






出处/论文: DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
中文名称: DetectGPT:基于概率曲率的零样本机器生成文本检测
文章: https://arxiv.org/pdf/2301.11305
代码: https://github.com/eric-mitchell/detect-gpt
作者: Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D. Manning, Chelsea Finn
日期: 2023.01.26
本篇博客将对DetectGPT模型的源码进行拆解阅读。
DetectGPT是基于概率曲率的零样本机器生成文本检测模型。所谓零样本机器生成文本检测,即在没有任何人类撰写或机器生成样本数据用于训练检测器的情况下,利用特定LLM的内在特性,如概率曲率或表示空间等,判断给定文本是否由特定的大型语言模型生成。DetectGPT考虑机器生成文本检测的零样本方法,通过估计样本周围对数概率的局部曲率来进行检测。
首先,在上一篇博客对DetectGPT的相关论文进行阅读的基础上,简单概述DetectGPT模型的实现流程。
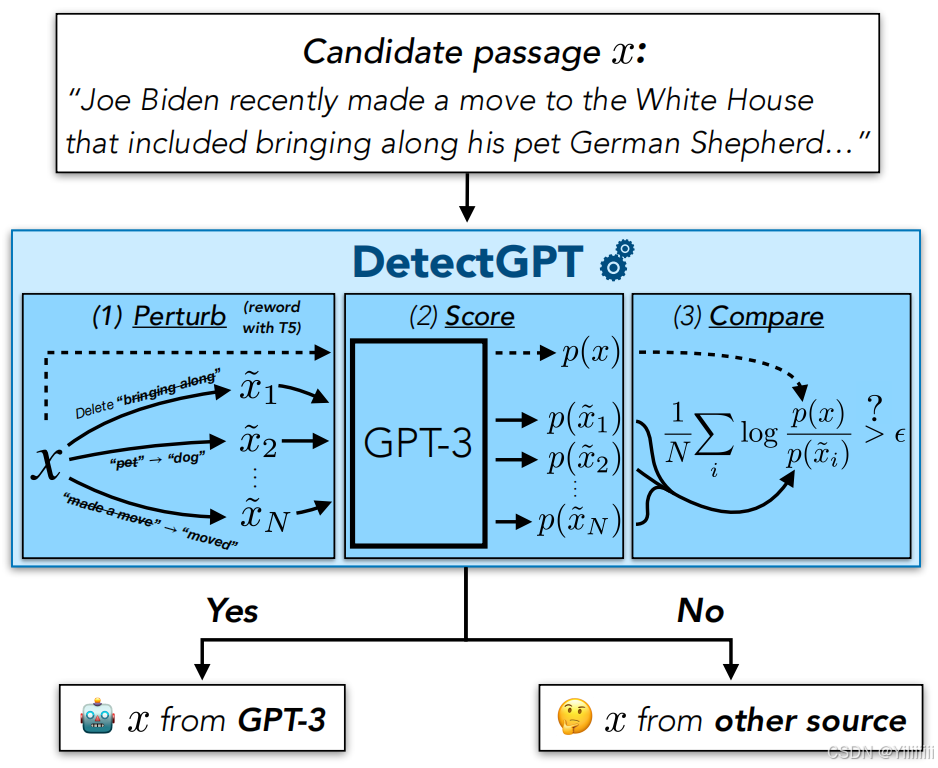
上图流程描述如下:
(1)Perturb (掩码填充模型T5)对候选文本添加多种小扰动,生成扰动后文本
(2)Score 对原始文本以及扰动后的文本进行生成概率统计,得到
(3)Compare 将原始文本的生成概率分别除以扰动后文本的生成概率,并进行对数平均。将得到的数值与设定的阈值进行比较。若大于阈值
,则将候选文本判定为机器生成文本。反之,判定为人类生成文本。
即通过在候选文本上应用小扰动,用扰动前后文本在模型下的对数概率计算扰动差异。如果扰动差异较大,则更可能是机器生成的文本。
DetectGPT模型的核心算法如下图所示:

接下来对detect-gpt模型中文件进行分析,简要分析custom_datasets.py,进一步分析run.py。
detect-gpt/custom_datasets.py
detect-gpt/custom_datasets.py提供了统一的接口,用于加载并预处理多种数据集。
| load_pubmed(cache_dir) | 加载 PubMed QA 数据集,合并问题和答案形成格式化字符串 |
| process_prompt(prompt) | 清理提示文本,去除特殊标记(如[ WP ]和[ OT ]) |
| process_spaces(story) | 清理故事文本中的多余空格、不一致的标点符号和换行符 |
| load_writing(cache_dir=None) | 加载并预处理 Writing Prompts 数据集中的提示和故事,并进行清理和预处理 |
| load_language(language, cache_dir) | 根据指定语言加载 WMT16 德英翻译数据集的英语或德语文档 |
| load_german(cache_dir) | 调用load_language函数,加载并返回 WMT16 数据集中符合条件的德语文档 |
| load_english(cache_dir) | 调用load_language函数,加载并返回 WMT16 数据集中符合条件的英语文档 |
| load(name, cache_dir, **kwargs) | 通用加载函数,根据指定的name调用相应的数据集加载函数 |
custom_datasets.py完整代码如下:
import random
import datasets
# 定义分隔符,用于分隔问题和答案或文本的不同部分
SEPARATOR = '<<<SEP>>>'
# 定义可加载的数据集名称列表
DATASETS = ['writing', 'english', 'german', 'pubmed']
# 加载PubMed数据集
def load_pubmed(cache_dir):
data = datasets.load_dataset('pubmed_qa', 'pqa_labeled', split='train', cache_dir=cache_dir)
# 将问题和长答案合并成一条数据,中间用分隔符分隔
data = [f'Question: {q} Answer:{SEPARATOR}{a}' for q, a in zip(data['question'], data['long_answer'])]
return data
# 处理文本中的特定标记
def process_prompt(prompt):
# 替换文本中的'[ WP ]'和'[ OT ]'标记为空字符串
return prompt.replace('[ WP ]', '').replace('[ OT ]', '')
# 定义一个函数,用于处理和标准化文本中的空格和标点符号
def process_spaces(story):
