 HDFS 3.3.6 Federation联邦机制介绍与部署
HDFS 3.3.6 Federation联邦机制介绍与部署





1. Federation背景介绍
在大数据时代,随着数据量的爆炸式增长,Hadoop分布式文件系统(HDFS)面临着前所未有的扩展性挑战。传统的单一NameNode架构逐渐显露出性能瓶颈,举个例子,一般1GB内存放1,000,000 block元数据。200个节点的集群中每个节点有24TB存储空间,block大小为128MB,能存储大概4千万个block(200*24*1024*1024M/128 约为4千万或更多)。100万需要1G内存存储元数据,4千万大概需要40G内存存储元数据,假设节点数如果更多、存储数据更多的情况下,需要的内存也就越多。
通过以上例子可以看出,单NameNode的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode 成为了性能的瓶颈。这时该怎么办?元数据空间依然还是在不断增大,一味调高NameNode的JVM大小绝对不是一个持久的办法,这时候就诞生了 HDFS Federation 的机制。
1.1 传统架构的局限性
传统HDFS采用单一NameNode架构,所有元数据都存储在单个NameNode的内存中。这种架构存在两个主要问题:
- 内存限制:NameNode需要将所有文件系统的元数据(包括文件、目录、块信息)保存在内存中,随着数据量增长,内存成为瓶颈。
- 吞吐量限制:所有客户端请求都必须通过单个NameNode,导致其成为系统吞吐量的瓶颈。
1.2 联邦机制的原理
联邦机制通过引入多个NameNode来实现水平扩展,每个NameNode管理文件系统命名空间的一部分。这些NameNode相互独立,不需要相互协调。
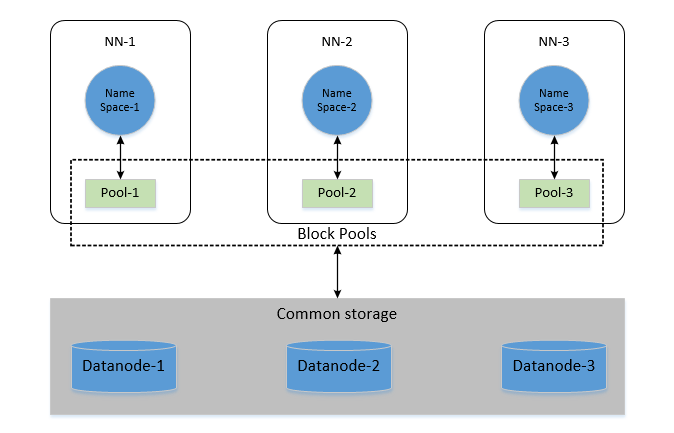
1.2.1 联邦机制的关键组件
- 多个NameNode:每个管理独立的命名空间
- 共享的DataNode池:所有DataNode为所有NameNode存储数据块
- BlockPool:每个NameNode在DataNode上有独立的数据块池
- 客户端挂载表:决定如何将路径映射到特定的NameNode
