







目录
实现 Runnable 接⼝⽐继承 Thread 类所具有的优势:
newSingleThreadExecutor——不推荐使用
多线程
多线程概述
在了解学习多线程之前,我们先要熟悉了解几个关于多线程有关的概念。
什么是程序,进程,什么是线程
程序:是为了完成某个特定的任务,而用某种语言编写的一组指令的集合,即指的是一段静态的代码,静态对象。
进程:进程指正在运行的程序。确切的来说,当一个程序进入内存运行,即变成一个进程,进程是处于运行过程中的程序,并且具有一定独立功能。
线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。一个进程中是可以有多个线程的,这个应用程序也可以称之为多线程程序。(银行项目的还款,里边就有多条线程,比如一条线程还款完成响应给用户,另一条线程去更改数据库里的数据)
简而言之:一个程序运行后至少有一个进程,一个进程中可以包含多个线程。
例如:QQ里面打开一个聊天窗口是一个线程,再打开一个聊天窗口又是一个线程 或打开浏览器的一个页面是一个线程,再打开页面又是一个线程
多线程定义:在一个程序中,这些独立运行的程序片段叫作“线程”。即就是一个程序中有多个线程在同时执行。
我们可以通过程序执行流程,来区分单线程程序与多线程程序的不同:
单线程程序:即,若有多个任务只能依次执行。当上一个任务执行结束后,下一个任务开始执行。如接水,有一个水龙头,一个人接完,下一个人才能开始接水。
多线程程序:即,若有多个任务可以同时执行。如在饮水机处接水,温水处与热水处可以同时放水。
为什么使用多线程
1.与进程相比,他是一种花销小,切换快,更节俭的多任务操作方式;
2.线程间方便的通信机制;
3.多线程作为一种多任务,并发的工作方式,可以提高程序的响应;
4.使多系统CPU更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行在不同的CPU上;
5.改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序会利于理解和修改。
多线程应用场景
1.多线程应用最多的场景
web服务器本身(tomcat)服务器(当我们启动了一个项目,就相当于一个线程),各种专用服务器(如游戏服务器);
2.多线程常见的应用场景
(1)后台任务,例如:定时向大量(100w以上)的用户发送邮件;(1024程序员节,定时向csdn用户发送节日祝福)
(2)异步处理,例如:发微博,记录日志等;(写微博,部分刷新)
(3)分布式计算
(4) 程序需要实现一些需要等待的任务时,如用户输入、文件读写操作、网络操作、搜索等。
并行与并发的理解
并行:若干个程序段同时在系统中运行,这些程序的执行在时间上是重叠的,一个程序段的执行尚未结束,另一个程序段的执行已经开始,无论从微观还是宏观,程序都是一起执行的。可理解为多个CPU同时执行多个任务。(浏览器页面,淘宝页面加载 主线程负责主要结构布局和文字展示 子线程负责后续加载图片; )
并发:在同一个时间段内,两个或多个程序执行,有时间上的重叠(宏观上是同时,微观上仍是顺序执行)。可以理解为一个CPU(采用时间片)同时执行多个任务。比如:秒杀、
创建线程的方法
方式一:继承Thread类
1、 创建一个继承于Thread类的子类。
2、 重写Thread类的run() ,将此线程执行的操作声明在run()中。
3、 创建Thread类的子类的对象,即创建了线程对象。
4、 通过此对象调用start(): ① 启动当前线程 ② 调用当前线程的run()
package com.xinzhi.test;
public class MyThread extends Thread {
//1.创建一个继承于Thread的子类
public MyThread(){
super();
}
// 2.重写Thread类的run(),将此线程执行的操作声明在run中
@Override
public void run(){
for(int i = 0;i<100;i++){
System.out.println("子线程"+ i);
}
}
// 3.创建Thread类的子类对象,即创建了线程对象
public static class ThreadTest{
public static void main(String[] args) {
// 1.创建线程
MyThread myThread = new MyThread();
// 2.启动线程,并调用当前线程的run方法
myThread.start();
}
}
}
注意:
1、如果自己手动调用 run() 方法,那么就只是普通方法,没有启动多线程模式。
2、run() 方法由 JVM 调用,什么时候调用,执行的过程控制都有操作系统的 CPU
调度决定 。
3、想要启动多线程,必须调用 start() 方法 。
4、一 个线程对象只能调用一次 start() 方法启动,如果重复调用了,则将抛出异常 "IllegalThreadStateException
方式二:实现Runnable接口
1) 定义子类 ,实现 Runnable 接口。
2) 子类中重写 Runnable 接口中的 run() 方法。
3) 通过 Thread 类含参构造器创建线程对象。
4) 将 Runnable 接口的子类对象作为实际参数传递给 Thread 类的构造器中 。
5) 调用 Thread 类的 start() 方法:开启线程调用 Runnable 子类接口的 run() 方法。
package com.xinzhi.test;
//1.创建一个实现runnable接口的类
public class RunnThread implements Runnable {
@Override
