







相信大家都已经了解或学习了MySQL的一些知识,下面是使用select查询语句在具体事例中的一些应用,相信可以帮助大家更好的理解MySQL中查询语句,和掌握他的用法。
函数的名称和作用
在我们进行实战之前需要了解一下在查询语句中必不可少的函数, 在查询语句中它的使用频率是非常高的,那么MySQL中有哪些函数?可以参考我这篇文章—>MySQL函数
如果你已经了解了函数的使用,请继续往下看。
首先创建一张表
这张表用于我们下面实现查询语句,实现数据来源。
我们建立一张名为worker公司员工信息管理表用来存储员工的
- 部门号
- 职工号
- 工作时间
- 工资
- 政治面貌
- 姓名
- 出生日期
- 性别
并将该表的职工号设置为从1001开始自增,主键设置为职工号,将政治面貌默认为”群众,“将所有的字段设置为“NOT NULL”,储存引擎设置为InnoDB,字符集设置为utf-8,行格式设置为动态行格式
代码如下所示
CREATE TABLE worker (
部门号 INT(11) NOT NULL,
职工号 INT(11) NOT NULL AUTO_INCREMENT,
工作时间 DATE NOT NULL,
工资 FLOAT(8,2) NOT NULL,
政治面貌 VARCHAR(10) DEFAULT '群众',
姓名 VARCHAR(20) NOT NULL,
出生日期 DATE NOT NULL,
性别 VARCHAR(10) NOT NULL ,
PRIMARY KEY (职工号)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC, AUTO_INCREMENT=1001;
然后在表中插入一些信息
INSERT INTO worker VALUES
(1, NULL, '2019-9-6', 9200.00, '党员', '张三', '1993-2-8','男'),
(1, NULL, '2017-2-6', 3200.00, '团员', '李四', '1997-2-1','男'),
(2, NULL, '2011-1-4', 8500.00, '党员', '王五', '1982-6-8','女'),
(2, NULL, '2016-10-15', 5500.00, '群众', '赵六', '1994-9-2','男'),
(2, NULL, '2014-5-1', 4800.00, '党员', '钱七', '1992-12-20','男'),
(2, NULL, '2015-5-5', 1500.00, '团员', '孙八', '1996-2-2','女'),
(2, NULL, '2011-5-4', 4500.00, '党员', '刘阿姨', '1952-6-8','女'),
(3, NULL, '2016-10-5', 5800.00, '群众', '陈小姐', '1994-9-2','男'),
(3, NULL, '2014-5-1', 7800.00, '党员', '李师傅', '1959-11-20','男');
一些关于查询语句的问题
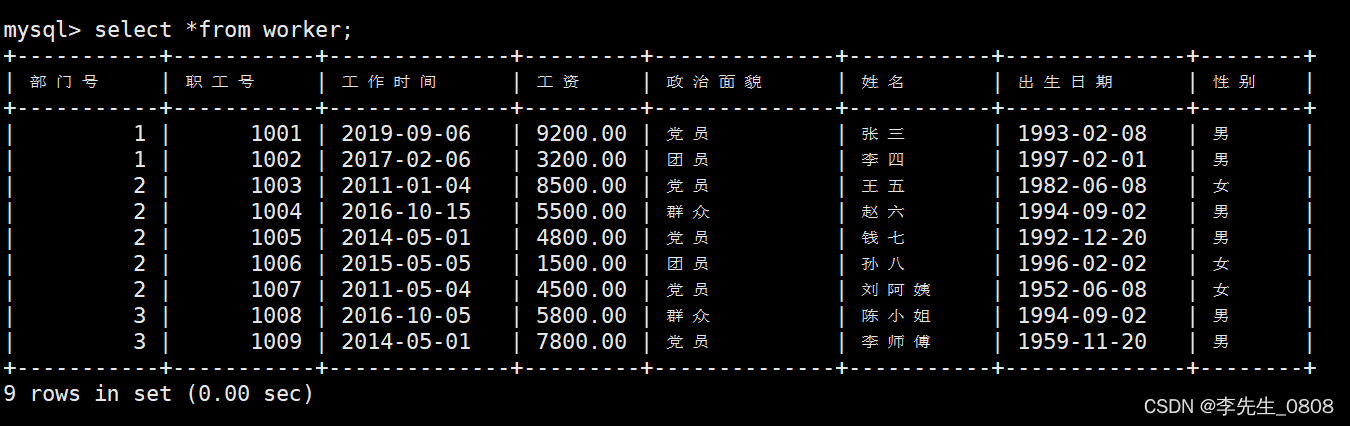
显示所有职工的基本信息。
