







前言
本次博客先会输出DFS的一些题目,DFS蓝桥考的真的不少,掌握需要大量的刷题,这点题目是完全不够的,有时间的话可以去网站刷,之后是字符串的内容
黄金树
黄金树
DFS 和 树结合也是常考题目,每年基本上会有关于树问题的题目
这个题确实不难,对DFS熟悉的可以轻松码出来
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
#define int long long
#define ld long double
#define vt vector<int>
const int mod = 1e9 + 7;
const int N = 1e5 + 7;
int n;
struct node{
int val,left,right;//儿子
}w[N];
int ans;
void dfs(int x,int go)
{
if(x > n) return;
if(go == 0) ans += w[x].val;
int ls = w[x].left;
int rs = w[x].right;
if(ls != -1) dfs(ls,go + 1);
if(rs != -1) dfs(rs,go - 1);
if(ls == -1 && rs == -1) return;
}
void solve()
{
cin >> n;
for(int i = 1;i <= n;i++) cin >> w[i].val;
for(int i = 1;i <= n;i++) cin >> w[i].left >> w[i].right;
dfs(1,0);
cout << ans;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
int _ = 1;
//cin >> _;
while(_ --) solve();
return 0;
}
混境之地5
还是跑图题,注意要加记忆化搜索,否则会T
dp数组的意义就是dp[i][j][k]表示用了k次(0/1)次是否能到i,j这个位置
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 1;
int mp[N][N];
int n,m,k;
int x1,x2,fy,y2;
int dx[] = {0,0,1,-1};
int dy[] = {1,-1,0,0};
int dp[N][N][2];
bool h(int x,int y)
{
return x >= 1 && x <= n && y >= 1 && y <= m;
}
bool dfs(int x,int y,int t)
{
if(x == x2 && y == y2) return true;
if(dp[x][y][t] != -1) return dp[x][y][t];
for(int i = 0; i <= 3;i ++)
{
int nx = x + dx[i],ny = y + dy[i];
if(!h(nx,ny)) continue;
if(!t)
{
//用
if(mp[x][y] + k >= mp[nx][ny] && dfs(nx,ny,1)) return dp[x][y][t] = true;
//不用
if(mp[x][y] >= mp[nx][ny] && dfs(nx,ny,0)) return dp[x][y][t] = true;
}
else
{