// 2.实现runnable接口中的抽象方法run()
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 5 == 0)
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}package com.xinzhi.test;
public class ThreadTest {
public static void main(String[] args) {
//3.创建实现类的对象
RunnThread m = new RunnThread();
// 4.将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
Thread t1 = new Thread(m);
t1.setName("线程一:");
t1.start();
// 在启动一个
Thread t2 = new Thread(m);
t2.setName("线程二:");
t2.start();
}
}继承Thread类和实现Runnable接口的联系与区别
相同点:
1、两种方式都需要重写 run() ,将线程要执行的逻辑声明在run()中。
2、启动线程,都是调用的Thread类中的 start()。
实现 Runnable 接⼝⽐继承 Thread 类所具有的优势:
1. 适合多个相同的程序代码的线程去共享同⼀个资源。
2. 可以避免 java 中的单继承的局限性。
3. 增加程序的健壮性,实现解耦操作,代码可以被多个线程共享,代码和线程独⽴。
4. 线程池只能放⼊实现 Runable 或 Callable 类线程,不能直接放⼊继承 Thread 的类。
方式三:实现Callable 接口
与使用 Runnable 相比, Callable 功能更强大些。
● 相比 run() 方法,call() 可以有返回值。
● call() 方法可以抛出异常。
● Callable 支持泛型的返回值。
● 需要借助 FutureTask 类,比如获取返回结果。
Future 接口
可以对具体 Runnable 、 Callable 任务的执行结果进行取消、查询是否完成、获取结果等。
FutrueTask 是 Futrue 接口的唯一的实现类。
FutureTask 同时实现了 Runnable, Future 接口。它既可以作为。
Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值。
package com.xinzhi.test;
import java.util.concurrent.Callable;
//1.创建一个callable的实现类
public class CallThread implements Callable {
@Override
// 2.实现call方法,将此线程需要执行的操作声明在call()中
public Object call() throws Exception {
int sum = 0;
for (int i = 0; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(i);
sum += i;
}
}
return sum;
}
}import java.util.concurrent.FutureTask;
public class ThreadNew {
public static void main(String[] args) {
// 3.创建callable接口实现类的对象
CallThread numThread = new CallThread();
// 4.将此Callable接口实现类的对象作为参数传递到FutureTask构造器中,
FutureTask futureTask = new FutureTask(numThread);
// 5.将futureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象
new Thread(futureTask).start();
// 6.可获取Callable的call方法的返回值
// get()返回值为FutureTask构造器参数Callable实现类重写的call的返回值
try {
Object sum = futureTask.get();
System.out.println("总和为:"+sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
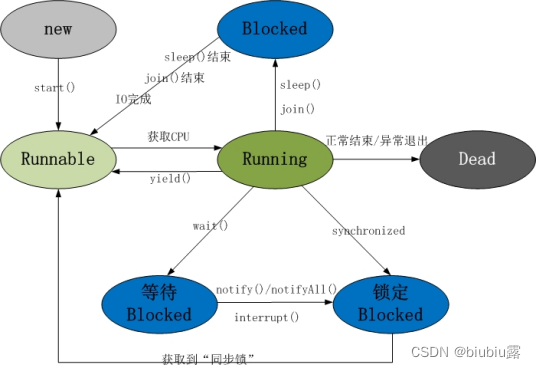
线程的状态
线程的生命周期
新建new: 当 一个 Thread 类或其子类的对象被声明并创建时,新生的线程对象处于新建状态。如:Thread t = new MyThread();
就绪Runnable: 当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;只是没分配到 CPU 资源。
运行running: 当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞Blocked:处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡Dead: 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。。
新建(new)和就绪(Runnable)状态
当new一个线程后,该线程处于新建状态,此时它和Java对象一样,仅仅由Java虚拟机为其分配内存空间,并初始化成员变量。