# 对文本进行一系列替换操作,以标准化空格和标点符号的使用
# 例如,将' ,'替换为',',将' ?'替换为'?'等
# 还处理了换行符和引号等特殊情况
return story.replace(
' ,', ',').replace(
' .', '.').replace(
' ?', '?').replace(
' !', '!').replace(
' ;', ';').replace(
' \'', '\'').replace(
' ’ ', '\'').replace(
' :', ':').replace(
'<newline>', '\n').replace(
'`` ', '"').replace(
' \'\'', '"').replace(
'\'\'', '"').replace(
'.. ', '... ').replace(
' )', ')').replace(
'( ', '(').replace(
' n\'t', 'n\'t').replace(
' i ', ' I ').replace(
' i\'', ' I\'').replace(
'\\\'', '\'').replace(
'\n ', '\n').strip()
# 定义一个函数,用于加载写作提示数据集
def load_writing(cache_dir=None):
# 定义写作提示数据集的路径
writing_path = 'data/writingPrompts'
# 读取写作提示和对应的故事
with open(f'{writing_path}/valid.wp_source', 'r') as f:
prompts = f.readlines()
with open(f'{writing_path}/valid.wp_target', 'r') as f:
stories = f.readlines()
# 处理写作提示,移除特定标记
prompts = [process_prompt(prompt) for prompt in prompts]
# 将写作提示和故事合并,并处理空格和标点符号
joined = [process_spaces(prompt + " " + story) for prompt, story in zip(prompts, stories)]
# 过滤掉包含'nsfw'或'NSFW'(不适合工作场合的内容)的故事
filtered = [story for story in joined if 'nsfw' not in story and 'NSFW' not in story]
# 打乱故事列表
random.seed(0)
random.shuffle(filtered)
return filtered
# 定义一个函数,用于加载英语或德语数据集
def load_language(language, cache_dir):
# 确保请求的语言是英语('en')或德语('de')
assert language in ['en', 'de']
# 从datasets库加载wmt16翻译数据集的训练集部分,并指定缓存目录
d = datasets.load_dataset('wmt16', 'de-en', split='train', cache_dir=cache_dir)
# 获取翻译文档列表
docs = d['translation']
# 根据请求的语言,选择相应的文档列表
desired_language_docs = [d[language] for d in docs]
# 计算每个文档的单词数
lens = [len(d.split()) for d in desired_language_docs]
# 选择单词数在100到150之间的文档
sub = [d for d, l in zip(desired_language_docs, lens) if l > 100 and l < 150]
return sub
# 定义一个函数,用于加载德语数据集
def load_german(cache_dir):
return load_language('de', cache_dir)
# 定义一个函数,用于加载英语数据集
def load_english(cache_dir):
return load_language('en', cache_dir)
# 定义一个通用加载函数,根据数据集名称调用相应的加载函数
def load(name, cache_dir, **kwargs):
# 如果请求的数据集名称在已知数据集列表中,则调用相应的加载函数
if name in DATASETS:
load_fn = globals()[f'load_{name}']
return load_fn(cache_dir=cache_dir, **kwargs)
else:
# 如果请求的数据集名称不在已知列表中,则抛出异常
raise ValueError(f'Unknown dataset {name}')detect-gpt/run.py