if(mp[x][y] >= mp[nx][ny] && dfs(nx,ny,1)) return dp[x][y][t] = true;
}
}
return dp[x][y][t] = false;
}
int main()
{
memset(dp,-1,sizeof(dp));
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
cin >> n >> m >> k;
cin >> x1 >> fy >> x2 >> y2;
for(int i = 1; i <= n ; i++)
{
for(int j = 1; j <= m; j++) cin >> mp[i][j];
}
cout << (dfs(x1,fy,0) ? "Yes" :" No")<< '\n';
return 0;
}
混境之地2
这个题和上面那个很像,但是有区别,这个题行走只要不走到墙可以无限转圈,所以要加个vis数组,记得要回溯,不然包错的
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 1;
char mp[N][N];
int n,m,k;
int x1,x2,yf,y2;
int dx[] = {0,0,1,-1};
int dy[] = {1,-1,0,0};
int dp[N][N][2];
int vis[N][N];
bool h(int x,int y)
{
return x >= 1 && x <= n && y >= 1 && y <= m;
}
bool dfs(int x,int y,int t)
{
if(x == x2 && y == y2) return true;
if(dp[x][y][t] != -1) return dp[x][y][t];
for(int i = 0; i <= 3;i ++)
{
int nx = x + dx[i],ny = y + dy[i];
if(vis[nx][ny] == 1) continue;
vis[nx][ny] = 1;
if(!h(nx,ny)) continue;
if(!t)
{
//用
if(mp[nx][ny] == '#'&& dfs(nx,ny,1)) return dp[x][y][t] = true;
//不用
if(mp[nx][ny] == '.' && dfs(nx,ny,0)) return dp[x][y][t] = true;
}
else
{
if(mp[nx][ny] == '.' && dfs(nx,ny,1)) return dp[x][y][t] = true;
}
vis[nx][ny] = -1;//要注意回溯
}
return dp[x][y][t] = false;
}
int main()
{
memset(dp,-1,sizeof(dp));
memset(vis,-1,sizeof(vis));
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
cin >> n >> m;
cin >> x1 >> yf >> x2 >> y2;
for(int i = 1; i <= n ; i++)
{
for(int j = 1; j <= m; j++) cin >> mp[i][j];
}
cout << (dfs(x1,yf,0) ? "Yes" :" No")<< '\n';
return 0;
}
字符串
本次讲的算法有kmp等(自己看目录),ac自动机会给个链接,还有一些例题。。。要吐了
KMP