1.2.2 多个Namespace的路由规则配置
客户端挂载表(client.mount.table)是联邦机制中的关键配置,它定义了文件系统路径到特定NameNode的映射关系。通过这个表,客户端知道对于特定的路径应该访问哪个NameNode。
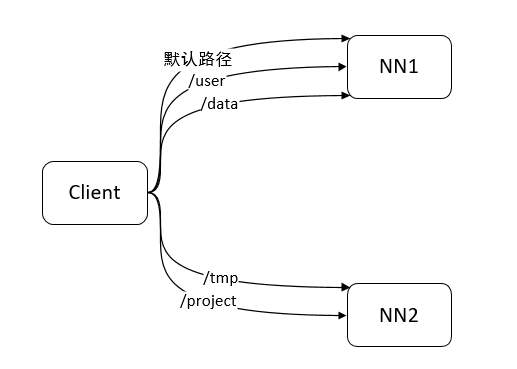
- 最长前缀匹配:客户端会寻找与路径匹配的最长前缀
- 默认命名空间:如果没有匹配项,则使用配置的默认命名空间
1.2.3 BlockPool与Namespace的映射关系
在联邦机制中,每个NameNode都有一个独立的BlockPool。BlockPool是DataNode上为特定NameNode存储数据块的逻辑分区。
- 独立性:每个BlockPool只属于一个Namespace
- 共享存储:所有BlockPool共享相同的DataNode物理存储
- 隔离性:一个Namespace的问题不会影响其他Namespace的数据
2. 联邦部署
之前我们部署过完全分布式集群,就不再赘述啦0.0,我们在此基础上进行改造;
链接在这里HDFS分布式部署![]() https://blog.csdn.net/weixin_62206215/article/details/150279539?spm=1011.2124.3001.6209
https://blog.csdn.net/weixin_62206215/article/details/150279539?spm=1011.2124.3001.6209
2.1 集群规划
| 节点 | NN1 | NN2 | NN1-SNN | NN2-SNN | DN |
| hadoop101 | √ | ||||
| hadoop102 | √ | ||||
| hadoop103 | √ | √ | |||
| hadoop104 | √ | √ | |||
| hadoop105 | √ |
2.2 部署
开始部署前,我们需要删除原集群上各节点的data,log目录
[root@hadoop101 data] rm -rf /data/hadoop
