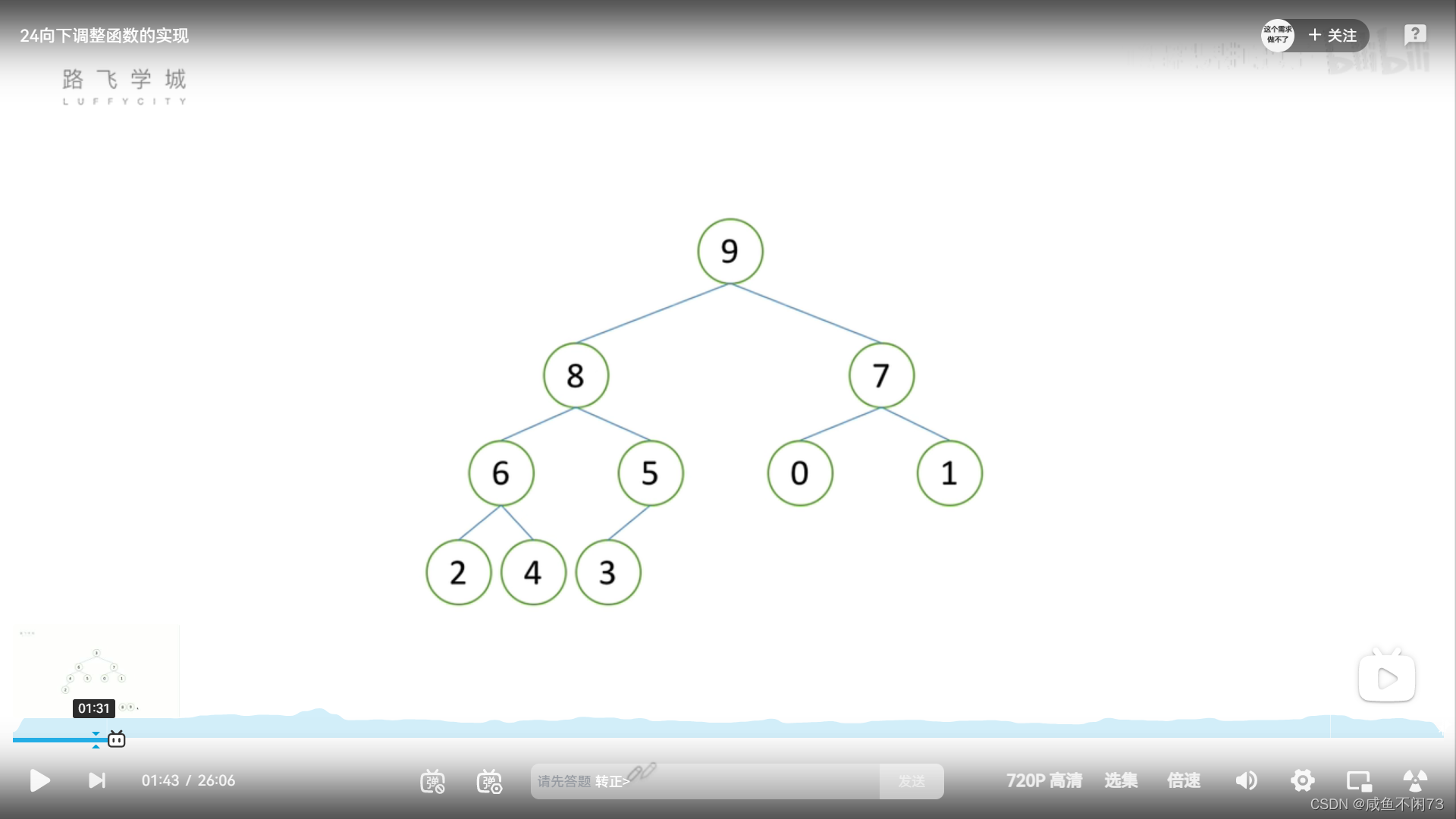
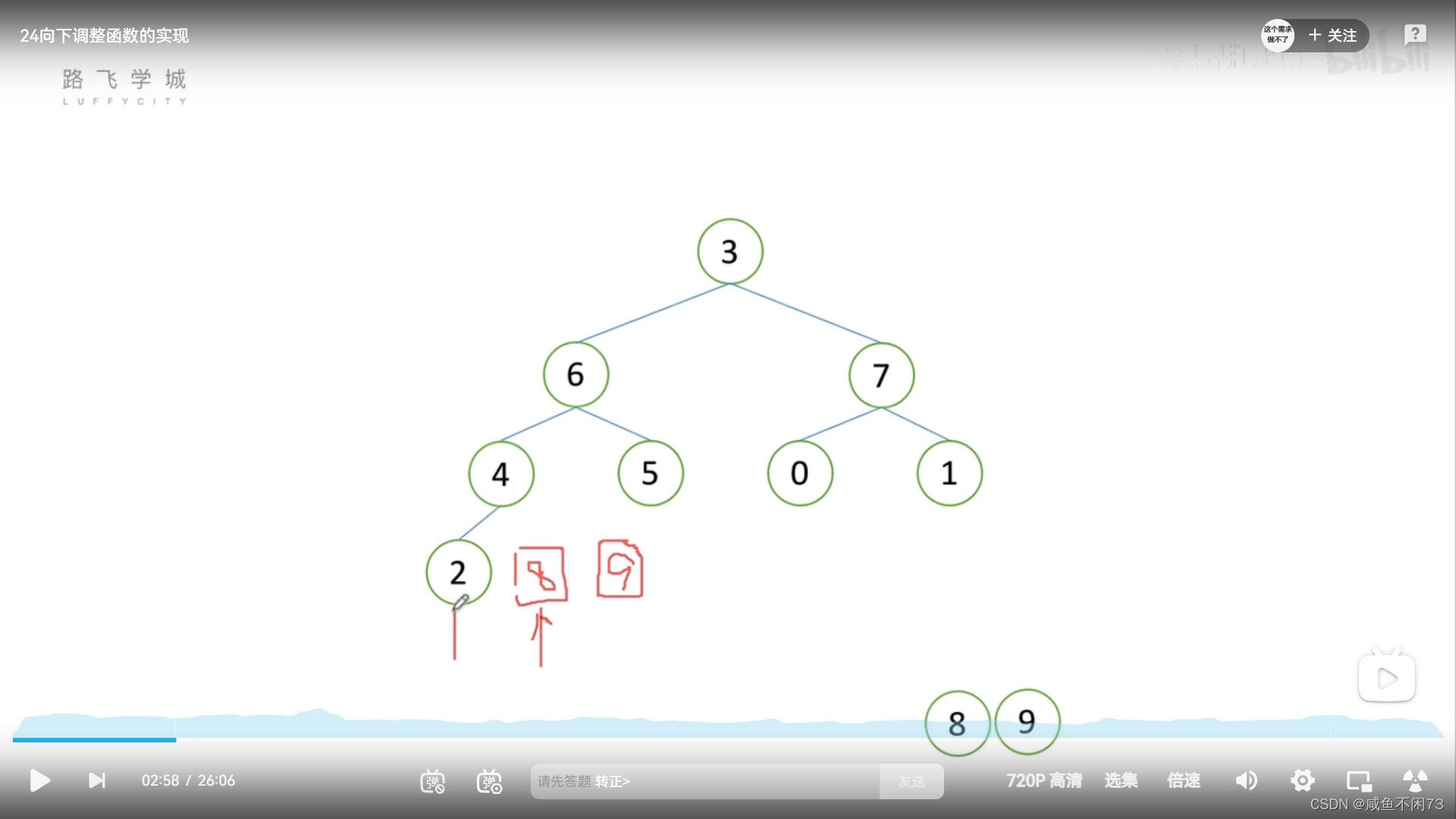
方法就是上面那样,第二张图之后,开始堆排序时,认为2是末尾元素。
我们如何构造一个堆?
我们采用由下到上的方式,逐一构建堆(先建好小堆,然后再建好一个大堆):
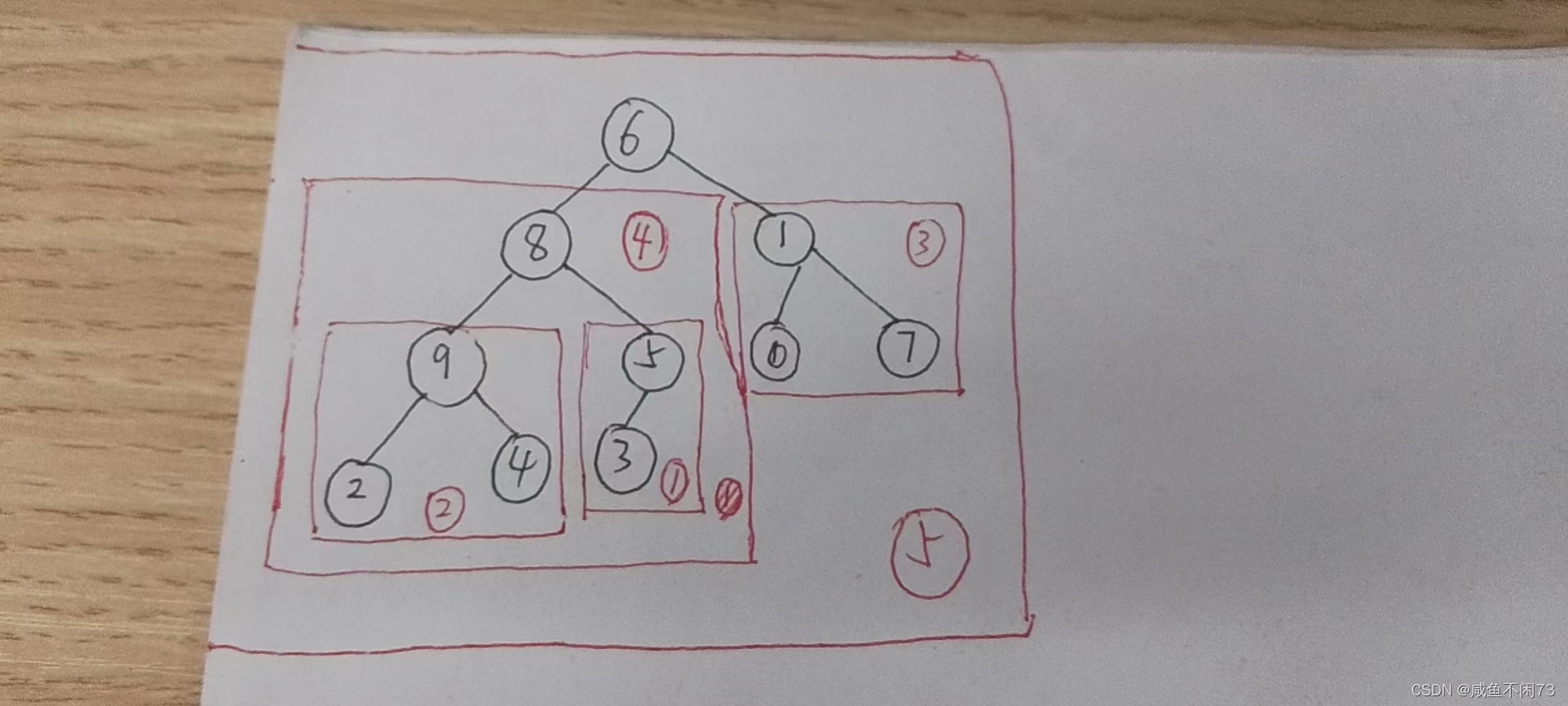
