






目录
一、项目前准备
注:在进行之前、小编默认你有一些es的基础能力,可以简单编写DSL语句
1、了解什么是ElasticSearch
Elasticsearch是一个开源的分布式搜索和分析引擎,它是建立在Apache Lucene搜索引擎库之上的。Elasticsearch提供了一个RESTful API,用于实时地存储、搜索和分析大量数据。它被广泛用于构建实时搜索、日志分析、应用程序性能监控等各种用例中。
Elasticsearch具有以下特点:
- 分布式架构:可以轻松地扩展到多个节点,实现高可用性和水平扩展。
- 实时搜索:支持实时索引和搜索,能够快速地处理大量数据。
- 多种数据类型支持:除了全文搜索外,还支持结构化数据、地理空间数据等多种数据类型的搜索和分析。
- 强大的聚合功能:能够进行复杂的数据聚合和分析操作。
- 插件生态系统:有丰富的插件和工具可用于扩展和定制Elasticsearch的功能。
总的来说,Elasticsearch是一个功能强大、灵活且易于扩展的搜索和分析引擎,适用于各种大规模数据处理和搜索场景。例如京东、淘宝、百度、携程等大型软件都是采用这门技术。
2、配置docker环境
在我有一篇文章里提到了如何安装docker 地址:关于docker-compose在linux上的集群部署_linux使用compose部署-CSDN博客
3、安装ElasticSearch镜像
3.1 dockerHub上安装
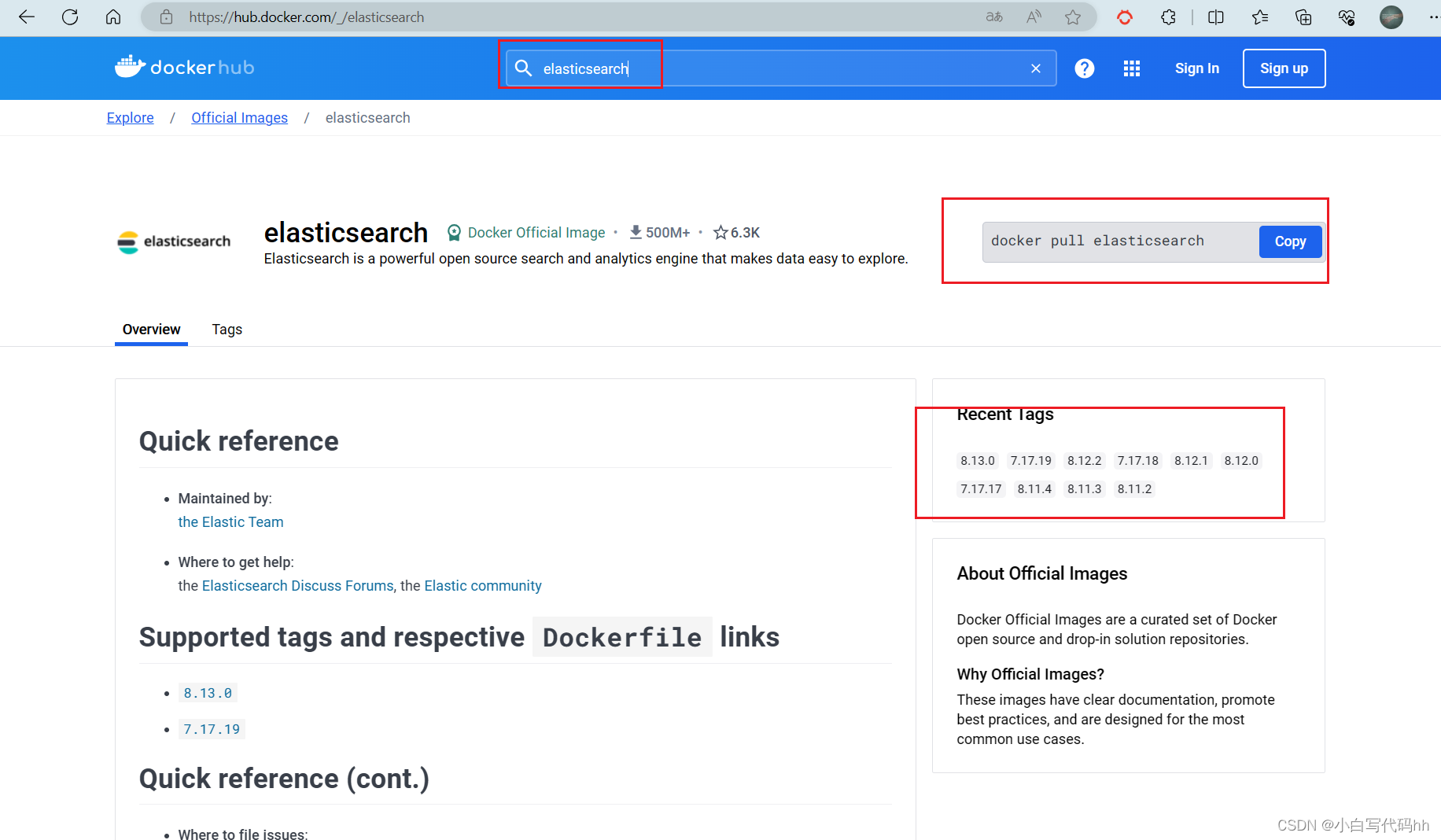
这里自己选择版本 把代码放到linux上面运行就OK 就拉去好镜像了
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。建议大家和我的保持一致
运行ElasticSearch
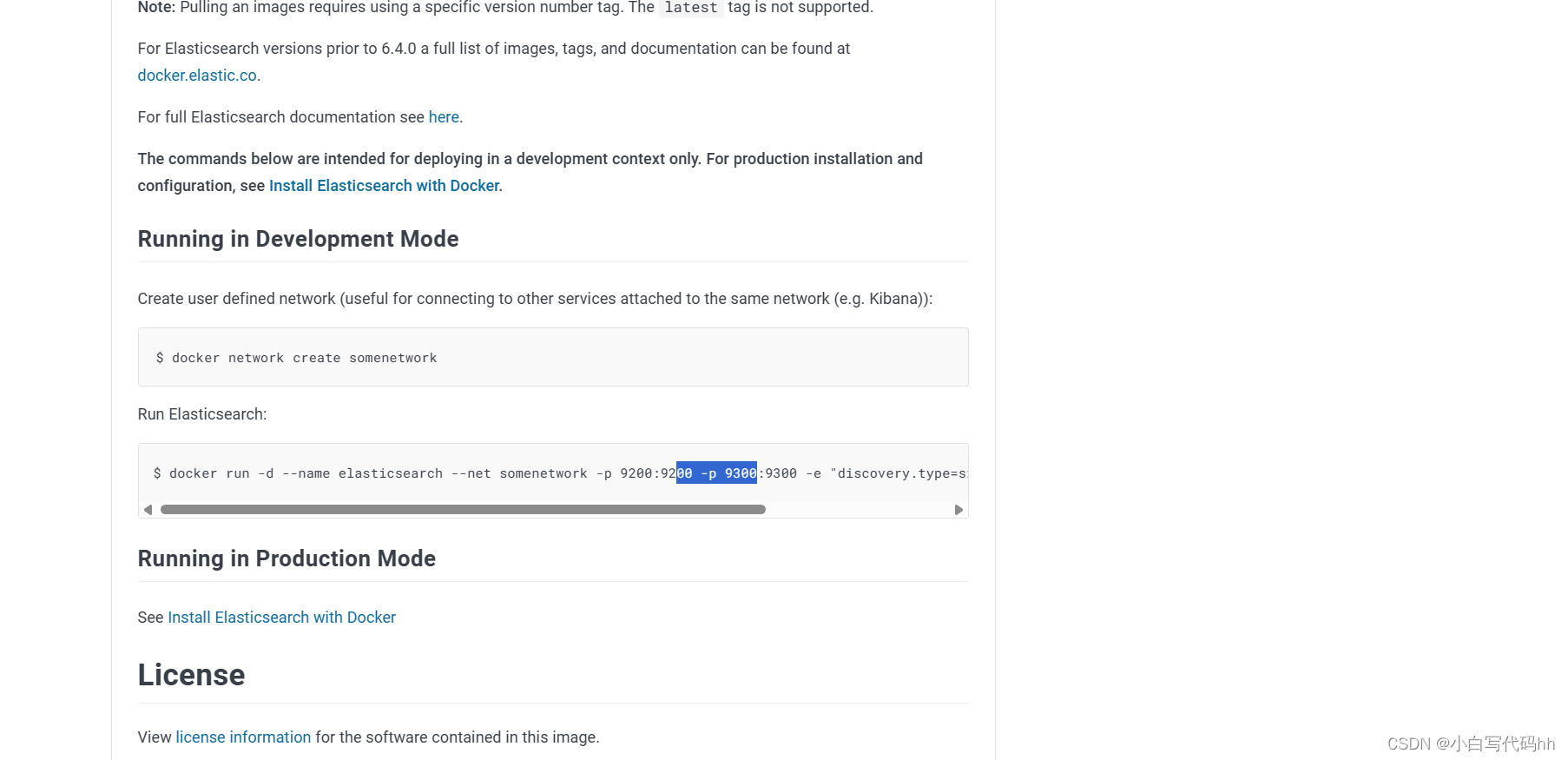
官网上是有文档教程的 大家可以去看:
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net我这里直接写了
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.14、安装kibana镜像
