







Mysql —— 多行/聚合/分组函数

每博一文案
作家三毛说过这样一句话,世间的人和事,来和去都有它的时间,我们只需要把
自己修炼成最好的样子。然后静静地去等待就好了。
人生在世,每个人。都有自己的困境,每个人都有自己的深渊,
每个人都有可能摔进去,但每个人生命都有属于自己的绽放时刻。
这一生的挫折会来,也会过去,热泪会留下,也会收起。
每个在阳光下开怀大笑的人,都有一段沉默的时光。
当我们走过难熬的岁月。回首往昔,当初的脆弱早已变成勇敢,成为了我们
攻坚克难的坚硬铠甲。
愿你纵使孤身一人,也可以将这场生命旅程走得光灿明亮,自由坦荡。
—————— 一禅心灵庙语
文章目录
一. 分组函数
分组函数 又被人叫做是 聚合函数 以及多行函数 ,就是将多行汇总为一行,实际上,所有的聚合函数都是这样的,输入多行输出一行,如下,关于单行函数 的介绍 大家可以移步至 🔜🔜🔜 Mysql 中 “必知” 的单行处理函数_ChinaRainbowSea的博客-CSDN博客
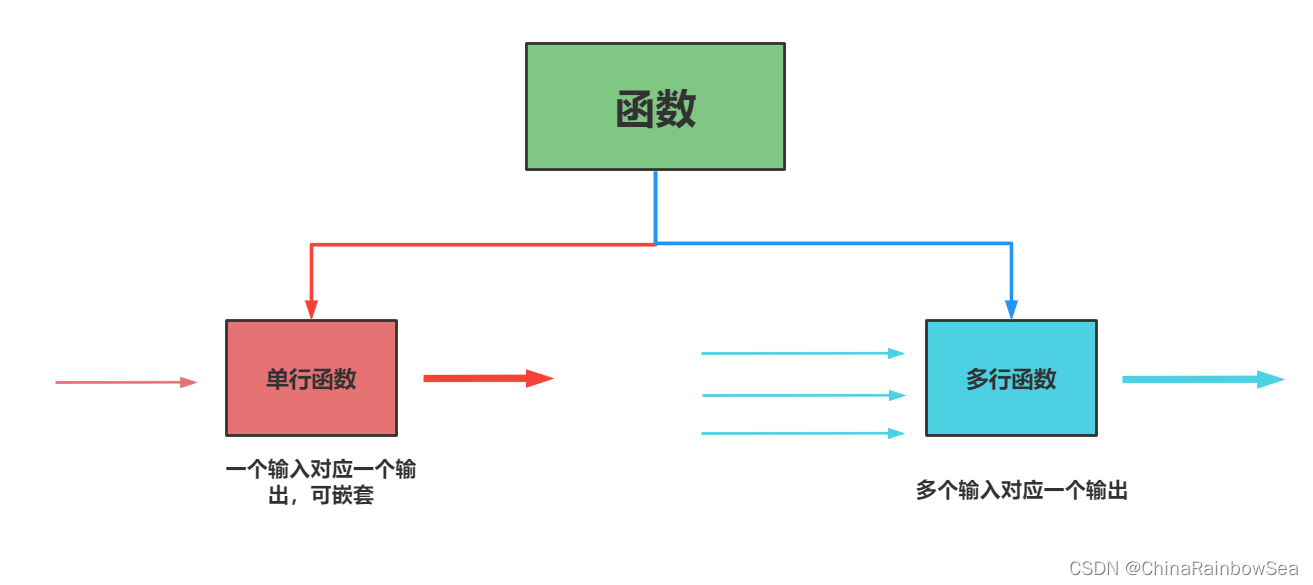
大家记住如下 5 个常用的分组函数
- SUM : 计算表中数值列中数据的合计值
- AVG : 计算表中数值列中数据的平均值
- MAX : 求出表中任意列中数据的最大值
- MIN : 求出表中任意列中数据的最小值
- COUNT : 计算表中的记录数(行数)
注意 :分组函数在使用的时候必须先进行分组 GROUP BY , 然后才能用,如果你没有对数据进行分组,整张表默认为一组
1.1 AVG 与 SUM
- SUM : 计算表中数值列中数据的合计值
- AVG : 计算表中数值列中数据的平均值
**AVG 与 SUM ** :只适用于数值类型的字段,不适用于 字符串,日期时间类型上计算求值
注意 : 无论是 AVG 还是 SUM ,它们都不会计算到 NULL 的,会自动将 NULL 排除在外,因为 含有 NULL的运算其结果也是 NULL 的
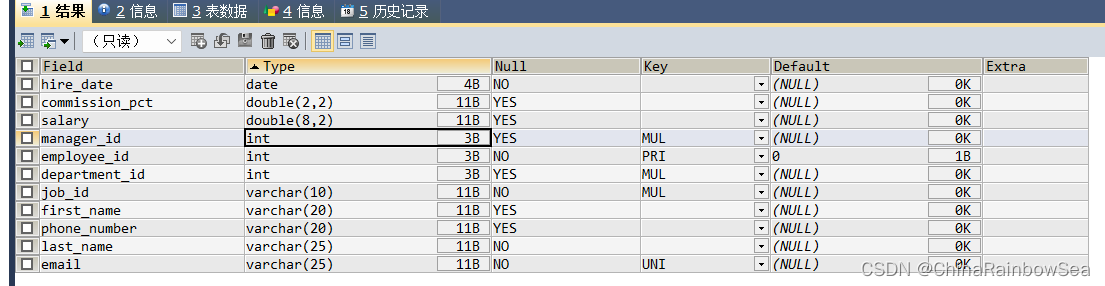
SELECT SUM(salary), AVG(salary)
FROM employees;
运用在日期时间,字符串类型的计算结果,虽然出来了,结果,但是是没有意义的无效的结果的,因为字符串之间不可以直接进行加法,日期时间类型也是无法直接进行加法运算的。
SELECT SUM(last_name), SUM(hire_date), AVG(last_name), AVG(hire_date)
FROM employees;

1.2 MAX 与 MIN
- MAX : 求出表中任意列中数据的最大值
- MIN : 求出表中任意列中数据的最小值
MAX/MIN : 适用于数值类型,字符串类型,日期时间类型的字段(或变量)
注意 : 无论是 MAX 还是 MIN ,它们都不会计算到 NULL 的,会自动将 NULL 排除在外,因为 含有 NULL的运算其结果也是 NULL 的
