




一、requests安装
获取URL、HTTP的长连接和连接缓存和会话、浏览器式的SSL验证、身份认证、Cookie会话、文件分块上传、流下载、HTTP(S)d代理功能、连接超时处理…
由于requests库不是Python内置的标准库,所有需要自行安装
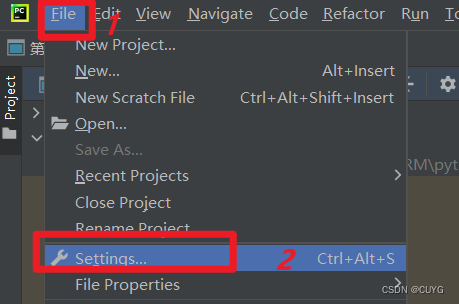
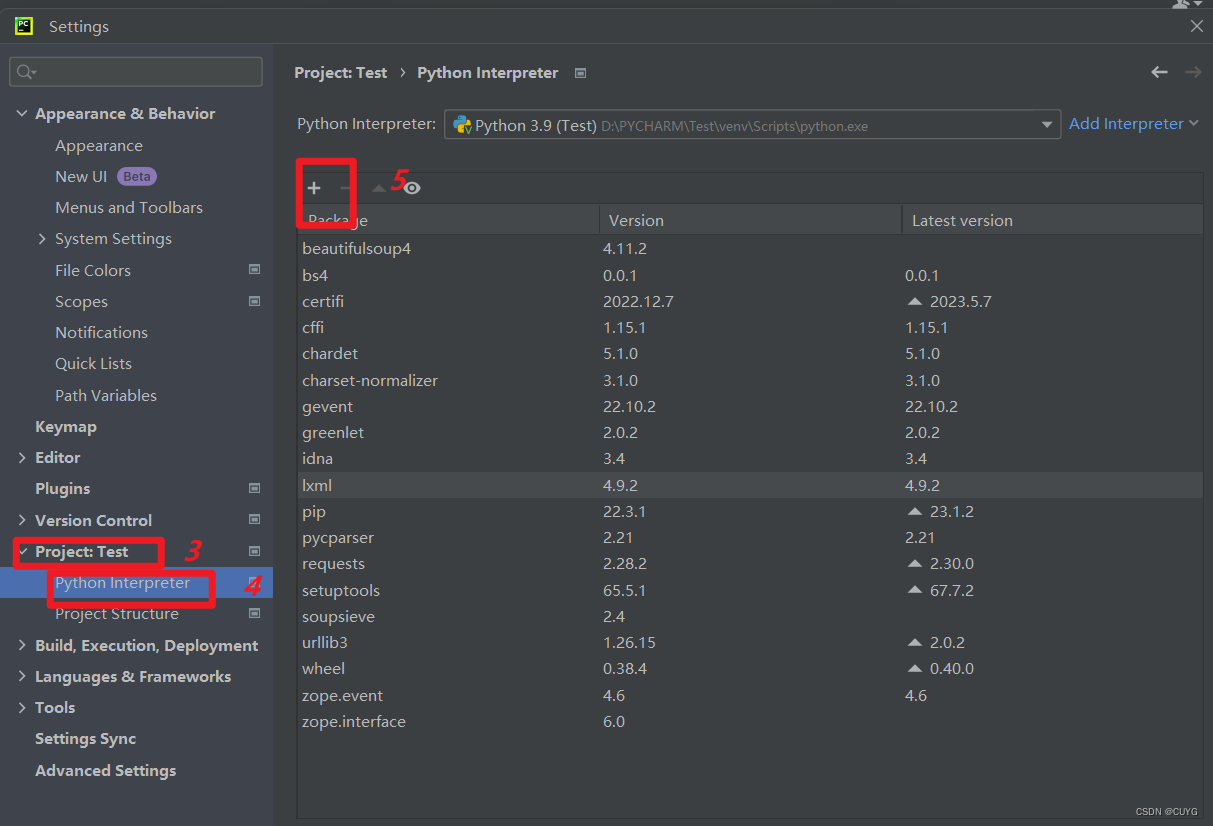
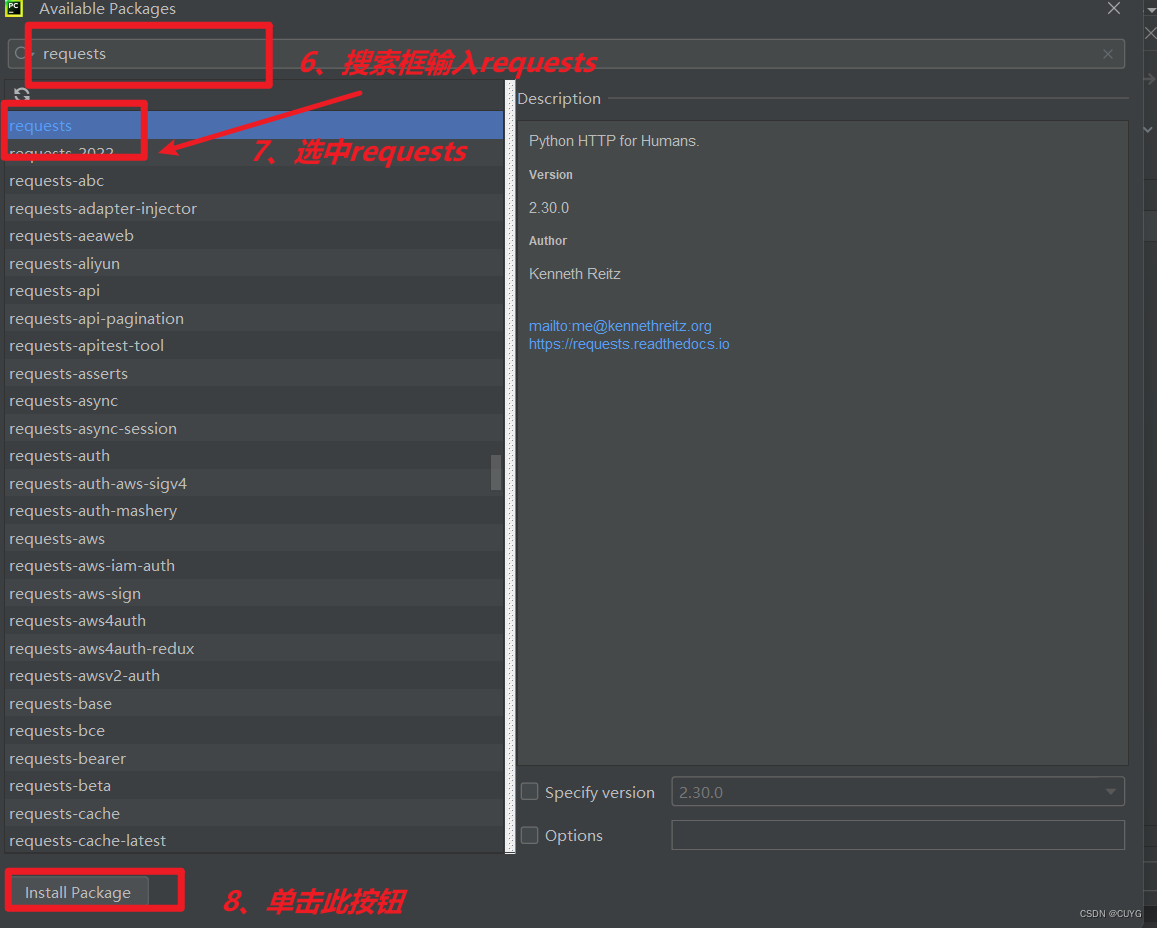
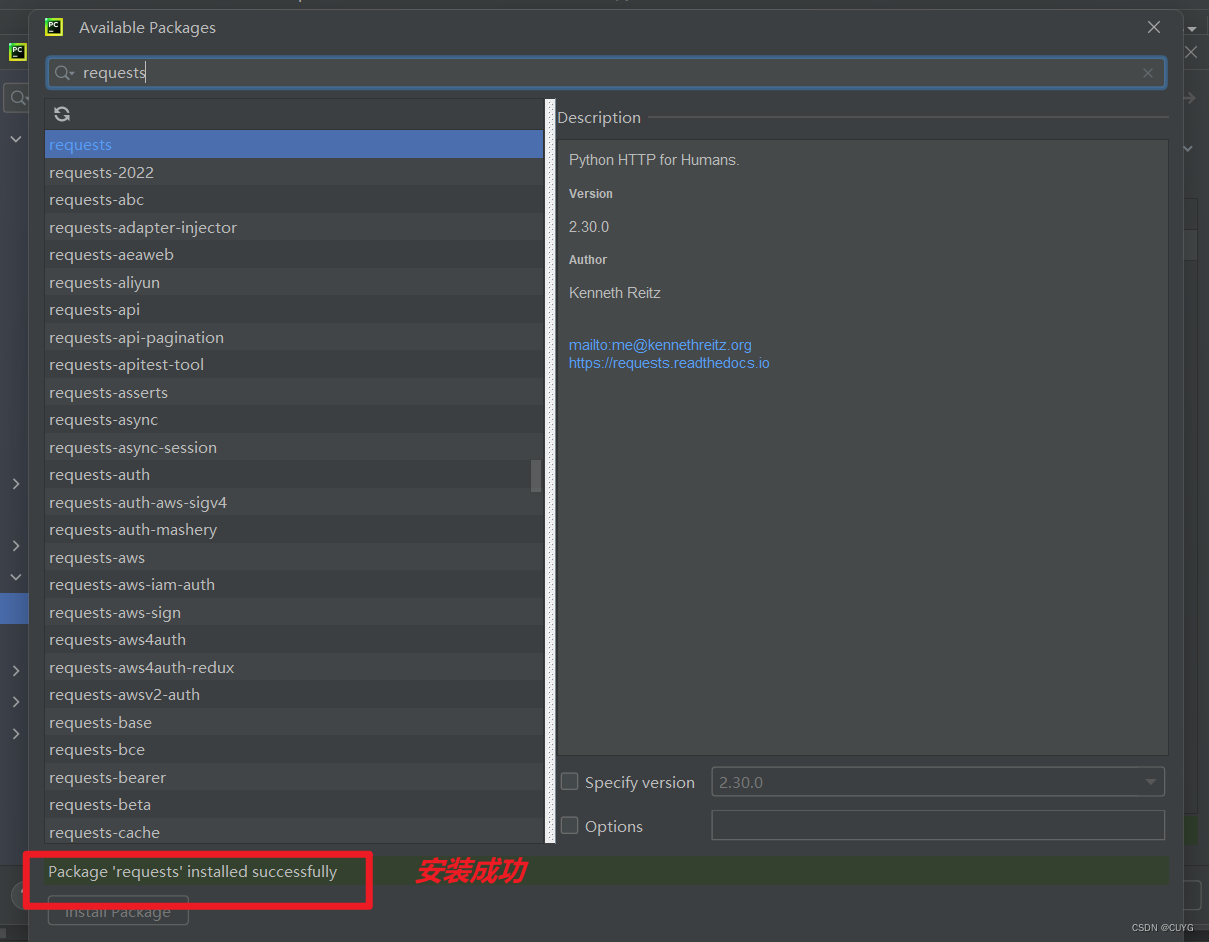
最后关闭弹窗,点击OK按钮
二、请求方法
1、GET方法
格式:
requests.get(url,params=None,**Kwargs)
解释:
(1)url:请求的URL(网站地址)。
(2)params:字典或字节序列,作为参数增加到url中。
(3)**kwargs:控制访问的参数(headers、cookies、timeout、proxies…)