同上步骤 这里不用多解释
启动方式:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1 
可以看到两个镜像均是拉去下来了
接下来执行以上命令便可以跑起来了。
在浏览器输入你的虚拟机ip+端口 例如 我的es是:

kibana是:
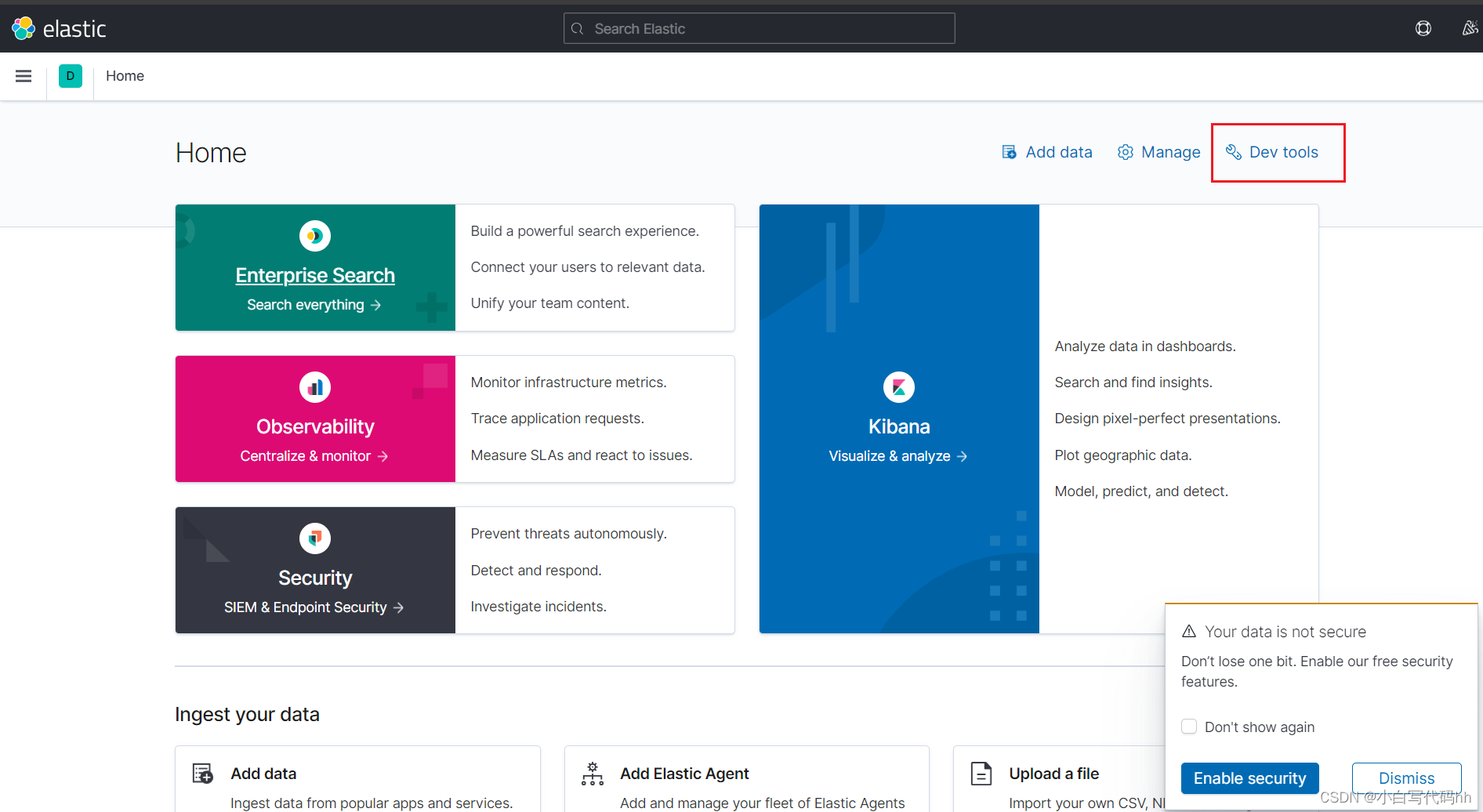
点击devops就可以进入dsl语句书写界面了。
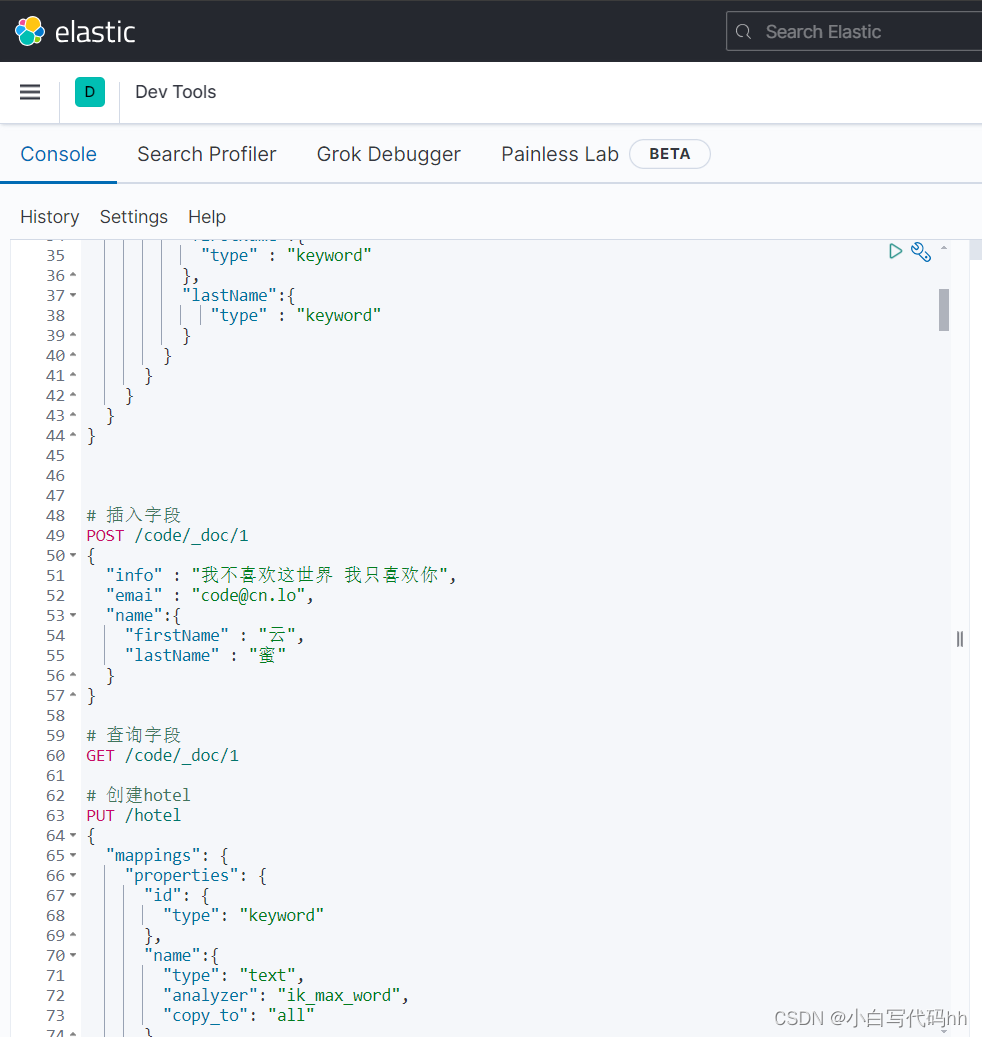
5、安装ik分词器
可以在github上去下载 也可用提供的资料 资料放在末尾 官网 https://github.com/infinilabs/analysis-ik
6、安装拼音分词器
同上:官网:
https://github.com/infinilabs/analysis-pinyin
将下载好的压缩包 解压放到es目录下
-v es-plugins:/usr/share/elasticsearch/plugins 就在刚刚启动挂载的容器卷下。