KMP是一种字符串匹配算法,看到匹配或者一些玩前后缀的时候可以想这个,核心是处理nex数组(不要起名为next,会和库里的重复。。。。。)比如字符串p 在 s中出现的次数,朴素会到O(n * m)级别,KMP只需O(n + m)级别,不用研究nex数组怎么来的,会用就行
nex[i]表示在i这个位置,最长真相同前后缀的长度,也表示匹配失败时应该滚去的位置
比如 abaacd 的nex 就是0 0 1 1 0 0
模板
//n为字符串长度
注意:char s[100];cin >> s + 1;
int n = strlen(s + 1);//同步
nex[0] = nex[1] = 0;
for (int i = 2, j = 0; i <= n; i++)
{
while (j && p[i] != p[j + 1]) j = nex[j];
if (p[i] == p[j + 1]) j++;
nex[i] = j;
}
自己匹配自己的模板
#include <bits/stdc++.h>
//标准 KMP算法
//在 s中查找p出现的次数
using namespace std;
const int N = 1e6 + 1;
char s[N], p[N];
int nex[N], ans;
int main()
{
// cin >> p + 1 >> s + 1;
int n = strlen(p + 1);
int m = strlen(s + 1);
//进行处理nex数组
nex[0] = nex[1] = 0;
for (int i = 2, j = 0; i <= n; i++)
{
while (j && p[i] != p[j + 1]) j = nex[j];
if (p[i] == p[j + 1]) j++;
nex[i] = j;
}
// //对于样例abcabc // nex 为 0 0 0 1 2 3
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != p[j + 1]) j = nex[j];
if (s[i] == p[j + 1]) j++;
if (j == n) ans++;
}
cout << ans;
return 0;
}
例题后面一起放,可能字数会很多()
Manacher
最开始听别人说的一直以为是马拉车()原来还真是谐音梗
马拉车算法时有关回文字符串的算法,看到回文可以往这个想
先介绍一个概念为了后面的铺垫,
回文半径:比如字符串aabaa,对于回文中心b,回文半径就是三,但是对于偶数长度的字符串,很尴尬;
所以manacher算法的第一个处理,就是将字符串处理成奇数长度的字符串,把首尾和字符串中间加上特殊字符,比如原来的字符串是abba,处理完之后就变成^#a#b#b#a#@,注意首尾不同,其余都用#处理
对于当前的某一个位置i的回文半径p[i],说明原来回文串长度是p[i] - 1,很好理解和证明,记住就行。
!重要的是处理
模板,和KMP一样记住就行
int n = strlen(s + 1);
//填充 倒着填防止被覆盖,除非额外开一个数组!
s[0] = '@',s[2 * n + 2] = '$';
for(int i = 2 * n + 1; i >= 1;i--)
s[i] = i & 1 ? '#' : s[i >> 1];//写成if判断一个样
//或者这样
ns[0] = '@',ns[2 * n + 2] = '$';
for(int i = 1;i <= 2 * n + 1;i++)