按照顺序去建堆,1–>5, 层层嵌套。
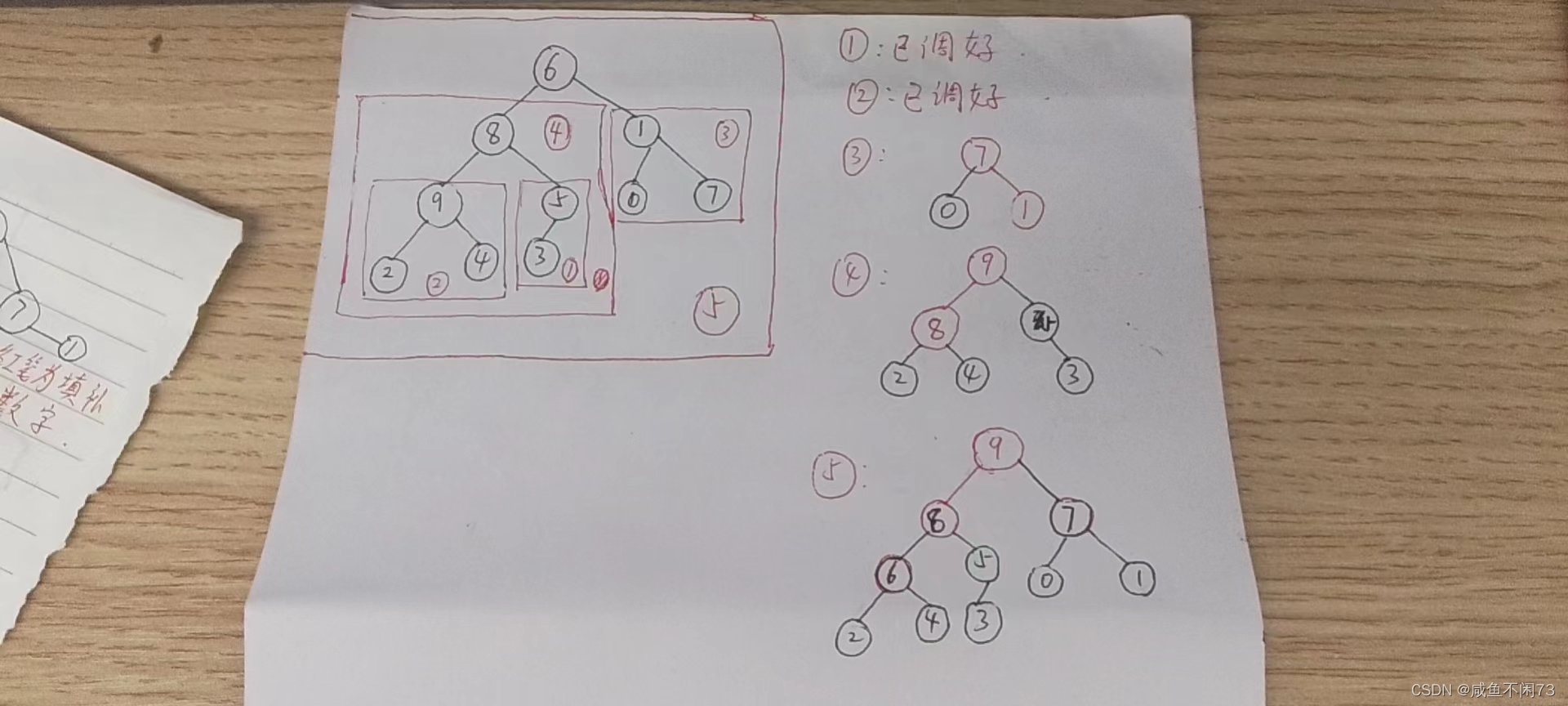
红色表示变化移动的节点,各位需要跟着我的思维手动去画一画动态图,就能把堆建好啦。
代码实现以及讲解:
代码部分使用python实现:
1.堆向下调整结构的实现:
def sift(li,low,high):
#li:列表
#low:根堆
#high:堆最后一个元素
i=low #最开始指向根节点
j=2*i+1 #j表示左孩子的位置
tmp=li[low] #先保留根节点的数值
while j<=high : #保证向下调整的过程中,序号不越界(不超过最后一个元素),这个也是向下调整的大前提
if li[j]<li[j+1] and j+1<=high: #如果右孩子存在,并且数值比左孩纸大,那么我们下一步(必须判断右孩子是否存在,因为右孩子可能没有!!)
