






缓存穿透:
查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库。
方法一:

方法二:
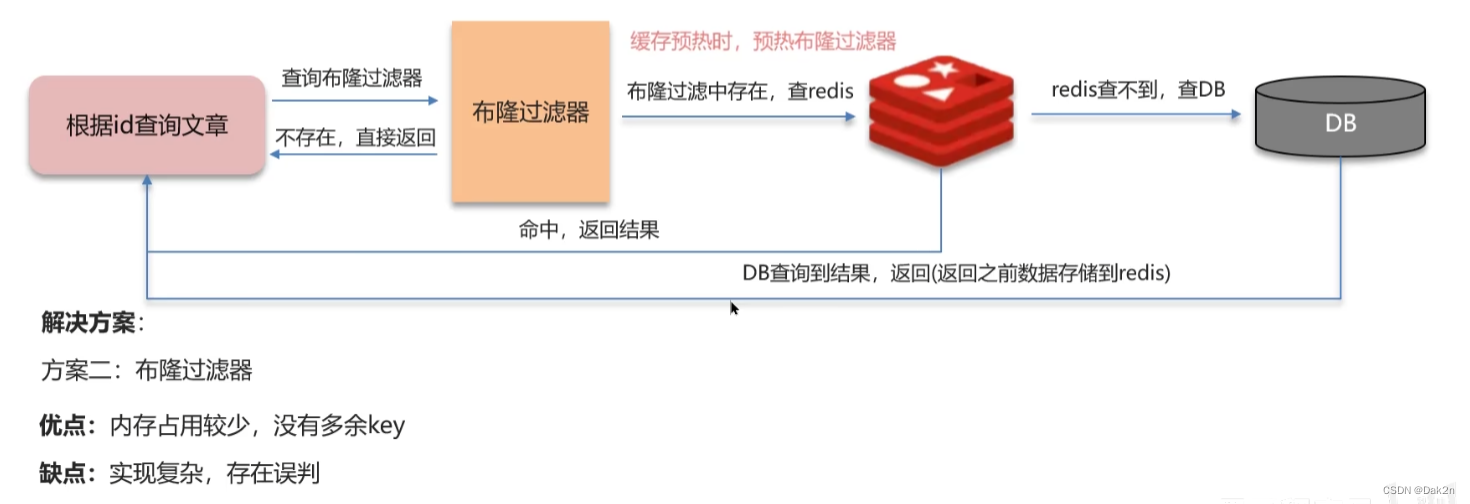
布隆过滤器:
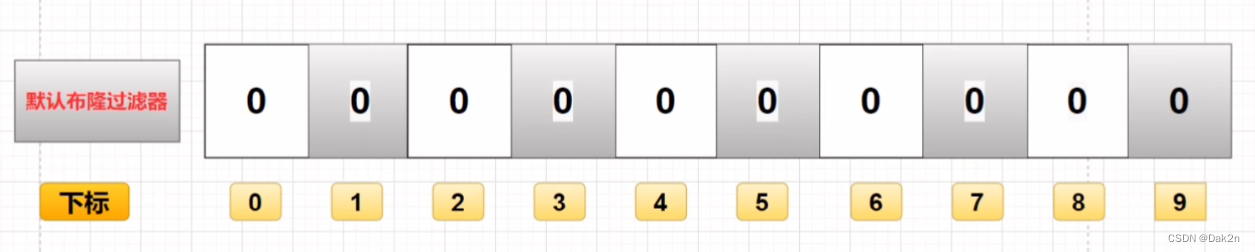
简单来说就是一个二进制数组,用0和1来判断数组中是否存在这个元素,整体流程如下:
-
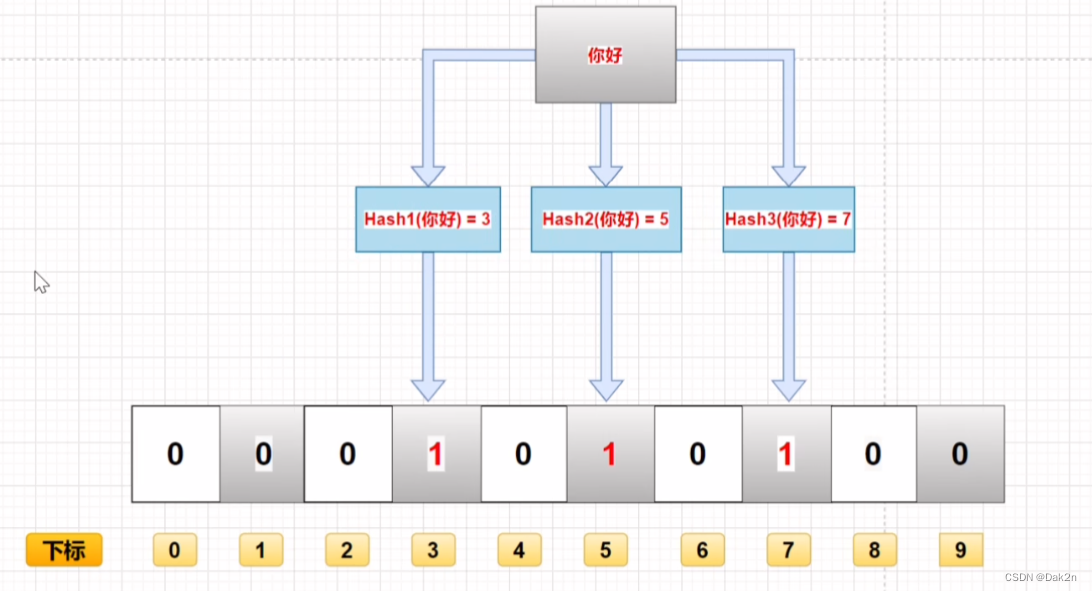
将传入的数通过n个哈希函数(不一定是三个)计算出n个哈希值。
-
然后在数组中将这n个下标(下标与哈希值相等)中的数由0转换为1。(增)
-
判断数是否存在的方法就是看数组中这n个下标中的数是否为1。(查)
缺点:
-
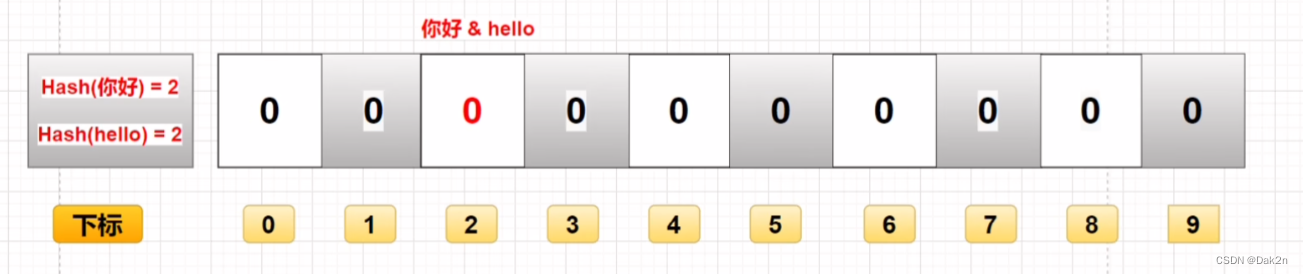
删除不便:如下图,假如数组下标为2的位置被用来储存 你好 和 hello 这两个信息,如果想对 你好 进行删除,那我也必然会将 hello 也删除掉
-
误判:如下图,id为1的数据将下标为1、3、7的数组数据改为了1,id为2的数据将下标为9、12、14的数组数据改为了1,这时候我们查询id为3的数据,通过三个哈希函数计算出的三个哈希值为3、9、12,数组中明明没有存过这个数据,但是这几个哈希值对应的下标在数组中数据为1,过滤器机会误判数组中存在这个数据。

我们可以通过谷歌的Guava工具类来减少误判
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.nio.charset.Charset;
@Configuration
public class BloomFilterConfig {
/**
* expectedInsertions:期望添加的数据个数
* fpp:期望的误判率,期望的误判率越低,布隆过滤器计算时间越长
* 原因就是fpp越小,占用的空间越大,同时使用的哈希函数越多,出现重复的可能性越小
* @return
*/
@Bean
public BloomFilter<String> goodsIDBloom(){
BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000,0.00001);
return filter;
}
@Bean
public BloomFilter<String> orderBloom(){
BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000,0.00001);
return filter;
}
}
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











