






参考:https://blog.csdn.net/pzjdoytt/article/details/126775241
https://www.cnblogs.com/an-wen/p/11180076.html
https://www.zhihu.com/question/32163005/answer/55772739
https://zhuanlan.zhihu.com/p/364044293
https://huixxi.github.io
前言
Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器。
使用 线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和模拟Proactor均实现) 的并发模型
使用状态机解析HTTP请求报文,支持解析GET和POST请求
访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件
实现同步/异步日志系统,记录服务器运行状态
经Webbench压力测试可以实现上万的并发连接数据交换
项目原代码:源码
基础知识
浏览器访问网站的完整流程:
](https://img-blog.csdnimg.cn/df4fb15118c8418b9291d42c97dd6686.png)
什么是CGI校验
CGI(通用网关接口),它是一个运行在Web服务器上的程序,在编译的时候将相应的.cpp文件编程成.cgi文件并在主程序中调用即可(通过社长的makefile文件内容也可以看出)。这些CGI程序通常通过客户在其浏览器上点击一个button时运行。这些程序通常用来执行一些信息搜索、存储等任务,而且通常会生成一个动态的HTML网页来响应客户的HTTP请求。我们可以发现项目中的sign.cpp文件就是我们的CGI程序,将用户请求中的用户名和密码保存在一个id_passwd.txt文件中,通过将数据库中的用户名和密码存到一个map中用于校验。在主程序中通过execl(m_real_file, &flag, name, password, NULL);这句命令来执行这个CGI文件,这里CGI程序仅用于校验,并未直接返回给用户响应。这个CGI程序的运行通过多进程来实现,根据其返回结果判断校验结果(使用pipe进行父子进程的通信,子进程将校验结果写到pipe的写端,父进程在读端读取)。
HTTP协议简介
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
HTTP协议概述
**HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。**我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。
HTTP报文分为请求报文(浏览器端向服务器发送)和响应报文(服务器处理后返回给浏览器端)两种,每种报文必须按照特有格式生成,才能被浏览器端识别。
请求报文=请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
IO 多路复用是什么意思?
IO复用指的是在单个进程中通过记录跟踪每一个Socket(I/O流)的状态来同时管理多个I/O流. 发明它的原因,是尽量多的提高服务器的吞吐能力。要解决多客户端连接的问题,首先得有一个队列来对这个连接请求进行排序存放,而后需要通过并发多线程的手段对已连接的客户进行应答处理。
本项目是利用epollIO复用技术实现对监听socket(listenfd)和连接socket(客户请求连接之后的socket)的同时监听。注意I/O复用虽然可以同时监听多个文件描述符,但是它本身是阻塞的,所以为提高效率,这部分通过线程池来实现并发,为每个就绪的文件描述符分配一个逻辑单元(线程)来处理。
Unix有五种基本的IO模型:
阻塞式IO(守株待兔)
非阻塞式IO(没有就返回,直到有,其实是一种轮询(polling)操作)
IO复用(select、poll等,使系统阻塞在select或poll调用上,而不是真正的IO系统调用(如recvfrom),等待select返回可读才调用IO系统,其优势就在于可以等待多个描述符就位)
信号驱动式IO(sigio,即利用信号处理函数来通知数据已完备且不阻塞主进程)
异步IO(posix的aio_系列函数,与信号驱动的区别在于,信号驱动是内核告诉我们何时可以进行IO,而后者是内核通知何时IO操作已完成)
对于到来的IO事件(或是其他的信号/定时事件),又有两种事件处理模式:
Reactor模式:要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生(可读、可写),若有,则立即通知工作线程,将socket可读可写事件放入请求队列,读写数据、接受新连接及处理客户请求均在工作线程中完成。(需要区别读和写事件)
**Proactor模式:**主线程和内核负责处理读写数据、接受新连接等I/O操作,工作线程仅负责业务逻辑(给予相应的返回url),如处理客户请求。
通常使用同步I/O模型(如epoll_wait)实现Reactor,使用异步I/O(如aio_read和aio_write)实现Proactor,但是异步IO并不成熟,本项目中使用同步IO模拟proactor模式。
PS:什么是同步I/O,什么是异步I/O呢?