{
ns[i] = i & 1 ?'#':s[i >> 1];
}
//处理
int c = 0, R = 0; // r是当前最右回文边界,c是中心
for(int i = 1;i <= 2 * n + 1;i ++)
{
int mirror = 2 * c - i;
p[i] = i < R ? min(R - i, p[mirror]) : 1;
while(s[i + p[i]] == s[i - p[i]]) p[i]++;
if(i + p[i] > R) c = i, R = i + p[i];
}
例题依旧放在后面
字符串哈希
这个感觉是很实用的算法,用数字表示字符串,降低处理字符串的复杂度,比如在s中寻找p的出现次数就可以适用字符串哈希,将每一段的值以O(1)算出
记得开unsigned long long,如果开long long可能会导致哈希冲突,还得设两个标准值,标准值相当于进制,一般是一个质数,比如131等,类比十进制
模板—背下来
//字符串哈希
#include<bits/stdc++.h>
#define ull unsigned long long
const ull base = 131;//base一般是一个质数
const int N = 1e6 + 1;
ull h[N],b[N]; //h[i] 表示s[1-i]的hash ---前缀和
char s[N];
ull getHash(int l,int r)
{
return h[r] - h[l - 1] * b[r - l + 1];
}
using namespace std;
int main()
{
cin >> s + 1;
int n;
n = strlen(s + 1);
b[0] = 1;
for(int i = 1;i <= n;i++) h[i] = h[i - 1] * base + (int)s[i];//这里直接转成int就行,懒得去减
for(int i = 1;i <= n;i++) b[i] = b[i - 1] * base;//获取base的i次方
//获取子串l - r 的hash
getHash()
return 0;
}
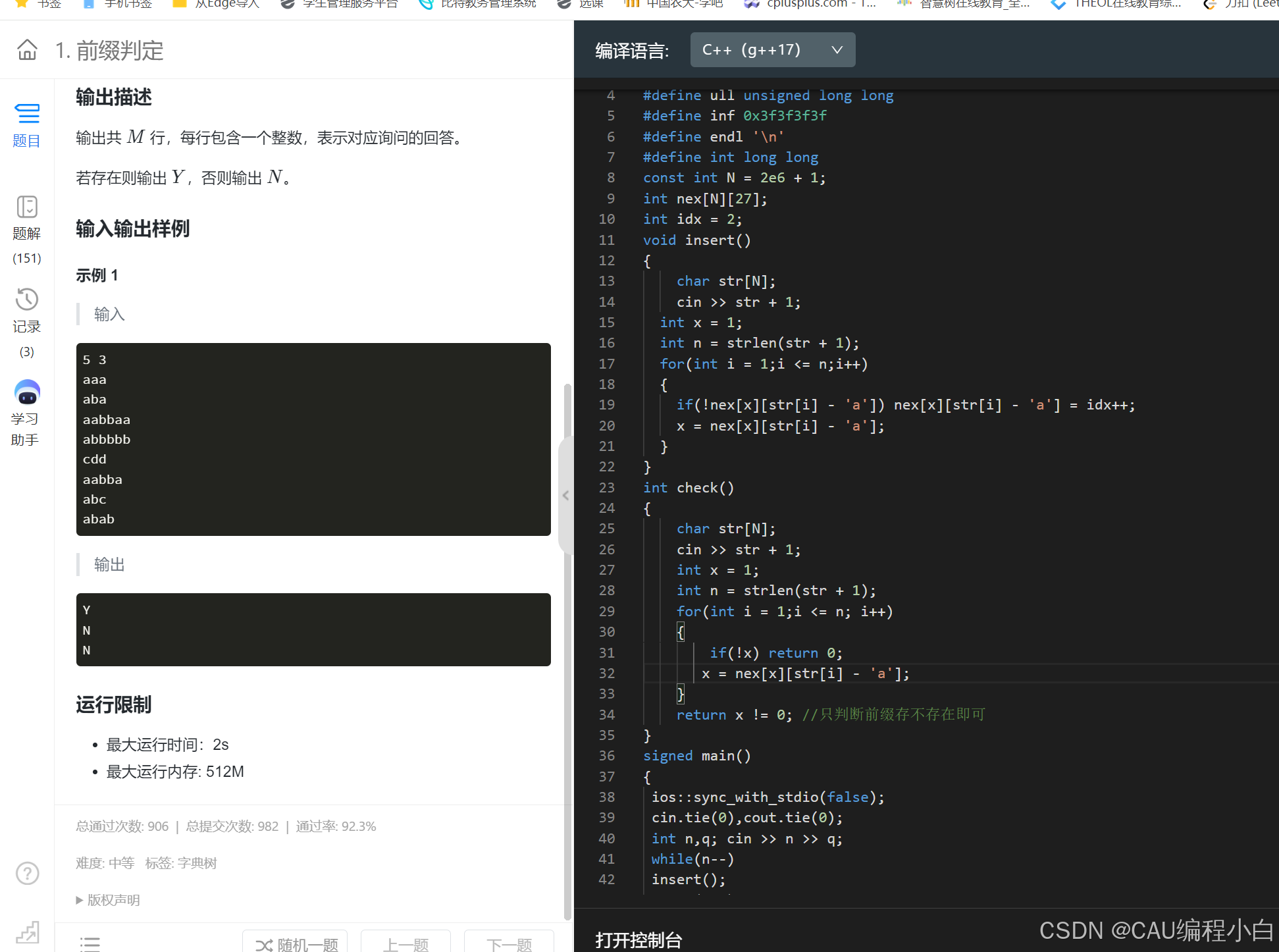
字典树
给N个字符串S1 到 Sn,查找t是否在这里出现过,朴素的查法就是遍历,比较是否相等,复杂度较高,下面引入更快的方法,字典树,叫做字典树,就是一颗树形结构,每一条边代表一个字符,每一个结点可以存储可以不存储,看具体的题干
模板:
(字典树用的不多,更多的是下面的01trie,主要放在后面重点的讲解)
//下面是利用字典树查找的代码
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
const int N = 1e6 + 1ll;
int nex[N][27]; //nex[i][0]表示从节点i出发,边为a的下一个节点地址
int cnt[N];//cnt[i]表示以节点i为结尾的字符串数量
int idx = 2;//记录结点
void insert(char s[])
{
int n = strlen(s + 1);
int x = 1; //从1开始往下走
//将每一个字符取出操作
for(int i = 1;i <= n;i++)
{
//不存在这一条边就去开一个边
if(!nex[x][s[i] - 'a']) nex[x][s[i]-'a'] = idx++;
//往下走
x = nex[x][s[i] - 'a'];