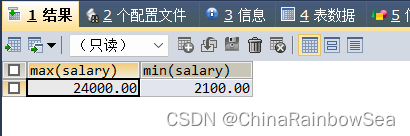
数值上的比较
SELECT MAX(salary), MIN(salary)
FROM employees;
字符串类型上的比较
SELECT MAX(last_name),MIN(last_name)
FROM employees;
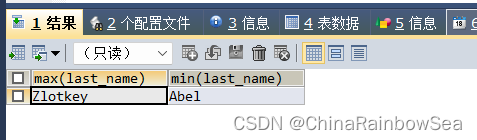
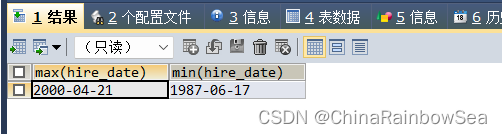
日期时间类型上的比较
SELECT MAX(hire_date), MIN(hire_date)
FROM employees;
1.3 COUNT
- COUNT : 计算表中的记录数(行数)
COUNT(参数) 该分组函数存在两种参数,第一种 参数为(表中的字段),第二种参数为(*) 星号,参数不同意义不同
COUNT(参数) 与 COUNT(*)的区别
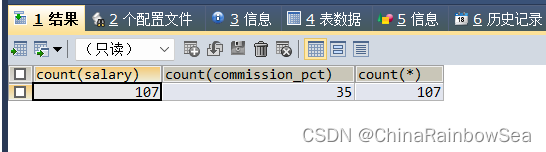
COUNT(表中字段) : 计算指定字段在表中的个数,没有将为空NULL的属性的计算在内,说白了就是统计该字段下所有不为 NULL 的元素的总数,从而导致不同的字段其统计的数值也是不一样的,
COUNT(*) : 表示计算表中所有的行数,只要不是所有的的列数的字段为 NULL,只是其中的某几列字段为 NULL,都计算包含在内,count++,说白了就是,统计该表当中的总行数(只要有一行数据 count ++),同一表中的 count(*) 其数值是一样的
SELECT COUNT(salary), COUNT(commission_pct),COUNT(*)
FROM employees;
SELECT commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
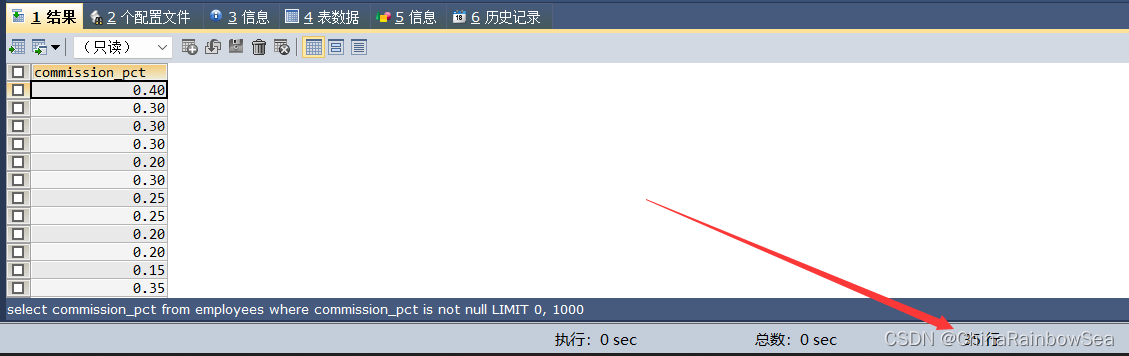
通过上述两个查询结果的比较就可以看出我们的结论是正确的,
1.4 AVG = SUM/COUNT
AVG 平均值的计算都可以使用该公式计算出来,需要注意的是,该公式中的计算对象必须是一致的,不然会因为 其中字段为 NULL的,而导致 COUNT 没有计算到。导致结果的不同
SELECT AVG(salary), SUM(salary)/COUNT(salary), SUM(salary)/COUNT(commission_pct)
FROM employees;

1.5 使用分组函数删除重复值(关键字 DISTINCT)
计算去除重复数据后的行数
SELECT COUNT(DISTINCT salary), COUNT(salary)
FROM employees;
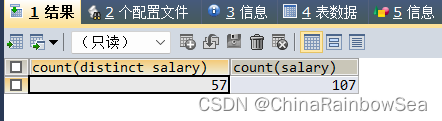
