






1、实现多线程有哪几种方式,如何返回结果?
三种方式,
1、继承Thread类
看jdk源码可以发现,Thread类其实是实现了Runnable接口的一个实例,继承Thread类后需要重写run方法并通过start方法启动线程。
继承Thread类耦合性太强了,因为java只能单继承,所以不利于扩展。
2、实现Runnable接口
通过实现Runnable接口并重写run方法,并把Runnable实例传给Thread对象,Thread的start方法调用run方法再通过调用Runnable实例的run方法启动线程。
所以如果一个类继承了另外一个父类,此时要实现多线程就不能通过继承Thread的类实现。
3、实现Callable接口
通过实现Callable接口并重写call方法,并把Callable实例传给FutureTask对象,再把FutureTask对象传给Thread对象。它与Thread、Runnable最大的不同是Callable能返回一个异步处理的结果Future对象并能抛出异常,而其他两种不能。
案例:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Demo7 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread t1=new Thread1();
Thread t2=new Thread(new Thread2());
FutureTask<User> ft=new FutureTask<>(new Thread3<>());
Thread t3=new Thread(ft);
t1.start();
t2.start();
t3.start();
System.out.println(ft.get());
}
//继承Thread类
static class Thread1 extends Thread{
@Override
public void run() {
System.out.println("第一种方法运行了");
}
}
//实现Runnable
static class Thread2 implements Runnable{
@Override
public void run() {
System.out.println("第二种方法运行了");
}
}
//实现Callable
static class Thread3<T> implements Callable<T>{
@SuppressWarnings("unchecked")
@Override
public T call() throws Exception {
System.out.println("第三种方法运行了");
return (T) new User();
}
}
public static class User{
Integer age;
@Override
public String toString() {
return "User{" +
"age=" + age +
'}';
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
}
2、多个线程如何实现顺序访问?
join()
join()是线程类 Thread的方法,官方的说明是:
Waits for this thread to die.
等待这个线程结束,也就是说当前线程等待这个线程结束后再继续执行,下面来看这个示例就明白了。
示例
public static void main(String[] args) throwsException{
System.out.println("start");
Thread t = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println(i);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
t.join();
System.out.println("end");}
结果输出:
start
0
1
2
3
4
end
线程t开始后,接着加入t.join()方法,t线程里面程序在主线程end输出之前全部执行完了,说明t.join()阻塞了主线程直到t线程执行完毕。
如果没有t.join(),end可能会在0~5之间输出。
join()原理
下面是join()的源码:
public final synchronized void join(long millis)throwsInterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}}
可以看出它是利用wait方法来实现的,上面的例子当main方法主线程调用线程t的时候,main方法获取到了t的对象锁,而t调用自身wait方法进行阻塞,只要当t结束或者到时间后才会退出,接着唤醒主线程继续执行。millis为主线程等待t线程最长执行多久,0为永久直到t线程执行结束。
3、两个线程如何进行数据交换?
