







目录
1. 插入查询结果
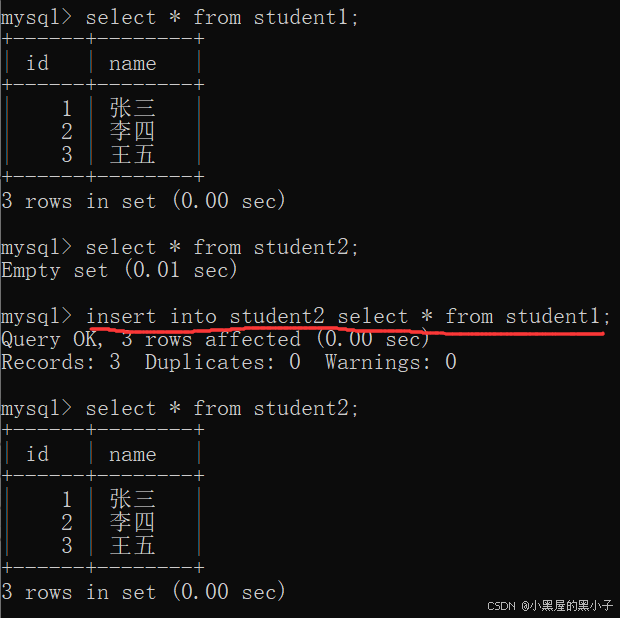
查询搭配插入使用。把查询语句的查询结果,作为插入的数值。
查询结果集合的列数、类型,和插入的表的列数,类型要相匹配 —— 表结构相同
询结果
2 聚合查询 (行与行之间运算)
聚合查询,是针对行和行之间进行运算的。表达式查询,是针对列和列之间进行运算的。
sql中提供了一些"聚合函数”通过聚合函数来完成上述行之间的运算。聚合函数 ,sql提供的 库函数。
| 函数 | 说明 |
| count([distinct] expr) | 返回查询到的数据的 数量(查询结果的行数) |
| sum([distinct] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg([distinct] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max([distinct] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min([distinct] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
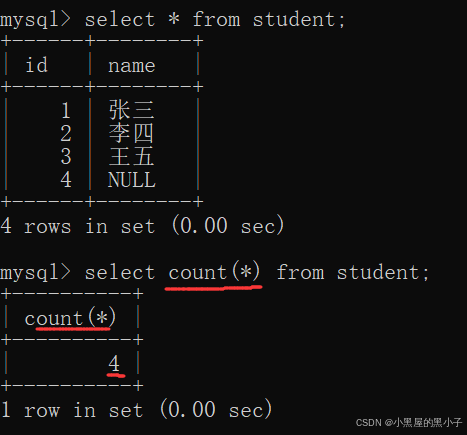
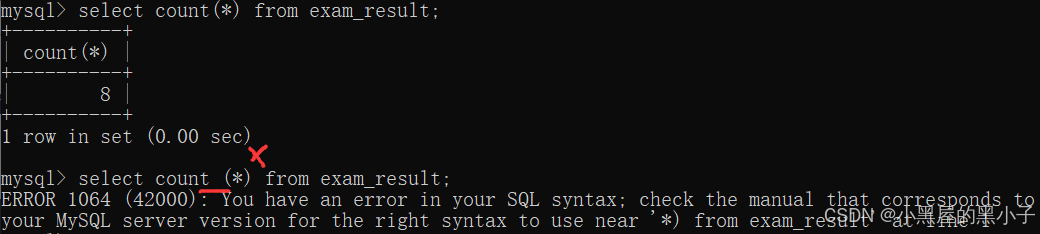
count 计算查询结果的行数
- 这个操作可以理解为,先执行select *,再针对结果集合进行统计(看看具体有几行)。
- 4 rows in set (0.00 sec) 这里已经能看到行数了,为什么还要使用count呢。
- 这里显示行数是mysql客户端内置的功能。如果是通过代码来操作mysql服务器就没这个功能。
- 另外,count(*)得到的结果还可以参与各种算术运算,还可以搭配其他sql使用。
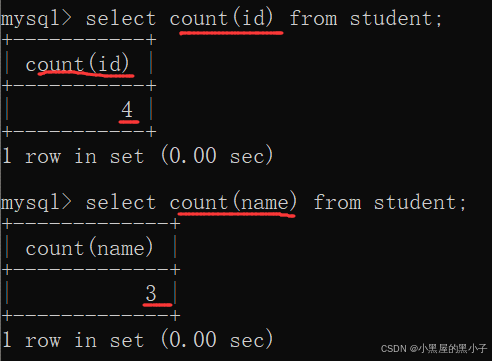
指定列进行的count
- 注意这里name 计数的是3个, name为 NULL 的数据不会计入结果。
- 如果当前的列里面有null,select * 和 指定列 两种方式计算的count是不同的。
- 指定具体列,是可以进行去重的。而select * 不支持。

很多语言中,函数名和后面()中间的空格是不做要求的。但在有的语言中就是例外,例如sql中。
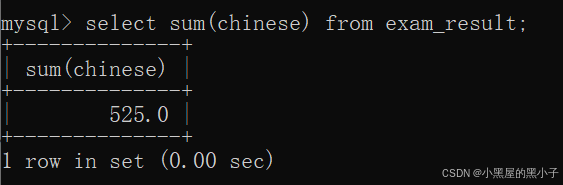
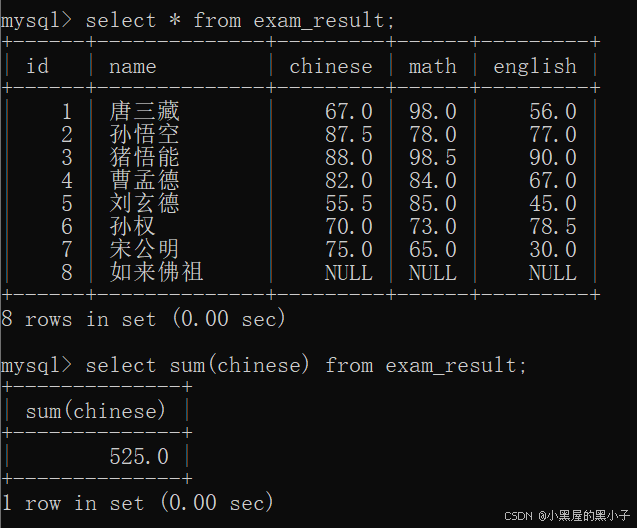