注意 关于 DISTINCT 的使用注意事项:
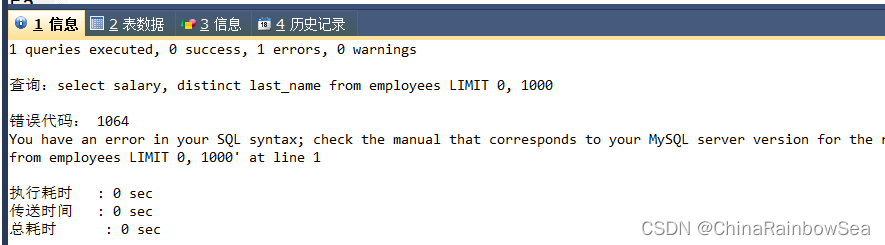
DISTINVCT 除了在运用在分组函数中去重复,单独使用 DISTINVCT 对查询的数据去重复,必须将DISTINVCT 放在 SELECT 查询语句中字段的最开头,不然会报错的,如下:
SELECT salary, DISTINCT last_name FROM employees;
SELECT DISTINCT salary, last_name FROM employees;
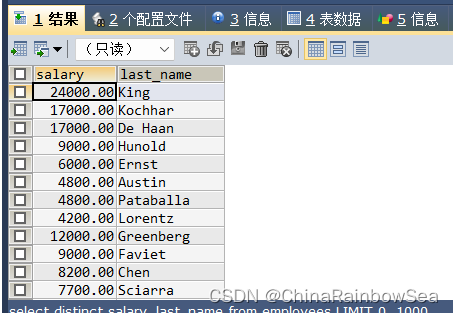
先计算数据行数再删除重复数据
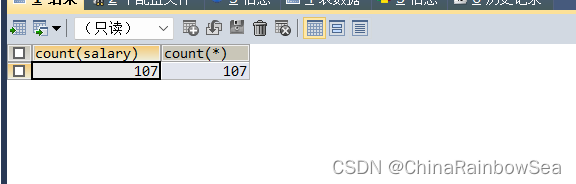
SELECT DISTINCT COUNT(salary),COUNT(*)
FROM employees;
1.6 练习
查询公司中平均奖金率
/* 查询公司中的平均奖金率*/
SELECT AVG(commission_pct)*100
FROM employees;
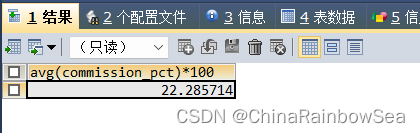
上述查询方法错误,计算奖金率是包含了为NULL,没有得到奖金的,而我们的 分组函数 AVG 是不会计算包含到 NULL 值的,所以错误,不合题意
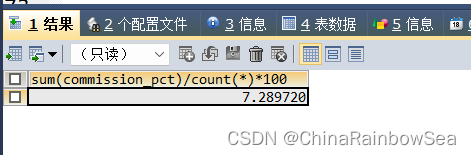
修改方式一,使用 count(*) 统计全部行数包含 NULL,公式 AVG = SUM/COUNT
/* 方式一: 使用公式 AVG = SUM/COUNT*/
SELECT SUM(commission_pct)/COUNT(*)*100
FROM employees;
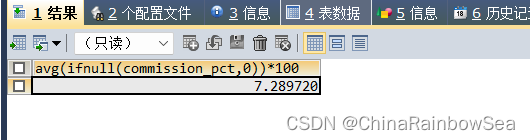
方式二:计算参数为 IFNULL,NULL替换为 0
/* 查询公司中的平均奖金率*/
/* 参数为 IFNULL,NULL替换为 0替换*/
SELECT AVG(IFNULL(commission_pct,0))*100
FROM employees;
方式三: count ifnull nul 替换
/* 查询公司中的平均奖金率*/
/* 方式三 count ifnull null 替换*/
SELECT SUM(commission_pct)/COUNT(IFNULL(commission_pct,0))*100
FROM employees
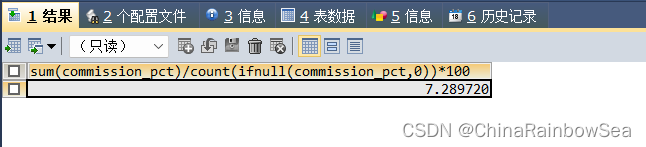
二. GROUP BY
可以使用GROUP BY子句将表中的数据分成若干组
GROUP BY 子句就像切蛋糕那样将表进行了分组。在 GROUP BY 子句中指定的列称为 聚合键 或者 分组列,由于能够决定表的切分方式,所以是非常重要的列。当然,GROUP BY 子句也和 SELECT 子句一样,可以通过逗号分隔指定多列。