第 3 题也是通过 JDK 中的 java.util.concurrent.Exchanger 类来实现的,并不需要我们重复造轮子,这个工具类在 JDK 1.5 中就已经引入了,并不是什么 “新特性”。
Exchanger 简介
Exchanger 就是线程之间的数据交换器,只能用于两个线程之间的数据交换。
Exchanger 提供了两个公开方法:
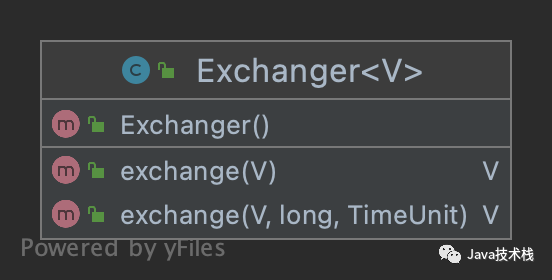
1、只带泛型 V(交换的数据对象)的方法,线程一直阻塞,直到其他任意线程和它交换数据,或者被线程中断;线程中断也是一门学问,栈长在公众号Java技术栈已经分享过,可在公众号搜索阅读;
2、另外一个带时间的方法,如果超过设置时间还没有线程和它交换数据,就会抛出 TimeoutException 异常;
Exchanger 实战
以下代码包括四个案例:
1.两个线程交换数据案例
2.线程超时数据交换案例
3.线程中断数据交换
4.两两交换线程数据
import java.util.concurrent.Exchanger;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
public class Demo6 {
public static void main(String[] args) {
//text1();
//text2();
/*try {
text3();
} catch (InterruptedException e) {
e.printStackTrace();
}*/
text4();
}
//两个线程交换数据案例
public static void text1() {
Exchanger exchanger = new Exchanger();
//创建线程1
new Thread(() -> {
try {
Object data = "我是第一个线程";
System.out.println(Thread.currentThread().getName() + data);
//开始交换数据
data = exchanger.exchange(data);
System.out.println(Thread.currentThread().getName() + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
//创建线程2
new Thread(() -> {
try {
Object data = "我是第二个线程";
System.out.println(Thread.currentThread().getName() + data);
data = exchanger.exchange(data);
System.out.println(Thread.currentThread().getName() + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
//线程超时数据交换案例
private static void text2() {
Exchanger exchanger = new Exchanger();
new Thread(() -> {
try {
Object data = "超时了吗";
System.out.println(Thread.currentThread().getName() + data);
data = exchanger.exchange(data, 3000L, TimeUnit.MILLISECONDS);
System.out.println(Thread.currentThread().getName() + data);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}).start();
}
//线程中断数据交换
private static void text3() throws InterruptedException {
Exchanger exchanger = new Exchanger();
Thread thread = new Thread(() -> {
try {
Object data = "中断了吗";
System.out.println(Thread.currentThread().getName() + data);
data = exchanger.exchange(data);
System.out.println(Thread.currentThread().getName() + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread.start();
//线程中断
Thread.sleep(3000L);
thread.interrupt();
}
//两两交换线程数据
private static void text4() {
Exchanger exchanger = new Exchanger();
for (int i = 0; i < 10; i++) {
Integer data = i;
new Thread(()->{
try {
Object e=exchanger.exchange(data);
System.out.println(Thread.currentThread().getName()+"--"+e);
} catch (InterruptedException interruptedException) {
interruptedException.printStackTrace();
}
},"java技术栈"+i).start();
}
}
}
4、如何统计 5 个线程的运行总耗时?
CountDownLatch见名思义,即倒计时器,是多线程并发控制中非常有用的工具类,它可以控制线程等待,直到倒计时器归0再继续执行。
给你出个题,控制5个线程执行完后主线徎再往下执行,并统计5个线程的所耗时间。当然我们可以通过join的形式完成这道题,但如果我说统计100个1000个线程呢?难道要写1000个join等待吗?这显然是不现实的。
废话少说,我们来做一个例子看看上面的题怎么实现,并理解倒计时器。
import java.util.concurrent.CountDownLatch;
public class emo8 {
public static void main(String[] args) throws InterruptedException {
//倒计时器,数字为线程数
CountDownLatch cl=new CountDownLatch(5);
//当前的时间ms
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
new Thread() {
public void run(){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//倒计时器减一
cl.countDown();
}
};
}.start();
}
cl.await();
System.out.println(cl.getCount());
System.out.println(String.format("耗时:%sms",System.currentTimeMillis()-start));
}
}
//运行结果
0
耗时:515ms
首先通过new CountDownLatch(5)约定了倒计时器的数量,在这里也是线程的数量,每个线程执行完后再对倒计时器-1。countDown()方法即是对倒计时器-1,这个方法需要放在finally中,一定要保证在每个线程中得到释放,不然子线程如果因为某种原因报错倒计时器永远不会清0,则会导报主线程会一直等待。
await()方法即是主线程阻塞等待倒计器归0后再继续往下执行,当然await可以带时间进去,等待多久时间后不管倒计时器有没有归0主线程继续往下执行。
如上面的例子所示,我们输出了倒计时器最后的数字0,表示倒计时器归0了,也输出了从开始到结束所花费的时间。从这个例子可以完全理解倒计时器的含义,这个工具类在实际开发经常有用到,也很好用。
5、如何将一个任务拆分成多个子任务执行,最后合并结果?