[root@hadoop101 data] rm -rf /opt/module/hadoop-3.3.6/logs2.2.1 配置core-site.xml
<configuration>
<!-- 指定HDFS文件系统访问URI -->
<property>
<name>fs.defaultFS</name>
<value>viewfs://ClusterX</value>
</property>
<!-- 将 /data 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./data</name>
<value>hdfs://hadoop101:8020/data</value>
</property>
<!-- 将 /project 目录挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./project</name>
<value>hdfs://hadoop101:8020/project</value>
</property>
<!-- 将 /user 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./user</name>
<value>hdfs://hadoop102:8020/user</value>
</property>
<!-- 将 /tmp 目录挂载到 viewfs 中,并通过NN2集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://hadoop102:8020/tmp</value>
</property>
<!-- 对于没有配置的路径存放在 /home目录并挂载到 viewfs 中,并通过NN1集群进行管理-->
<property>
<name>fs.viewfs.mounttable.ClusterX.linkFallback</name>
<value>hdfs://hadoop101:8020/home</value>
</property>
<!-- 指定 Hadoop 数据存放的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/federation</value>
</property>
</configuration> 2.2.2 配置hdfs-site.xml
<configuration>
<!-- block副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 两个NS -->
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<!-- NS1 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hadoop101:8020</value>
</property>
<!-- NS1 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>hadoop101:9870</value>
</property>
<!-- NS1 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns1</name>
<value>hadoop103:9868</value>
</property>
<!-- NS2 NameNode 地址和端口号-->
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hadoop102:8020</value>
</property>
<!-- NS2 NameNode WebUI访问地址-->
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>hadoop102:9870</value>
</property>
<!-- NS2 SecondaryNameNode WebUI访问地址-->
<property>
<name>dfs.namenode.secondary.http-address.ns2</name>
<value>hadoop104:9868</value>
</property>
</configuration>2.2.3 分发配置文件