GROUP BY 也会对为 NULL的字段(聚合键),进行统一的分组
注意 :分组函数在使用的时候必须先进行分组 GROUP BY , 然后才能用,如果你没有对数据进行分组,整张表默认为一组
需求:查询各个部门的平均工资,最高工资
注意:各个部门需要分组显示
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id /* 根据字段 department_id 进行分组*/
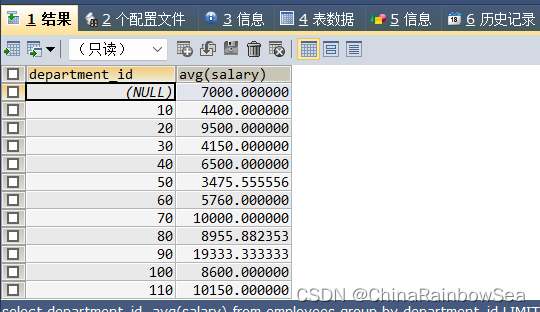
查询各个department_id, job_id 的平均工资
注意 在 GROUP BY …字段1,字段2 ,之间的分组依据的字段的顺序不会影响结果,结果与分组字段的顺序无关
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id; /* 根据字段 departent_id,job_id进行分组*/
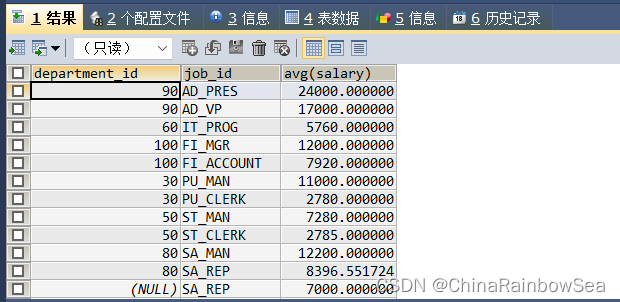
调换分组字段的顺序,不会影响查询的结果
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY job_id,department_id; /*根据字段 job_id,departent_id进行分组*/
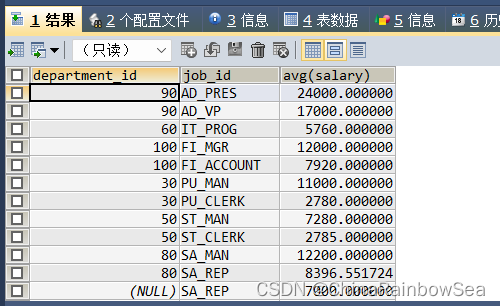
2.1 与分组函数和GROUP BY子句有关的常见错误
- 问题一:——在 SELECT 子句中书写了多余的列
在使用分组函数(AVG, MAX,MIN,SUM,COUNT) 这样的分组函数,SELECT子句中的元素有严格的限制,实际上,使用 GROUP BY时,SELECT 子句中只能存在以下三种元素
- 常数
- 分组函数
- GROUP BY 子句中分组依据的字段(也就是聚合键)
所谓的常数 就像数字 123,或者字符串 ‘测试’ 这样写在 Mysql语句中固定值,在含有 GROUP BY 的MYSQL语句中将常数 直接写在 SELECT 子句中是没有任何问题的,此外还可以直接写 分组函数或者是聚合键 ,这些都是没有问题的。
这里经常会出现的错误就是 把 GROUP BY 子句中分组依据的字段(也就是聚合键)以外的字段书写在了 SELECT 子句中 ,这是不行的,会发生错误,如下:
SELECT department_id,last_name,SUM(salary) /*last_name 出现了聚合键以外的其他字段*/
FROM employees
GROUP BY department_id; /*根据字段 department_id 进行分组*/