此时线程对象没有表现出任何的动态特征,程序也不会执行线程的执行体。
注意:run方法是线程的执行体,不能由我们手动调用。我们可以用start方法启动线程,系统会把run方法当成线程的执行体来运行,如果直接调用线程对象run方法,则run方法立即会被运行。而且在run方法返回之前其他线程无法并行执行,也就是说系统会把当前
线程类当成一个普通的Java对象,而run方法也是一个普通的方法,而不是线程的执行体。
运行(running)和阻塞(Blocked)状态
如果处于就绪状态的线程就获得了CPU,开始执行run方法的线程执行体,则该线程处于运行状态。
单CPU的机器,任何时刻只有一条线程处于运行状态。当然,在多CPU机器上将会有多线程并行(parallel)执行,当线程大于CPU数量时,依然会在同一个CPU上切换执行。
线程运行机制:一个线程运行后,它不可能一直处于运行状态(除非它执行的时间很短,瞬间执行完成),线程在运行过程中需要中断,目的是让其他的线程有运行机会,线程的调度取决于底层的策略。对应抢占式的系统而言,系统会给每个可执行的线程一个小时间段来处理任务,当时间段到达系统就会剥夺该线程的资源,让其他的线程有运行的机会。在选择下一个线程时,系统会考虑线程优先级。
以下情况会出现线程阻塞状态:
A、线程调用sleep方法,主动放弃占用的处理器资源
B、线程调用了阻塞式IO方法,在该方法返回前,该线程被阻塞
C、线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。
D、线程等待某个通知(notify)
E、程序调用了suspend方法将该线程挂起。不过这个方法容易导致死锁,尽量不免使用该方法
当线程被阻塞后,其他线程将有机会执行。被阻塞的线程会在合适的时候重新进入就绪状态,注意是就绪状态不是运行状态。也就是被阻塞线程在阻塞解除后,必须重新等待线程调度器再次调用它。
针对上面线程阻塞的情况,发生以下特定的情况可以解除阻塞,让进程进入就绪状态:
A、调用sleep方法的经过了指定的休眠时间
B、线程调用的阻塞IO已经返回,阻塞方法执行完毕
C、线程成功获得了试图同步的监视器
D、线程正在等待某个通知,其他线程发出了通知
E、处于挂起状态的线程调用了resume恢复方法
线程从阻塞状态只能进入就绪状态,无法进入运行状态。而就绪和运行状态之间的转换通常不受程序控制,而是由系统调度所致的。
当就绪状态的线程获得资源时,该线程进入运行状态;当运行状态的线程事情处理器资源时就进入了就绪状态。
但对调用了yield的方法就例外,此方法可以让运行状态转入就绪状态。
线程调度
分时调度
所有线程轮流使⽤ CPU 的使⽤权,平均分配每个线程占⽤ CPU 的时间。
抢占式调度
优先让优先级⾼的线程使⽤ CPU,如果线程的优先级相同,那么会随机选择⼀个(线程随机性), Java使⽤的为抢占式调度。
抢占式调度详解
⼤部分操作系统都⽀持多进程并发运⾏,现在的操作系统⼏乎都⽀持同时运⾏多个程序。⽐如: 现在我们⼀边使⽤编辑器,⼀边使⽤录屏软件,同时还开着画图板, dos 窗⼝等软件。此
时,这些程序是在同时运⾏, “ 感觉这些软件好像在同⼀时刻运⾏着 ” 。
实际上,CPU (中央处理器)使⽤抢占式调度模式在多个线程间进⾏着⾼速的切换。对于 CPU 的 ⼀个核⽽⾔,某个时刻,只能执⾏⼀个线程,⽽ CPU 的在多个线程间切换速度相对我们的感觉 要快,看上去就是在同⼀时刻运⾏。
其实,多线程程序并不能提⾼程序的运⾏速度,但能够提⾼程序运⾏效率,让 CPU 的使⽤率更 ⾼。
线程等待
Object类中的wait()方法,导致当前的线程等待,知道其他线程调用此对象的notify()方法或notifyall()唤醒方法。这两个唤醒方法也是Object类中的方法,行为等价于调用wait()。
线程唤醒
Object类中的notify()方法,唤醒再此对象监视器上等待的单个线程,如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现作出决定时发生。线程通过调用其中一个wait方法,在对象的监视器上等待。知道当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权和劣势。类似的方法还有一个notifyAll(),唤醒再此对象监视器上等待的所有线程。
public class ThreadMethod04 {
private static Object obj = new Object();
public static void main(String[] args) {
new Thread(new Wait1(obj)).start();
new Thread(new Wait2(obj)).start();
}
}
class Wait1 implements Runnable{
private Object obj;
public Wait1(Object obj) {
this.obj = obj;
}
@Override
public void run() {
synchronized (obj) {
for (int i = 1; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+"---" + i);
}
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("我醒了~~~醒了~~~");
}
}
}
class Wait2 implements Runnable {
private Object obj;
public Wait2(Object obj) {
this.obj = obj;
}
@Override
public void run() {