[root@hadoop101 hadoop-3.3.6] xsync.sh ./etc/hadoop/core-site.xml
[root@hadoop101 hadoop-3.3.6] xsync.sh ./etc/hadoop/hdfs-site.xml 2.2.4 格式化集群
Hadoop Federation联邦集群搭建完成后需要对两个NameNode进行格式化,在格式化node1和node2上的namenode时候,需要指定clusterId,并且两个格式化的时候这个clusterId要一致,两个namenode具有相同的clusterId,它们在一个集群中,它们是联邦的关系。如下:
[root@hadoop101 hadoop-3.3.6] hdfs namenode -format -clusterId viewfs
[root@hadoop102 hadoop-3.3.6] hdfs namenode -format -clusterId viewfs2.2.5 启动集群
[root@hadoop102 hadoop-3.3.6] start-dfs.sh两个namenode节点都处于活跃状态
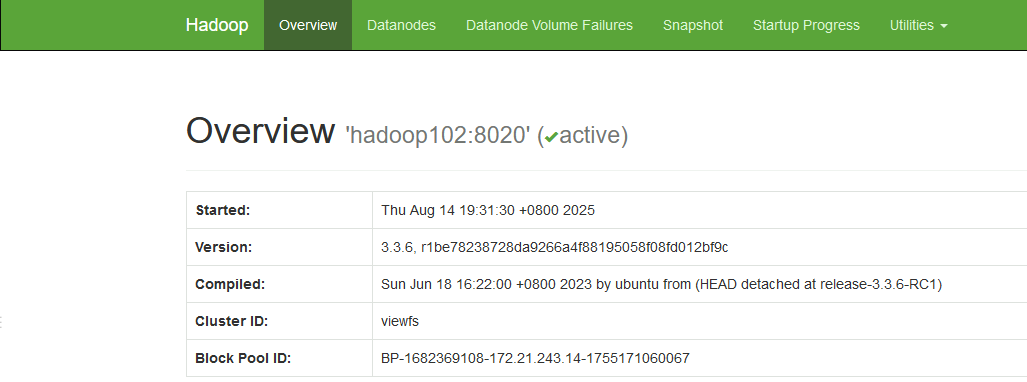
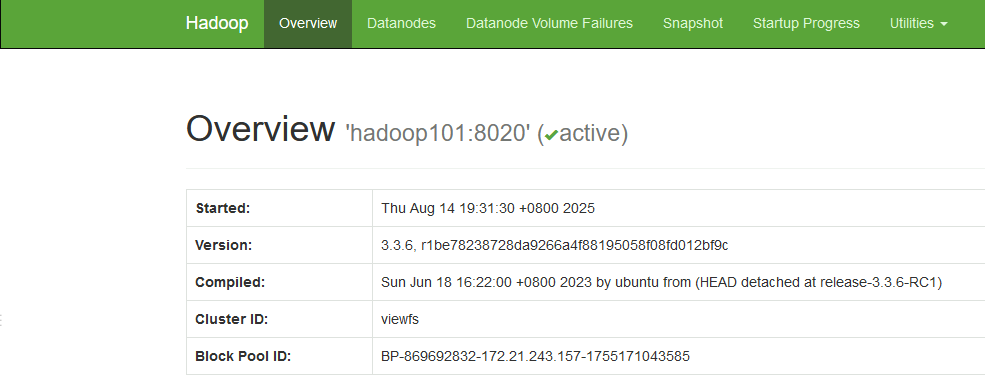
2.2.6 验证
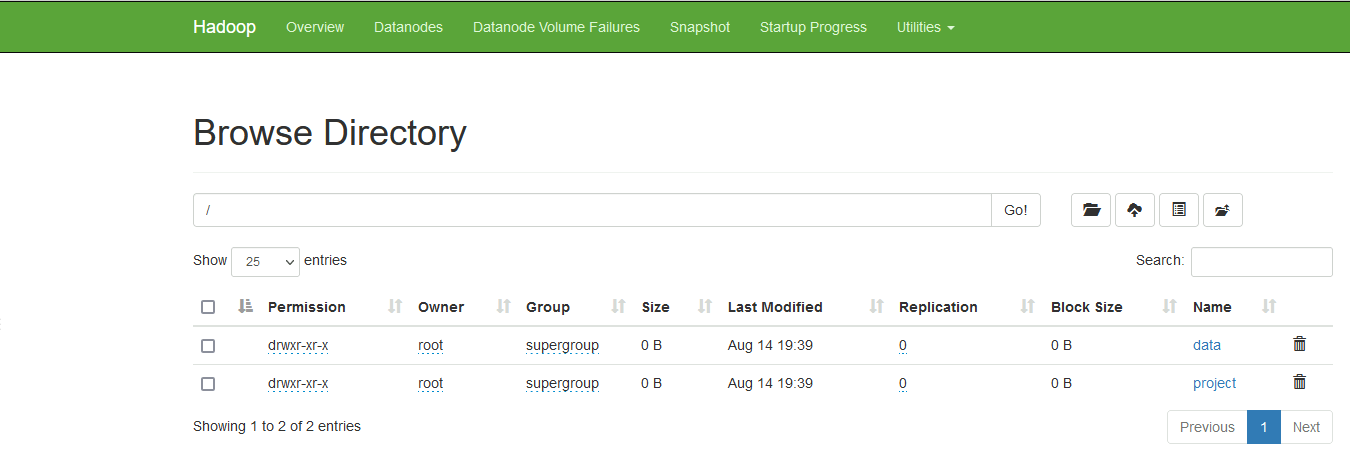
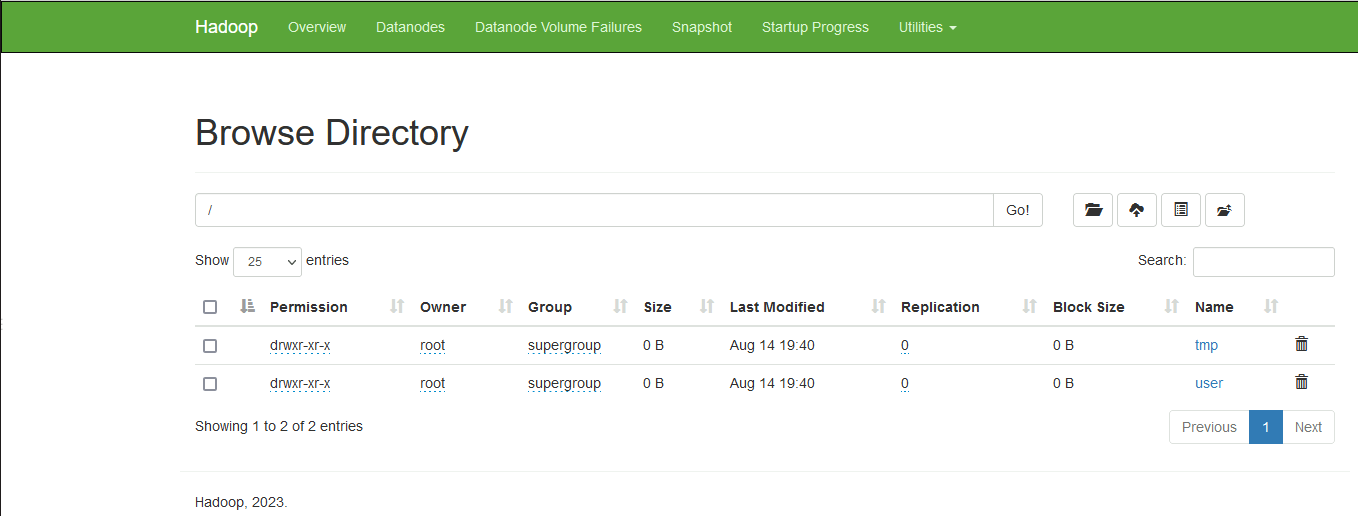
集群启动后需要在集群中创建好 /data 、/project、/user、/tmp目录。这个目录需要我们自己手动创建出来。
[root@hadoop101 hadoop-3.3.6] hdfs dfs -mkdir hdfs://hadoop101:8020/data
[root@hadoop101 hadoop-3.3.6] hdfs dfs -mkdir hdfs://hadoop101:8020/project
[root@hadoop101 hadoop-3.3.6] hdfs dfs -mkdir hdfs://hadoop102:8020/tmp