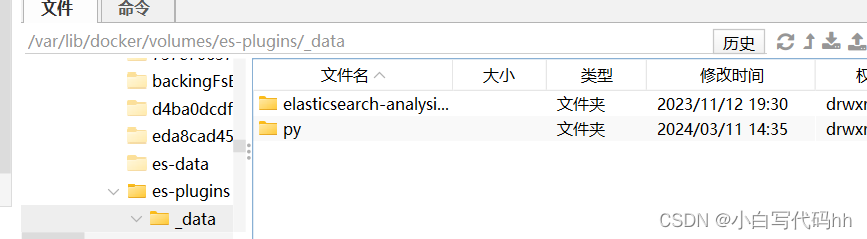
如果急记不得 输入以下指令
docker volume ls
find -/ name es-plugins
就会显现容器卷的 然后查找它所在的位置即可
7、编写对应数据库的索引
7.1数据库表的字段
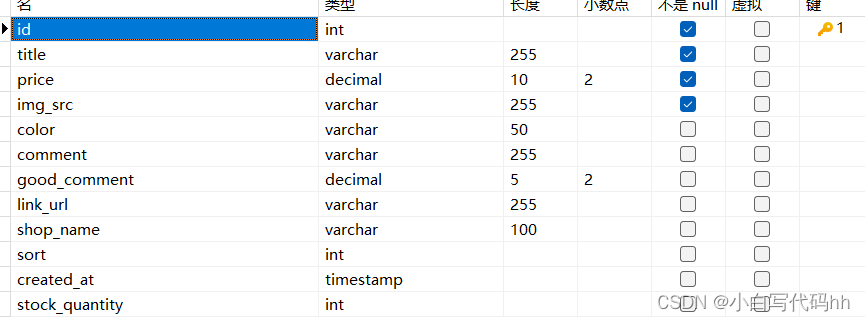
建立的索引为:
PUT /product
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"title":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"img_src":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"color":{
"type": "keyword",
"copy_to": "all"
},
"comment":{
"type": "keyword"
},
"good_comment":{
"type": "keyword"
},
"link_url":{
"type": "keyword"
},
"shop_name":{
"type": "keyword",
"copy_to": "all"
},
"sort":{
"type": "integer",
"index": false
},
"created_at":{
"type": "keyword",
"index": false
},
"stock_quantity":{
"type": "integer"
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"category":{
"type": "text",
"copy_to": "all",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}执行
GET /product/_mapping
出现这样便是创建成功:自己可以添加点数据测试一下 这里就大家自己去测试吧!