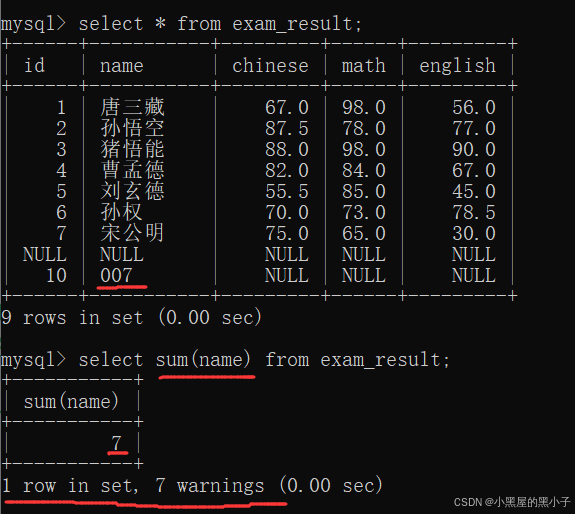
sum 求和
把这一列的若干行,进行求和(算术运算)只能针对数字类型使用。虽然字符串可以相加,但不是"算术运算"。
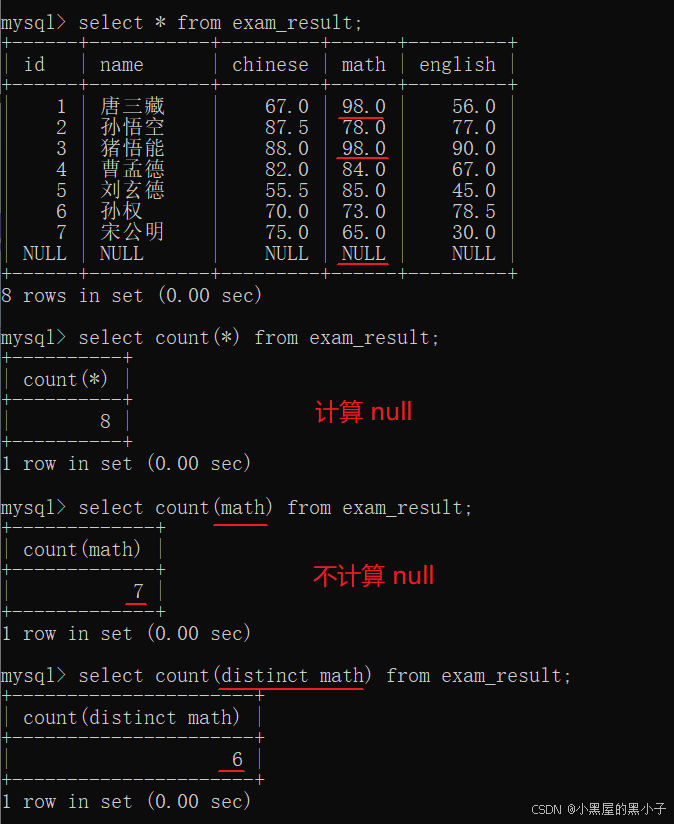
- 如果计算该列数据中有null,sum操作会自动跳过查询结果为null的行。原因:null和其他数值进行运算,结果还是null,这样sum操作就没意义了。
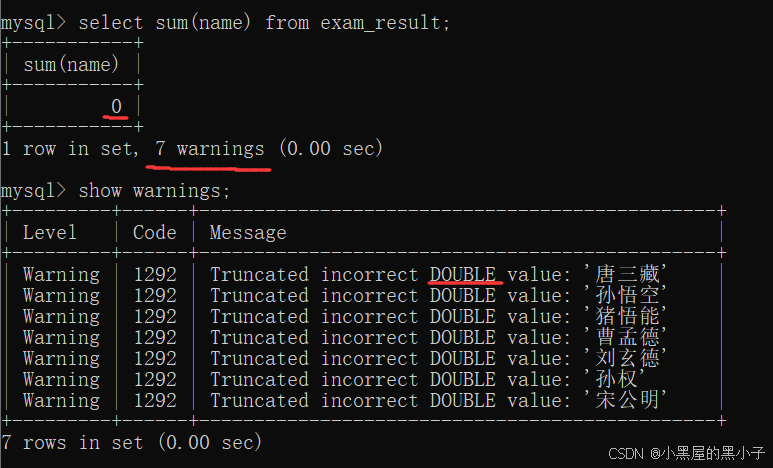
- 字符串可以相加,但不是"算术运算"。
- 这里进行字符串的相加,没有直接报错,只是出现了 7 个警告,有问题但不严重。
- 通过 show warnings 语句查看警告。我们看到在进行相加时,mysql会尝试把这一列给转成double类型,如果转成了,就可以进行运算。如果没转成,就会警告。
这里‘007’被转化为了double类型,参加了算数运算。
- sum()中可以指定表达式,也可以进行去重操作。
- select chinese + math + english .....把对应的列相加,得到一个临时表
- 再把这个临时表的结果进行,行和行相加。
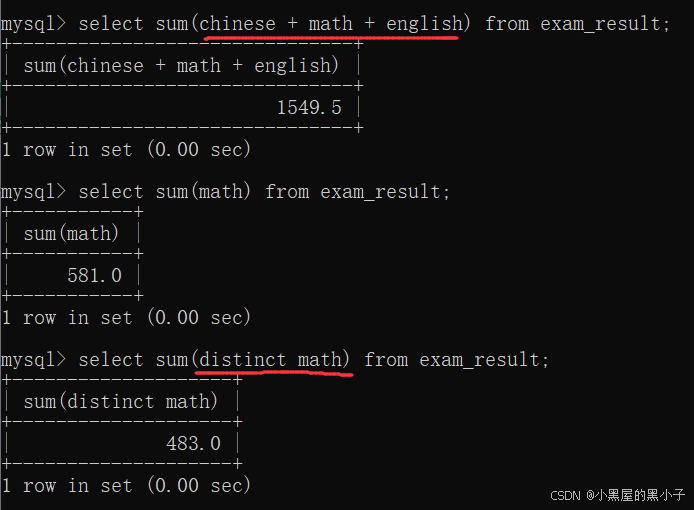
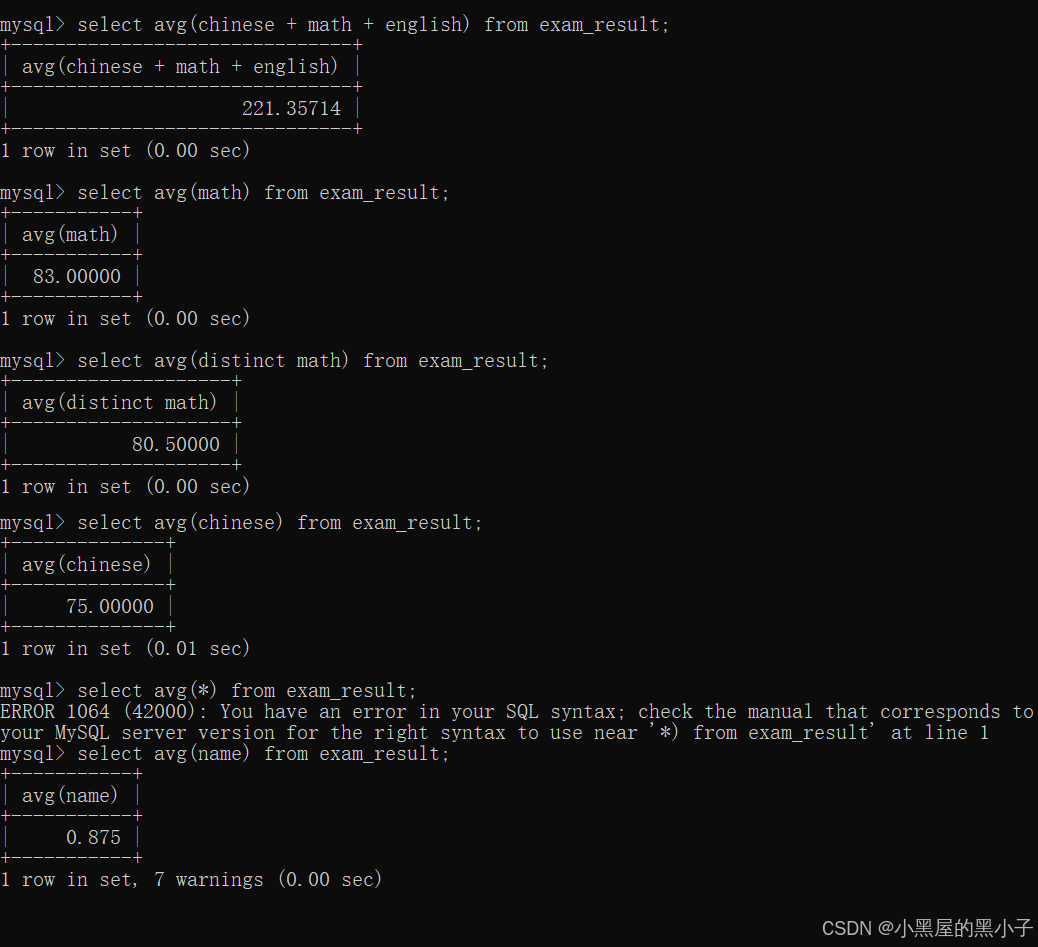
avg 求平均值
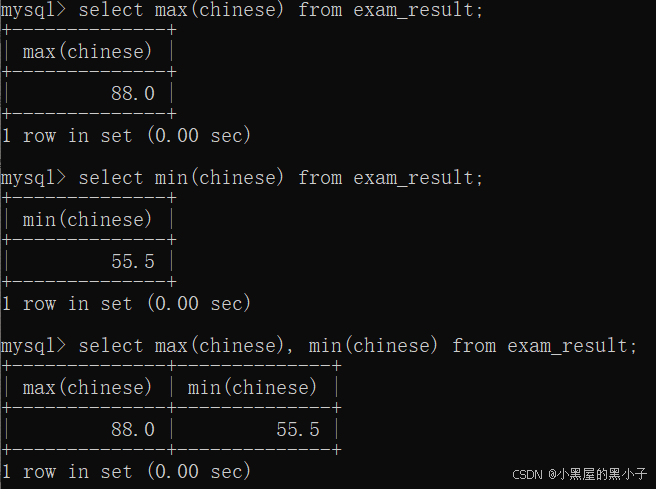
max 最大值 min 最小值
都可以进行表达式、去重、不计算null等操作。
【小结】
- 都可以进行表达式、去重、不计算null等操作。
- sql是有一定的"统计计算”能力的,就像excel一样。
- 能不能在聚合函数里面再添加一个聚合函数?sql表达逻辑的能力是有限的,如果有这样的需求,可以使用java操作sql,复杂逻辑用java来表达, sql只是做简单的查询和统计。
- 这样算平均薪资是不合理的。
- 这些聚合函数,默认都是针对这个表里的列中所有数据进行了聚合。
- 有时候需要分组聚合,(按照指定的字段,把记录分成若干组,每一组分别使用聚合函数)
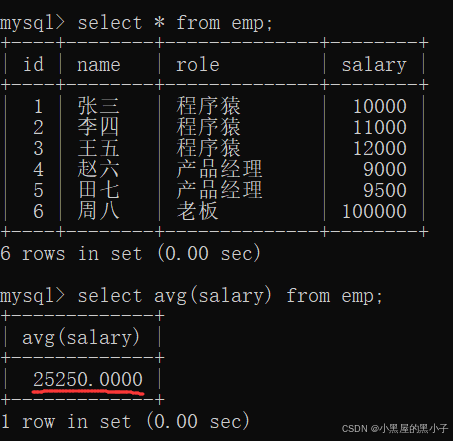
3. group by 子句 分组
- 使用group by进行分组,针对每个分组,再分别进行聚合查询。
- 针对指定的列进行分组,指把列里值相同的行,分到同一个组。得到若干个组,针对这些组分别使用聚合函数。
- select 指定的列,要么是带有聚合函数的,要么是指定的group by的列。不能指定一个非聚合,非group by的列。