Fork/Join是什么?
Fork/Join框架是Java7提供的并行执行任务框架,思想是将大任务分解成小任务,然后小任务又可以继续分解,然后每个小任务分别计算出结果再合并起来,最后将汇总的结果作为大任务结果。其思想和MapReduce的思想非常类似。对于任务的分割,要求各个子任务之间相互独立,能够并行独立地执行任务,互相之间不影响。
Fork/Join的运行流程图如下:
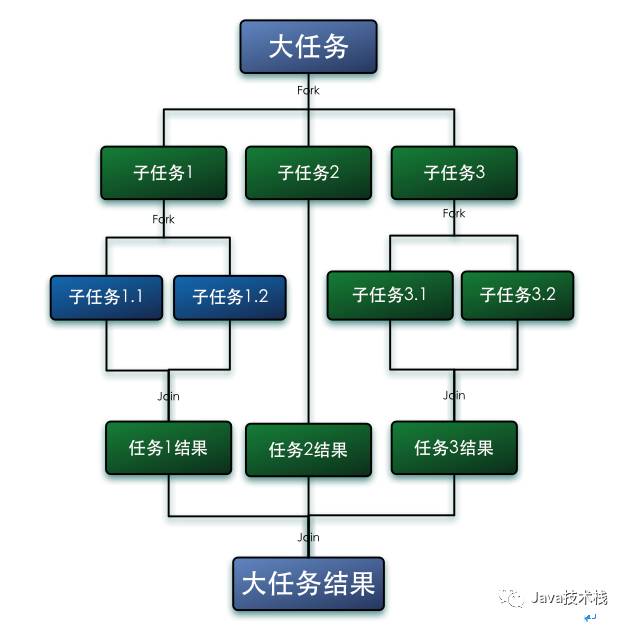
我们可以通过Fork/Join单词字面上的意思去理解这个框架。Fork是叉子分叉的意思,即将大任务分解成并行的小任务,Join是连接结合的意思,即将所有并行的小任务的执行结果汇总起来。 
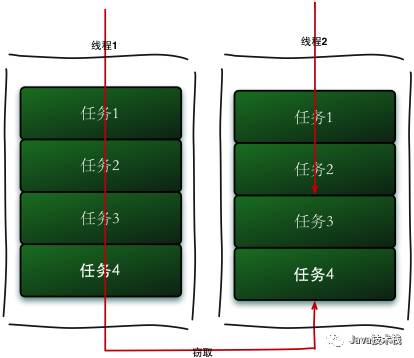
工作窃取算法
ForkJoin采用了工作窃取(work-stealing)算法,若一个工作线程的任务队列为空没有任务执行时,便从其他工作线程中获取任务主动执行。为了实现工作窃取,在工作线程中维护了双端队列,窃取任务线程从队尾获取任务,被窃取任务线程从队头获取任务。这种机制充分利用线程进行并行计算,减少了线程竞争。但是当队列中只存在一个任务了时,两个线程去取反而会造成资源浪费。
工作窃取的运行流程图如下:
Fork/Join核心类
Fork/Join框架主要由子任务、任务调度两部分组成,类层次图如下。
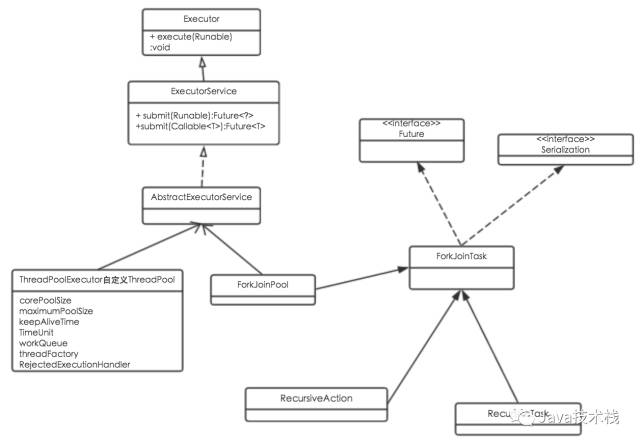
- ForkJoinPool
ForkJoinPool是ForkJoin框架中的任务调度器,和ThreadPoolExecutor一样实现了自己的线程池,提供了三种调度子任务的方法:
- execute:异步执行指定任务,无返回结果;
- invoke、invokeAll:异步执行指定任务,等待完成才返回结果;
- submit:异步执行指定任务,并立即返回一个Future对象;
- ForkJoinTask
Fork/Join框架中的实际的执行任务类,有以下两种实现,一般继承这两种实现类即可。
- RecursiveAction:用于无结果返回的子任务;
- RecursiveTask:用于有结果返回的子任务;
Fork/Join框架实战
下面实现一个Fork/Join小例子,从1+2+…10亿,每个任务只能处理1000个数相加,超过1000个的自动分解成小任务并行处理;并展示了通过不使用Fork/Join和使用时的时间损耗对比。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class Demo9 extends RecursiveTask<Long> {
private static final long MAX = 1000000000L;
private static final long THRESHOLD = 1000L;
private long start;
private long end;
public Demo9(long start, long end) {
this.start = start;
this.end = end;
}
public static void main(String[] args) {
text();
System.out.println("-----------------");
textForkJoin();
}
//串行方法
private static void text() {
System.out.println("text");
long start = System.currentTimeMillis();