j=j+1 #把目标指向右孩子
if li[j]>tmp: #现在开始比较大小,如果孩子节点比父节点大,替换数值
li[i]=li[j]
i=j #现在我们已经解决了父节点了,现在我们开始往下看一层,那么这一层的孩子节点就变成了父节点。
j=2*i+1 #j往下移动。
我们先讲到这里,暂停一会,现在我来展示以下变换过程:
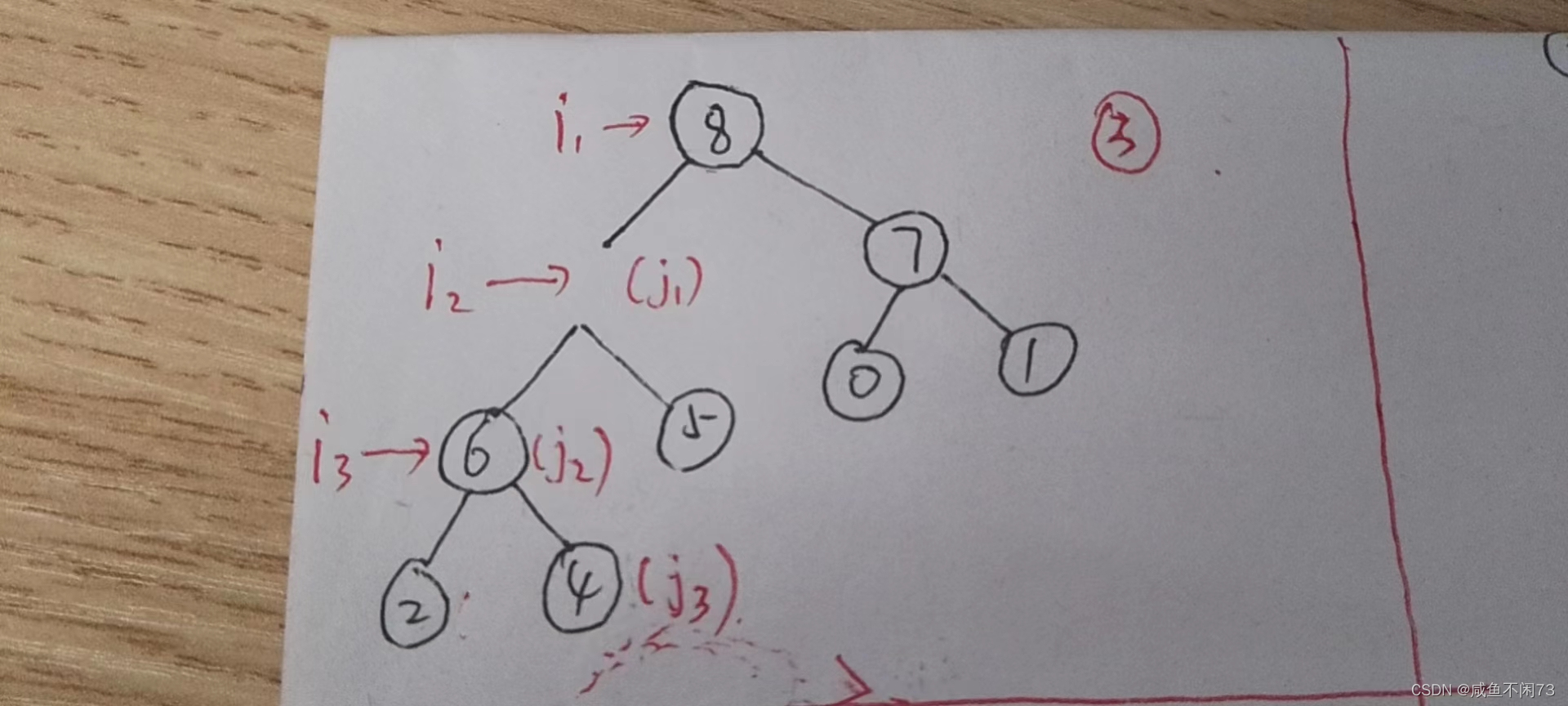
i 和 j不断向下移动,这也就是上面代码最后两行的意思了。
继续讲解:
elif li[j]<tmp:
li[i]=tmp #孩子节点小于根节点的数值,那么直接把根节点的数值放到其父节点的位置上即可

比如这张图片,6与4比较,6更大,所以6放到了空位(父节点)上,那么一次向下调整就已经结束了。
else:
#不满足while条件,此时孩子节点已经越界了(不存在),空位已经移到了最底部。那么直接将根节点元素放到该位置即可!
li[i]=tmp
图片解释如下:
那么,我们向下调整的函数接讨论完了!