for (int i = 10; i < 20; i++) {
System.out.println(Thread.currentThread().getName()+"---" + i);
}
synchronized (obj) {
System.out.println("唤醒wait1");
obj.notify();
}
}
}线程方法
线程停止
在Java中有以下三种方法可以终止正在运行的线程:
1. 通过设置退出标志位,使线程正常退出。
2. 调用Thread类中的stop()方法强行终止线程。但是不推荐使用这个方法,该方法已被弃用。
3. 使用Thread类中的interrupt()方法中断线程。
1.建议线程正常停止--->利用次数,不建议死循环;
2.建议使用标志位,设置一个标志位;
3.不要使用stop或destroy等或者是JDK不建议使用的方法。
一、使用标志位终止线程
在线程类中,我们会定义一个标志位表示是否需要终止线程,并提供一个公共方法供外部设置标志位,在run()方法中通过标志位的取值判断是否需要终止。
例如,我们模拟了一个服务器不断接收客户端请求的过程。当主线程中将“running”这一标志位设为false后,while死循环就会结束,线程体执行结束,整个线程也就执行完毕了。
public class Main {
public static void main(String[] args) throws InterruptedException {
// start a thread (simulated server)
Server server = new Server();
new Thread(server).start();
// run the thread for about 10 seconds
Thread.sleep(10000);
// time to stop the thread
server.setRunning(false);
}
}
class Server implements Runnable {
// whether the server should be running or not
private volatile boolean running = true;
// setter method for user
public void setRunning(boolean running) { this.running = running; }
@Override
public void run() {
// run until the flag is set to be false
while (running) {
// simulate the process of server to handle the request
System.out.println("Server is processing the request...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// finish the process and stop the thread
System.out.println("Server is closing...");
}
}二、调用stop()方法终止线程
通过调用Thread类中的stop()方法可以终止一个线程的运行,但是该方法已经在JDK中被声明为已过时(deprecated),不再推荐使用,因为该方法被认为是不安全的。具体的原因有:
1. 调用stop()方法会立刻停止run()方法中剩余的全部工作,包括在catch或finally语句中的,并抛出ThreadDeath异常(通常情况下此异常不需要显示的捕获),因此可能会导致一些清理性的工作的得不到完成,如文件,数据库等的关闭。
2. 调用stop()方法会立即释放该线程所持有的所有的锁,导致数据得不到同步,出现数据不一致的问题。
例如,存在一个对象user持有ID和NAME两个字段,假如写入线程在写对象的过程中,只完成了对ID的赋值,但没来得及为NAME赋值,就被stop()导致锁被释放,那么当读取线程得到锁之后再去读取对象user的ID和Name时,就会出现数据不一致的问题。
三、调用interrupt()方法终止线程
通过调用Thread类中的interrupt()方法也可以终止线程,但是它和stop()还是有着明显的区别。事实上,interrupt()方法并不会立即执行中断操作,而只是给线程设置一个为true的中断标志,所以它并不是真正的终止线程(否则那和stop()方法有什么区别了呢)。
来看下面一个例子:
public class Main {
public static void main(String[] args) throws InterruptedException {
// start a thread
Task task = new Task();
Thread thread = new Thread(task);
thread.start();
// wait for 5ms
Thread.sleep(5);
// now we interrupt the thread
thread.interrupt();
}
}
class Task implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
System.out.println("In Thread: " + i);
}
}
}
上述程序的输出结果如下:
In Thread: 0
In Thread: 1
In Thread: 2
In Thread: 3
In Thread: 4
In Thread: 5
............