}
cnt[x]++;
}
int check(char s[])
{
int n = strlen(s + 1);
int x = 1;
for(int i = 1;i <= n; i++)
{
if(!x) return 0;
x = nex[x][s[i]-'a'];
}
return cnt[x];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
return 0;
}
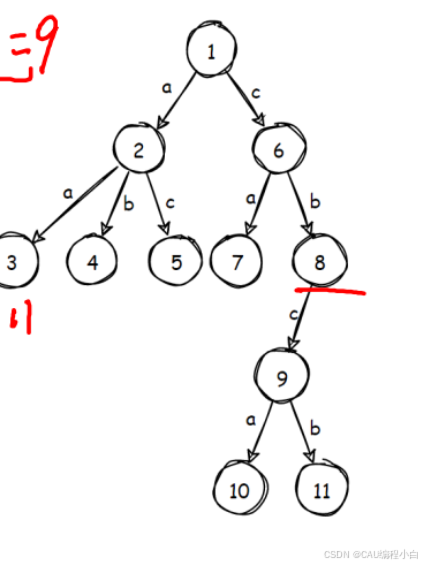
对nex数组不理解的来看这个图奥,nex[8][‘c’ - ‘a’] = 9;nex[1][‘a’ - ‘a’] = 2;这样基本就能看懂了
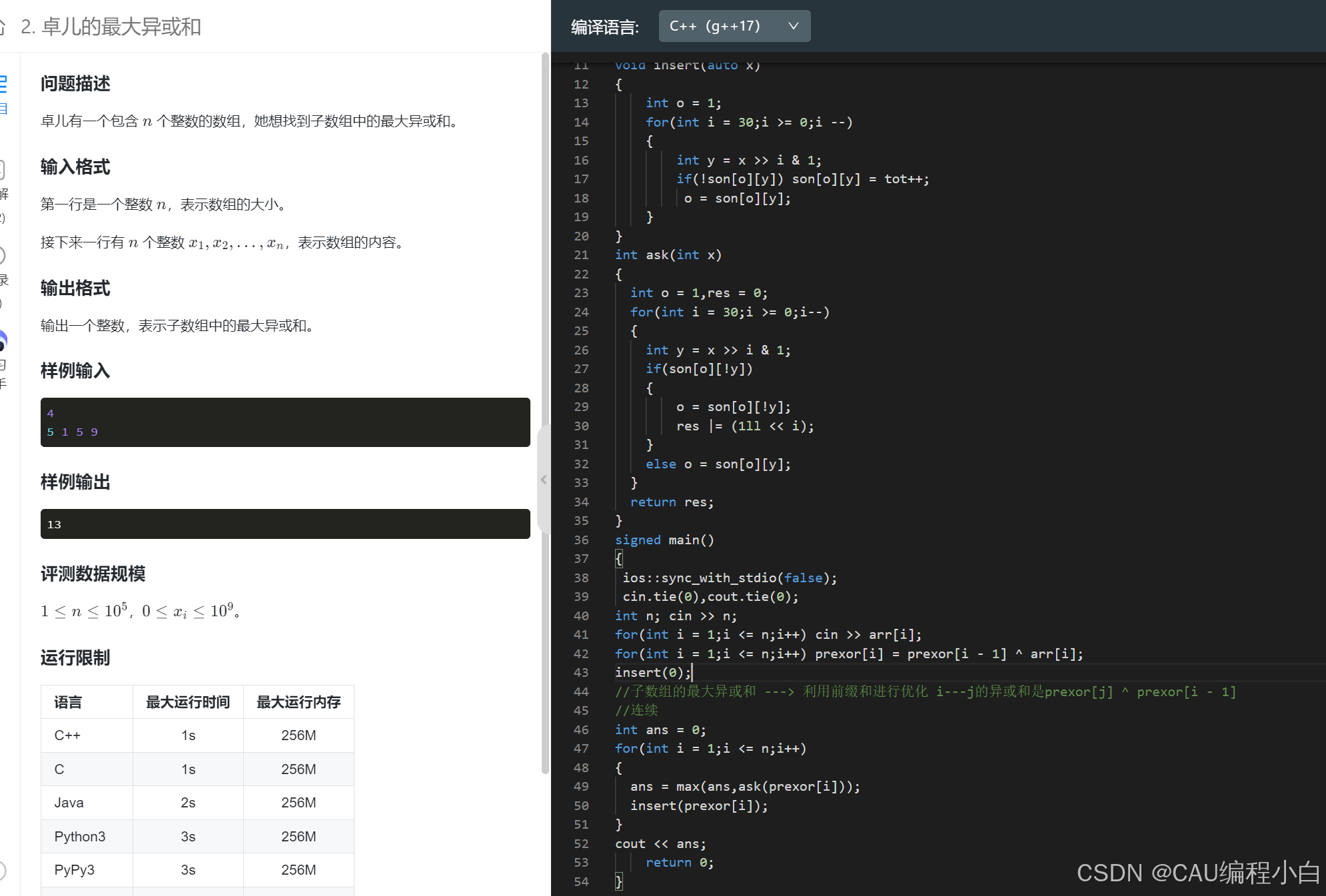
01trie树
是一种二叉树 每个叶子节点对应一个二进制数
解决最大异或对问题
01Trie树支持三种操作
插入
查询与x异或的最大的元素
查询比更大的元素的个数,可用于解决逆序对问题
有了字典树的模板,更好写这个了
///字典树
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
#define int long long
const int N = 1e6 + 1; //一般要开已有数据的30倍数
int son[N][2];
int e[N];
int iot = 1;
void insert(int x)
{
int o = 1;//表示节点编号
e[o]++;
for(int i = 30;i >= 0;--i)
{
int y = x >> i & 1; //第i位的值
if(!son[o][y]) son[o][y] = ++iot;
o = son[o][y];
e[o]++;
}
}
//查询Trie中与x异或的最大值
int checkmax(int x)
{
int res = 0,o = 1;
for(int i = 30;i >= 0;i --)
{
int y = x >> i & 1;
if(son[o][!y]) o = son[o][!y],res |= (1ll << i);
else o = son[o][y];
}
return res;
}
//查询最小值
int checkmin(int x)
{
int res = 0,o = 1;
for(int i = 30;i >= 0;i--)
{
int y = x >> i & 1;
if(son[o][y]) o = son[o][y];
else o = son[o][!y],res |= 1ll << i;
}
return res;
}
//比x大的数目
int bigcount(int x)
{
int res = 0,o = 1;
for(int i = 30;i >= 0;i--)
{
int y = x >> i & 1;
if(y == 0) res += e[son[o][1]];
if(!son[o][y])break;
o = son[o][y];
}
return res;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
return 0;
}
关于异或问题,一般会想到前缀和 / 按位运算 / 01trie树/ 线性基
关于线性基,详见OI wiki
这里我介绍的算法都不是详细的,有问题可以去OI wiki的官网,直接搜就能搜的到
例题:算法模板题(题目很简单,就不放链接了)