detect-gpt/run.py是 DetectGPT 项目中的主脚本,负责加载数据、执行文本扰动、模型推断和实验分析,最后保存结果。
| 模型加载 | |
| load_base_model() | 加载基础生成模型(如GPT-2),并将其移至设备(CPU/GPU) |
| load_mask_model() | 加载掩码填充模型(如T5),用于生成候选文本的扰动样本 |
| 数据处理 | |
| generate_samples(raw_data, batch_size) | 从原始数据集中生成候选样本(包括真实文本和生成文本),并按批次处理数据 |
| load_data_from_path(path, dataset_key) | 从指定路径加载数据集,根据dataset_key提取目标字段 |
| load_data_from_huggingface(dataset, dataset_key) | 从HuggingFace数据集库加载数据,提取指定字段 |
| 文本处理、添加扰动 | |
| tokenize_and_mask(text, span_length, pct, ceil_pct=False) | 将输入文本分词,并按指定比例随机选择单词,用掩码标记(<extra_id_*>)替换,以准备扰动样本 |
| perturb_texts(texts, span_length, pct, ceil_pct=False) | 对输入文本生成多个扰动版本,调用掩码填充模型完成掩码的填充替换,返回扰动后的文本 |
| strip_newlines(text) | 去除文本中的换行符,便于统一处理文本格式 |
| truncate_to_substring(text, start_substring, end_substring) | 截断文本,仅保留指定起始子串和结束子串之间的部分,用于预处理原始数据集 |
| 模型推断 | |
| get_ll(text) | 计算单个文本在基础生成模型上的对数似然值 |
| get_lls(texts) | 计算一组文本的对数似然值,批量调用生成模型以提高效率 |
| get_rank(text, log=False) | 计算文本中每个token在生成模型预测分布中的排名,统计平均排名作为检测指标 |
| sample_from_model(texts, min_words=55, prompt_tokens=30) | 使用基础生成模型生成样本文本,可指定最小生成单词数和前置提示长度 |
| 检测与评估 | |
| run_baseline_threshold_experiment(func, name, **kwargs) | 使用给定的函数(如get_ll)运行基线实验,评估其在生成文本检测上的性能 |
| run_perturbation_experiment(results, criterion, perturbation_mode, ...) | 运行基于扰动的实验,通过计算候选文本与其扰动版本的对数似然差值检测生成文本 |
| get_roc_metrics(real_preds, sample_preds) | 计算真实文本和生成文本的预测分数的ROC曲线指标(如AUC) |
| get_precision_recall_metrics(real_preds, sample_preds) | 计算精度-召回曲线指标(如AUC) |
| eval_supervised(data, model) | 使用指定的监督分类器(如RoBERTa)对真实文本和生成文本进行分类,评估其检测性能 |
| 结果保存与可视化 | |
| save_roc_curves(experiments) | 保存所有实验的ROC曲线图至文件,用于比较不同方法的性能 |
| save_ll_histograms(experiments) | 绘制并保存对数似然分布直方图,展示真实文本和生成文本的概率差异 |
| save_llr_histograms(experiments) | 绘制并保存对数似然比直方图,量化不同样本的概率分布差异 |
关键功能解析
文本扰动与掩码替换
对输入文本生成多个扰动版本,调用掩码填充模型完成掩码的填充替换,返回扰动后的文本
- 掩码生成:随机选择文本片段替换为 <extra_id_*>
- 掩码填充:使用 T5 模型生成填充内容
- 应用填充:将生成的内容替换回原文本
import numpy as np
def tokenize_and_mask(text, span_length, pct, ceil_pct=False):
"""
参数:
text (str): 输入的字符串文本。
span_length (int): 每个遮罩词段的长度。
pct (float): 遮罩词段占文本总词数的百分比。
ceil_pct (bool, 可选): 是否对计算出的遮罩词段数量进行向上取整。默认为False。
返回:
str: 遮罩并替换后的文本字符串。
"""
# 将文本按空格分割成单词列表
tokens = text.split(' ')
# 定义用于遮罩的字符串
mask_string = '<<<mask>>>'
# 计算需要遮罩的词段(span)数量
# args.buffer_size表示遮罩词段两侧的缓冲区大小
# n_spans的计算考虑了缓冲区,因此实际的遮罩空间会减少
n_spans = pct * len(tokens) / (span_length + args.buffer_size * 2)
# 如果ceil_pct为True,则对计算出的遮罩词段数量进行向上取整
# 这样做可以确保至少遮罩指定百分比数量的词段(可能会多遮罩一些)
if ceil_pct:
n_spans = np.ceil(n_spans)
# 将遮罩词段数量转换为整数,因为不能有部分遮罩词段
n_spans = int(n_spans)
# 记录已经遮罩的词段数量
n_masks = 0
# 循环,直到遮罩的词段数量达到n_spans
while n_masks < n_spans:
# 随机选择一个起始位置,确保遮罩词段不会超出文本范围
start = np.random.randint(0, len(tokens) - span_length)
end = start + span_length
# 计算搜索缓冲区的起始和结束位置
# 确保不会检查到文本范围之外的位置
search_start = max(0, start - args.buffer_size)
search_end = min(len(tokens), end + args.buffer_size)
# 检查所选词段及其缓冲区内是否已经存在遮罩词段
# 如果不存在,则进行遮罩
if mask_string not in tokens[search_start:search_end]:
tokens[start:end] = [mask_string] * span_length # 使用列表乘法确保替换整个词段
n_masks += 1
# 遍历遮罩后的词列表,将每个遮罩字符串替换为带有递增编号的特殊标识符
num_filled = 0 # 记录已经替换的遮罩数量
for idx, token in enumerate(tokens):
if token == mask_string:
tokens[idx] = f'<extra_id_{num_filled}>'
num_filled += 1
# 验证替换后的遮罩数量是否与预期的遮罩数量一致
assert num_filled == n_masks, f"num_filled {num_filled} != n_masks {n_masks}"
# 将词列表重新组合成字符串并返回
text = ' '.join(tokens)
return text对给定的文本进行分词,并按指定比例随机选择单词,用掩码标记(<extra_id_*>)替换,以准备扰动样本 。
import random
import torch
def perturb_texts_(texts, span_length, pct, ceil_pct=False):
"""
参数:
texts (list of str): 输入的文本列表。
span_length (int): 遮罩词段的长度。
pct (float): 遮罩词段占文本总词数的百分比。
ceil_pct (bool): 是否对计算出的遮罩词段数量进行向上取整。默认为False。
返回:
list of str: 扰动后的文本列表。
"""
# 如果不使用随机填充(即使用模型生成的填充词)
if not args.random_fills:
# 对每个文本进行分词、遮罩处理
masked_texts = [tokenize_and_mask(x, span_length, pct, ceil_pct) for x in texts]
# 将遮罩词段替换为模型生成的填充词
raw_fills = replace_masks(masked_texts) # 模型生成填充词
extracted_fills = extract_fills(raw_fills) # 从生成结果中提取填充词
# 将提取的填充词应用到遮罩后的文本上
perturbed_texts = apply_extracted_fills(masked_texts, extracted_fills)
# 处理模型未生成正确数量填充词的情况
attempts = 1 # 记录尝试次数
while '' in perturbed_texts:
# 找到未成功填充的文本索引
idxs = [idx for idx, x in enumerate(perturbed_texts) if x == '']
print(f'WARNING: {len(idxs)} texts have no fills. Trying again [attempt {attempts}].')
