







任务描述:
使用requests的post爬取肯德基官网站餐厅查询中,获取某个城市的肯德基餐厅地址,以济南为例。
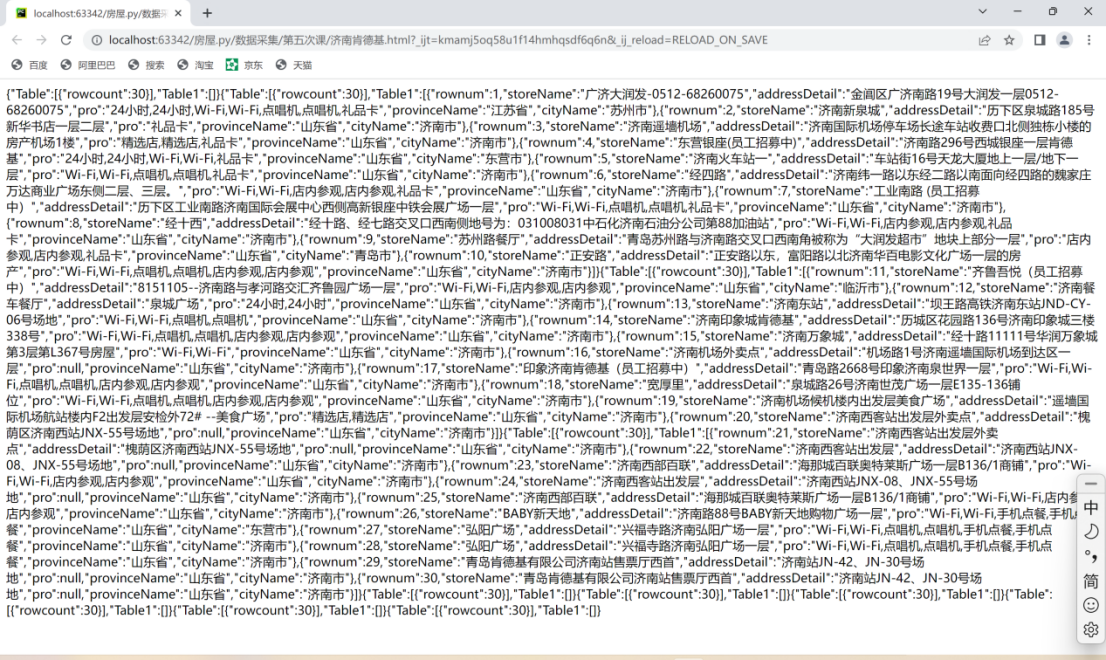
注意:1.考虑翻页2.写文件是追加。



任务实现:
import requests
url ='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
for page in range(0, 10):
page = str(page)#转换成字符串
data = {'cname': '',
'pid':'',
'keyword': '济南',
'pageIndex': page,
'pageSize': '10'}
response = requests.post(url, data=data, headers=headers)
text = response.text
with open('济南肯德基.html', 'a') as f:
f.write(text)
print('over')存储结果:















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