KMP 和 Hash
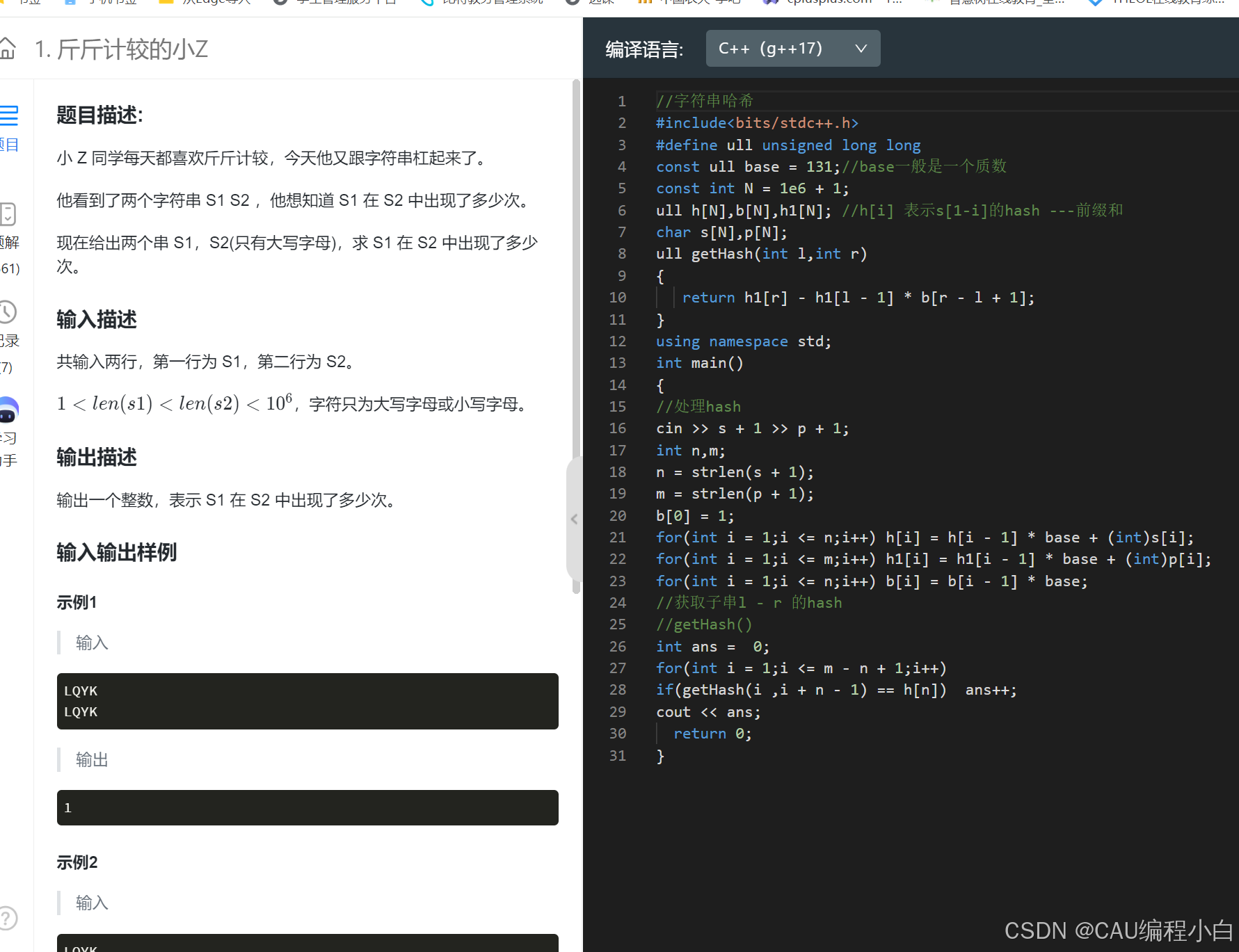
KMP定义
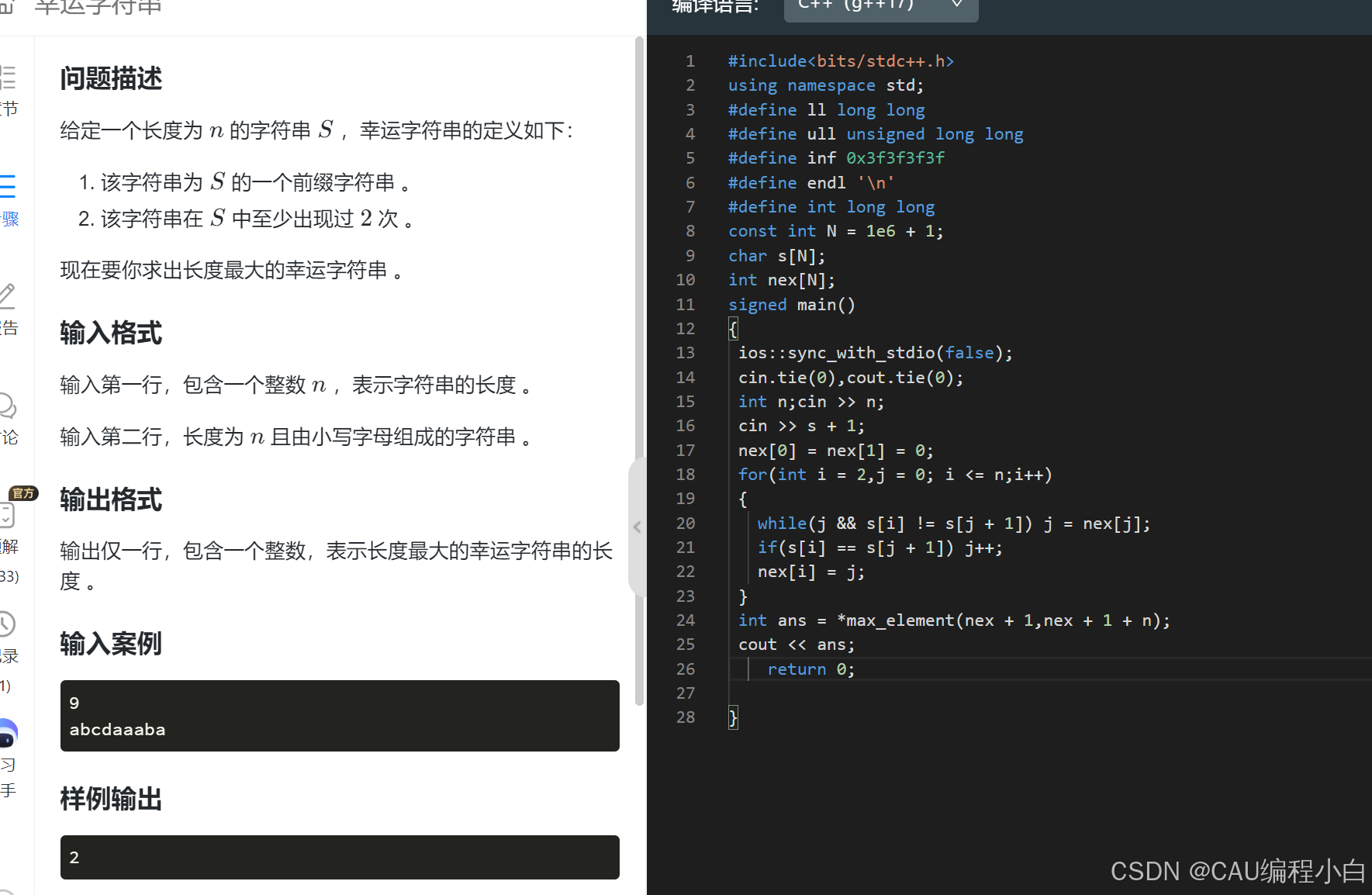
manacher
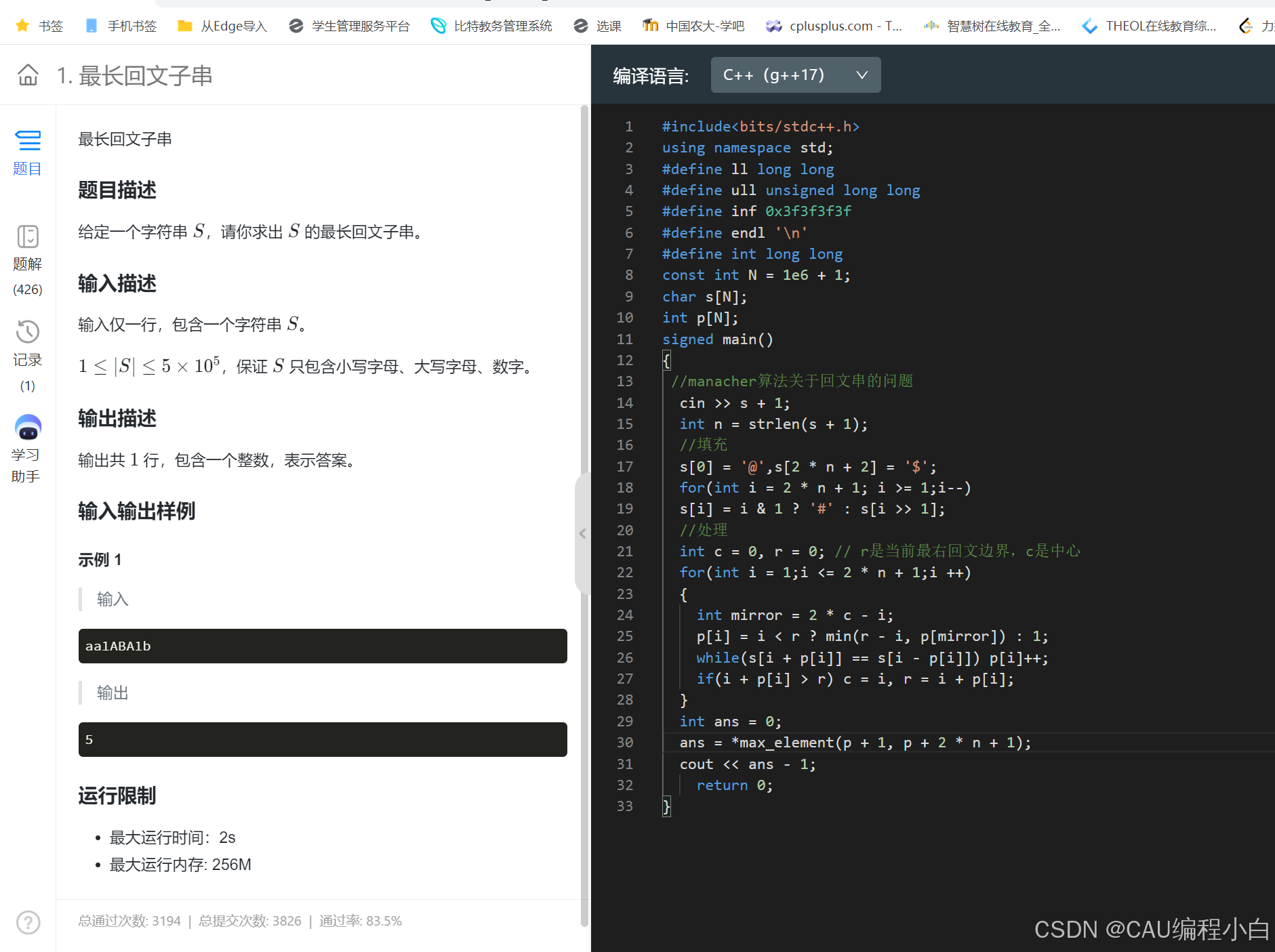
字典树
01trie树
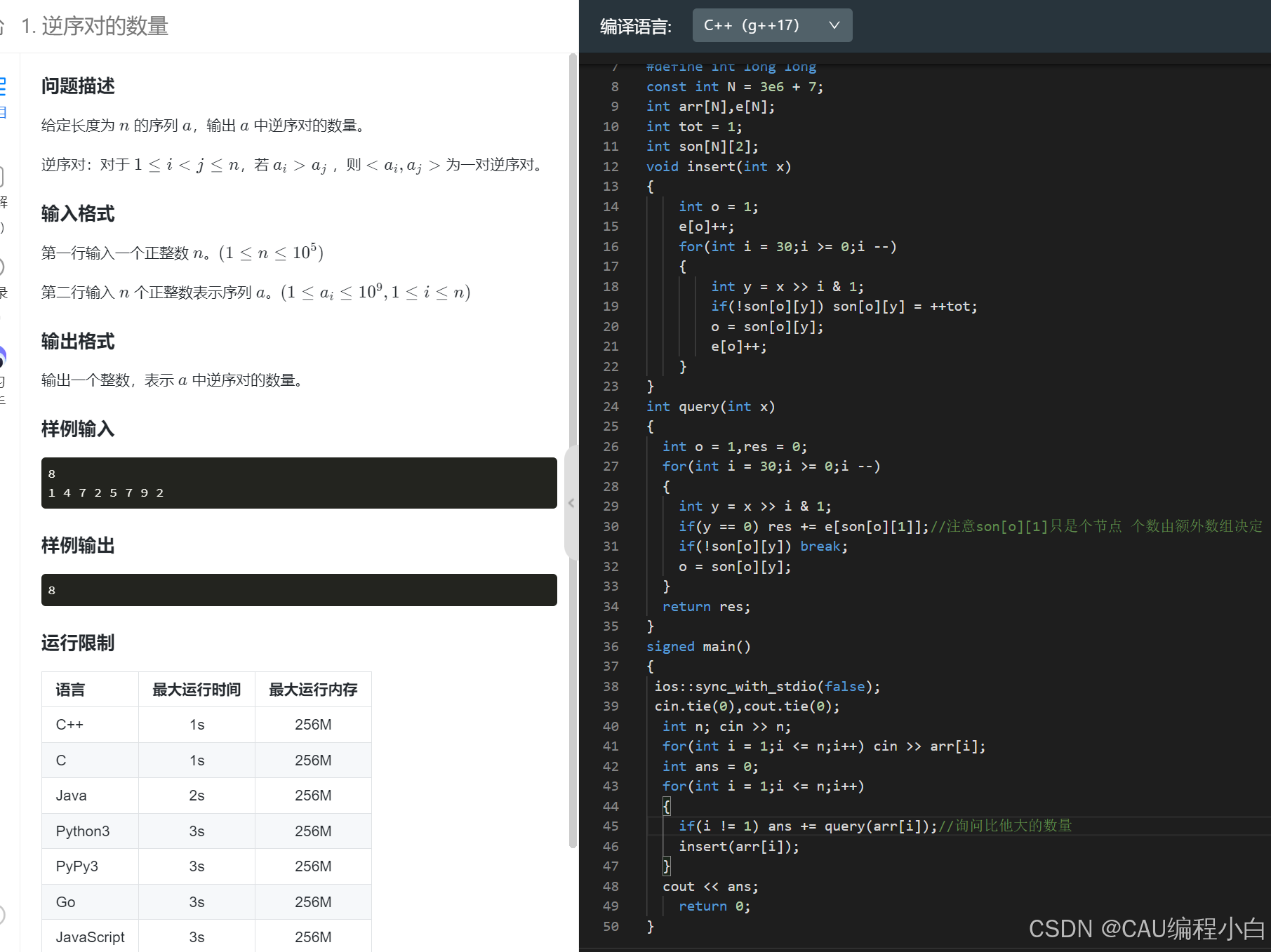
逆序对的数量这道题也可以使用树状数组来实现,等我讲到那个的吧
下面是一些有难度的题目
最大异或结点
链接
看上去像01,但是发现直接相连的不能这样取异或,所以要加入一个remove函数,每次要把相连的remove掉,但是还要记得复原
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
#define int long long
//思路 01tire写一个remove函数 修改边是不容易的,可以改权值
//将所有信息读入Trie中,对于每一个节点,移除掉与他有关的节点之后,取最大值,最后回溯,再将信息加进来
const int N = 3e6 + 1;
int son[N][2];
vector<int> v[N];//存放信息
int e[N];
int arr[N],fa[N];
int tot = 1;
void insert(int x)
{
int o = 1;
e[o]++;
for(int i = 30;i >= 0; i--)
{
int y = x >> i & 1;
if(!son[o][y]) son[o][y] = ++tot;
o = son[o][y];
e[o]++;
}
}
void remove(int x)
{
int o = 1;
e[o]--;
for(int i = 30;i >= 0; i--)
{
int y = x >> i & 1;
o = son[o][y];
e[o]--;
}
}
int query(int x)
{
int res = 0;
int o = 1;
for(int i = 30;i >= 0; i--)
{
int y = x >> i & 1;
if(son[o][!y] && e[son[o][!y]])
{
o = son[o][!y];
res |= (1ll << i);
}
else o = son[o][y];
}
return res;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
int n; cin >> n;
for(int i = 0;i < n;i ++) cin >> arr[i];
for(int i = 0;i < n;i++)
{
cin >> fa[i];
if(fa[i] != -1)
v[fa[i]].push_back(i - 1); //从0开始 v[0] 含有 1 3
// v[1] 含有2 4
}
for(int i = 0;i < n;i++) insert(arr[i]);
int ans = 0;
for(int i = 0;i < n;i++)
{
//移除 //arr[i]是当前的节点 移除掉所有与arr[i]相连的节点 v[i]中存放好了个数
//i - 1是当前节点 e + 1读入是 1 到 n 节点是0 到 n - 1;
for(auto e : v[i]) remove(arr[e]);
//计算
ans = max(ans,query(arr[i]));
//回溯