# 仅对未成功填充的文本重新进行遮罩处理
masked_texts_retry = [tokenize_and_mask(texts[idx], span_length, pct, ceil_pct) for idx in idxs]
# 重新生成填充词并应用
raw_fills_retry = replace_masks(masked_texts_retry)
extracted_fills_retry = extract_fills(raw_fills_retry)
new_perturbed_texts = apply_extracted_fills(masked_texts_retry, extracted_fills_retry)
# 更新未成功填充的文本
for idx, x in zip(idxs, new_perturbed_texts):
perturbed_texts[idx] = x
attempts += 1
# 如果使用随机填充
else:
if args.random_fills_tokens:
# 使用分词器对文本进行分词,并转换为张量(假设base_tokenizer和DEVICE已定义)
tokens = base_tokenizer(texts, return_tensors="pt", padding=True).to(DEVICE)
# 获取有效的词汇索引(非填充词汇)
valid_tokens = tokens.input_ids != base_tokenizer.pad_token_id
# 计算随机替换的词汇百分比(考虑了缓冲区大小)
replace_pct = args.pct_words_masked * (args.span_length / (args.span_length + 2 * args.buffer_size))
# 创建一个随机掩码,用于标记需要替换的词汇
random_mask = torch.rand(tokens.input_ids.shape, device=DEVICE) < replace_pct
random_mask &= valid_tokens # 确保不会替换填充词汇
# 生成随机词汇索引,并替换原词汇
random_tokens = torch.randint(0, base_tokenizer.vocab_size, (random_mask.sum(),), device=DEVICE)
# 确保随机词汇不是特殊词汇(假设base_tokenizer.all_special_tokens包含所有特殊词汇)
while any(base_tokenizer.decode(x) in base_tokenizer.all_special_tokens for x in random_tokens):
random_tokens = torch.randint(0, base_tokenizer.vocab_size, (random_mask.sum(),), device=DEVICE)
tokens.input_ids[random_mask] = random_tokens # 替换词汇
# 解码并返回扰动后的文本
perturbed_texts = base_tokenizer.batch_decode(tokens.input_ids, skip_special_tokens=True)
else:
# 对每个文本进行分词、遮罩处理
masked_texts = [tokenize_and_mask(x, span_length, pct, ceil_pct) for x in texts]
# 直接将遮罩词段替换为FILL_DICTIONARY中的随机词汇
perturbed_texts = masked_texts.copy() # 复制遮罩后的文本列表,避免修改原始列表
for idx, text in enumerate(perturbed_texts):
filled_text = text
# 对每个遮罩词段进行替换
for fill_idx in range(count_masks([text])[0]): # 假设count_masks函数返回遮罩词段数量
fill = random.sample(FILL_DICTIONARY, span_length) # 从FILL_DICTIONARY中随机选择词汇
filled_text = filled_text.replace(f"<extra_id_{fill_idx}>", " ".join(fill)) # 替换遮罩词段
assert count_masks([filled_text])[0] == 0, "Failed to replace all masks" # 确保所有遮罩词段都已替换
perturbed_texts[idx] = filled_text # 更新扰动后的文本
return perturbed_texts # 返回扰动后的文本列表对输入文本生成多个扰动版本,调用掩码填充模型完成掩码的填充替换,返回扰动后的文本
import tqdm # 引入tqdm库用于显示进度条
def perturb_texts(texts, span_length, pct, ceil_pct=False):
"""
参数:
texts (list of str): 待扰动的文本集合。
span_length (int): 扰动时替换或生成的文本片段的长度。
pct (float): 扰动比例,即文本中多少比例的内容会被替换或修改。
ceil_pct (bool, optional): 是否对扰动比例进行向上取整处理。默认为False。
返回:
list of str: 扰动后的文本集合。
"""
# 从全局配置对象args中获取每次处理的文本块大小
chunk_size = args.chunk_size
# 如果用于填充掩码的模型名称中包含'11b',则将块大小减半
if '11b' in mask_filling_model_name:
chunk_size //= 2
# 初始化一个空列表,用于存储扰动后的文本
outputs = []