- role这一列,是group by指定的列。每一组所有的记录的role,—定是相同的。
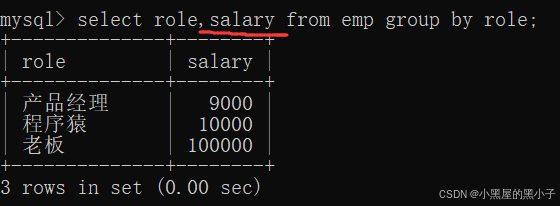
如果进行分组的时候,不进行聚合:
- 如果针对分组之后,不使用聚合函数,此时的结果就是查询出每一组中的某个代表数据(没有ordor by 约束的查询结果,不具备有序性)。
- 往往还是要搭配聚合函数使用,否则这里的查询结果,就是没有意义的。
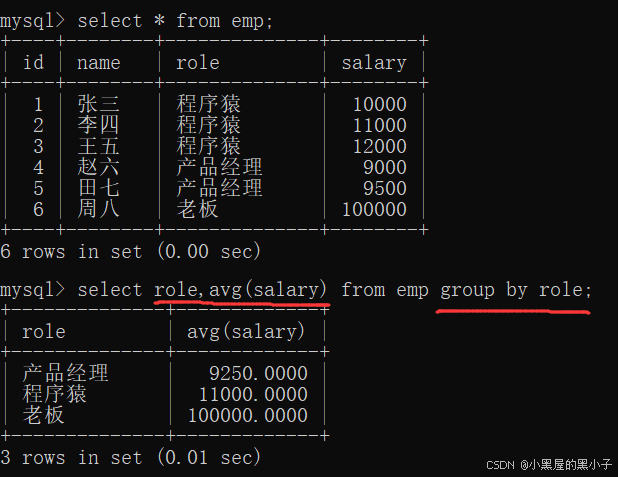
使用 group by 分组的时候,可以搭配条件筛选
需要先区分清楚,该条件是分组之前的条件,还是分组之后的条件。
where 条件
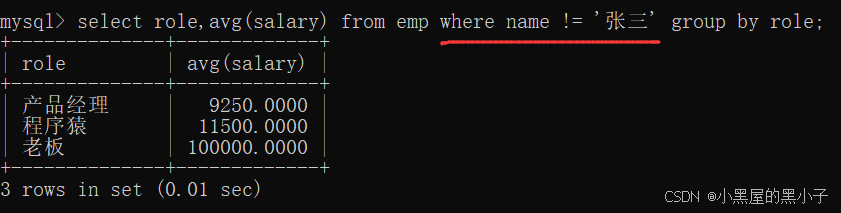
1、分组前筛选,使用 where 条件
查询每个岗位的平均薪资,但是排除张三同学。
直接使用where即可。where子句一般写在group by 的前面。
整个sql语句的执行顺序:先执行where 条件 筛选,再进行分组,然后执行聚合函数。
having 条件
2、分组后筛选,使用 having 条件
求每个岗位的平均薪资,但是排除平均薪资超过2w的结果。
使用having描述条件。having子句一般写在group by的后面。
整个sql语句执行顺序:先进行分组,执行聚合函数,然后执行 haveing 条件 筛选

3、在group by 分组,可以一个sql同时完成这两类条件的筛选。查询每个岗位的平均薪资,排除张三同学,并保留平均值<2w的结果。

分组前筛选、分组后筛选,还是两种条件都具备,具体内容具体分析。
4. 联合查询(多表查询)
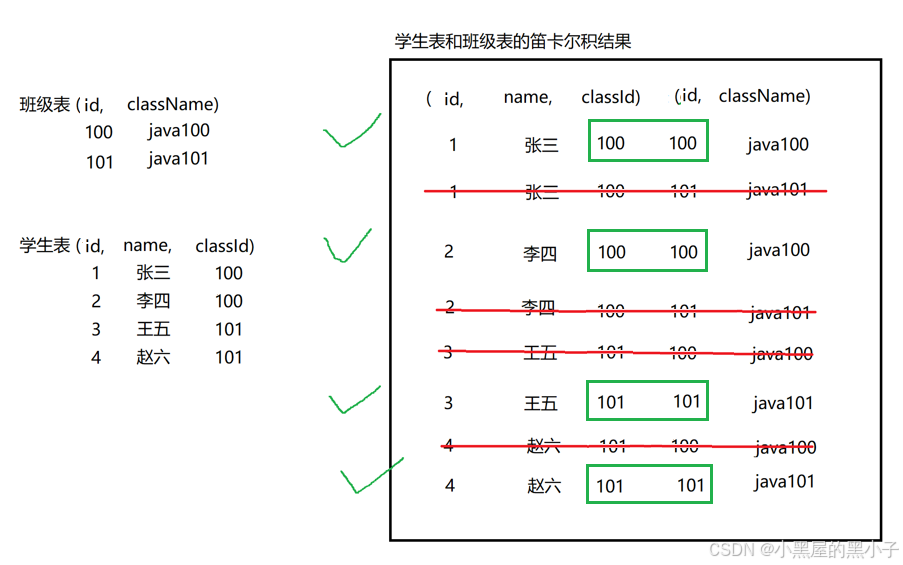
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积。
- 前面的查询,都是针对一个表。相比之下,有些查询则是一次性需要从多个表中进行查询获取记录。联合查询就是把多个表联合到一起进行查询。
- 联合查询步骤:先经过笛卡尔积运算,通过连接条件筛选出有效数据,结合需求进一步筛选要查询的记录。
- 联合查询关键思路,在于理解"笛卡尔积"工作过程。笛卡尔积,是一种排列组合,把两张表的记录,尽可能的排列组合出N种情况。
- 笛卡尔积通过排列组合的方式,得到的一个更大的表。
- 笛卡尔积的列数,是两个表的列数相加。笛卡尔积的行数,是两个表的行数相乘
- 由于笛卡尔积简单无脑的排列组合方式,把所有可能的情况都穷举了一遍。包含一些合法的数据也包含非法的,无意义的数据。
- 进行多表查询时,使用sql的条件筛选出有效的数据。通过观察上述笛卡尔积表得出这个条件就是,where 班级表的id = 学生表的classld 也叫连接条件。
