







写在前面
上一节讲了TreeSet、TreeMap的关系,具体可以看博客TreeSet与TreeMap那些关系,这一节讲解的HashMap,HashSet其底层都是用哈希表实现的Map,Set。接下来将介绍,他们之间的一些区别。
解释说明:
哈希表也称散列表,是为了提高搜索效率,不经过任何比较,一次直接从表中得到要搜索的元素(理想情况)。哈希表是通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系。
结构如图:以一下哈希函数的存储方式。
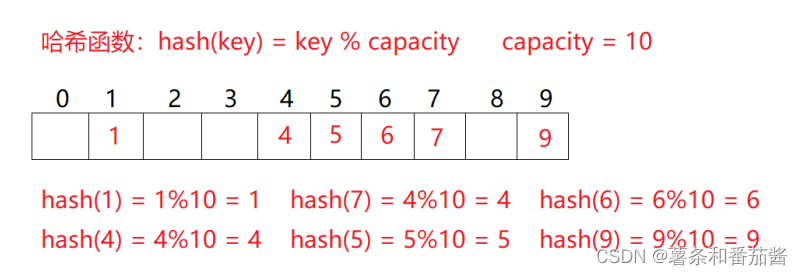
这种情况下,会出现 哈希冲突,为了减少冲突,数组的每一项对应了一个链表,同时如果链表元素个数,数组元素个数到达一定条件,会演变为红黑树,HashMap底层是如此实现的。具体关于哈希冲突以及解决办法,不做说明。
1. 二者区别
与上一节TreeSet底层用Map实现相同,HashSet底层也是用HashMap实现,其自己实现的方法主要有:clone(),writeObject(),readObject(),其他方法都是直接调用HashMp中的方法实现。HashMap传入参数有Key,Value,HashSet实现时,保持HashMap的Value为常量,只对Key进行处理。
总结:

1.1 存储对象过程不同
1.1.1 HahMap存储过程
-
对HahMap的Key调用hashCode()方法,返回int值,即对应的hashCode;
-
把此hashCode作为哈希表的索引,查找哈希表的相应位置,若当前位置内容为NULL,则把hashMap的Key、Value包装成Entry数组,放入当前位置;
-
若当前位置内容不为空,则继续查找当前索引处存放的链表,利用equals方法,找到Key相同的Entry数组,则用当前Value去替换旧的Value;
-
若未找到与当前Key值相同的对象,则把当前位置的链表后移(Entry数组持有一个指向下一个元素的引用),把新的Entry数组放到链表表头;
1.1.2 HashSet存储过程
-
往HashSet添加元素的时候,HashSet会先调用元素的hashCode方法得到元素的哈希值 ,然后通过元素的哈希值经过移位等运算,算出该元素在哈希表中的存储位置。
-
如果算出元素存储的位置目前没有任何元素存储,那么该元素可以直接存储到该位置上。
-
如果算出该元素的存储位置目前已经存在有其他的元素,那么会调用该元素的equals方法与该位置的元素再比较一次,如果equals返回的是true,那么该元素与这个位置上的元素就视为重复元素,不允许添加,如果equals方法返回的是false,那么该元素运行添加。















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