使用select *from worker;
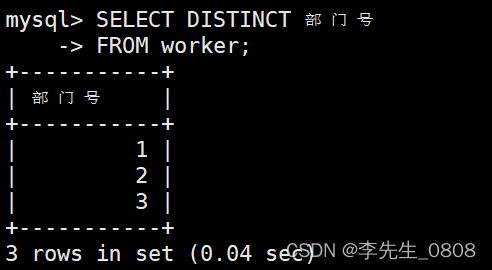
查询所有职工所属部门的部门号,不显示重复的部门号。
使用DISTINCT关键字来进行去重操作,
完整代码:
SELECT DISTINCT 部门号
FROM worker;
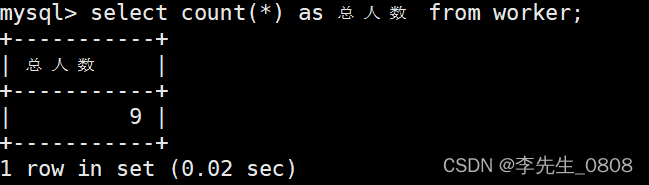
求出所有职工的人数。
使用求和函数COUNT(*)
完整代码:
SELECT COUNT(*) AS 总人数
FROM worker;
列出最高工和最低工资。
使用求最大值函数MAX()和最小值函数MIN()
完整代码:
SELEC MAX(工资) AS 最高工资, MIN(工资) AS 最低工资
FROM worker;

列出职工的平均工资和总工资。
使用求平均函数AVG()和求和函数SUM()
完整代码:
SELECT AVG(工资) AS 平均工资, SUM(工资) AS 总工资
FROM worker;

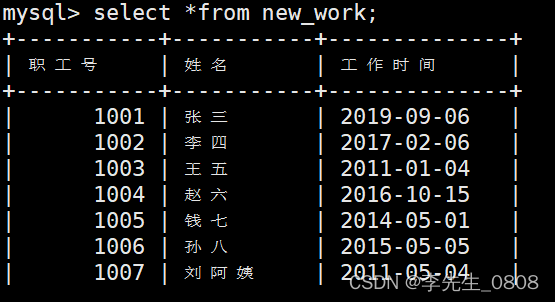
创建一个只有职工号、姓名和参加工作的新表
将本张表中 职工号 姓名 工作时间 字段复制到新建表new_work 中
这个新表将继承原始数据的数据类型和其他属性。
完整代码:
CREATE TABLE new_work
SELECT 职工号, 姓名, 工作时间
FROM worker;
使用select *from new_worker;查询后发现新表创建成功
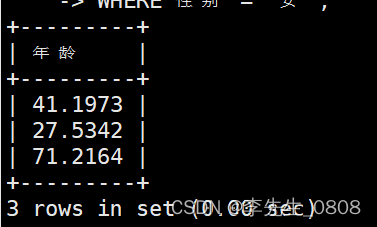
显示所有女职工的年龄。
使用DATEDIFF函数:用于计算当前日期与出生日期之间的天数差
CURRENT_DATE()函数:用于获取当前日期
完整代码:
SELECT DATEDIFF(CURRENT_DATE(), 出生日期) / 365 AS 年龄
FROM worker
WHERE 性别 = '女';
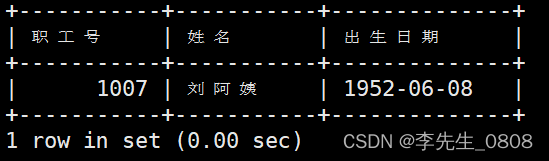
列出所有姓刘的职工的职工号、姓名和出生日期
使用LIKE进行模糊查找
当在 LIKE 关键字中使用 % 时,它表示匹配任意数量的字符(包括零个字符)。
完整代码:
SELECT 职工号, 姓名, 出生日期
FROM worker
WHERE 姓名 LIKE '刘%';
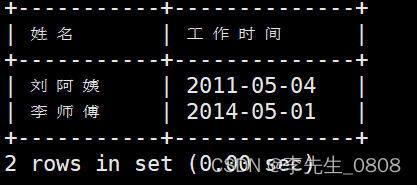
列出1960年以前出生的职工的姓名、参加工作日期。
将出生日期与‘1960-01-01’比较,小于该时间则输出。
完整代码:
SELECT 姓名, 工作日期
FROM worker
WHERE 出生日期 < '1960-01-01';
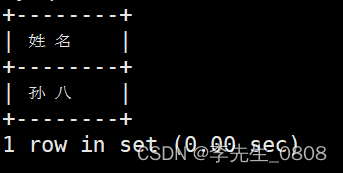
列出工资在1000-2000之间的所有职工姓名。
使用AND:AND 运算符用于指定多个条件都必须为真时才返回结果。
完整代码:
SELECT 姓名
FROM worker
WHERE 工资 >= 1000 AND 工资 <= 2000;
列出所有陈姓和李姓的职工姓名
OR 运算符:用于指定多个条件中只要有一个为真就返回结果