构造堆的实现:
假设现在咱们有一个乱序的数组(完全二叉树),那我们开始建堆:
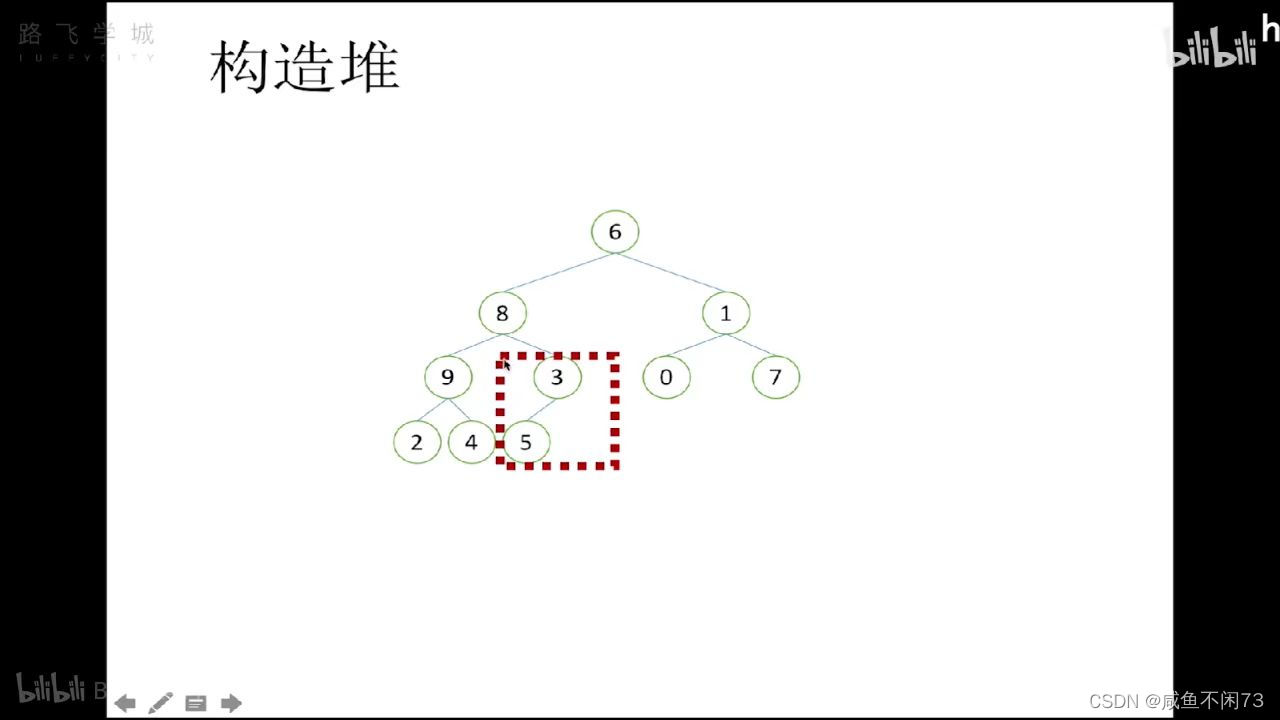
这个小堆“(3,5)”的代码如下:
假设左孩子节点是 j ,父节点是 i
那么 j=2*i+1 同样,i=(j-1)//2
理论上假设右孩子节点是K,那么 i=(k-2)//2,但是计算i =(k-1)//2 同样也能找到父节点,所以我们统一认为,通过孩子节点找到其父结点的关系式是:
i=(j-1)//2
tmp = li[(high-1)//2] #保留父节点3
li[(high-1)//2]=li[high]
li[high]=tmp
上述代码实现了3和5的互换(小堆建成)
现在·我们开始建这个堆:
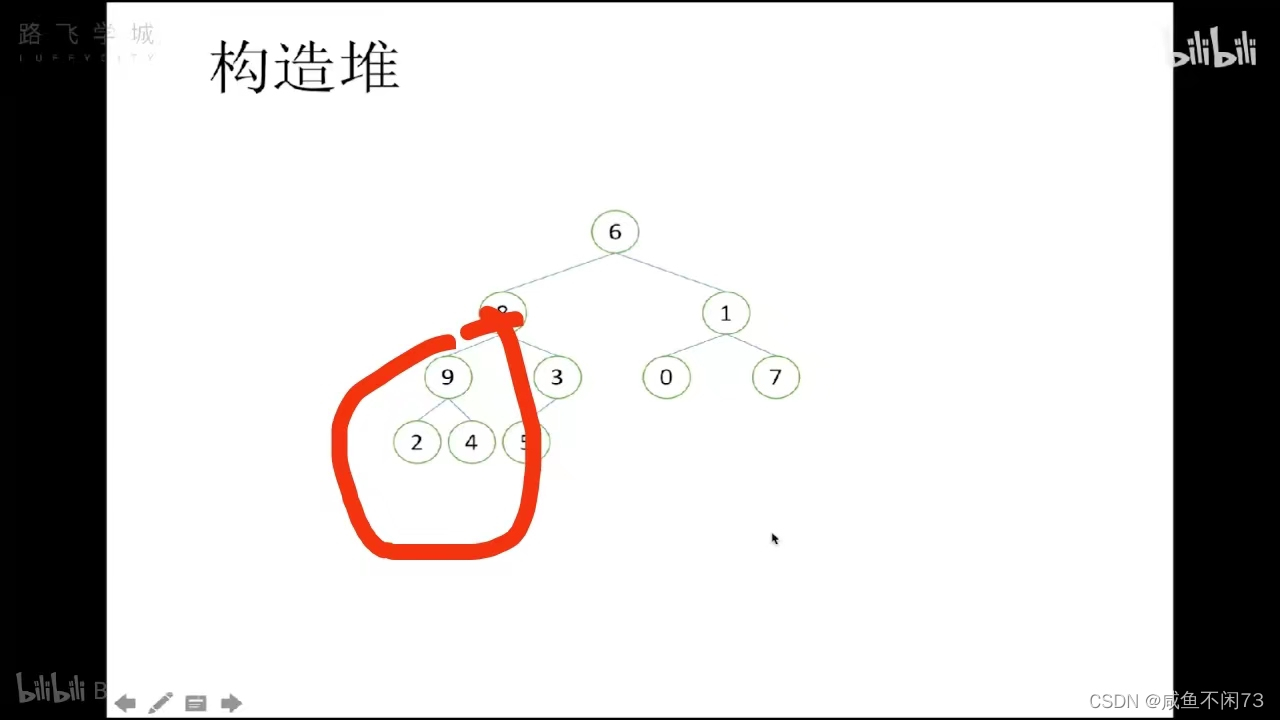 (9,2,4)
(9,2,4)
上面我们已经找到了父节点3的位置:(high-1)//2,那么父节点的位置就是