- 注意这里两个表并没有使用外键约束进行关联的,而是通过逻辑上的关系(业务字段匹配)关联的,例如某某学生属于哪个班级,是客观的实际情况。笛卡尔积穷举出所有可能,使用连接条件(逻辑上的关系)筛选出有效数据。
- 关联查询可以对关联表使用别名。
笛卡尔积在日常开发中,要非常克制的使用。
- 有时候使用起来非常的方便快捷。
- 一旦表的数据量大或者表数目多,得到的笛卡尔积就非常庞大。如果针对大表进行笛卡尔积(多表查询),就会生成大量的临时结果,这个过程非常消耗时间。数据库服务器在这样的情况下就可能卡死。
- 如果多表查询涉及到的表数目比较多时,sql就会非常复杂,可读性也大大降低了。
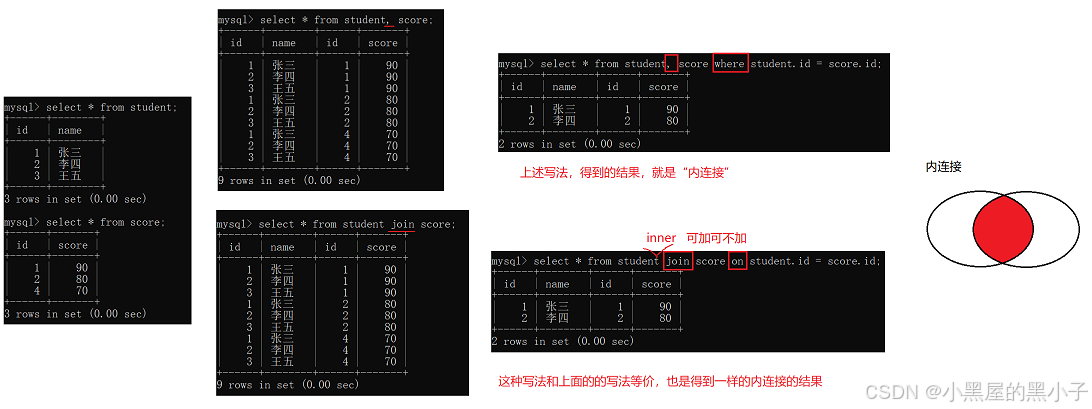
内连接
语法:
- select 字段 from 表1 别名1 , 表2 别名2 where 连接条件 and 其他条件;
- select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
- 两个sql语句是等价,一个使用 , ...... where ......; 一个使用 [inner] join ...... on......;
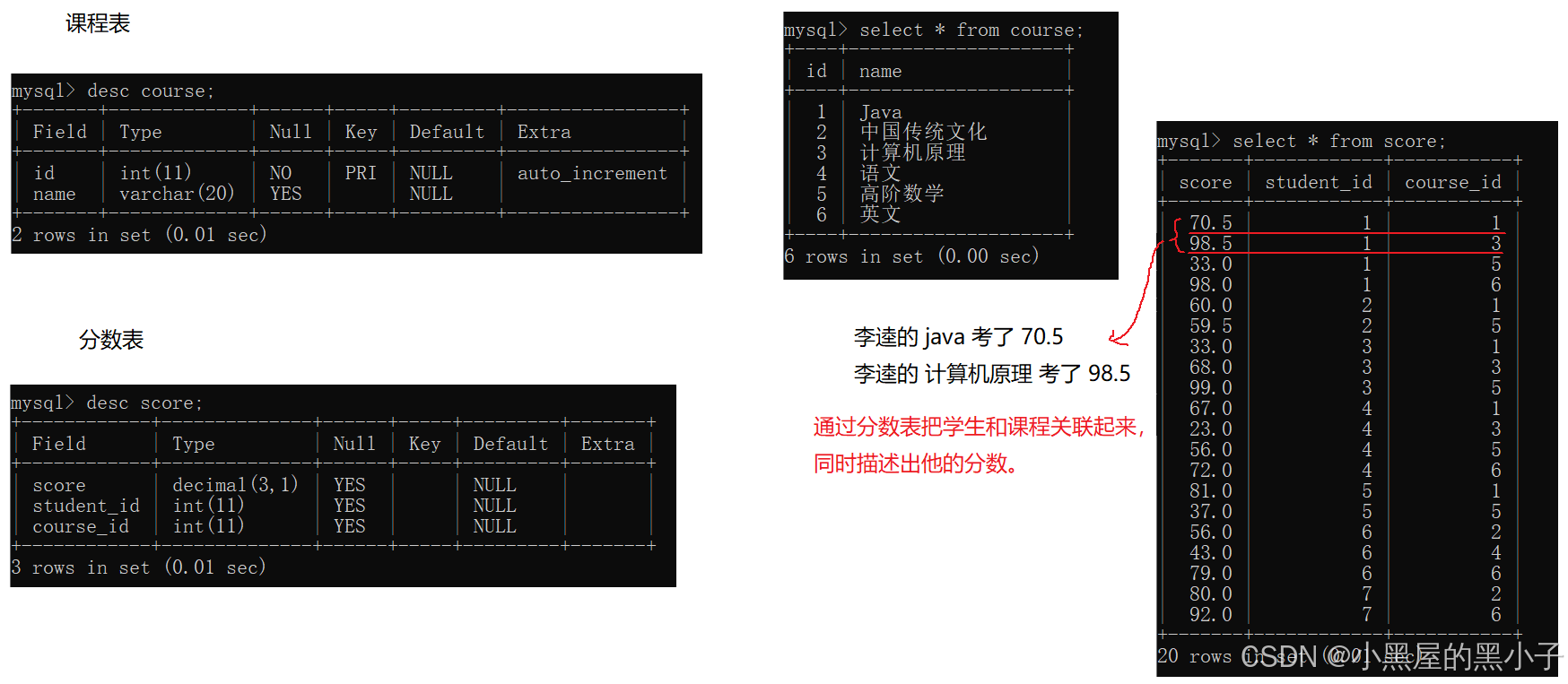
先创建几个表:学生表、班级表、课程表、分数表(学生和课程之间的关联表)
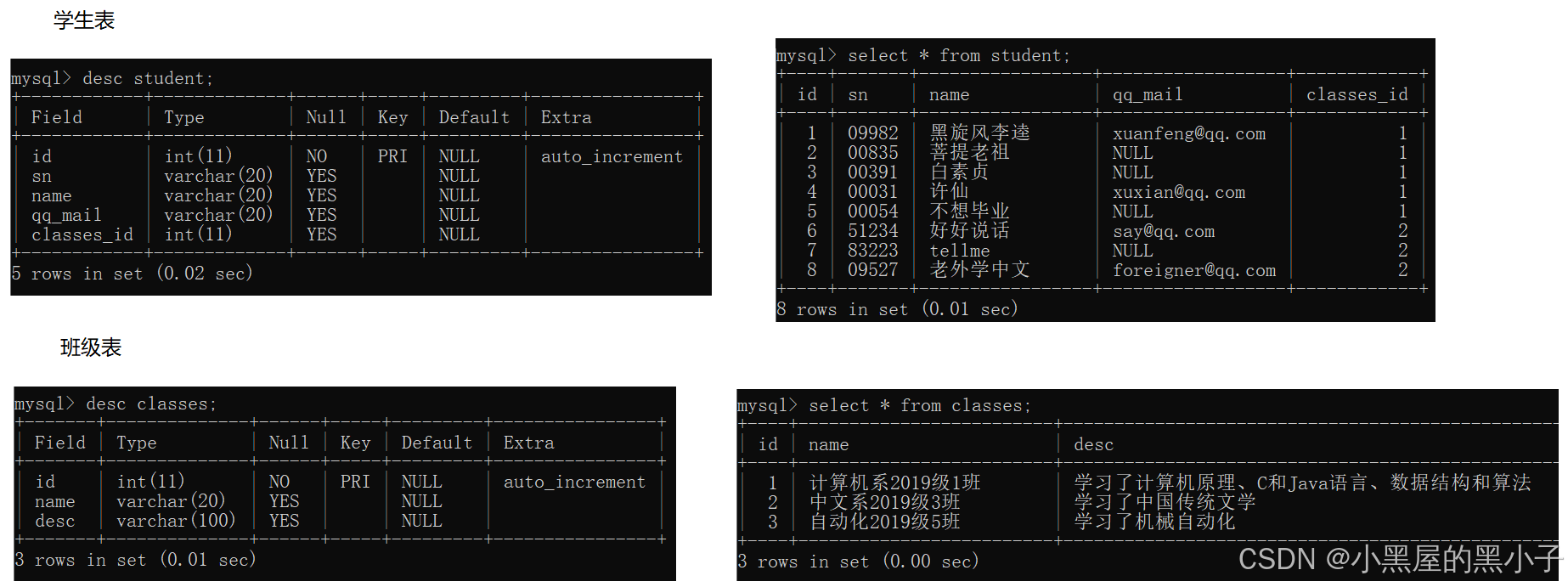
【案例1】查询‘许仙’同学的 成绩。
两个表:student和score。怎么进行联合查询。
1、先把这两个表,进行笛卡尔积。
- sql中直接通过表名中间 , 隔开就可以可以排列组合得到笛卡尔积。
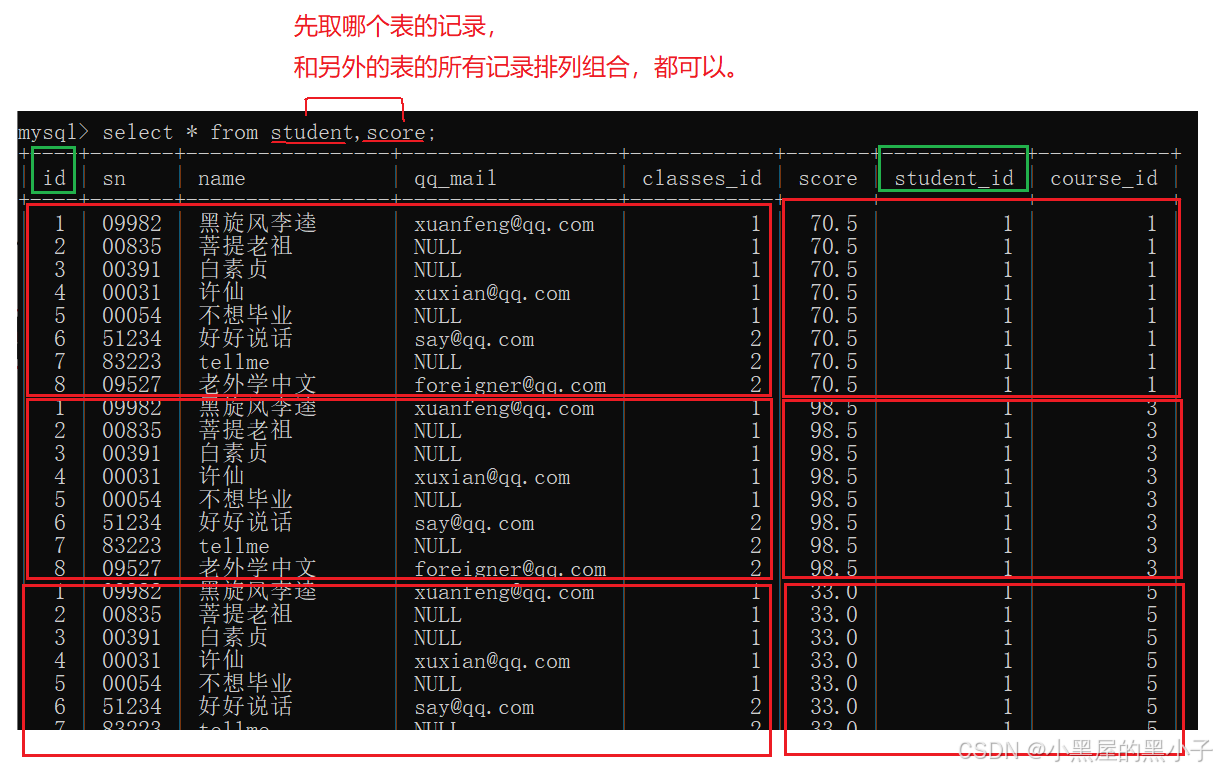
2、加上连接条件,筛选出有效数据
- 学生表的 id = 分数表的 student_id
- 为了避免不同表中可能存在有列名相同的列当做连接条件。同时笛卡尔积后列变多,可能区分不了是哪个表中的列。
- 所以连接条件写作:表名.列名。类似于java中的对象访问字段。
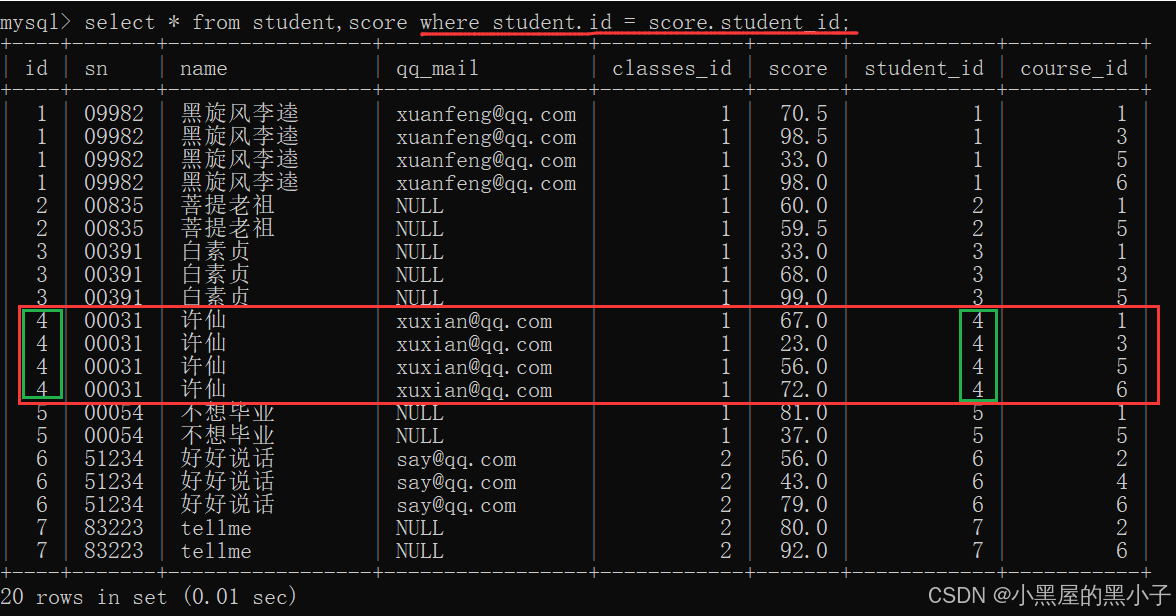
3、结合需求,进一步添加条件,针对结果进行筛选
此处是查询许仙的成绩,就可以再加上一个 student.name = '许仙'
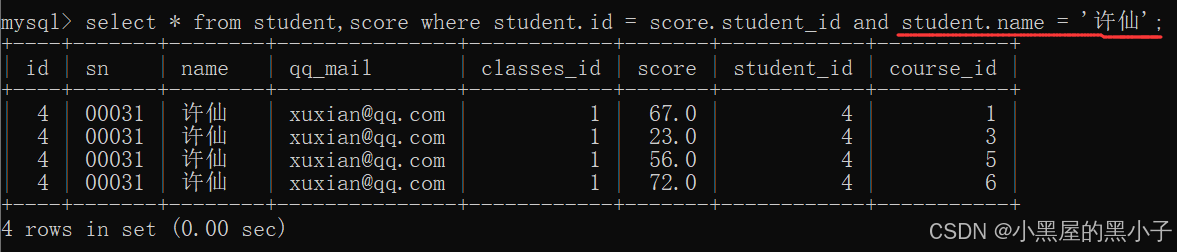
4、针对查询到的列进行精简,只保留需求中的列

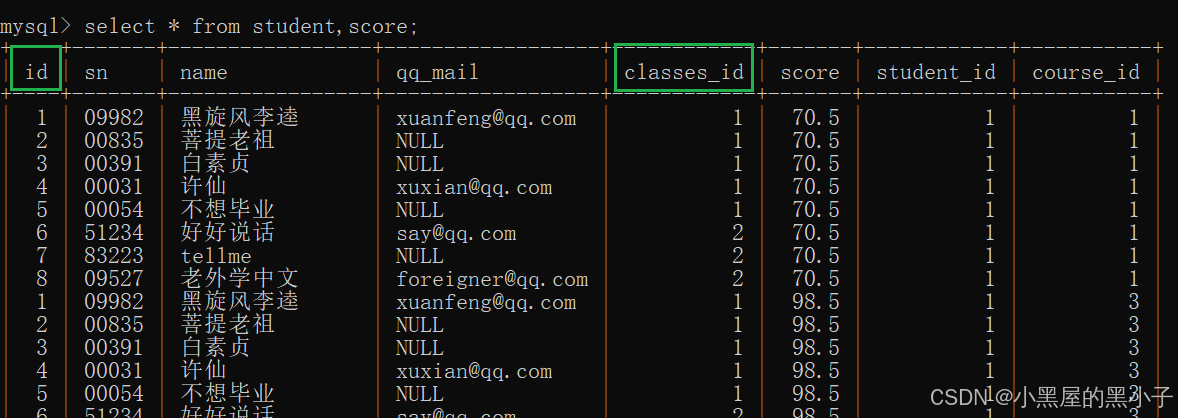