调用requests.get()/requests.post()函数后,返回一个Response类型对的对象。以下是Response类型的对象提供的属性和方法:
status_code:响应状态码;
headers:响应头;
request.headers:请求头;
url:请求的url;
encoding:从HTTP headers中猜测的响应内容编码方式;
apparent_encoding:从响应内容分析编码方式;
content:获取二进制类型的响应内容,会自动解码gzip和deflate编码的响应内容;
text:获取文本类型的响应内容;
json():返回JSON类型数据;
raise_for_status():如果是status_code不是200,则会抛出异常。
#导入requests库
import requests
url = "https://www.baidu.com/"
r = requests.get(url,params=None)
print("响应状态码",r.status_code)
print("响应头",r.headers)
print("请求头",r.request.headers)
print("请求url",r.url)
print("响应内容编码方式",r.encoding)
print("编码方式",r.apparent_encoding)
print("二进制的响应内容",r.content)
print("文本类型响应内容",r.text)
print("抛出异常",r.raise_for_status())
运行结果
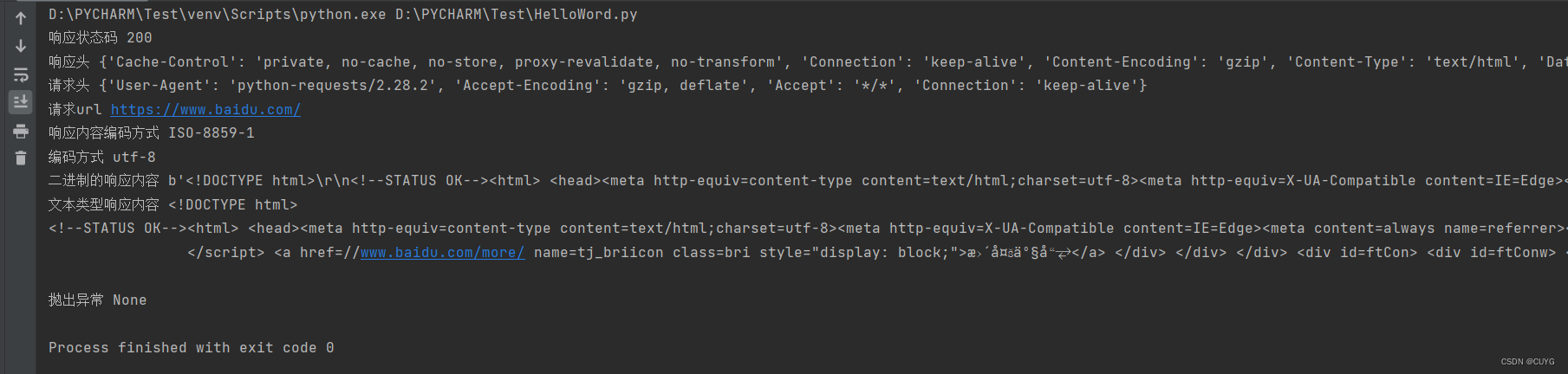
获取的文本类型响应内容为乱码,可以在此语句添加以下语句,解决乱码问题:
r.encoding = r.apparent_encoding
运行结果
2、POST方法
格式:
post(url,data=None,json=None,**kwargs)
解释:
(1)url:请求的URL(网站地址)。
(2)data:字典、字节序列或文件对象,作为请求体的内容。
(3)**kwargs:控制访问的参数(headers、cookies、timeout、proxies…)。
3、定制请求头
在request库中,get()或post()函数可以直接传递字典形式的User_Agent信息给headers参数实现定制请求头。
4、设置Cookie
Cookie可以帮助用户记录访问web页面时的个人信息,并保存在客户端,当用户再次访问同一Web页面时,Cookie来维持登录状态。
5、设置超时
在爬取网页的过程中,有时服务器没有响应,程序可能会一直等待响应,request库可以在get()或post()函数中设置timeout参数来解决这个问题。程序在等待设置的秒数后会停止等待,抛出Timeout异常。
使用requets库发出HTTP请求可能会发生异常,如错误异常(request.HTTPError)、URL缺失异常(request.URLRequired)和请求URL超时异常(request.Timeout)等。Respose类型的对象提供raise_for_status()方法来捕获访问网页后的HTTP响应状态码不是200时的requests.HTTPError。
6、获取二进制文件
图片、音频、视频等文件的本质上是由二进制码组成,有特定的保存格式和对应的解码方式,想爬取这些文件,需要获取他们的二进制数据。


















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









