






保存王者荣耀所有英雄的图片:
先搜索王者荣耀官方网站,找到英雄资料,摁F12,找到网络的选项,勾选停用缓存

然后刷新界面,会出现网址里的信息。因为要爬英雄图片,在搜索栏里搜“json”,会出现所有英雄图片的一个文件,点开“herolist.json”我们需要复制此链接
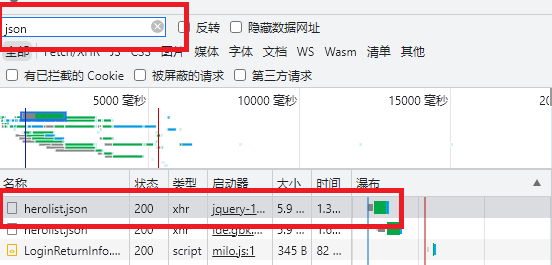
开始写代码:
import requests发起请求 获取所有角色信息
res = requests.get("https://pvp.qq.com/web201605/js/herolist.json")
for role in res.json():
cname = role["cname"]
ename = role["ename"]发起请求 获取所有角色头像
res2 = requests.get(f"https://game.gtimg.cn/images/yxzj/img201606/heroimg/{ename}/{ename}.jpg")这个网站地址是在搜索栏中搜索jpg,复制链接
将请求的图片存到本地磁盘
with open(f"{cname}.jpg","wb") as f:
f.write(res2.content)保存LOL所有英雄的图片:
先搜索LOL官方网站,找到游戏资料资料,摁F12,找到网络的选项,勾选停用缓存,然后刷新界面,会出现网址里的信息。找到存放英雄图片的文件,复制此链接
开始写代码:
import requests发起请求 获取所有角色信息
res = requests.get("https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2794104")
for role in res.json()["hero"]:
heroId = role["heroId"]
name = role["name"]发起请求 获取所有角色头像
res2 = requests.get(f"https://game.gtimg.cn/images/lol/act/img/skinloading/{heroId}000.jpg")将请求的图片存到本地磁盘
with open(f"{name}.jpg","wb") as f:
f.write(res2.content)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









