







一、requests小技巧
1、把cookie对象转化为字典
方法:requests.utils.dict_from_cookiejar
import requests
response = requests.get('https://www.baidu.com')
requests.utils.dict_from_cookiejar(response.cookies)
2、请求SSL证书验证
response = requests.get('https://www.12306.cn/index/',verify=False)
3、设置超时
response = requests.get(url,timeout=10)
4、配合状态码判断是否请求成功
assert response.status_code == 200
5、URL地址的编解码
requests.utils.unquote() 解码
requests.utils.quote() 编码
6、retrying
import requests
from retrying import retry
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) Appl
@retry(stop_max_attempt_number = 3)
def _parse_url(url):
print('代码执⾏了⼏次?')
response = requests.get(url,headers=headers,timeout=3)
assert response.status_code == 200
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except:
html_str = None
return html_str
if __name__ == '__main__':
url = 'http://www.baidu.com'
print(parse_url(url))
二、爬⾍数据json
1、数据提取
什么是数据提取?
简单的来说,数据提取就是从响应中获取我们想要的数据的过程。
2、数据分类
(1)⾮结构化数据:HTML
处理⽅法:正则表达式、xpath
(2)结构化数据:json、xml
处理⽅法:转化为Python数据类型
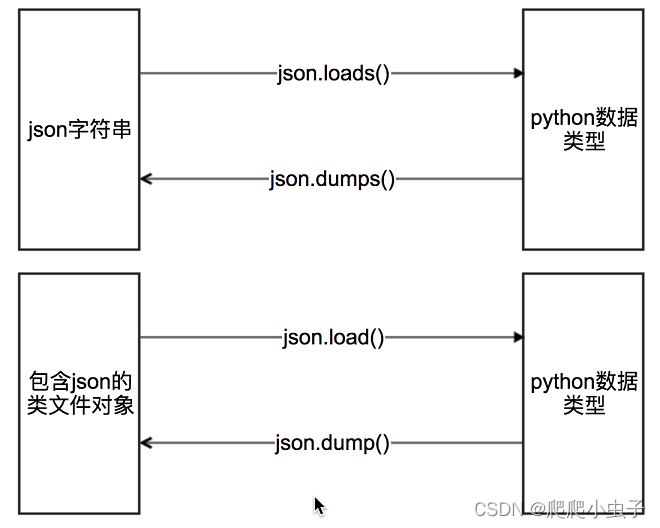
3、数据提取之json
由于把json数据转化为python内建数据类型很简单,所以爬⾍中,如果我们能够找到返回json数据的URL,就会尽量使⽤这种URL。
JSON是⼀种轻量级的数据交换格式,它使得⼈们很容易的进⾏阅读和编写。同时也⽅便了机器进⾏解析和⽣成。适⽤于进⾏数据交互的场景,⽐如⽹站前台与后台之间的数据交互。
4、使⽤json注意点
- json中的字符串都是双引号
5、爬取王者荣耀英雄信息案例
from urllib.request import urlretrieve
import requests
import os
# 英雄列表URL地址
heros_url = "http://gamehelper.gm825.com/wzry/hero/list"
# 下载王者荣耀英雄图⽚
def hero_imgs_download(url,header):
# 获取⽂本.text 获取图⽚ .content
req = requests.get(url = url,headers = header).json()
# 字典格式
# print((req))
hero_num = len(req['list'])
print("⼀共有%d个英雄"%hero_num)
hero_images_path = 'hero_images'
if not os.path.exists(hero_images_path):
os.mkdir(hero_images_path)
hero_list = req['list']
for each_hero in hero_list:
# print(each_hero)
hero_photo_url = each_hero['cover']
hero_name = each_hero['name'] + '.jpg'
filename = hero_images_path + '/' + hero_name
print("正在下载 %s的图⽚"%each_hero['name'])
# if hero_images_path not in os.listdir():
# os.makedirs(hero_images_path)
# 下载图⽚
urlretrieve(url = hero_photo_url,filename = filename)
hero_imgs_download(heros_url,headers)















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