# 使用tqdm库显示进度条,按块处理文本集合
# range(0, len(texts), chunk_size)生成一个迭代器,每次迭代返回一块文本
for i in tqdm.tqdm(range(0, len(texts), chunk_size), desc="Applying perturbations"):
# 对当前块中的文本进行扰动处理,并将结果扩展到outputs列表中
# 这里调用了perturb_texts_函数,它应该返回扰动后的文本列表
outputs.extend(perturb_texts_(texts[i:i + chunk_size], span_length, pct, ceil_pct=ceil_pct))
# 返回所有扰动后的文本
return outputs 封装函数,负责将文本数据分块并调用 perturb_texts_ 来处理,同时提供进度反馈
模型推断的核心代码部分
计算原始文本和扰动文本的对数概率,并使用这些对数概率的差异进行评估。
1. 对数概率计算
# 获取给定文本在基础模型下的对数似然
def get_ll(text):
# 检查是否使用OpenAI模型
if args.openai_model:
# 设置OpenAI API的调用参数
kwargs = {
"engine": args.openai_model, # OpenAI模型的名称或ID
"temperature": 0, # 采样温度,0表示贪心选择
"max_tokens": 0, # 最大生成token数,这里可能需要根据实际情况调整
"echo": True, # 是否回显输入的prompt
"logprobs": True # 是否返回每个token的对数概率
}
# 调用OpenAI的Completion.create方法生成文本
# 注意:这里使用了<|endoftext|>作为前缀,这通常是GPT模型的一个特殊标记,用于指示文本结束
r = openai.Completion.create(prompt=f"<|endoftext|>{text}", **kwargs)
# 从返回结果中提取第一个选择(因为temperature为0,所以只有一个选择)
result = r['choices'][0]
# 提取tokens和对应的对数概率
# 注意:这里忽略了第一个token(通常是<|endoftext|>),因为它不是原始文本的一部分
tokens, logprobs = result["logprobs"]["tokens"][1:], result["logprobs"]["token_logprobs"][1:]
# 断言tokens和logprobs的长度相同,以确保数据一致性
assert len(tokens) == len(logprobs), f"Expected {len(tokens)} logprobs, got {len(logprobs)}"
# 计算并返回对数概率的平均值
return np.mean(logprobs)
else:
# 如果不使用OpenAI模型,则使用本地的PyTorch模型
# 禁用梯度计算,以加快推理速度
with torch.no_grad():
# 对文本进行分词,并转换为PyTorch张量
tokenized = base_tokenizer(text, return_tensors="pt").to(DEVICE)
# 获取分词后的输入ID作为标签(在训练时用于计算损失)
labels = tokenized.input_ids
# 将分词后的输入传递给模型,并计算损失
loss = -base_model(**tokenized, labels=labels).loss.item()
# 返回损失值(即负对数似然的平均值)
return loss计算单个文本在基础生成模型上的对数似然值
def get_lls(texts):
# 检查是否使用OpenAI模型
if not args.openai_model:
# 如果不使用OpenAI模型,则直接对每个文本调用get_ll函数,并返回结果列表
return [get_ll(text) for text in texts]
else:
# 如果使用OpenAI模型,则首先计算所有文本的总token数
total_tokens = sum(len(GPT2_TOKENIZER.encode(text)) for text in texts)
# 更新全局变量API_TOKEN_COUNTER,以跟踪API token的使用量
API_TOKEN_COUNTER += total_tokens * 2
# 创建一个线程池,线程池的大小由args.batch_size指定
pool = ThreadPool(args.batch_size)
# 使用线程池的map方法并行地对每个文本调用get_ll函数
# 并返回结果列表,这里的结果顺序与输入文本的顺序一致,因为map方法保持了输入的顺序
return pool.map(get_ll, texts)计算一组文本的对数似然值,批量调用生成模型以提高效率
for res in tqdm.tqdm(results, desc="Computing log likelihoods"):
# 计算扰动样本(分别为样本文本和原始文本的扰动版本)的对数概率
p_sampled_ll = get_lls(res["perturbed_sampled"])
p_original_ll = get_lls(res["perturbed_original"])
# 计算原始文本和样本文本的对数概率
res["original_ll"] = get_ll(res["original"])
res["sampled_ll"] = get_ll(res["sampled"])
# 存储扰动文本的对数概率存储
res["all_perturbed_sampled_ll"] = p_sampled_ll
res["all_perturbed_original_ll"] = p_original_ll
# 计算并存储扰动文本的对数概率的均值
res["perturbed_sampled_ll"] = np.mean(p_sampled_ll)
