






框架
实际是他人实现的一系列接口和类的集合。通入导入对应框架的jar文件(maven项目导入对应的依赖), 进行适当的配置,就能使用其中的所有内容。
Spring
一个轻量级开源的Java框架。是一个管理项目中对象的容器,同时也是其他框架的粘合器,目的就是对 项目进行解耦。
Spring的核心是IOC控制反转和AOP面向切面编程
IOC
Inversion Of Control 控制反转
DI
Dependency Injection 依赖注入
控制反转(IOC)是一种思想,就是让创建对象的控制权由自身交给第三方,控制反转这种思想,通 过依赖注入(DI)的方式实现。
IOC和DI其实都是在描述控制反转,IOC是思想,DI是具体实现方式。
bean标签常用属性
| 属性 | 作用 |
|---|---|
| class | 定义类的全限定名 |
| id | 定义对象的名称 |
| lazy-init | 是否为懒加载。默认值为false,在解析配置文件时就会创建对象。设置为true表示懒加载,只有在getBean()时才会创建对象。 |
| scope | 单例/原型模式。默认值为singleton,表示单例模式,只会创建一个对象。设置为prototype,表示原型模式,每调getBean()就创建一个对象。 |
| init-method | 初始化时触发的方法。在创建完该对象时自动调用的方法。该方法只能是无参方法,该属性的值只需要写方法名即可 |
| destory-method | 销毁时触发的方法。Spring容器关闭时自动调用的方法,该方法只能是无参方法。只有在单例模式下有效。 |
属性注入
给某个bean添加属性的方式有两种:构造器注入和setter注入
setter注入
这种方式注入属性时,类中必须要有set方法
在bean标签中,加入<property></property>标签,
该标签的name属性通常表示该对象的某个属性名,但实际是setXXX()方法中的XXX单词。
如有age属性,但get方法为getNianLing(),name属性就需要写成nianLing。
该标签的value属性表示给该类中的某个属性赋值,该属性的类型为原始类型或String。
该标签的ref属性表示给该类中除String以外的引用类型属性赋值,值为Spring容器中另一个bean的id。
<!--注入Car类对象并用set方式注入其属性-->
<bean class="com.hqyj.spring01.Car" id="c">
<!--该属性是字符串或原始类型,使用value赋值-->
<property name="brand" value="宝马"></property>
<!--name并不是类中是属性名,而是该属性对应的getXXX()方法中XXX的名称-->
<!--如Car类中有color属性,但get方法名为getColo(),这里就要写为colo-->
<property name="colo" value="白色"></property>
</bean>
<!--注入Person类对象并用set方式注入其属性-->
<bean class="com.hqyj.spring01.Person" id="p1">
<property name="name" value="王海"></property>
<property name="age" value="22"></property>
<!--属性是引用类型,需要通过ref赋值,值为另外的bean的id ref即references-->
<property name="car" ref="c"></property>
</bean>构造方法注入
这种方式注入属性时,类中必须要有相应的构造方法
在bean标签中,加入<constructor-arg></constructor-arg>标签,
该标签的name属性表示构造方法的参数名,index属性表示构造方法的参数索引。
赋值时,原始类型和字符串用value,引用类型用ref。
<!--注入Person类对象并用构造方法注入其属性-->
<bean class="com.hqyj.spring01.Person" id="p2">
<!--constructor-arg表示构造方法参数 name是参数名 index是参数索引-->
<constructor-arg name="name" value="张明"></constructor-arg>
<constructor-arg index="1" value="20"></constructor-arg>
<constructor-arg name="car" ref="c"></constructor-arg>
</bean>Spring核心注解
在Spring配置文件中加入
<!--设置要扫描的包,扫描这个包下所有使用了注解的类-->
<context:component-scan base-package="com.hqyj.spring02.bookSystem"></context:component-scan>类上加的注解
- @Component
- 当一个类不好归纳时,定义为普通组件
- @Controller
- 定义一个类为控制层组件
- @Service
- 定义一个类为业务层组件
- @Repository
- 定义一个类为持久层(数组访问层)组件
- @Lazy/@Lazy(value=true)
- 设置该类为懒加载。
- @Scope(value="singleton/prototype")
- 设置为单例/原型模式。
在Web项目中使用Spring
1.创建基于Maven的web-app项目
2.添加依赖
<!--servlet-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