虽然,结果显示出来了,但是这是一种错误行为,大家要将其认为是错误,这种错误操作,还显示了结果,只有Mysql 会这样,不会发生错误提示(在多列候补中只要有一列满足要求就可以了)。但是 Mysql以外的DBMS ,如 Oracle ,sever SQL 是不支持这样的语法的,不会显示结果,会直接报错,因此请不要使用这样的语法
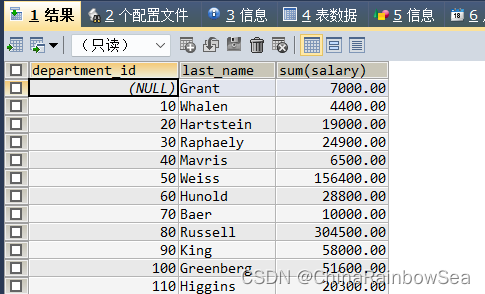
注意,我们的GROUP BY 分组的字段可以不出现 SELECT 子句中对结果没有影响,只是我们不知道是分组后的数据,是那个组的而已,如下:
SELECT SUM(salary)
FROM employees
GROUP BY department_id; /*根据字段 department_id 进行分组*/
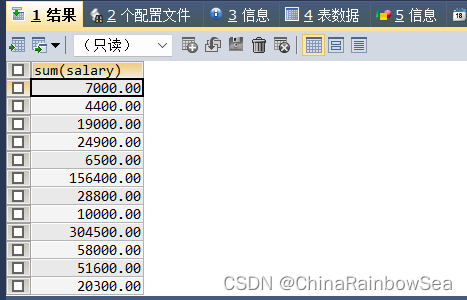
该错误的结论是: 如果 一条 SELECT语句中出现了GROUP BY,那么 在SELECT 子句中出现的字段除了常数,分组函数,其他的必须是在 GROUP BY 中出现了的字段,反之,GROUP BY 出现的字段可以不用在 SELECT 中出现。这样看起来,GROUP BY 是不是十分的霸道,没有办法语法规定了。
- 问题二: ——在GROUP BY子句中使用了别名
这是一个非常常见的错误,我们学过SELECT 中使用 子句中的项目可以通过 AS 关键字用来指定别名,但是,在 GROUP BY 中是不能使用别名的。如下:
SELECT department_id AS dep , SUM(salary)
FROM employees
GROUP BY dep; /* 在GROUP BY子句中使用了 SELECT定义的别名 进行分组*/
这种错误是由SQL 语句在 DBMS 内部的执行顺序造成的——SELECT 子句是在 GROUP BY子句之后执行的。在执行 GROUP BY子句的时候,SELECT 子句中定义的别名,DBMS 还不知道的。虽然该 SQL 语句的错误使用在Mysql 中是不会报错的,但是这种错误的写法在其他的 DBMS 是行不通的,因此请大家不要使用。
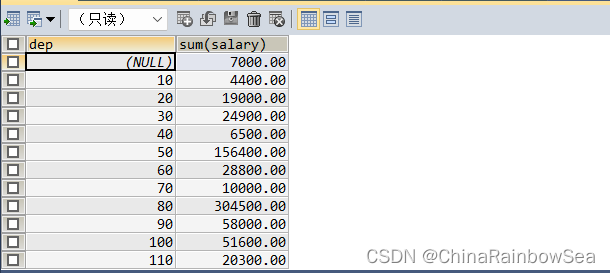
该错误的结论是: 在 GROUP BY子句中不要使用 SELECT子句中定义的别名,在 FROM 定义的表别名没有问题
- 问题三: ——GROUP BY 在 FROM之后使用
这是语法规定的要求,具体大家可以看到本文章的第四点处,查看,
GROUP BY 子句的结果通常都包含了多行,有时可能是成百上千行,那么,这些结果都是按照什么顺序排序的 ??? 答案是:随机的
有时候乍一看是按照行数的降序或是是升序排序的,注意的这只是偶然的。
三. HAVING