同步(阻塞)I/O:等待IO操作完成,才能继续进行下一步操作。这种情况称为同步IO。
异步(非阻塞)I/O:当代码执行IO操作时,它只发出IO指令,并不等待IO结果,然后就去执行其他代码了。一段时间后,当IO返回结果时(内核已经完成数据拷贝),再通知CPU进行处理。(异步操作的潜台词就是你先做,我去忙其他的,你好了再叫我)
IO复用需要借助select/poll/epoll,本项目之所以采用epoll,参考问题(Why is epoll faster than select?)
对于select和poll来说,所有文件描述符都是在用户态被加入其文件描述符集合的,每次调用都需要将整个集合拷贝到内核态;epoll则将整个文件描述符集合维护在内核态,每次添加文件描述符的时候都需要执行一个系统调用。系统调用的开销是很大的,而且在有很多短期活跃连接的情况下,epoll可能会慢于select和poll由于这些大量的系统调用开销。
select使用线性表描述文件描述符集合,文件描述符有上限;poll使用链表来描述;epoll底层通过红黑树来描述,并且维护一个ready list,将事件表中已经就绪的事件添加到这里,在使用epoll_wait调用时,仅观察这个list中有没有数据即可。
select和poll的最大开销来自内核判断是否有文件描述符就绪这一过程:每次执行select或poll调用时,它们会采用遍历的方式,遍历整个文件描述符集合去判断各个文件描述符是否有活动;epoll则不需要去以这种方式检查,当有活动产生时,会自动触发epoll回调函数通知epoll文件描述符,然后内核将这些就绪的文件描述符放到之前提到的ready list中等待epoll_wait调用后被处理。
select和poll都只能工作在相对低效的LT模式下,而epoll同时支持LT和ET模式。
综上,当监测的fd数量较小,且各个fd都很活跃的情况下,建议使用select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使用epoll会明显提升性能。
其中提到的LT与ET是什么意思?
LT是指电平触发(level trigger),当IO事件就绪时,内核会一直通知,直到该IO事件被处理;
ET是指边沿触发(Edge trigger),当IO事件就绪时,内核只会通知一次,如果在这次没有及时处理,该IO事件就丢失了。
什么是多线程?
上文提到了并发多线程,在计算机中程序是作为一个进程存在的,线程是对进程的进一步划分,即在一个进程中可以有多个不同的代码执行路径。相对于进程而言,线程不需要操作系统为其分配资源,因为它的资源就在进程中,并且线程的创建和销毁相比于进程小得多,所以多线程程序效率较高。
但是在服务器项目中,如果频繁地创建/销毁线程也是不可取的,这就引入了线程池技术,即提前创建一批线程,当有任务需要执行时,就从线程池中选一个线程来进行任务的执行,任务执行完毕之后,再将该线程丢进线程池中,以等待后续的任务。