<!--spring容器-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.23</version>
</dependency>
<!--web集成spring-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.3.23</version>
</dependency>3.在main目录下创建java和resources目录,修改web.xml版本为4.0
4.在resources目录下创建Spring配置文件application.xml,扫描使用了注解的根包
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!--扫描使用了Spring注解的根包-->
<context:component-scan base-package="com.hqyj.springweb"></context:component-scan>
</beans>如何初始化Spring容器(解析Spring配置文件)
在控制台应用程序中,可以在main方法中通过ClassPathXmlApplicationContext来解析Spring配置文件,初始化Spring容器。
在web项目中没有main方法,只有servlet中的service方法,如果在service方法中创建ClassPathXmlApplicationContext对象,会每次访问都执行。
而Spring容器只需初始化一次,在项目启动时就解析Spring配置文件,全局监听器就是一个很好的选择。
spring-web包中提供了一个ContextLoaderListener类,它实现了ServletContextListener,属于项目级别的全局监听器。
这个类需要一个contextConfigLocation参数,表示要解析的Spring配置文件的路径。
这个监听器会在项目启动时,读取指定的Spring配置文件路径,并且创建WebApplicationContext对象,即Spring容器。
6.在web.xml中配置监听器用于初始化Spring容器
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!--配置监听器ContextLoaderListener-->
<listener>
<!--监听器全限定名-->
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!--定义全局参数contextConfigLocation用于读取Spring配置文件-->
<context-param>
<!--参数名固定contextConfigLocation-->
<param-name>contextConfigLocation</param-name>
<!--只是Spring配置文件的路径 classpath:表示从根目录出发-->
<param-value>classpath:application.xml</param-value>
</context-param>
</web-app>7.创建一个Servlet,访问该Servlet,获取Spring容器,从容器中获取注入的对象
package com.hqyj.springweb.controller;
import com.hqyj.springweb.entity.Pojo;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.support.WebApplicationContextUtils;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebServlet("/hello")
public class MyServlet extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//获取Spring容器
WebApplicationContext app = WebApplicationContextUtils.getWebApplicationContext(getServletContext());
//从容器中获取某个bean
Pojo pojo = app.getBean("pojo", Pojo.class);
pojo.fun();
}
}JDBCTemplate常用方法
| 方法 | 作用 | 说明 |
|---|---|---|
| query(String sql,RowMapper mapper) | 无条件查询 | 返回值为List集合 |
| update(String sql) | 无条件更新(删除、修改) | 返回值为受影响的行数 |
| query(String sql,RowMapper mapper,Object... objs) | 条件查询 | 可变参数为?的值 |
| update(String sql,Object... objs) | 条件更新(增加、删除、修改) | 可变参数为?的值 |
| queryForObject(String sql,RowMapper mapper) | 无条件查询单个对象 | 返回值为指定对象 |
| queryForObject(String sql,RowMapper mapper,Object... objs) | 条件查询单个对象 | 返回值为指定对象 |
| execute(String sql) | 执行指定的sql | 无返回值 |
AOP
概念
Process Oriented Programming 面向过程编程POP
Object Oriented Programming 面向对象编程OOP