完整代码:
SELECT 姓名
FROM worker
WHERE 姓名 LIKE '陈%' OR 姓名 LIKE '李%';
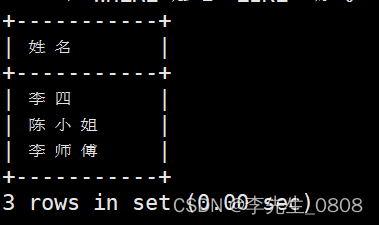
列出所有部门号为2和3的职工号、姓名、群众面貌。
使用了 IN 运算符:来指定部门号为2或3的条件
IN 运算符用于检查某个字段的值是否在指定的值列表中。
完整代码:
SELECT 职工号, 姓名, 政治面貌
FROM worker
WHERE 部门号 IN (2, 3);
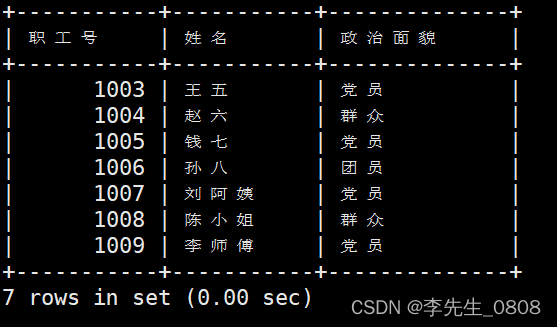
将职工表worker中的职工按出生的先后顺序排序
RDER BY:是用于在SQL查询中指定排序顺序的关键字。
通过使用ORDER BY可以按照一个或多个列对查询结果进行排序。
如果要逆序排序可以在ORDER BY子句之后添加DESC关键字。
完整代码:
SELECT *
FROM worker
ORDER BY 出生日期;
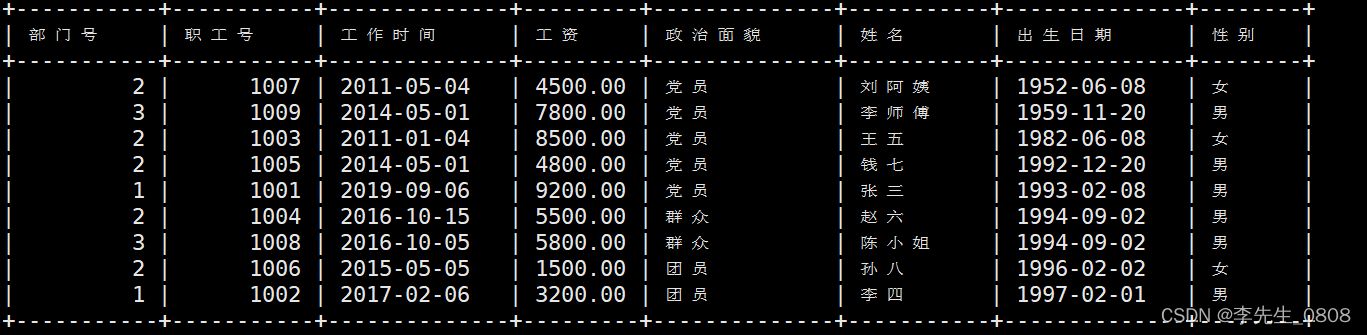
显示工资最高的前3名职工的职工号和姓名
使用LIMIT n:来限制结果只返回前n行。
完整代码:
SELECT 职工号, 姓名
FROM worker
ORDER BY 工资 DESC
LIMIT 3;
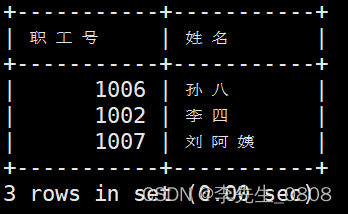
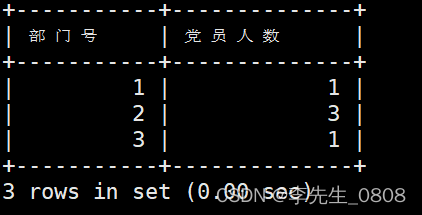
求出各部门党员的人数
GROUP BY子句:是用于将结果按照一个或多个列进行分组的SQL语句。
完整代码:
SELECT 部门号, COUNT(*) AS 党员人数
FROM worker
WHERE 政治面貌='党员'
GROUP BY 部门号;
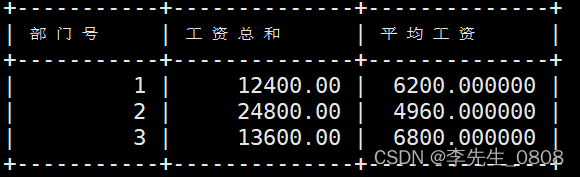
统计各部门的工资和平均工资
GROUP BY子句:是用于将结果按照一个或多个列进行分组的SQL语句。
它通常与聚合函数(如COUNT、SUM、AVG等)一起使用,以对每个分组计算汇总值。
完整代码:
SELECT 部门号, SUM(工资) AS 工资总和, AVG(工资) AS 平均工资
FROM worker
GROUP BY 部门号;
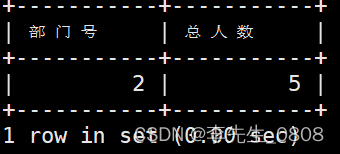
列出总人数大于4的部门号和总人数。
使用HAVING子句过滤出总人数大于4的部门。
HAVING子句的作用:可以让我们筛选分组后的各组数据。
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
完整代码:
SELECT 部门号, COUNT(*) AS 总人数
FROM worker
GROUP BY 部门号
HAVING COUNT(*) > 4;
本次实战篇到此就结束了,后续还将更新多表查询等内容,及时关注我可以方便获取最新的文章;















 2932
2932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