(high-1)//2 -1 ,这里记为 位置K,同样的方法,先把目标指向4(找出最大的孩子),然后4和9比较,很明显,这个堆本来就已经建好了,所以不需要调整。同样的道理,我们继续去建下一个堆(1,0,7)等。
有没有发现,在我们建堆的过程中,其实二叉树的都可以以最后一个叶节点作为边界(以5的原始位置作为边界),这个在(9,2,4)(8,9,3,2,4,5)以及最大堆中都容易理解,可能在(1,0,7)这个堆里面不好理解。你肯定会问,为什么(1,0,7)这个堆不以7的位置作为边界呢?其实也可以,但是逻辑上就更难了。不着急,我现在和你讲讲(1,0,7)为什么同样也可以以“5”作为边界。图片如下:
假设0和7下面也有孩子节点:
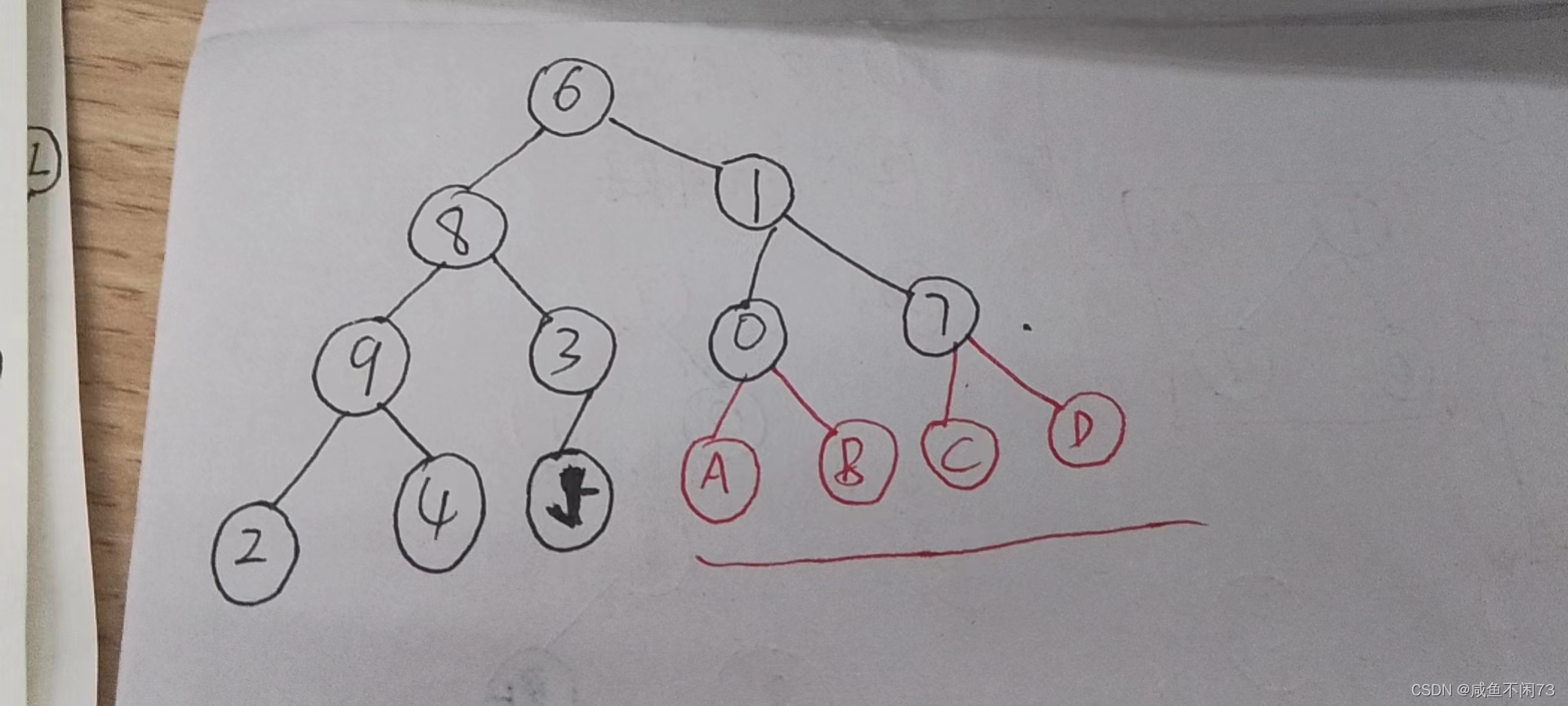
A,B,C,D的位置显然已经超越了“5”的边界,所以这就是为什么我们可以以“5”作为边界的原因!