我们使用GROUP BY 子句,可以得到将表分组后的结果。在此,我们想通过指定条件选取特定组的方法。说到指定条件大家都会想到使用 WHERE 子句。但是,WHEHE 子句只能指定记录(行)的条件,而不能用来指定组的条件(就是在WHERE 不能对分组函数 进行过滤筛选,否则会报错的)。为什么会报错,具体报错的原因大家可以翻看本文章的的第四点
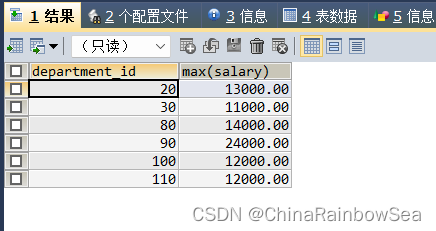
如下:查询各个部门中员工最大工资大于 10000 的信息
SELECT department_id, MAX(salary)
FROM employees
WHERE MAX(salary) > 10000
GROUP BY department_id;

而我们的 HAVING 作用和 WHERE 一样是条件筛选,但是 HAVING 是专门解决WHERE 不能对分组函数 进行过滤筛选,否则会报错的问题的,HAVING 对 使用了分组函数 的条件过滤筛选的作用,
注意: HAVING子句必须写在GROUP BY(分组之后) ,HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
使用HAVING 对分组函数过滤,同样
如下:查询各个部门中员工最大工资大于 10000 的信息
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
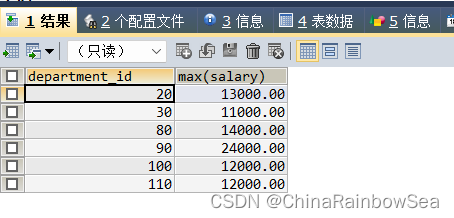
上述的查询存在一定的效率的消耗,该查询方式是先对表中所有的数据进行分组(GROUP BY),但是所有数据分组后,通过HAVING 筛选后,只要其中的几条分组的结果,前面对所有数据的分组都浪费了,大大影响效率。
优化策略
先对表中的所有数据进行 WHERE < 10000 的工资的筛选后,再对这些筛选过后满足条件的数据,分组(GROUP BY) 从而减少无用的分组的数据量,提高效率,再对分组后的数据,过滤(HAVING)
SELECT department_id, MAX(salary)
FROM employees
WHERE salary > 10000
GROUP BY department_id
HAVING MAX(salary) > 10000;
结论
当条件过滤中存在分组函数(AVG, SUM,MAX,MIN,COUNT),则次过滤条件的筛选必须声明在HAVING中,当过滤条件中没有分组函数的时候,此过滤条件声明在 WHERE中,提高效率,在分组**(GROUP BY)** ,先思考一下是否可以使用 WHERE过滤掉一部分的数据减少,分组的数据量,提高效率
四. SELECT 的执行过程顺序
- SQL 92 语法执行顺序
SELECT ... 5.查询
FROM ... 1. 表
WHERE ... 2. 筛选
GROUP BY ... 3. 分组
HAVING ... 4. 分组函数过滤
ORDER BY ... 6. 排序
LIMIT ...7. 分页
- SQL 99 语法执行顺序
SELECT ... 5. 查询