Long sum = 0L;
for (long i = 0L; i < MAX; i++) {
sum += i;
}
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start + "ms");
}
//并行方法
private static void textForkJoin() {
System.out.println("textForkJoin");
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
Long sum = forkJoinPool.invoke(new Demo9(1, MAX));
System.out.println(sum);
System.out.println(System.currentTimeMillis() - start + "ms");
}
@Override
protected Long compute() {
long sum = 0;
if (end - start <= THRESHOLD) {
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
long mid = (start + end) / 2;
Demo9 task1 = new Demo9(start, mid);
task1.fork();
Demo9 task2 = new Demo9(mid + 1, end);
task2.fork();
return task1.join() + task2.join();
}
}
}
这里需要计算结果,所以任务继承的是RecursiveTask类。ForkJoinTask需要实现compute方法,在这个方法里首先需要判断任务是否小于等于阈值1000,如果是就直接执行任务。否则分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会阻塞并等待子任务执行完并得到其结果。
程序输出:
text
500000000500000000
2858ms
-----------------
textForkJoin
500000000500000000
428ms
从结果看出,并行的时间损耗明显要少于串行的,这就是并行任务的好处。
尽管如此,在使用Fork/Join时也得注意,不要盲目使用。
-
如果任务拆解的很深,系统内的线程数量堆积,导致系统性能性能严重下降;
-
如果函数的调用栈很深,会导致栈内存溢出;
}
}
}
这里需要计算结果,所以任务继承的是RecursiveTask类。ForkJoinTask需要实现compute方法,在这个方法里首先需要判断任务是否小于等于阈值1000,如果是就直接执行任务。否则分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会阻塞并等待子任务执行完并得到其结果。
程序输出:
```java
text
500000000500000000
2858ms
-----------------
textForkJoin
500000000500000000
428ms
从结果看出,并行的时间损耗明显要少于串行的,这就是并行任务的好处。
尽管如此,在使用Fork/Join时也得注意,不要盲目使用。
- 如果任务拆解的很深,系统内的线程数量堆积,导致系统性能性能严重下降;
- 如果函数的调用栈很深,会导致栈内存溢出;














 3851
3851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