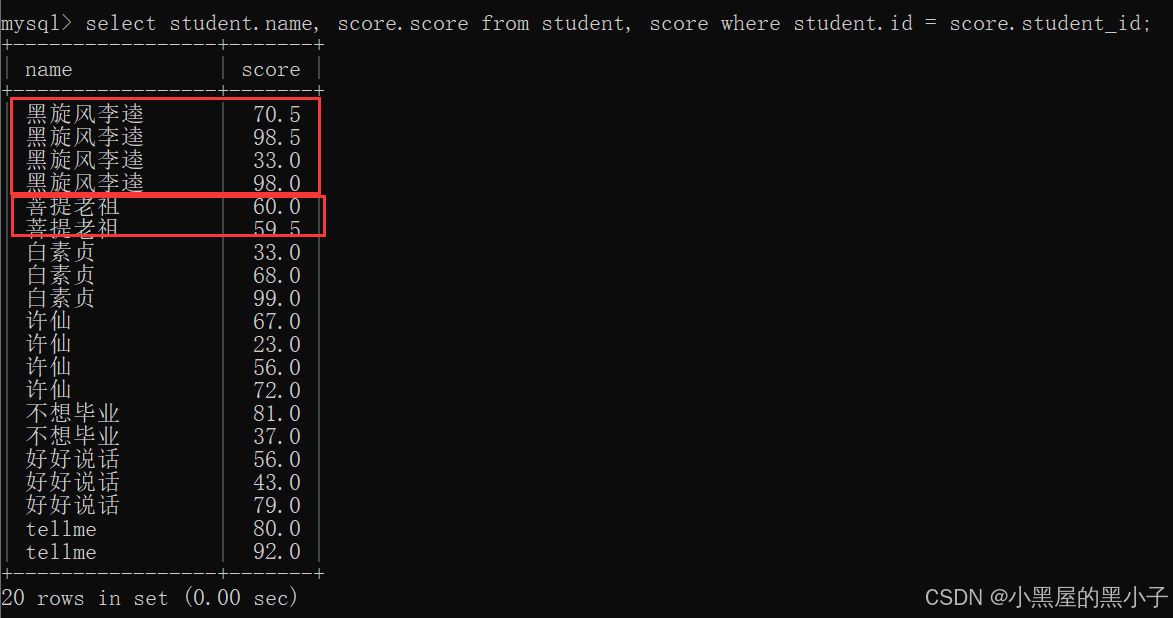
【案例2】查询所有同学的总成绩,及同学的个人信息。
分析:
- 之前是通过表达式查询来完成总成绩的计算(列与列之间运算)。
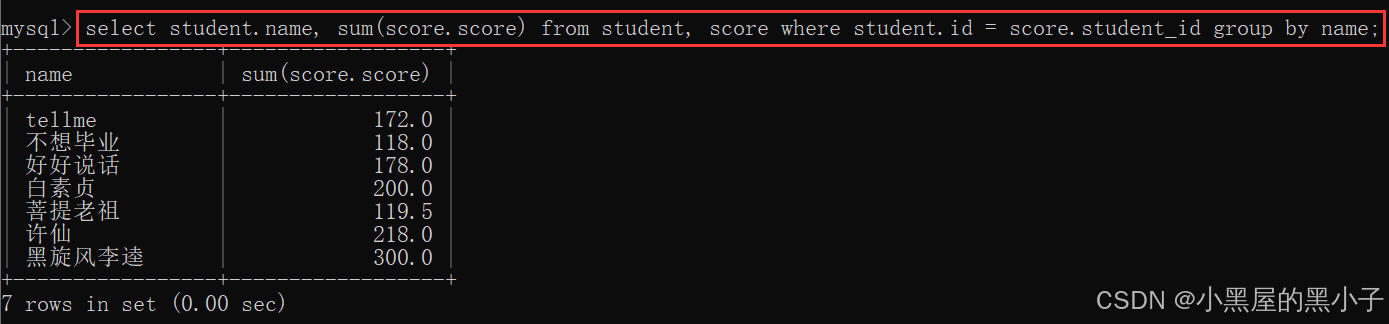
- 这里同学的成绩是按照行来组织的,使用聚合查询(行与行之间运算),聚合函数sum完成总成绩的计算,同时搭配group by子句 按照同学进行分组。
- 基于多表查询和聚合查询综合运用。
1、先进行笛卡尔积
2、指定连接条件
student.id = class.student_id
3、先精简列
4、针对上述结果,再进行group by聚合查询。
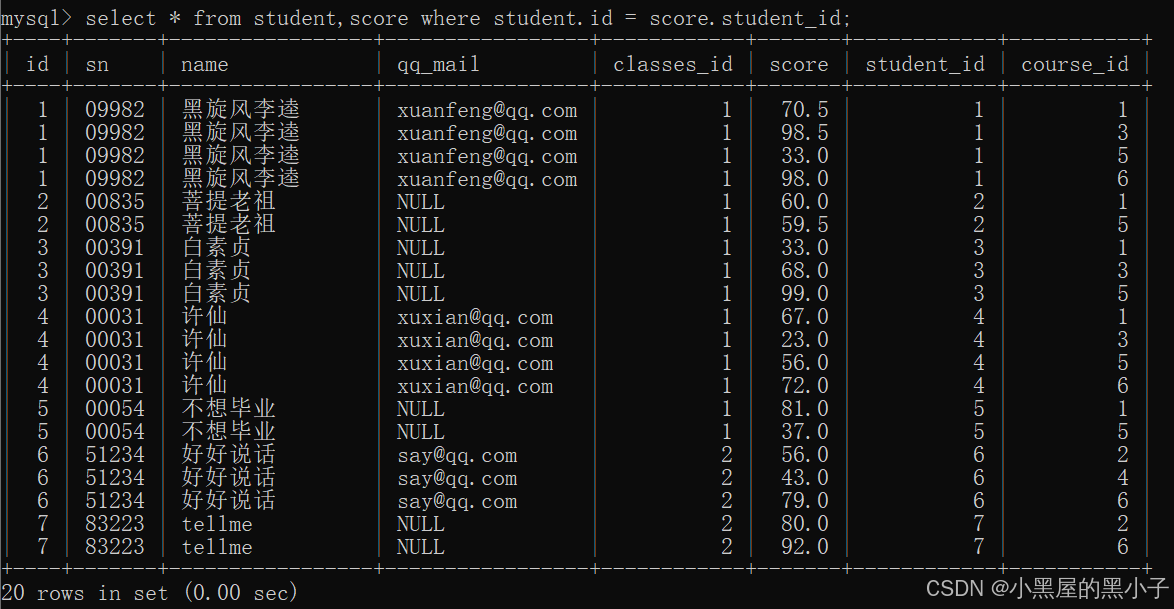
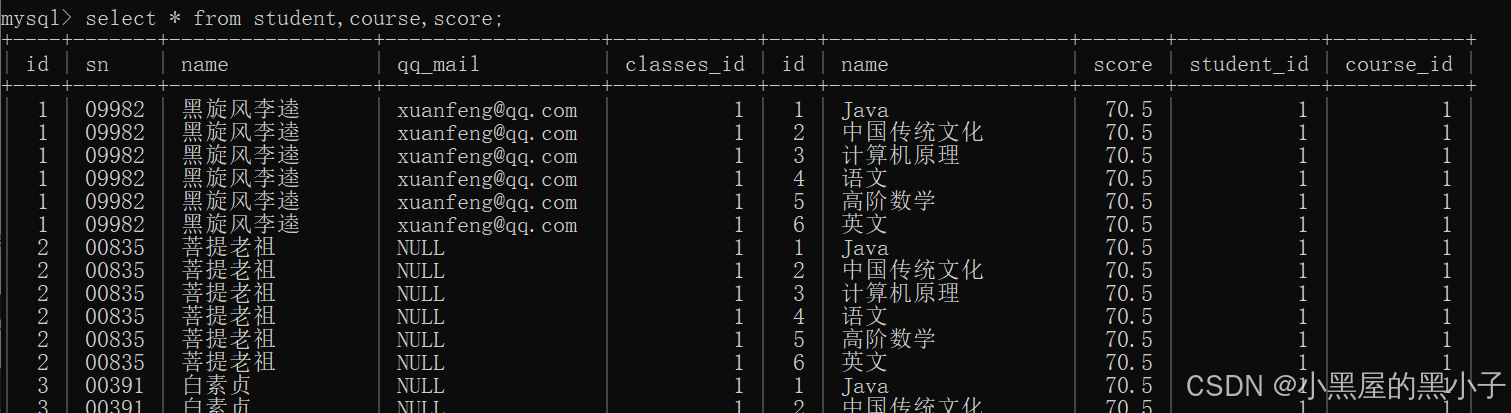
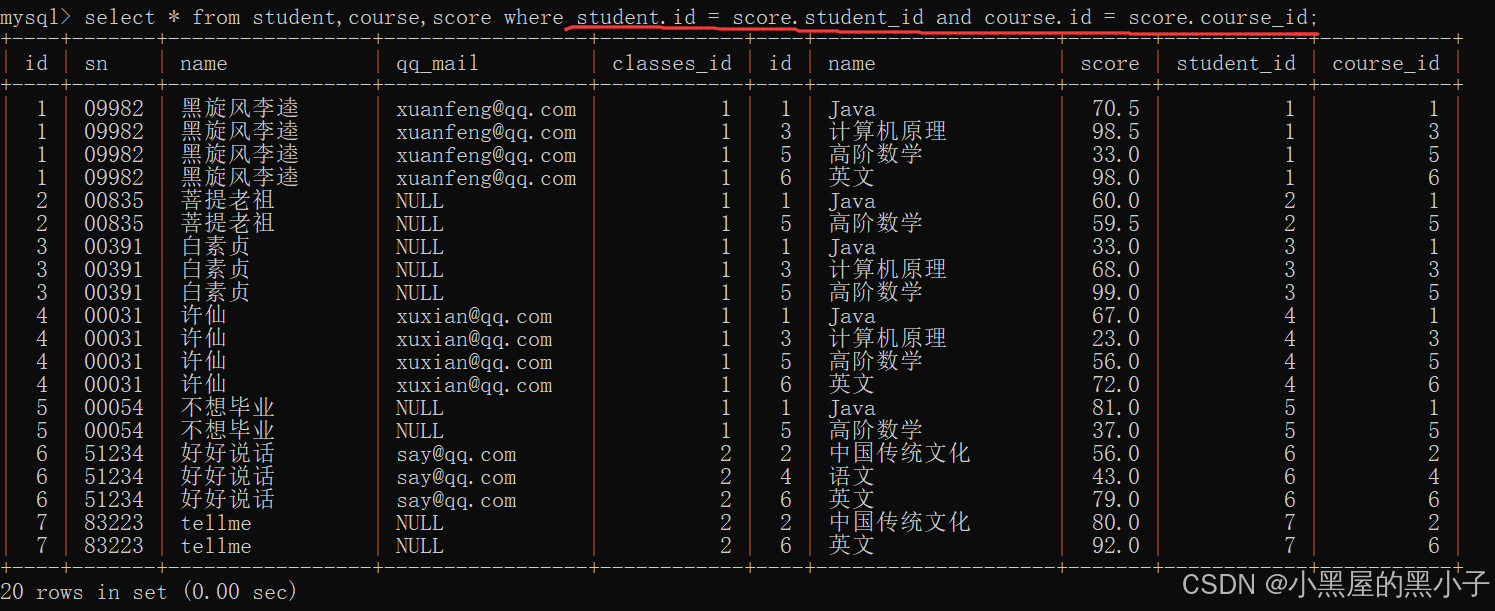
【案例3】查询每个同学,每门课程的课程名字和分数。
三张表:student,course,score
1、先进行笛卡尔积
2、指定连接条件,筛选数据
三个表,涉及到两个连接条件。分数表把学生和课程关联起来,同时描述出他的分数。
3、精简列

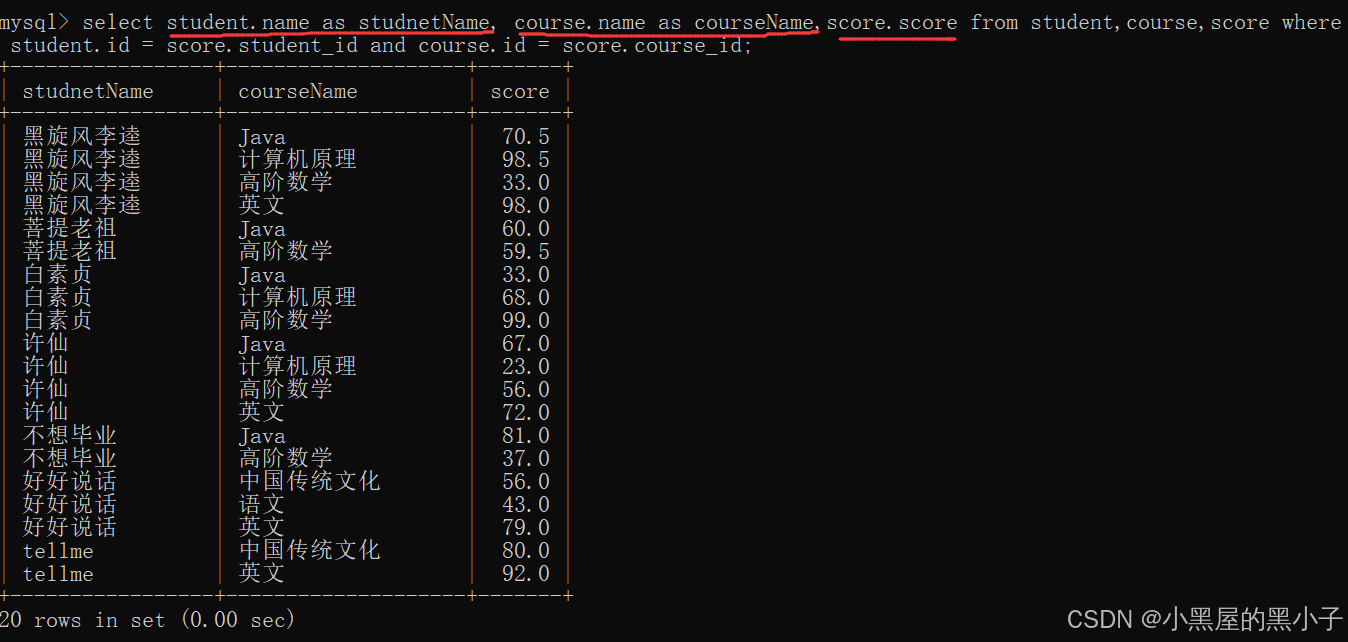
外连接
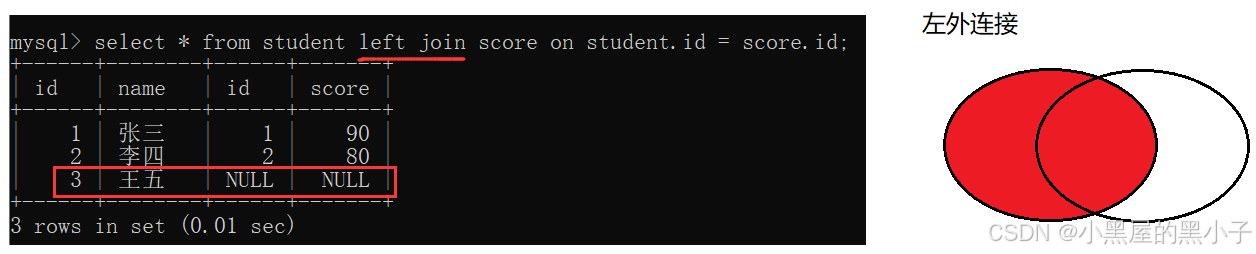
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示就说是左外连接;右侧的表完全显示就说是右外连接。
语法:
-- 左外连接,表1完全显示
- select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
- select 字段 from 表名1 right join 表名2 on 连接条件;
如果这两个表,里面的记录都是存在对应关系,内连接和外连接的结果是一致的。
- student 中的每一条记录,都可以在score表中找到对应。
- 每一个score中的记录,也可以在student中找到对应。

如果两个表,里面存在不对应的记录,内连接和外连接就会出现差别。
这种情况很少出现,因为在插入数据的时,一般都会进行严格的校验,但不否认不会存在这样的情况。例如王五同学缺考了,没有成绩。

内连接
左外连接,left join
- 左外连接,就是以左侧表为基准。
- 保证左侧表的每个数据都会出现在最终结果里。
- 如果左表中的记录在右侧表中不存在,对应的列就填成null
右外连接,right join
- 右外连接,是以右侧表为基准。
- 保证右侧表的每个数据都会出现在最终结果里。