FROM ...(LEFT / RIGHT) JOIN ... ON 1. 外连接
WHERE ... 2. 过滤
GROUP BY ... 3. 分组
HAVING ... 4. 分组过滤
ORDER BY ... 6. ASC / DESC 排序
LIMIT ... 7. 分页
关键字之间的执行顺序不能颠倒了
FROM -> JOIN (LEFT / RIGHT) -> NO -> WHERE -> GROUP BY -> HAVING
-> SELECT -> DISTINCT -> ORDER BY -> LIMIT
面试问题: 为什么分组函数(AVG, SUM,MAX,MIN,COUNT) 不能在 WHERE中使用 ???
因为分组函数(AVG, SUM,MAX,MIN,COUNT) 必须先进行分组(GROUP BY) 然后才能使用,如果你没有对数据进行分组(GROUP BY) ,默认整张表为一组,
从上面的SQL执行顺序我们可以知道,在WHERE 子句执行的时候,还没有进行分组(GROUP BY) , 所以 WHERE 后面不能出现分组函数,这是个执行顺序的先后问题,与Java中是静态的访问非静态的是类似的
面试问题: 那为什么 SELECT SUM(salary) FROM employees 这个没有分组,为啥可以使用呢 ???
SELECT SUM(salary) FROM employees;
因为从执行顺序中我们可以看出 SELECT 是在 GROUP BY 之后执行的,所以是可以使用的
五. 相关练习
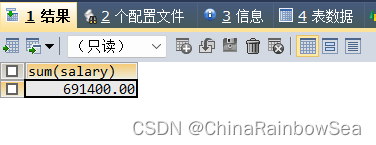
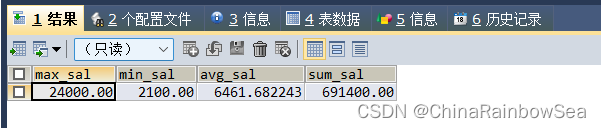
查询员工工资的最大值,最小值,平均值,总和
/* 查询员工工资的最大值,最小值,平均值,总和*/
SELECT MAX(salary) AS max_sal, MIN(salary) AS min_sal,
AVG(salarY) AS avg_sal, SUM(salary) AS sum_sal
FROM employees;
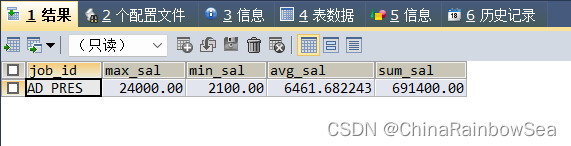
查询各 job_id 的员工的最大值最小值,平均值,总和
/* 查询各 job_id 的员工的最大值最小值,平均值,总和
各个说明需要分组 */
SELECT job_id, MAX(salary) AS max_sal, MIN(salary) AS min_sal,
AVG(salary) AS avg_sal, SUM(salary) AS sum_sal
FROM employees;
计算具有各个 job_id 的员工人数
/* 计算具有各个 job_id 的员工人数
注意计算员工人数,为NULL的不计算到*/
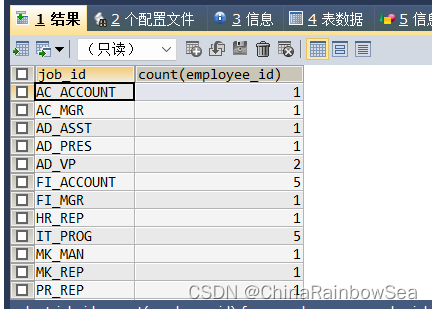