明白了这一些,现在开始代码展示:
def sift(li,low,high):
#li:列表
#low:根堆
#high:堆最后一个元素
i=low #最开始指向根节点
j=2*i+1 #j表示左孩子的位置
tmp=li[low] #先保留根节点的数值
while j<=high : #保证向下调整的过程中,序号不越界(不超过最后一个元素),这个也是向下调整的大前提
if li[j]<li[j+1] and j+1<high: #如果右孩子存在,并且数值比左孩纸大,那么我们下一步(必须判断右孩子是否存在,因为右孩子可能没有!!)
j=j+1 #把目标指向右孩子
if li[j]>tmp: #现在开始比较大小,如果孩子节点比父节点大,替换数值
li[i]=li[j]
i=j #现在我们已经解决了父节点了,现在我们开始往下看一层,那么这一层的孩子节点就变成了父节点。
j=2*i+1 #j往下移动。
elif li[j]<tmp:
li[i]=tmp #孩子节点小于根节点的数值,那么直接把根节点的数值放到其父节点的位置上即可
break
else:
#不满足while条件,此时孩子节点已经越界了(不存在),空位已经移到了最底部。那么直接将根节点元素放到该位置即可!
li[i]=tmp
def heap_sort(li):
n=len(li) #获取列表长度,便于找到父节点的位置
for i in range((n-1-1)//2,-1,-1): #开启循环建堆,遍历每一个父节点
# i 代表的是父节点, n-1 是指最后一个元素,所以最后一个元素的父节点是:(n-1-1)//2,这里不管最后一个元素是左节点还是右节点,公式都成立,上面内容有解释
sift(li,i,n-1) #从父节点开始向下调整结构,我们始终可以认为“n-1”作为边界。
#每一次都向下调整,循环结束后,堆全部建立完成
筛选最大值的实现:
for i in range(n-1,-1,-1): #循环遍历,从末尾开始
tmp = li[0] #保存堆顶的元素
li[0]=li[i] #最末尾的元素与堆顶元素做交换,实际是把末尾的元素放到堆顶
li[i]=tmp #把原来堆顶的元素放到堆的末尾
sift(li,0,i-1) #i表示堆的最后一个元素,但是此时最后一个元素的位置已经用于存放原来的堆顶元素了(文章上面的内容有提到忽略最后一个元素),所以传入sift函数的末尾序列应该是i-1.
结束
那么到现在,堆排序的各个部分都已经讲完了,全部代码如下:
#空位表示父节点
def sift(li,low,high):
#li:列表
#low:根堆
#high:堆最后一个元素
i=low #最开始指向根节点
j=2*i+1 #j表示左孩子的位置
tmp=li[low] #先保留根节点的数值
while j<=high : #保证向下调整的过程中,序号不越界(不超过最后一个元素),这个也是向下调整的大前提
if li[j]<li[j+1] and j+1<=high: #如果右孩子存在,并且数值比左孩纸大,那么我们下一步(必须判断右孩子是否存在,因为右孩子可能没有!!)
j=j+1 #把目标指向右孩子
if li[j]>tmp: #现在开始比较大小,如果孩子节点比父节点大,替换数值
li[i]=li[j]
i=j #现在我们已经解决了父节点了,现在我们开始往下看一层,那么这一层的孩子节点就变成了父节点。
j=2*i+1 #j往下移动。
else:
li[i]=tmp #孩子节点小于根节点的数值,那么直接把根节点的数值放到其父节点的位置上即可
break
else:
#不满足while条件,此时孩子节点已经越界了(不存在),空位已经移到了最底部。那么直接将根节点元素放到该位置即可!