res["perturbed_original_ll"] = np.mean(p_original_ll)
# 计算并存储扰动文本对数概率的标准差
res["perturbed_sampled_ll_std"] = np.std(p_sampled_ll) if len(p_sampled_ll) > 1 else 1
res["perturbed_original_ll_std"] = np.std(p_original_ll) if len(p_original_ll) > 1 else 1
样本文本指通过生成模型基于提示或条件生成的文本。样本文本用于模拟生成模型的输出,是生成文本检测的核心目标。
原始文本指真实数据集中的人工创作文本。它是对照组,用于与样本文本进行对比。
2. (标准化)对数概率差异
predictions = {'real': [], 'samples': []}
for res in results:
if criterion == 'd':
# 计算原始文本和扰动文本的对数概率差
predictions['real'].append(res['original_ll'] - res['perturbed_original_ll'])
predictions['samples'].append(res['sampled_ll'] - res['perturbed_sampled_ll'])
elif criterion == 'z':
# 标准化对数概率差异(通过除以标准差)
predictions['real'].append((res['original_ll'] - res['perturbed_original_ll']) / res['perturbed_original_ll_std'])
predictions['samples'].append((res['sampled_ll'] - res['perturbed_sampled_ll']) / res['perturbed_sampled_ll_std'])
criterion == 'd'
在 d 模式 下,直接计算原始文本和扰动文本之间的对数概率差:
res['original_ll'] - res['perturbed_original_ll']
res['sampled_ll'] - res['perturbed_sampled_ll']
原始文本的对数概率减去扰动文本的对数概率,值越大,说明扰动的文本越可能是生成的。
criterion == 'z'
在 z 模式 下,对对数概率差进行标准化,即用扰动文本的对数概率标准差除以差值:
(res['original_ll'] - res['perturbed_original_ll']) / res['perturbed_original_ll_std']
(res['sampled_ll'] - res['perturbed_sampled_ll']) / res['perturbed_sampled_ll_std']
标准化后的值,可以消除扰动文本对数概率差异的幅度影响,使得模型在不同数据集上更加鲁棒。
3. 分类性能评估
运行基于扰动的实验,通过计算候选文本与其扰动版本的对数似然差值检测生成文本
def run_perturbation_experiment(results, criterion, span_length=10, n_perturbations=1, n_samples=500):
# compute diffs with perturbed
predictions = {'real': [], 'samples': []}
for res in results:
if criterion == 'd':
predictions['real'].append(res['original_ll'] - res['perturbed_original_ll'])
predictions['samples'].append(res['sampled_ll'] - res['perturbed_sampled_ll'])
elif criterion == 'z':
if res['perturbed_original_ll_std'] == 0:
res['perturbed_original_ll_std'] = 1
print("WARNING: std of perturbed original is 0, setting to 1")
print(f"Number of unique perturbed original texts: {len(set(res['perturbed_original']))}")
print(f"Original text: {res['original']}")
if res['perturbed_sampled_ll_std'] == 0:
res['perturbed_sampled_ll_std'] = 1
print("WARNING: std of perturbed sampled is 0, setting to 1")
print(f"Number of unique perturbed sampled texts: {len(set(res['perturbed_sampled']))}")
print(f"Sampled text: {res['sampled']}")
predictions['real'].append((res['original_ll'] - res['perturbed_original_ll']) / res['perturbed_original_ll_std'])
predictions['samples'].append((res['sampled_ll'] - res['perturbed_sampled_ll']) / res['perturbed_sampled_ll_std'])
fpr, tpr, roc_auc = get_roc_metrics(predictions['real'], predictions['samples'])
p, r, pr_auc = get_precision_recall_metrics(predictions['real'], predictions['samples'])