多线程是处理高并发的一种编程方法,即并发需要用多线程实现。且一个进程里面可以有多个线程。
代码架构
用VsCode打开项目,该项目的代码架构如下:
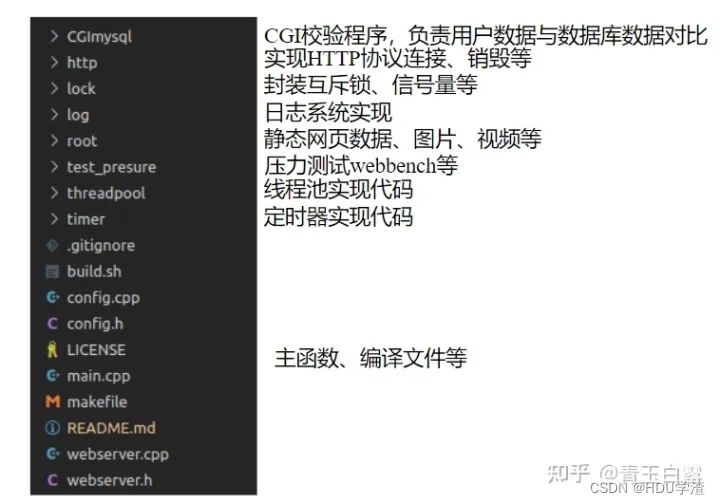
参考文档,该项目的代码框架如下:
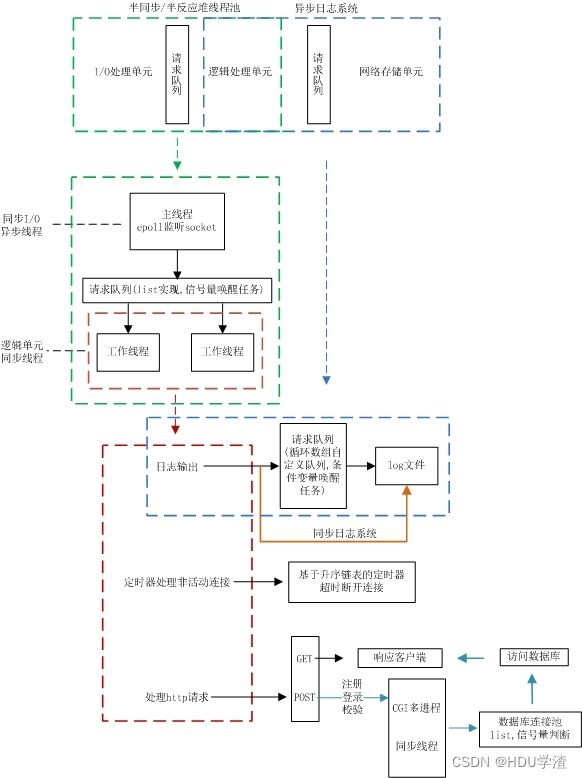
一个服务器运行时工作流程图如下:
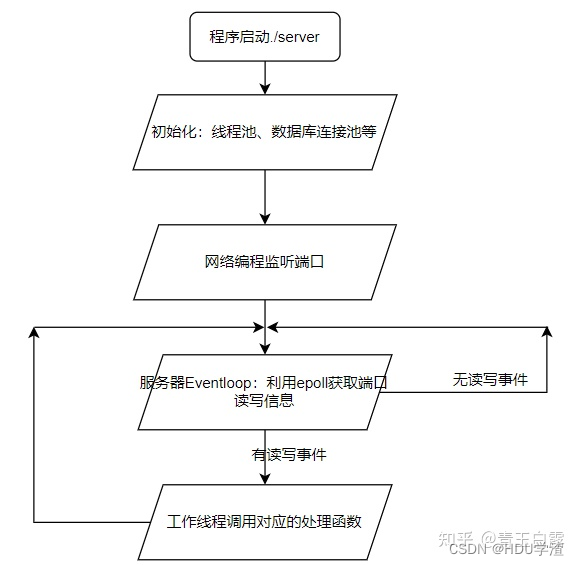
数据库连接池是如何运行的
在处理用户注册,登录请求的时候,我们需要将这些用户的用户名和密码保存下来用于新用户的注册及老用户的登录校验,相信每个人都体验过,当你在一个网站上注册一个用户时,应该经常会遇到“您的用户名已被使用”,或者在登录的时候输错密码了网页会提示你“您输入的用户名或密码有误”等等类似情况,这种功能是服务器端通过用户键入的用户名密码和数据库中已记录下来的用户名密码数据进行校验实现的。若每次用户请求我们都需要新建一个数据库连接,请求结束后我们释放该数据库连接,当用户请求连接过多时,这种做法过于低效,所以类似线程池的做法,我们构建一个数据库连接池,预先生成一些数据库连接放在那里供用户请求使用。
(找不到mysql/mysql.h头文件的时候,需要安装一个库文件:sudo apt install libmysqlclient-dev)
我们首先看单个数据库连接是如何生成的:
使用mysql_init()初始化连接
使用mysql_real_connect()建立一个到mysql数据库的连接
使用mysql_query()执行查询语句
使用result = mysql_store_result(mysql)获取结果集
使用mysql_num_fields(result)获取查询的列数,mysql_num_rows(result)获取结果集的行数
通过mysql_fetch_row(result)不断获取下一行,然后循环输出
使用mysql_free_result(result)释放结果集所占内存
使用mysql_close(conn)关闭连接
对于一个数据库连接池来讲,就是预先生成多个这样的数据库连接,然后放在一个链表中,同时维护最大连接数MAX_CONN,当前可用连接数FREE_CONN和当前已用连接数CUR_CONN这三个变量。同样注意在对连接池操作时(获取,释放),要用到锁机制,因为它被所有线程共享。
Webbench是什么,介绍一下原理
父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。














 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