li[i]=tmp
def heap_sort(li):
n=len(li) #获取列表长度,便于找到父节点的位置
for i in range((n-1-1)//2,-1,-1): #开启循环建堆,遍历每一个父节点
# i 代表的是父节点, n-1 是指最后一个元素,所以最后一个元素的父节点是:(n-1-1)//2,这里不管最后一个元素是左节点还是右节点,公式都成立,上面内容有解释
sift(li,i,n-1) #从父节点开始向下调整结构,我们始终可以认为“n-1”作为边界。
#每一次都向下调整,循环结束后,堆建立完成
for i in range(n-1,-1,-1): #循环遍历,从末尾开始
tmp = li[0] #保存堆顶的元素
li[0]=li[i] #最末尾的元素与堆顶元素做交换,实际是把末尾的元素放到堆顶
li[i]=tmp #把原来堆顶的元素放到堆的末尾
sift(li,0,i-1) #i表示堆的最后一个元素,但是此时最后一个元素的位置已经用于存放原来的堆顶元素了(文章上面的内容有提到忽略最后一个元素),所以传入sift函数的末尾序列应该是i-1.
#测试部分:
li=[20,13,41,2,5,98,11,42,57]
print(li)
heap_sort(li)
print(li)
结果展示如下:
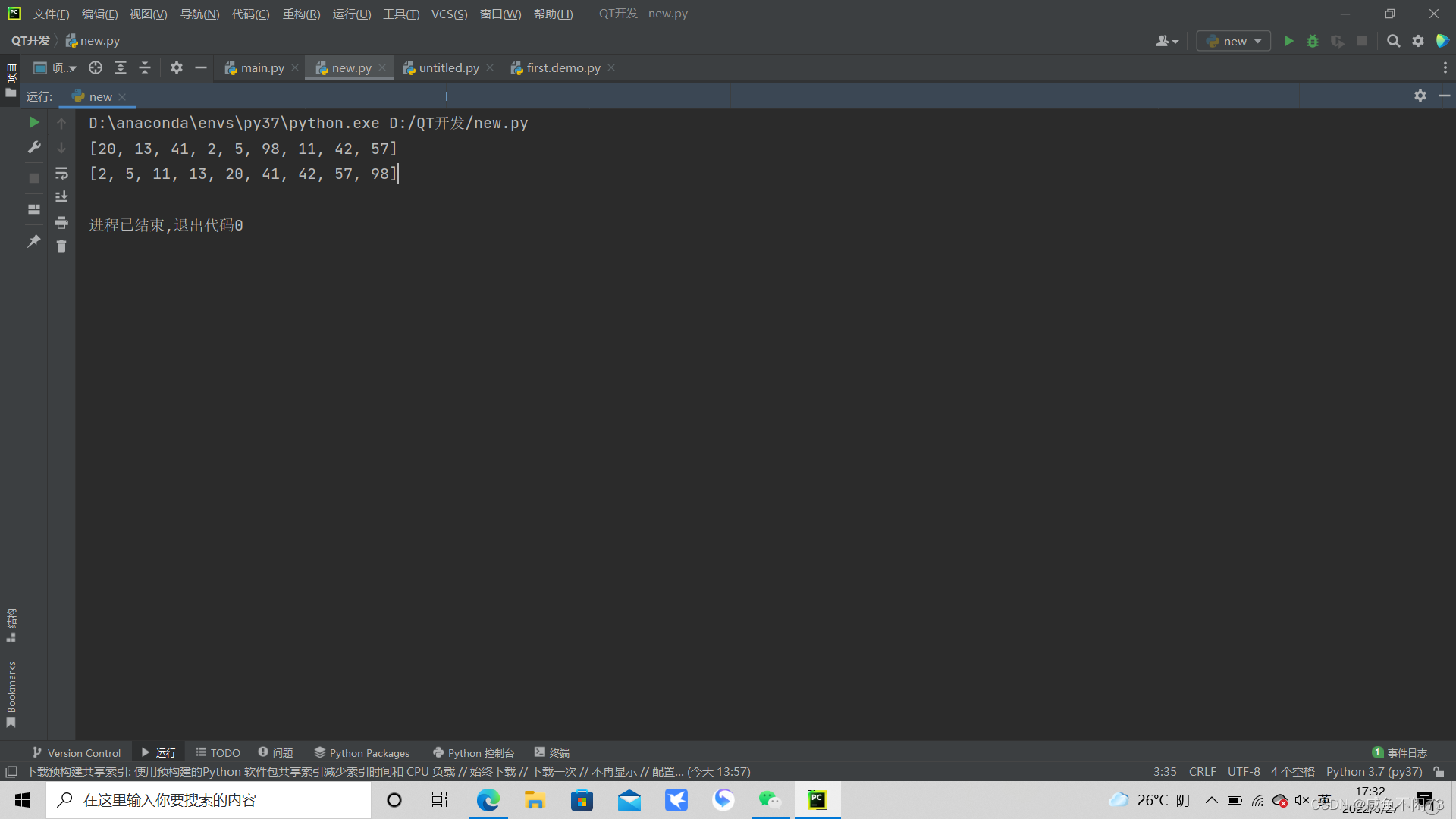
堆排序是最复杂的排序算法了,但是逻辑非常地清晰严谨,仔细研究非常有意思,希望大家在看完本教程后,也要自己能够复现出逻辑代码,多回顾,多敲,才能真真正正地记住!














 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