for(auto e : v[i]) insert(arr[e]);
}
cout << ans;
return 0;
}
串的前缀
串的前缀
利用并查集 + KMP
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 +10;
#define int long long
char s[N];
int n,ans;
int ne[N];
int find(int x)
{
if(!ne[x]) return x;
return ne[x] = find(ne[x]);
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
cin >> n >> s + 1;
for(int i = 2,j = 0;i <= n;i++)
{
while(j && s[i] != s[j + 1]) j = ne[j];
if(s[i] == s[j + 1]) j++;
ne[i] = j;
}
//i 1 2 3 4 5 6 7 8
//fin 1 2 1 2 1 2 1 2
//ans 0 0 2 2 4 4 6 6
//nex 0 0 1 2 3 4 5 6
for(int i = 2;i <= n;i++)
{
if(ne[i]) ans += i - find(i);
}
cout << ans << endl;
return 0;
}
你也喜欢幸运字符串吗
链接
dp数组的意义是dp[i]表示以0到i为前缀的个数
dp[nex[i]] = dp[nex[i]] + dp[i] //想一想就明白了,注意要倒着处理,因为nex数组
比如abcabc
dp[nex[6] = 3] += dp[6];
代码
```cpp
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
#define int long long
const int N = 1e6 + 1;
char s[N];
int nex[N];
int dp[N];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
int n; cin >> n;
cin >> s + 1;
for(int i = 2,j = 0;i <= n;i ++)
{
while(j && s[i] != s[j + 1]) j = nex[j];
if(s[i] == s[j + 1]) j++;
nex[i] = j;
}
for(int i = 1;i <= n;i++) dp[i] = 1;
for(int i = n;i >= 1;i--) dp[nex[i]] += dp[i]; //加入前缀
int ans = 0;
for(int i = 1;i <= n;i++) ans += dp[i];
cout << ans;
return 0;
}
异或和之差
链接
这个还是蛮恶心的
知道思路也写起来很费劲
就是对于每一个分割位置i,求出前面异或的最大 - 后面的最小 || 后面最大减去前面最小 记录四个数组开写。。。
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define ull unsigned long long
#define inf 0x3f3f3f3f
#define endl '\n'
#define int long long
const int N = 1e6 + 1;