- 如果右表中的记录在左侧表中不存在,对应的列就填成null

【小结】
- 多表查询运行过程中会产生大量的中间数据。在日常开发中,要非常克制的使用。使用时要尽可能明确,是针对多大规模的表使用以及产生的结果规模。
- 即使使用,大多数情况下都是使用内连接。外连接只是针对特殊情况,给出的特殊处理方式。
自连接
- 自连接是指在同一张表连接自身进行查询。自己和自己进行笛卡尔积。(特殊技巧)
- 特殊情况下特殊用法:sql中的条件都是列和列之间进行比较。但是有的需求可能涉及到行和行比较。所以可以使用自连接,把行的关系转换成列的关系。
【案例】显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
此处course_id 为 1 的是Java的成绩,为 3 的是计算机原理的成绩,看哪个同学的计算机原理的成绩比Java的成绩高,但是它们处在不同的行中,无法直接进行比较。 我们使用自连接方式,把行的关系转换成列的关系。
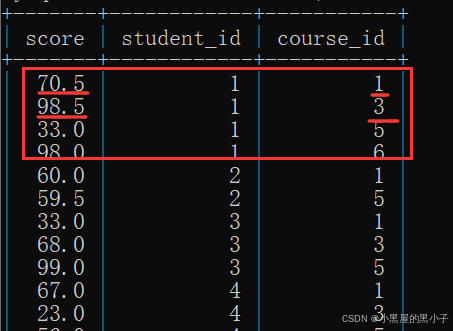
1、自己与自己进行笛卡尔积
- score, score 这样写报错了,原因:score不是唯一的表/别名。
- 利用别名,使两个表名区别开。
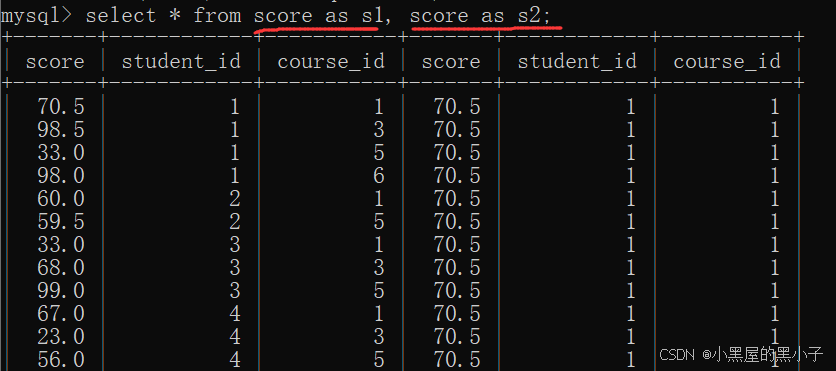
2、指定连接条件,筛选数据
- 这里可以按照学生id进行筛选,也可以使用课程id进行筛选。主要看关注的是学生信息还是课程信息。
- 此处关注的是学生信心,按照学生信息去筛选。
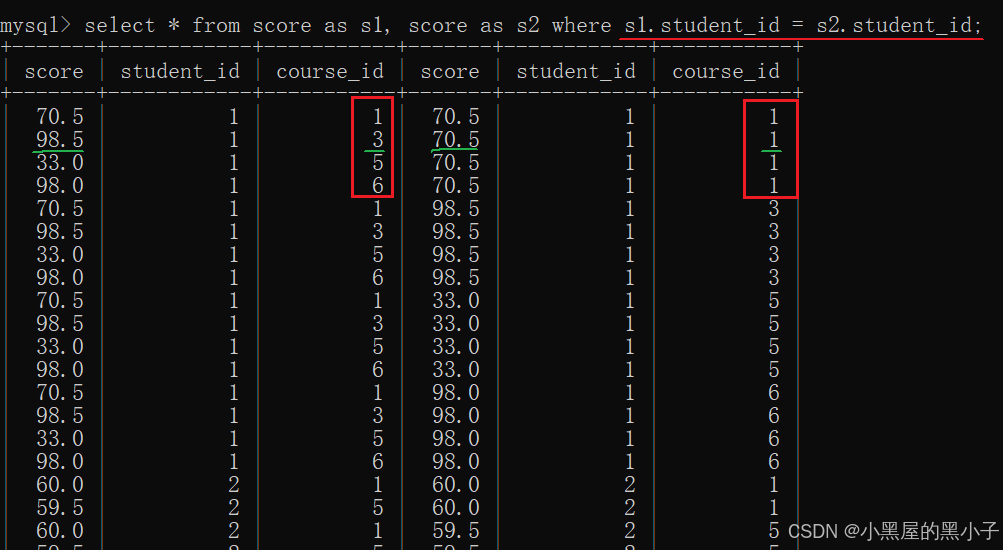
3、结合需求,进一步添加条件,针对结果进行筛选
- 得到的结果,左侧表分数列是计算机原理;右侧分数列是java。而且是不同学生的。
4、结合需求,再添加条件,针对结果进行筛选
得到计算机课程成绩大于java课程成绩的信息。
5、精简列
- 如果想要学生姓名,就可以拿这个表和学生表做笛卡尔积
- 如果想要课程名字,就可以拿这个表和课程表做笛卡尔积




子查询
- 子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。本质上是在"套娃"。
- 把多个简单的SQL拼成一个复杂的SQL。一个大的复杂的东西,不方便看也不好理解。
- 违背了一贯的编程原则:平时写代码都讲究,把大的拆分成小的,把复杂的拆分成多个简单的。
- 在开发中并不建议使用子查询,应该使用多个简单sql替代。但是还是要了解一下的。
1、单行子查询:返回一行记录的子查询
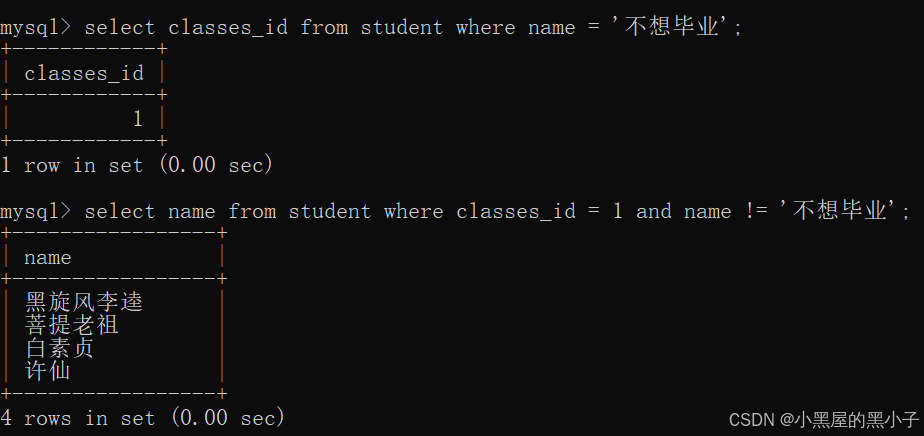