Aspect Oriented Programming 面向切面编程AOP
以上都是编程思想,但AOP不是OOP和POP的替代,而是增强、拓展和延伸。主流编程思想依然是OOP。
作用
简单来说,就是将不同位置中重复出现的一些事情拦截到一处进行统一处理。
MVC
MVC设计思想并不是某个语言特有的设计思想,而是一种通用的模式。
是将一个应用分为三个组成部分:Model模型,View视图,Controller控制器
这样会降低系统的耦合度,提高它的可扩展性和维护性。
SpringMVC
在Web阶段中,控制层是由Servlet实现,传统的Servlet,需要创建、重写方法、配置映射。使用时极不方便,SpringMVC可以替换Servlet。
SpringMVC是Spring框架中位于Web开发中的一个模块,是Spring基于MVC设计模式设计的轻量级Web框架。
SpringMVC提供了一个DispatcherServlet的类,是一个Servlet。它在指定映射(通常设置为/或*.do)接收某个请求后,调用相应的模型处理得到结果,再通过视图解析器,跳转到指定页面,将结果进行渲染。
原理大致为:配置SpringMVC中的DispatcherServlet,将其映射设置为/或.do。*
如果是/表示一切请求先经过它,如果是*.do表示以.do结尾的请求先经过它,
它对该请求进行解析,指定某个Controller中的某个方法,这些方法通常返回一个字符串,
这个字符串是一个页面的名称,再通过视图解析器,将该字符串解析为某个视图的名称,跳转到该视图页面。
SpringMVC相关注解
- @Controller
- 只能写在类上,表示该类属于一个控制器
- @RequestMapping("/请求映射名")/@RequestMapping(value="/请求映射名")/@RequestMapping(path="/请求映射名")
- 该注解可以写在类或方法上。写在类上用于区分功能模块,写在类上用于区分具体功能
- 默认写一个属性或value或path后的值,都表示访问该类或该方法时的请求映射
- @RequestMapping(value="/请求映射名",method=RequestMethod.GET/POST/PUT/DELETE)
- method属性表示使用哪种请求方式访问该类或该方法
- 如果注解中不止一个属性,每个属性都需要指定属性名
- **@GetMapping("/请求映射名")**相当于@RequestMapping(value="/请求映射名",method=RequestMethod.GET)
- post、put、delete同理
- @GetMapping只能写在方法上
- @PathVariable
- 该注解写在某个方法的某个形参上
- 通常配合@RequestMapping("/{path}")获取请求时传递的参数
@RequestMapping("/{path}") public String fun(@PathVariable("path") String pageName){ return pageName; } //当前方法如果通过"localhost:8080/项目名/hello"访问,就会跳转到hello.jsp //当前方法如果通过"localhost:8080/项目名/error"访问,就会跳转到error.jsp //映射中的/{path}就是获取路径中的hello或error,将其赋值给形参 //通常用于跳转指定页面
- @RequestParam(value="传递的参数名",defaultValue ="没有传递参数时的默认值")
- 该注解写在某个方法的某个参数上
- 用于获取提交的数据,可以设置默认值在没有提交数据时使用
SSM项目中使用Ajax
ajax依赖于jquery,所以先保证页面中存在jquery.js。
$.ajax({
url:"访问地址",
data:{
"提交的参数名":"实际值",
"提交的参数名":"实际值"
},
type:"get/post",
success:function(res){
//成功后的回调函数,res为访问后的结果,必须是json格式
}
});
在前端页面中使用ajax访问controller时,controller的返回值必须是一个JSON格式的字符串。
所以controller中的方法上要加入@ResponseBody注解
拦截器
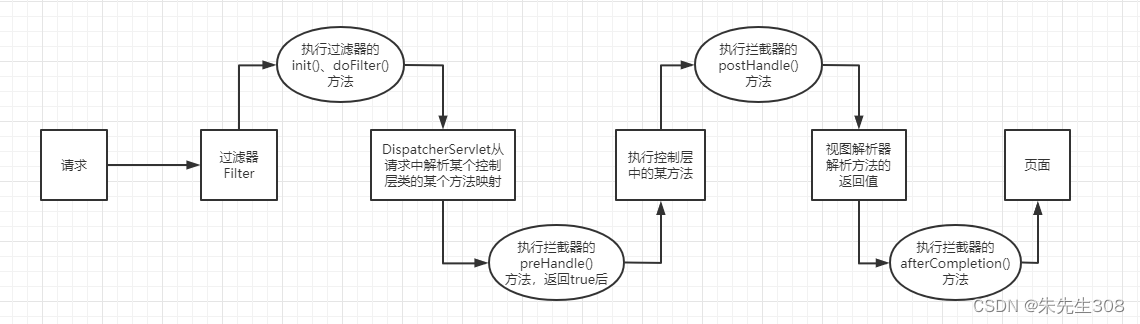
每次请求controller时,都要经过的一个类。
当一个项目中有过滤器、拦截器和controller时的执行流程
拦截器
每次请求controller时,都要经过的一个类。
当一个项目中有过滤器、拦截器和controller时的执行流程
SpringBoot
Spring推出的一个Spring框架的脚手架。
不是一个新的框架,而是搭建Spring相关内容框架的平台。
它省去了Spring、SpringMVC项目繁琐的配置过程,让开发变得更加简单。
本质还是Spring+SpringMVC,可以搭配其他的ORM框架,如MyBatis、MyBatisPlus、JPA、Hibernate等。
特点
- 内置了Tomcat服务器,不需要部署项目到Tomcat中
- 内置了数据源Hikari
- 减少了jar文件依赖的配置
- SpringBoot中的配置文件可以使用yml格式文件,代替properties或xml
MyBatisPlus
MyBatis-Plus (简称 MP)是一个MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
只需简单的配置,就能实现对单表的CURD。
其核心有两个接口:BaseMapper和IService