int sonl[N][2],sonr[N][2];
int premax[N],premin[N];
int sufmax[N],sufmin[N],arr[N];
int prexor[N],sufxor[N];
int totl = 2;
void insert(int son[][2],int x)
{
int o = 1;
for(int i = 20;i >= 0;i --)
{
int y = x >> i & 1;
if(!son[o][y])
{
son[o][y] = totl++;
}
o = son[o][y];
}
}
int checkmax(int son[][2],int x)
{
int res = 0, o = 1;
for(int i = 20;i >=0; i --)
{
int y = x >> i & 1;
if(son[o][!y])
{
o = son[o][!y];
res |= 1ll << i;
}
else o = son[o][y];
}
return res;
}
int checkmin(int son[][2],int x)
{
int res = 0, o = 1;
for(int i = 20;i >= 0;i --)
{
int y = x >> i & 1;
if(son[o][y]) o = son[o][y];
else
{
o = son[o][!y];
res |= 1ll << i;
}
}
return res;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0),cout.tie(0);
int n; cin >> n;
for(int i = 1;i <= n;i++) cin >> arr[i];
insert(sonl,0);
insert(sonr,0);
for(int i = 0;i <= n + 1;i++)
{
premin[i] = sufmin[i] = inf;
}
for(int i = 1;i <= n;i++)
{
prexor[i] = prexor[i - 1] ^ arr[i];
premax[i] = max(premax[i - 1],checkmax(sonl,prexor[i]));
premin[i] = min(premin[i - 1],checkmin(sonl,prexor[i]));
insert(sonl,prexor[i]);
}
for(int i = n;i >= 1;i --)
{
sufxor[i] = sufxor[i + 1] ^ arr[i];
sufmax[i] = max(sufmax[i - 1],checkmax(sonr,sufxor[i]));
sufmin[i] = min(sufmin[i - 1],checkmin(sonr,sufxor[i]));
insert(sonr,sufxor[i]);
}
int ans = 0;
for(int i = 1;i < n;i ++)
{
ans = max(ans,max(sufmax[i + 1] - premin[i],premax[i] - sufmin[i + 1]));
}
cout << ans;
return 0;
}
到这吧,下次更新十三届A组真题 / 数论
求三连!!!!!

















 5437
5437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









