







OpenMP Programming Model
目录
2、Combined Parallel Worksharing Constructs
3、Combined Parallel Section Constructs
4、Synchronization Constructs(barrier)
5、Synchronization Constructs(Critical)
6、Synchronization Constructs(Atomic)
1、Parallel Construct
#include <iostream>
#include <omp.h>
int main() {
int id, numb;
omp_set_num_threads(3);
#pragma omp parallel private(id, numb)
{
id = omp_get_thread_num();
numb = omp_get_num_threads();
printf("I am thread % d out of % d \n", id, numb);
}
return 0;
}Parallel Construct执行代码
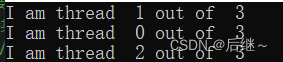
图1-1 运行结果

图1-2 华为TaiShan200服务器运行结果
分析:这是并行编程中的并行结构,在指令 #pragma omp parallel 中执行。三个线程都要执行该指令中的内容,只是因为抢执行位置的先后顺序,0,1,2出现的顺序不一样!
2、Combined Parallel Worksharing Constructs
#include <omp.h>
int main() {
omp_set_num_threads(3);
#pragma omp parallel for
for (int i = 0; i < 10; ++i) {
printf(" No. %d iteration by thread %d\n", i, omp_get_thread_num());
}
return 0;
}Combined Parallel Worksharing Constructs执行代码
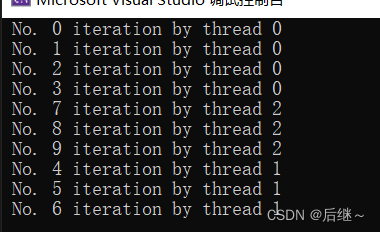
图2-1 运行结果
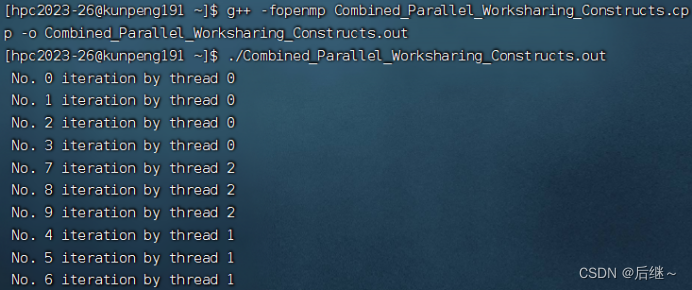 图2-2 华为TaiShan200服务器运行结果
图2-2 华为TaiShan200服务器运行结果
分析:在 #pragma omp parallel for 这个指令中,专门执行一个for循环,这个for循环的每一次迭代由能够进行处理的线程抢到并执行,直到整个for循环执行完。这和 #pragma omp parallel 指令不一样,#pragma omp parallel指令是让所有可用线程都将这个指令中的内容执行一遍(除了在 #pragma omp parallel 指令中嵌套其他指令,如for指令。嵌套指令中的内容按照嵌套指令的要求来执行)要注意两者的区别!!!
3、Combined Parallel Section Constructs
#include <iostream>
#include <omp.h>
int main() {
int id, numb;
omp_set_num_threads(2);
#pragma omp parallel sections //线程选择
{
#pragma omp section //选择之后就会由这个线程全部做完
for (int i = 0; i < 5; i++) {
printf("section i : iteration %d by thread no.%d\n", i, omp_get_thread_num());
}
#pragma omp section
for (int j = 0; j < 5; j++) {
printf("section j : iteration %d by thread no.%d\n", j, omp_get_thread_num());
}
#pragma omp section
for (int k = 0; k < 5; k++) {
printf("section k : iteration %d by thread no.%d\n", k, omp_get_thread_num());
}
}
}Combined Parallel Section Constructs执行代码
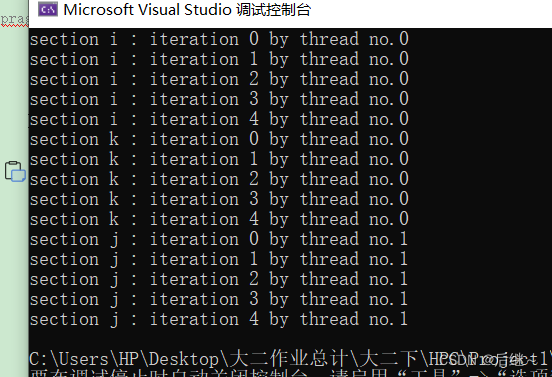
图3-1 运行结果
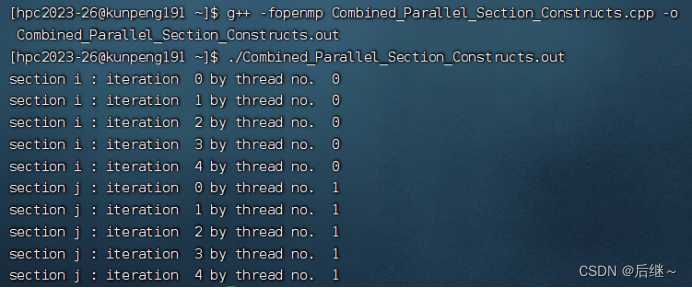
图3-2 华为TaiShan200服务器运行结果
分析:#pragma omp parallel sections指令中,提供给所有线程n个 #pragma omp section 指令,即所有线程有n个选择,线程选到该指令之后,由该线程执行指令中所有的内容!其余线程不参与其中的数据竞争。
4、Synchronization Constructs(barrier)
#include <iostream>
#include <omp.h>
int main() {
int id, numb;
omp_set_num_threads(3);
#pragma omp parallel
{
for (int i = 0; i < 10; ++i) {
printf("loop i : iteration % d by thread no. % d\n", i, omp_get_thread_num());
} //三个线程都要执行这个循环,谁先做完这个循环不一定,但是都会在barrier等待其他线程的同步
#pragma omp barrier //线程同步
for (int j = 0; j < 10; ++j) {
printf("loop j : iteration % d by thread no. % d\n", j, omp_get_thread_num());
}
}
}Synchronization Constructs(barrier)执行代码
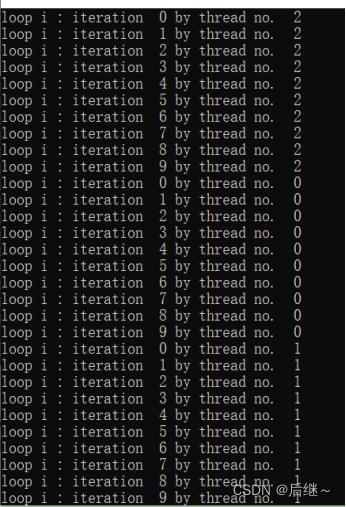
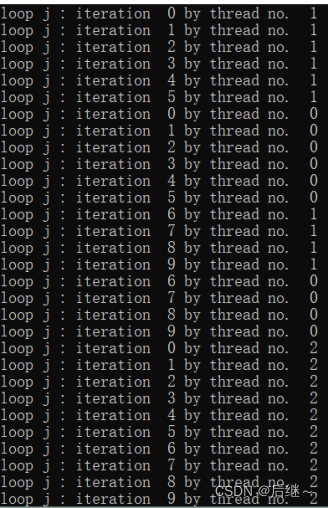
图4-1 运行结果
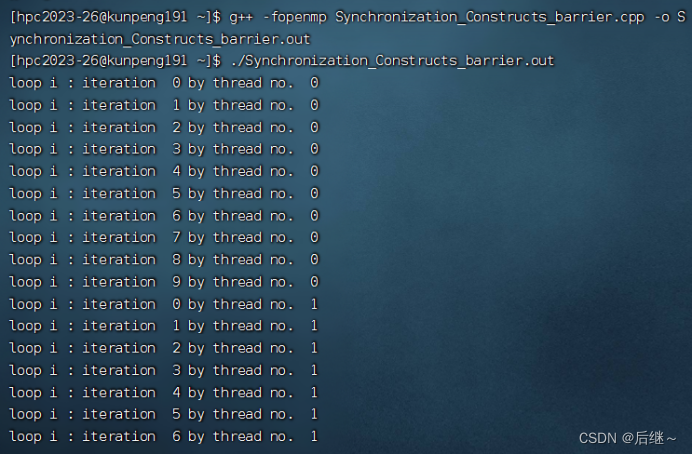
图4-2 华为TaiShan200服务器运行结果(展示部分结果……)
分析:在#pragma omp parallel指令中,所有线程都会执行其中的内容,但是因为数据竞争,所以不同线程执行时间不同。#pragma omp barrier的作用即让不同线程到这个地方停下来等待,直到所有线程统一进度。
5、Synchronization Constructs(Critical)
#include <iostream>
#include <omp.h>
int main() {
int id, numb;
omp_set_num_threads(3);
int x = 0;
#pragma omp parallel shared(x)
{
#pragma omp critical
x += 1;
}
printf("x = %d\n", x);
}Synchronization Constructs(Critical)执行代码
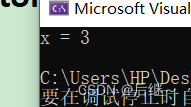
图5-1 运行结果