[root@hadoop101 hadoop-3.3.6] hdfs dfs -mkdir hdfs://hadoop102:8020/user观察结果
2.2.7 上传文件测试
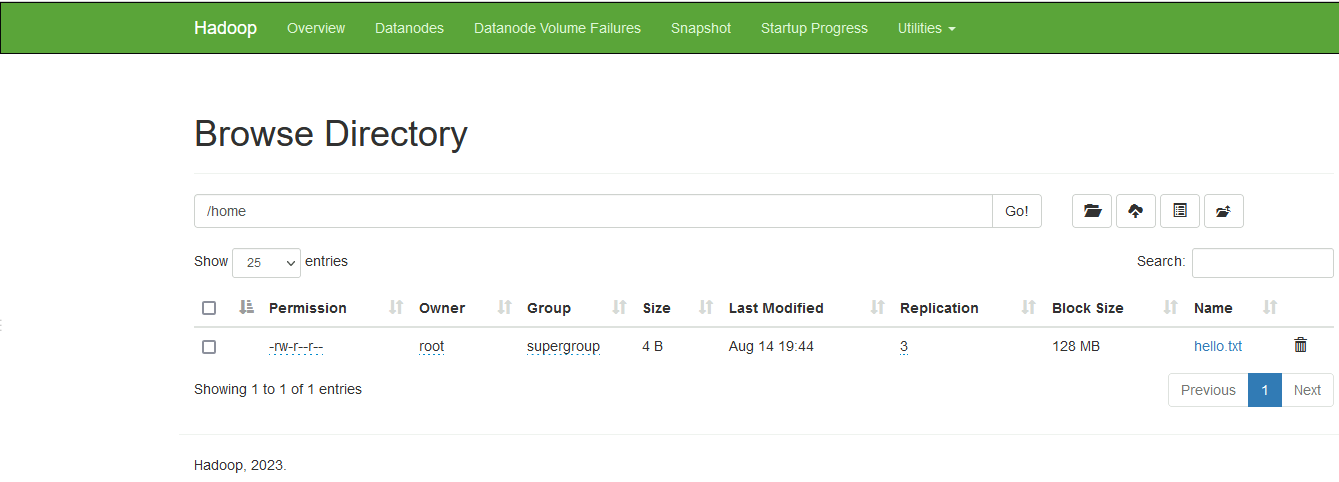
如果我们上传文件时,不指定目录
[root@hadoop101 home] hdfs dfs -put ./hello.txt /
hdfs会帮我们在NN1上,创建一个/home目录,把文件放在这个位置
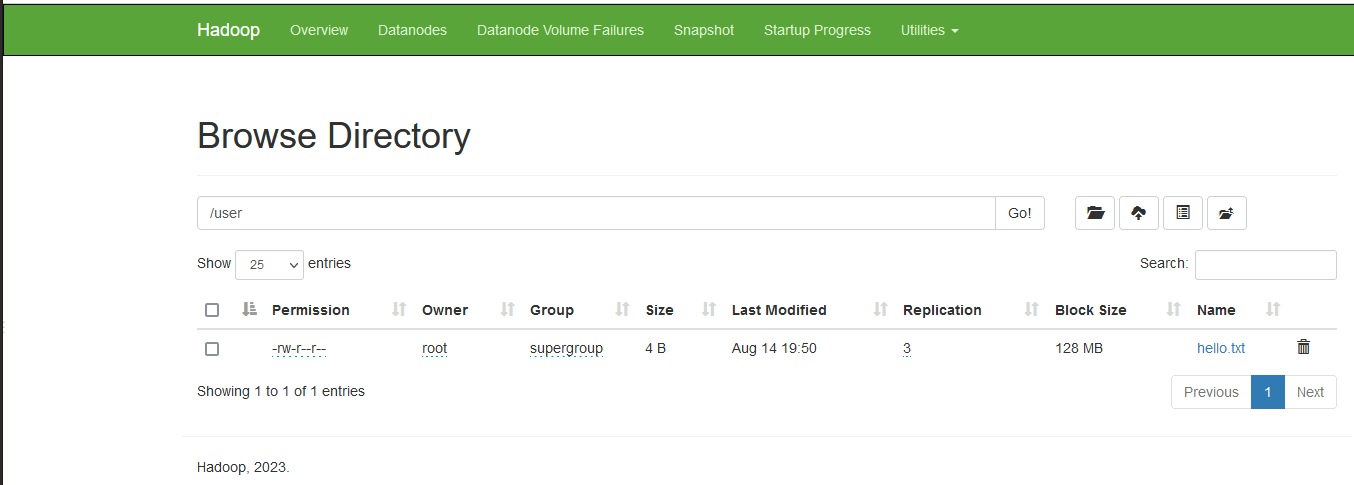
当我们上传文件到指定目录时
[root@hadoop101 home] hdfs dfs -put ./hello.txt /userhdfs会把文件上传到NN2节点上
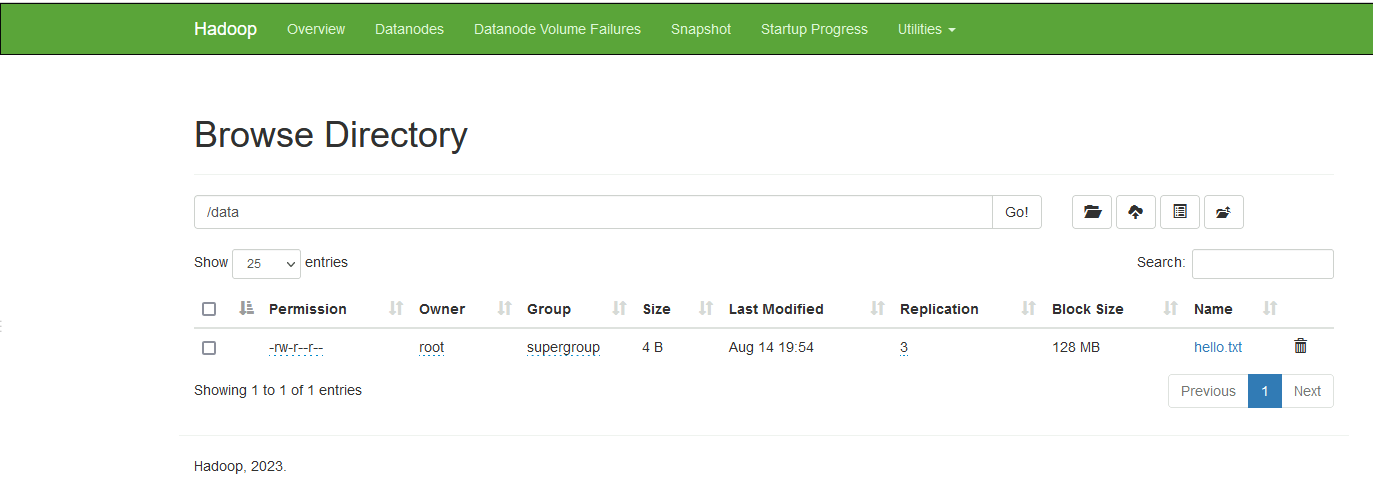
我们在NN2上创建一个/data目录
当我们向这个目录上传文件时,hdfs会根据配置文件提交到NN1上,而不是NN2
[root@hadoop101 home] hdfs dfs -put ./hello.txt /dataNN2
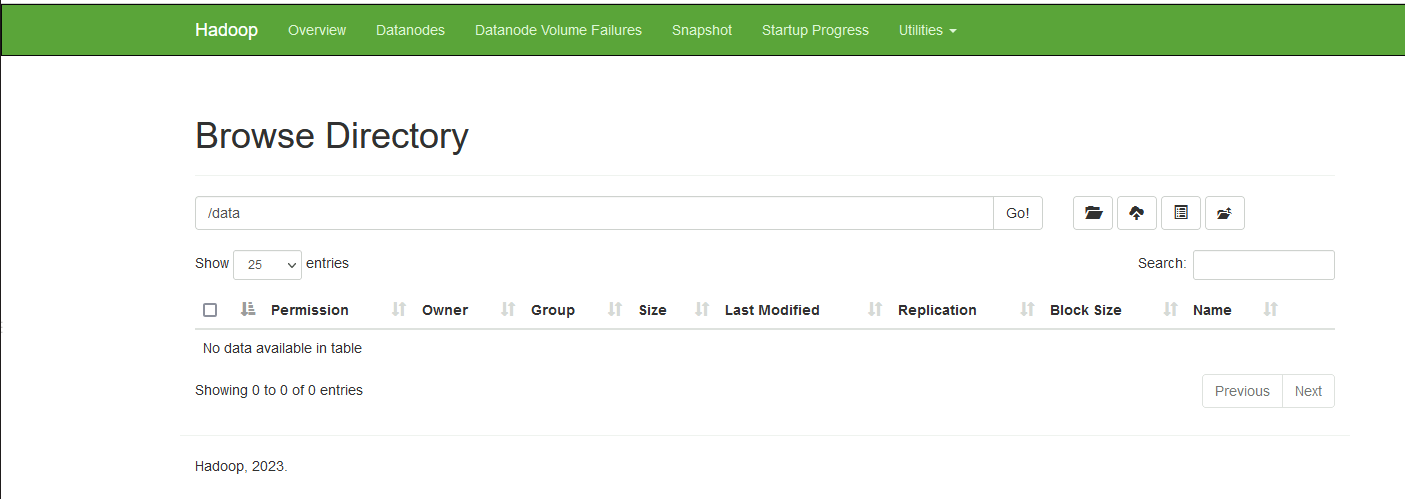
NN1
3. Federation问题
HDFS Federation 并没有完全解决单点故障问题。虽然 namenode/namespace 存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个 namenode 挂掉了,其管理的相应的文件便不可以访问。当然Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode 挂掉重启后,用于还原元数据信息,需要手动将挂掉的namenode重新启动。
所以一般集群规模真的很大的时候,会采用HA+Federation 的部署方案。也就是每个联合的namenodes都是HA(High Availablity - 高可用)的。后续将会为大家介绍。


















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