BaseMapper中封装了大量数据访问层的方法
IServcie中封装了大量业务流程层的方法
BaseMapper接口中的常用方法
| 方法名 | 参数 | 作用 |
|---|---|---|
| selectList(Wrapper wrapper) | 条件构造器 | 根据条件查询集合,如果实参为null表示查询所有,返回List集合 |
| selectById(Serializable id) | 主键 | 根据主键查询单个对象,返回单个对象 |
| selectOne(Wrapper wrapper) | 条件构造器 | 条件查询单个对象,返回单个对象 |
| insert(T entity) | 实体对象 | 添加单个实体 |
| updateById(T entity) | 实体对象 | 根据实体对象单个修改,对象必须至少有一个属性和主键 |
| update(T entity,Wrapper wrapper) | 实体对象和条件构造器 | 根据条件修改全部,对象必须至少有一个属性 |
| deleteById(Serializable id/T entity) | 主键/实体对象 | 根据主键删除单个对象 |
| deleteBatchIds(Collection ids) | 主键集合 | 根据集合删除 |
| delete(Wrapper wrapper) | 条件构造器 | 根据条件删除,如果实参为null表示无条件删除所有 |
IService接口中的常用方法
| 方法 | 作用 |
|---|---|
| list() | 无条件查询所有 |
| list(Wrapper wrapper) | 条件查询素有 |
| page(Page page) | 无条件分页查询,Page是分页模型对象 |
| page(Page page,Wrapper wrapper) | 条件分页查询,Page是分页模型对象 |
| getById(Serializable id) | 根据主键查询单个对象 |
| getOne(Wrapper wrapper) | 条件查询单个对象 |
| save(T entity) | 添加单个对象 |
| save(Collection col) | 批量添加对象的集合 |
| updateById(T entity) | 修改,参数至少有一个属性值和主键 |
| saveOrUpdate(T entity) | 添加或修改。如果实参对象的主键值不存在则添加,存在则修改 |
| update(T entity,Wrapper wrapper) | 条件修改,条件为null则修改全部数据 |
| removeById(Serializable id/T entity) | 根据主键或包含主键的对象删除 |
| removeBatchByIds(Collection ids) | 根据集合删除 |
| remove(Wrapper wrapper) | 根据条件删除,条件为null则删除全部 |
MyBatisPlus关联查询
原理
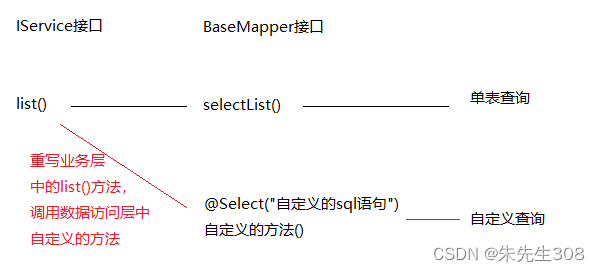
如果直接通过IService接口中的list()方法查询,实际调用的是BaseMapper接口中的selectList()方法,默认查询自身表。
如果重写业务层中的list()方法,或在业务层中自定义一个方法,让其调用数据访问层中自定义的某个方法,重新定制sql语句,就能得到想要的数据
Spring Data JPA
2001年推出了Hibernate,是一个全自动ORM框架。可以不用编写SQL语句,就能实现对数据库的持久化操作。
SUN公司在Hibernate的基础上,制定了JPA,全称 Java Persisitence API,中文名Java持久化API,
是一套Java访问数据库的规范,由一系列接口和抽象类构成。
后来Spring团队在SUN公司制定的JPA这套规范下,推出了Spring Data JPA,是JPA的具体实现。
如今常说的JPA,通常指Spring Data JPA。
创建实体类
- 类上加**@Entity**注解
- 主键属性上加
- @Id注解标明主键
- **@GeneratedValue(strategy = GenerationType.IDENTITY)**设置MySQL数据库主键生成策略,数据库设置为自增
- 其他属性名与字段名一致或驼峰命名法
- 如果字段名多个单词之间用_,使用驼峰命名法
- 如果不相同,使用**@Column(name="字段名")**注解指定该属性对应的字段名
@Data
@Entity
/*
* 实体类的属性名建议使用驼峰命名法
* */
public class BookInfo {
@Id//主键字段
//主键生成策略,GenerationType.IDENTITY表示MySQL自增
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer bookId;
private Integer typeId;
private String bookName;
private String bookAuthor;
//如果字段名和属性名不一致,使用@Column指定字段名
@Column(name = "book_price")
private Integer price;
private Integer bookNum;
private String publisher_date;
}JPA进阶
分页查询
调用数据访问层中的**findAll(Pageable pageable)**方法,即可实现分页。
参数Pageable是org.springframework.data.domain包中的一个接口,通过其实现类