二、JAVA代码的配置。
默认创建好项目
1、导入依赖
<!--elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>注意:因为spring项目依赖里默认有es的 所以需要把版本修改了
<properties>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>版本和自己pull的版本一定要对应 一定要对应、一定要对应,重要的是说三遍!!!
2、添加数据到创建好的文档里
2.1 配置es客户端的bean 添加到主启动类里面
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.88.130:9200")//ip + 端口需要改成自己的
));
}2.2 批量导入文件到es里面
// 批量导入文件到es
@Test
void addEsProduct() {
BulkRequest bulkRequest = new BulkRequest();
List<ProductComplex> productComplexes = productMapper.selectProductAll();
for (ProductComplex productComplex : productComplexes) {
ProductDoc productDoc = new ProductDoc(productComplex);
String json = JSON.toJSONString(productDoc);
bulkRequest.add(new IndexRequest("product")
.id(productDoc.getId().toString())
.source(json, XContentType.JSON));
}
try {
client.bulk(bulkRequest, RequestOptions.DEFAULT); // 将这行代码移动到forEach循环之外
} catch (IOException e) {
throw new RuntimeException(e);
}
}这里需要再字段里面定义suggestion属性 做自动补全的字段。
例如:
@Data
public class ProductDoc {
private Long id;
private String title;
private String imgSrc;
private String color;
private String comment;
private Integer price;
private String goodComment;
private String linkUrl;
private String shopName;
private Integer sort;
private Timestamp createdAt;
private Integer stockQuantity;
private String category;
private List<String> suggestion;
public ProductDoc(ProductComplex product) {
this.id = product.getId();
this.title = product.getTitle().replaceAll("<font[^>]*>", "").replaceAll("</font>", "");
this.imgSrc = product.getImgSrc();