【案例】查询与“不想毕业” 同学的同班同学:
- 先找到“不想毕业”同学,所在的班级classes_id 为 1;
- 然后找到班级classes_id 为 1 的其他同学,就找到“不想毕业”同学的同班同学。
通过子查询方式一步完成:
这里嵌套的select 语句,返回结果必须是一行的记录。这里直接把嵌套select 语句当成一个数值使用。

2、多行子查询:返回多行记录的子查询
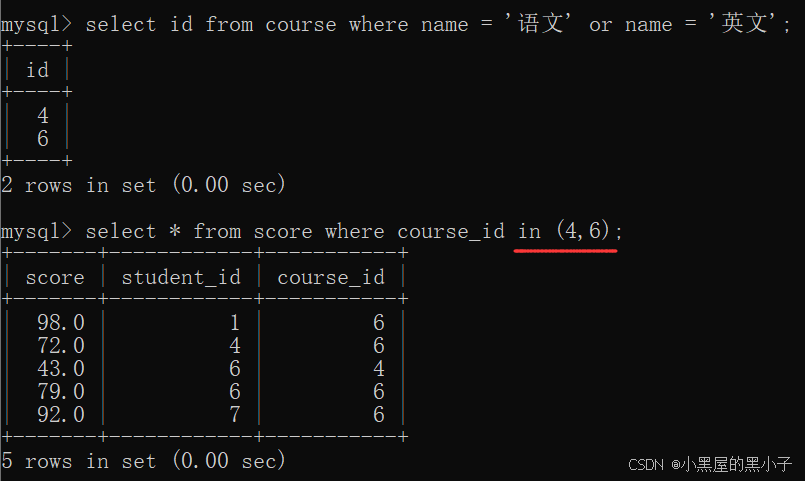
【案例】查询“语文”或“英文”课程的成绩信息
使用联合查询方法:两个表,course,score

使用多行子查询,搭配 in 关键字使用。in 表示某个值是否存在这个集合中。
- 先通过课程名字,找到课程id。
- 再通过课程id在分数表中进行查询
通过子查询方式一步完成:
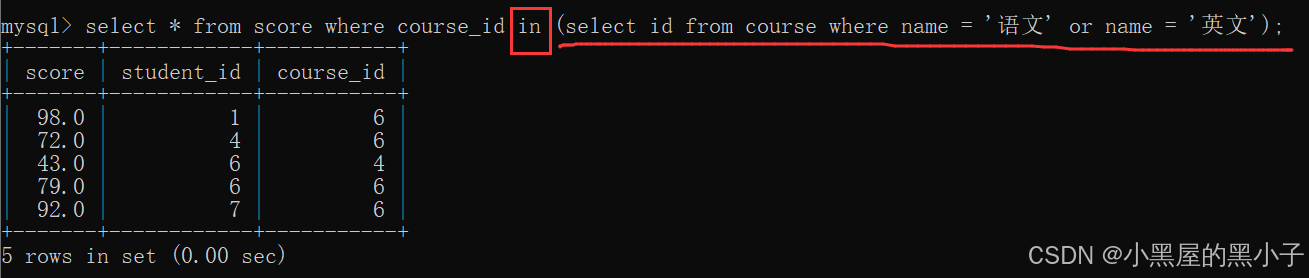
多行子查询,也可以搭配 exists 关键字使用。相比于 in 关键字,搭配 exists 更复杂,运行效率还比较低。唯一的优势是节省内存空间,仅此而已。但是内存并不是影响代码的瓶颈的设备。这里不做过多介绍,可自行了解。
合并查询
- 在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all 关键字。把多个sql查询的结果集合,合并到一起。
- 使用union 和 union all时,合并的两个sql的结果集的列,需要匹配。列的个数和类型,要一致的(列名不需要一致) —— 表结构相同。
- union 该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行(去重)。
- union all 则不会去掉结果集中的重复行。
- MySQL中的 union 是联合/合并的意思。在 C语言的自定义数据类型章节中讲述过,union 是联合体的意思,作用给一个内存空间赋予了多种解释方式。极致的省内存。Java中没有联合体。
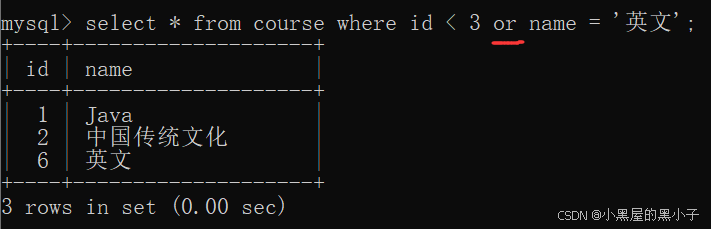
【案例】查询id小于3,或者名字为“英文”的课程:
- 使用 or 操作符,但只能针对一个表。
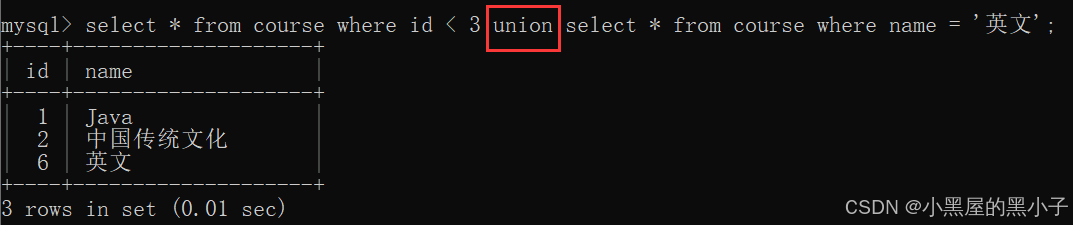
- 使用 union 操作符 进行合并查询。
- 允许把两个表不同的表,查询结果合并在一起。
- 合并的两个sql的结果集的列,需要匹配。列的个数和类型,要一致的(列名不需要一致)。
- 最终查询出的临时表的列名与第一个表的列名相同。
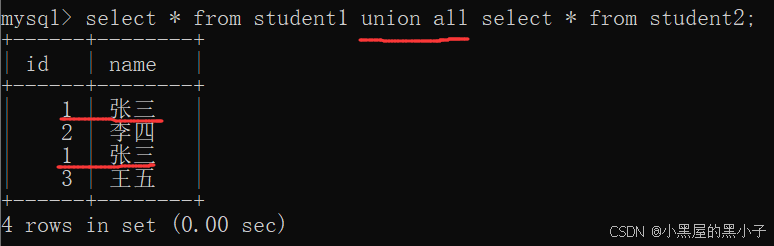