PageRequest,调用静态方法**of(int page,int size)**,当做Pageable对象使用。
这里的page从0开始为第一页。
@Test
void queryByPage(){
//PageRequest是Pageable的实现类,调用静态方法of(int page,int size)
//这里的page的值0表示第一页
//调用findAll(Pageable pageable)方法,返回分页模型对象
Page<BookInfo> pageInfo = bookInfoDao.findAll(PageRequest.of(0,5));
//分页相关数据
System.out.println("总记录数"+pageInfo.getTotalElements());
System.out.println("最大页数"+pageInfo.getTotalPages());
System.out.println("分页后的数据集合"+pageInfo.getContent());
System.out.println("当前页数"+pageInfo.getNumber());
System.out.println("每页显示的记录数"+pageInfo.getSize());
System.out.println("是否还有下一页"+pageInfo.hasNext());
System.out.println("是否还有上一页"+pageInfo.hasPrevious());
}
条件查询
在JPA中,使用自定义方法名自动生成对应的SQL语句,实现条件查询。
如在dao中定义了queryById(int id)方法,就表示根据id查询,自动生成sql语句。
方法命名格式
[xxx] [By] [字段对应的属性名] [规则] [Or/And] [字段对应的属性名] [规则] ...
- **xxx可以是find、get、query、search
- 方法如果有参数,参数的顺序和方法名中的参数顺序一致
如findByBookNameAndBookAuthor(String bookName,String bookAuthor),
对应的sql语句为 select * from book where book_name =? and book_author=?
常用规则
| 规则 | 方法名 | SQL中的条件 |
|---|---|---|
| 指定值 | findByBookName(String name) | book_name = name |
| Or/And | findByBookNameOrBookAuthor(String name,String author) | book_name = name or book_author = author |
| After/Befor | findByBookPriceAfter(double price) | book_price > price |
| GreaterThanEqual/LessThanEqual | findByBookNumLessThanEqual(int num) | book_num <= num |
| Between | findByBookNumBetween(int min,int max) | book_num between min and max |
| Is[Not]Null | findByPublisherDateIsNull() | publish_date is null |
| [Not]Like | findByBookNameLike(String condition) | book_name like 'condition' |
| [Not]Contains | findByBookNameContains(String keyword) | book_name like '%keyword%' |
| StartsWith/EndsWith | findByBookNameStartsWith(String firstName) | book_name like 'firstName%' |
| 无条件排序:findAllByOrderBy字段[Desc/Asc] | findAllByOrderByBookId() | order by book_id asc |
| 有条件排序:findAllBy条件OrderBy字段[Desc/Asc] | findAllByTypeIdOrderByBookIdDesc() | type_id = ? order by book_id desc |
@Repository
public interface BookInfoDao extends JpaRepository<BookInfo,Integer> {
//指定值查询
//根据书名查询
List<BookInfo> getAllByBookName(String x);
//查询价格大于指定值 字段对应的属性名 After/GreaterThan
List<BookInfo> findAllByPriceAfter(int price);
//查询价格小于于指定值 字段对应的属性名 Before/LessThan
List<BookInfo> findAllByPriceLessThan(int price);
//查询库存大于等于指定值 GreaterThanEqual
List<BookInfo> queryAllByBookNumGreaterThanEqual(int num);
//查询库存在指定闭区间内 Between(int min,int max)
List<BookInfo> findAllByBookNumBetween(int min,int max);
//空值查询 null