this.color = product.getColor();
this.comment = product.getComment();
this.goodComment = product.getGoodComment();
this.linkUrl = product.getLinkUrl();
this.shopName = product.getShopName();
this.sort = product.getSort();
this.createdAt = product.getCreatedAt();
this.stockQuantity = product.getStockQuantity();
this.suggestion = new ArrayList<>();
this.category = product.getType();
this.price = product.getPrice();
this.suggestion.add(this.title);
this.suggestion.add(this.shopName);
}
}这里用mybatis去查询 以及查询就不多说了
去控制台查询一下结果

共有八百多条数据 并且也有suggestion字段
3、编写查询语句
自动补全的代码 接受一个key的参数 字符串类型
service层的代码为:
// 自动补全
@Override
public PageResult getSuggestion(String key) {
SearchRequest request = new SearchRequest("product");
request.source().suggest(new SuggestBuilder().addSuggestion(
"title_suggest",
SuggestBuilders
.completionSuggestion("suggestion")
.prefix(key)
.skipDuplicates(true)
.size(10)
));
SearchResponse response = null;
try {
response = client.search(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
Suggest suggest = response.getSuggest();
List<String> list = new ArrayList<>();
suggest.getSuggestion("title_suggest").forEach(suggestion -> {
suggestion.getOptions().forEach(entry -> {
list.add(entry.getText().string());
});
});
return new PageResult(HttpStatus.HTTP_OK,list,"查询成功" );
}4、测试结果

可以看到是可以自动补全词条的这里
在测试根据搜索结果高亮显示
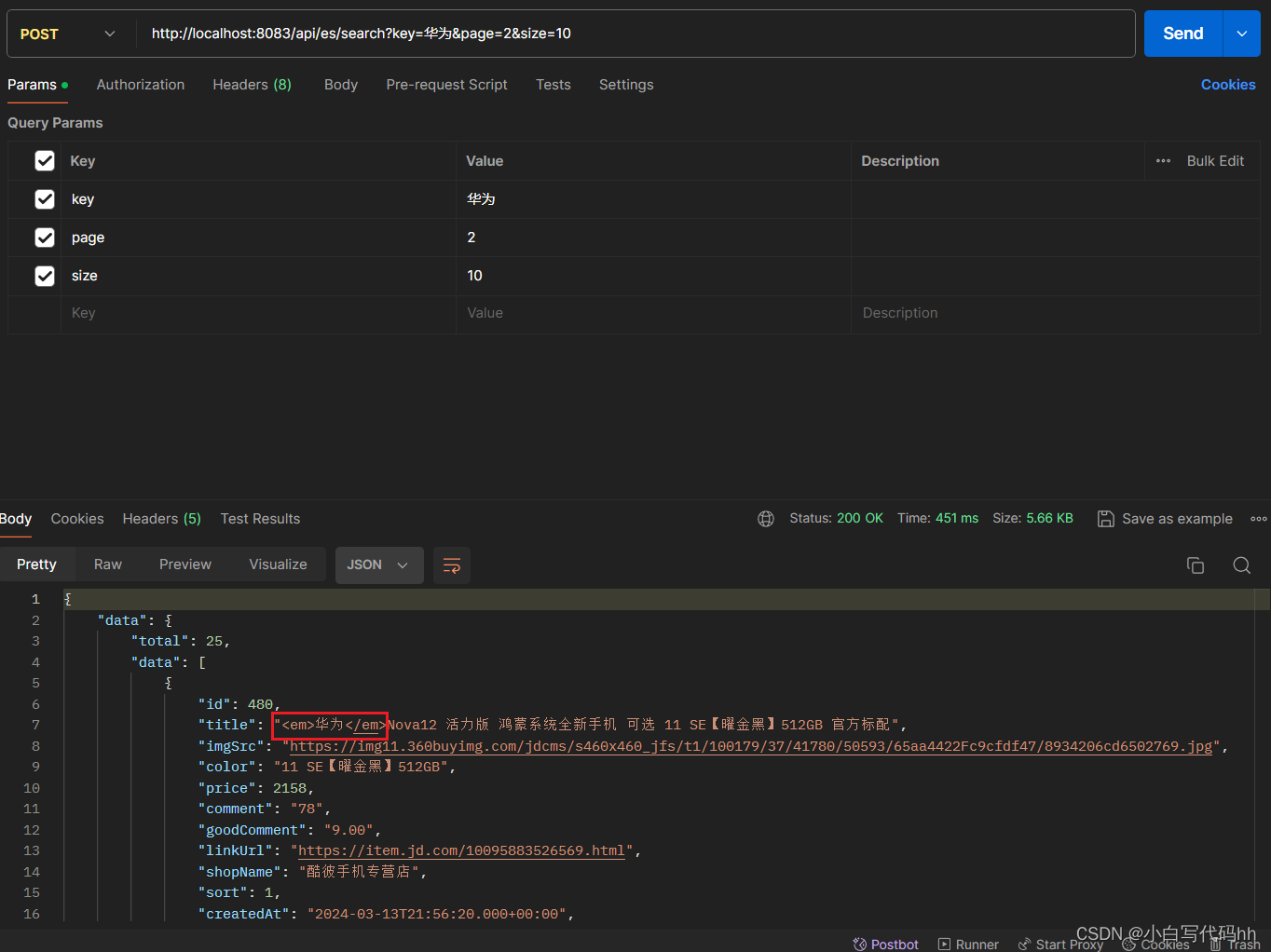
可以看到搜索的关键词也是被<em>标签包裹着的 到时后只需要给标签设置颜色即可。
资料: 链接:https://pan.baidu.com/s/1p7uz6WflDPIb0D4yIFEJGQ
提取码:lpfr
















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