SELECT job_id, COUNT(employee_id)
FROM employees
GROUP BY job_id /* 根据 job_id 分组*/
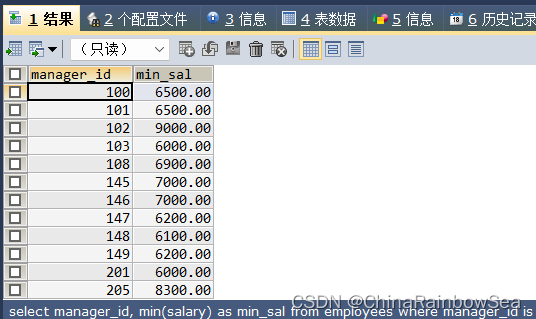
查询各个管理者手下员工的最低工资,其中最低工资不能低于 6000 没有管理者的员工不计算在内
/*查询各个管理者手下员工的最低工资,其中最低工资不能低于 6000 没有管理者的员工不计算在内*/
SELECT manager_id, MIN(salary) AS min_sal
FROM employees
WHERE manager_id IS NOT NULL
AND salary >= 6000
GROUP BY manager_id
HAVING MIN(salary) >= 6000;
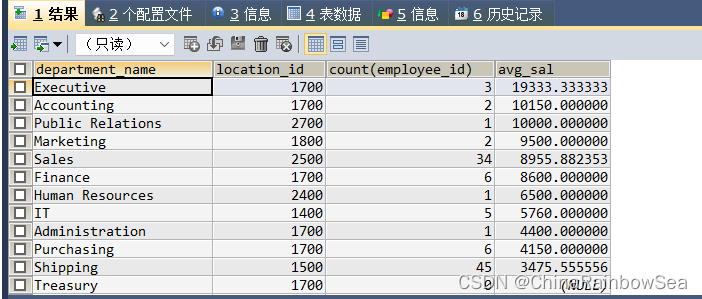
查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
/*查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
注意所有,外连接*/
SELECT dep.department_name, dep.location_id, COUNT(employee_id),
AVG(salary) AS avg_sal
FROM employees AS emp
RIGHT JOIN departments AS dep
ON dep.`department_id` = emp.`department_id`
GROUP BY dep.`department_name`, dep.`location_id`
ORDER BY avg_sal DESC; /* desc 降序,单独使用是查看表结构,asc 升序*/
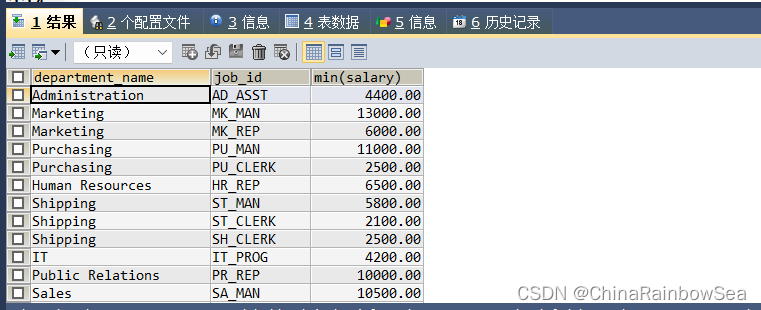
查询每个工种,每个部门的部门名,工种名和最低工资
/*查询每个工种,每个部门的部门名,工种名和最低工资
每个外连接*/
SELECT dep.department_name, emp.job_id, MIN(salary)
FROM departments AS dep
LEFT JOIN employees AS emp
ON dep.`department_id` = emp.`department_id`
GROUP BY dep.`department_name`,emp.`job_id`;
最后:
限于自身水平,其中存在的错误,希望大家给予指教,韩信点兵——多多益善,谢谢大家,后会有期,江湖再见!















 2525
2525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