name = f'perturbation_{n_perturbations}_{criterion}'
print(f"{name} ROC AUC: {roc_auc}, PR AUC: {pr_auc}")
return {
'name': name,
'predictions': predictions,
'info': {
'pct_words_masked': args.pct_words_masked,
'span_length': span_length,
'n_perturbations': n_perturbations,
'n_samples': n_samples,
},
'raw_results': results,
'metrics': {
'roc_auc': roc_auc,
'fpr': fpr,
'tpr': tpr,
},
'pr_metrics': {
'pr_auc': pr_auc,
'precision': p,
'recall': r,
},
'loss': 1 - pr_auc,
}
使用给定的函数(如get_ll)运行基线实验,评估其在生成文本检测上的性能
def run_baseline_threshold_experiment(criterion_fn, name, n_samples=500):
torch.manual_seed(0)
np.random.seed(0)
results = []
for batch in tqdm.tqdm(range(n_samples // batch_size), desc=f"Computing {name} criterion"):
original_text = data["original"][batch * batch_size:(batch + 1) * batch_size]
sampled_text = data["sampled"][batch * batch_size:(batch + 1) * batch_size]
for idx in range(len(original_text)):
results.append({
"original": original_text[idx],
"original_crit": criterion_fn(original_text[idx]),
"sampled": sampled_text[idx],
"sampled_crit": criterion_fn(sampled_text[idx]),
})
# compute prediction scores for real/sampled passages
predictions = {
'real': [x["original_crit"] for x in results],
'samples': [x["sampled_crit"] for x in results],
}
fpr, tpr, roc_auc = get_roc_metrics(predictions['real'], predictions['samples'])
p, r, pr_auc = get_precision_recall_metrics(predictions['real'], predictions['samples'])
print(f"{name}_threshold ROC AUC: {roc_auc}, PR AUC: {pr_auc}")
return {
'name': f'{name}_threshold',
'predictions': predictions,
'info': {
'n_samples': n_samples,
},
'raw_results': results,
'metrics': {
'roc_auc': roc_auc,
'fpr': fpr,
'tpr': tpr,
},
'pr_metrics': {
'pr_auc': pr_auc,
'precision': p,
'recall': r,
},
'loss': 1 - pr_auc,
}通过分类分数计算分类器的性能,涉及阈值选择和性能指标计算。
fpr, tpr, roc_auc = get_roc_metrics(predictions['real'], predictions['samples'])
p, r, pr_auc = get_precision_recall_metrics(predictions['real'], predictions['samples'])
def get_roc_metrics(real_preds, sample_preds):
fpr, tpr, _ = roc_curve([0] * len(real_preds) + [1] * len(sample_preds), real_preds + sample_preds)
roc_auc = auc(fpr, tpr)
return fpr.tolist(), tpr.tolist(), float(roc_auc)
def get_precision_recall_metrics(real_preds, sample_preds):
precision, recall, _ = precision_recall_curve([0] * len(real_preds) + [1] * len(sample_preds), real_preds + sample_preds)
pr_auc = auc(recall, precision)
return precision.tolist(), recall.tolist(), float(pr_auc)get_roc_metrics 和 get_precision_recall_metrics 函数用于计算 ROC 曲线 和 PR 曲线,使用了计算出的对数概率差异或标准化对数概率差异来评估模型性能。
补充完善中...


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