- 使用union all 操作符合并查询,不会去掉结果集中的重复行。

总结
插入查询结果:
insert into student2 select * from student1;
insert into student2(name, email) select name, qq_mail from student1;
聚合查询:
1、聚合函数:count、sum、avg、max、min
2、分组查询:group by 分组前筛选 where...group by... 分组后筛选group by...having...
联合查询:
3、内连接:
select ... from 表1, 表2 where 条件
-- inner可以缺省
select ... from 表1 [inner] join 表2 on 条件 where 其他条件
4、外连接:
左外连接:select ... from 表1 left join 表2 on 条件 where 其他条件
右外连接:select ... from 表1 right join 表2 on 条件 where 其他条件
5、自连接:
select ... from 表1,表1 where 条件
select ... from 表1 join 表1 on 条件
6、子查询:
-- 单行子查询
select ... from 表1 where 字段1 = (select ... from ...);
-- 多-行子查询
select ... from 表1 where 字段1 in (select ... from ...);
7、合并查询
-- UNION:去除重复数据
select ... from ... where 条件 union select ... from ... where 条件
-- UNION ALL:不去重
select ... from ... where 条件 union all select ... from ... where 条件
-- 使用UNION和UNION ALL时,前后查询的结果集中,字段类型与个数需要一致。
SQL查询中各个关键字的执行先后顺序: from > on > join > where > group by > with > having > select > distinct > order by > limit
好啦Y(^o^)Y,本节内容到此就结束了。下一篇内容一定会火速更新!!!
后续还会持续更新MySQL方面的内容,还请大家多多关注本博主,第一时间获取新鲜的知识。
如果觉得文章不错,别忘了一键三连哟! 


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