图5-2 华为TaiShan200服务器运行结果
分析:x为共享变量,citical作为相当于操作系统一个锁的结构,每次只让一个线程执行critical中的代码,不允许多个线程同时执行,以防共享变量x出错
6、Synchronization Constructs(Atomic)
#include <iostream>
#include <omp.h>
int main() {
int id, numb;
omp_set_num_threads(3);
int x = 0;
#pragma omp parallel shared(x)
{
#pragma omp atomic
x++;
}
printf("x = %d\n", x);
}Synchronization Constructs(Atomic)执行代码
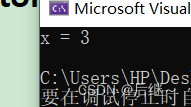
图6-1 运行结果

图6-2 华为TaiShan200服务器运行结果
分析:x为共享变量,atomic作为相当于操作系统一个锁的结构,每次只让一个线程执行atomic中的代码,不允许多个线程同时执行,以防共享变量x出错
7、Reduction clause
#include <iostream>
#include <omp.h>
static long num_steps = 100000; //让步长足够长
double step;
//求π,f(x) = 4 / (1 + x2) π = f(x)从 0 到 1 的积分
int main() {
int i;
double x, pi, sum = 0;
step = 1 / (double)num_steps; //每一步的距离
omp_set_num_threads(2);
#pragma omp parallel for reduction(+:sum) private(x)
for (i = 1; i <= num_steps; i++) {
x = (i - 0.5) * step; //矩形正中间
sum += 4.0 / (1.0 + x * x); //等效于积分
}
pi = step * sum;
printf("pi = %.12lf\n", pi);
return 0;
}Reduction clause 执行代码
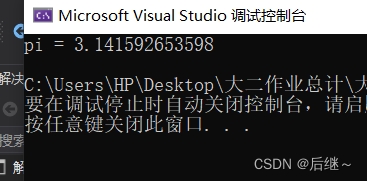
图7-1 运行结果
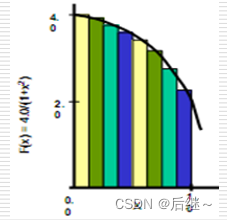
图7-2 pi函数

图7-3 华为TaiShan200服务器运行结果
分析:求pi,因为计算机的高性能计算能力,可以将微小的矩形拼接在一起,将f(x) = 4.0 / (1.0 + x * x)计算出来。















 2358
2358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