//查询出版日期为空 IsNull/IsNotNull
List<BookInfo> findAllByPublisherDateIsNull();
//书名中带有关键字 Like/NotLike 实参一定要使用%或_
List<BookInfo> getAllByBookNameLike(String keyword);
//作者名中带有关键字 Contains/NotContains 实参只需要关键字
List<BookInfo> getAllByBookAuthorContains(String keyword);
//指定作者的姓 指定开头/结尾 StartsWith/EndsWith
List<BookInfo> getAllByBookAuthorStartsWith(String keyword);
//查询所有数据,按价格降序 无条件排序 OrderBy字段[Desc/Asc]
List<BookInfo> getAllByOrderByPriceDesc();
//查询指定类型,按id降序
List<BookInfo> getAllByTypeIdOrderByBookIdDesc(Integer typeId);
}聚合函数分组查询
自定义SQL
在数据访问层接口中的方法上,可以加入@Query注解,默认要使用HQL(Hibernate专用)格式的语句。
如果要使用原生的SQL语句,需要添加nativeQuery=true属性,用value属性定义SQL语句
/*
* 在JPA中,如果要使用自定义的SQL语句
* nativeQuery = true 开启原生SQL语句
* value="sql语句"
* */
@Query(nativeQuery = true, value = "select book_author,count(book_id) from book_info group by book_author")
List testQuery();@Test
void test(){
List list = bookInfoDao.testQuery();
//查询的结果为集合,集合中保存的是每一行数据
for (Object row : list) {
//每一行页数一个对象数组
Object[] obj= (Object[])row;
//根据索引得到查询出的内容
System.out.println(obj[0]+"---"+obj[1]);
}
}自定义SQL中带参数
SQL语句中的":XXX"表示参数
如果方法的形参名和xxx一致时直接使用,如果不一致,在形参上加入@Param注解设置形参名
/*
* 根据作者查询其图书总库存
* 使用":形参名"在SQL语句中带参数
* 在方法中通过@Prama定义形参
* */
@Query(nativeQuery = true, value = " select book_author,sum(book_num) from book_info where book_author=:zuozhe")
List testQuery3(@Param("zuozhe") String xxx);
@Test
void test(){
List list = bookInfoDao.testQuery3("金庸");
//查询的结果为集合,集合中保存的是每一行数据
for (Object row : list) {
//每一行页数一个对象数组
Object[] obj= (Object[])row;
//根据索引得到查询出的内容
System.out.println(obj[0]+"---"+obj[1]);
}
}
前后端分离项目
前后端分离,就是将web应用中的前端页面和后端代码分开完成、部署。
- 前后端的开发者只需要完成各自的事情,最终以文档的形式约定数据接口(URL、参数、返回值、请求方式)
- 前后端分别用独立的服务器
- 后端只需处理数据并提供访问接口(路径),以RESTFul风格的JSON格式传输数据
- 前端只需负责渲染页面和展示数据
RESTFul风格具体使用
- 在请求映射的命名上,统一用小写字母的名词形式表示当前位于哪个模块。如/user、/book_info
- 访问时如果要传参,使用"/模块名/参数"方式,配合controller中的@PathVariable获取
@GetMapping("/book/{id}") public BookInfo queryById(@PathVariable("id")Integer id){ return service.findById(id); } - 在controller的方法上,使用@XXXMapping()设置访问该方法的请求方式
- @GetMapping("路径") 查询
- @PostMapping("路径") 添加
- **@PutMapping("路径") ** 修改
- **@DeleteMapping("路径") ** 删除
- @RequestMapping(value="路径",method=RequestMethod.GET/POST/PUT/DELETE))
- 如果请求方式不匹配,会报405异常
- 在同一个controller中,不能出现两个请求方式和路径都一致的方法
返回值设计
前后端分离项目的控制层方法的返回值也需要进行统一。
返回值通常包含以下信息
- 传递状态,用状态码表示Integer code
- 传递消息,用字符串表示String msg
- 传递集合,用集合表示List list
- 传递对象,用对象表示Object obj
将这些信息封装到一个对象中,这个对象称为返回结果类RestResult对象















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