In Thread: 9995
In Thread: 9996
In Thread: 9997
In Thread: 9998
In Thread: 9999
我们惊讶的发现,线程体居然顺利的全部执行完了,设置的中断完全没有起到作用。为了让线程能够中断,我们需要在run()方法中使用isInterrupted()方法进行判断:如果希望线程在中断后停止,就必须先判断是否被中断,并为它增加相应的中断处理代码。
public class Main {
public static void main(String[] args) throws InterruptedException {
// start a thread
Task task = new Task();
Thread thread = new Thread(task);
thread.start();
// wait for 5ms
Thread.sleep(5);
// now we interrupt the thread
thread.interrupt();
}
}
class Task implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
// check whether the thread is interrupted
if (Thread.currentThread().isInterrupted())
// if true, break the loop
break;
System.out.println("In Thread: " + i);
}
}
}
修改后程序的运行结果如下:
In Thread: 0
In Thread: 1
In Thread: 2
In Thread: 3
.............
In Thread: 207
In Thread: 208
In Thread: 209
In Thread: 210
In Thread: 211
In Thread: 212
显然,线程体远未执行完毕就被中断提前结束了。
需要注意的是,
1. 如果,线程的当前状态处于非阻塞状态,那么仅仅是线程的中断标志被修改为true而已;
2. 如果线程的当前状态处于阻塞状态,那么在将中断标志设置为true后,如果是wait、sleep以及join三个方法引起的阻塞,那么会将线程的中断标志重新设置为false,并抛出一个InterruptedException,这样受阻线程就得以退出阻塞的状态。
线程休眠
(1)Sleep(时间)指定当前线程阻塞的毫秒数;
(2)Sleep存在异常InterruptedException;
(3)Sleep时间达到后线程进入就绪状态;
(4)Sleep可以模拟网络延时,倒计时等;
(5)每个对象都有一个锁,Sleep不会释放锁。
public class TestSleep {
// public static void main(String[] args) throws InterruptedException {
// tenDown();
// }
public static void main(String[] args) {
//打印当前系统时间
Date startTime = new Date(System.currentTimeMillis());
while (true){
try {
Thread.sleep(1000);
System.out.println(new SimpleDateFormat("HH:mm:ss").format(startTime));
startTime = new Date(System.currentTimeMillis());//更新当前时间
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void tenDown() throws InterruptedException {
int num = 10;
while (true){
Thread.sleep(1000);
System.out.println(num--);
if (num <= 0 ){
break;
}
}
}
}
sleep和wait的区别:
-
sleep() 是 Thread 类的静态本地方法;wait() 是Object类的成员本地方法
-
sleep() 方法可以在任何地方使用;wait() 方法则只能在同步方法或同步代码块中使用,否则抛出异常Exception in thread "Thread-0" java.lang.IllegalMonitorStateException
-
sleep() 会休眠当前线程指定时间,释放 CPU 资源,不释放对象锁,休眠时间到自动苏醒继续执行;wait() 方法放弃持有的对象锁,进入等待队列,当该对象被调用 notify() / notifyAll() 方法后才有机会竞争获取对象锁,进入运行状态
-
sleep进入阻塞状态没有释放锁,wait进入阻塞状态但是同时释放了锁
线程礼让
(1)礼让线程,让当前正在执行的线程暂停,但不阻塞
(2)将线程从运行状态转为就绪状态
(3)让CPU重新调度,礼让不一定成功,看CPU心情
public class ThreadYield extends Thread{
public ThreadYield(String name){
super(name);
}
public void run() {
for (int i = 1; i <= 50; i++) {
System.out.println("" + this.getName() + "-----" + i);
// 当i为30时,该线程就会把CPU时间让掉,让其他或者自己的线程执行(也就是谁先抢到谁执行)
if(i == 30){
this.yield();
}
}
}
}
public class ThreadYieldTest {
public static void main(String[] args) {
ThreadYield TY = new ThreadYield("张三");
ThreadYield TY1 = new ThreadYield("李四");
TY.start();
TY1.start();
}
}线程加入
Join合并线程,待此线程执行完成后,再执行其它线程,其他线程阻塞,可以想象成插队。
join是Thread类的一个方法,启动线程后直接调用,即join()的作用是:“等待线程终止”,这里需要理解的就是该线程是指的主线程等待子线程的终止,也就是在子线程调用了join()方法后面的代码,只有等到子线程结束了才能执行。
在很多情况下,主线程生成并启动了子线程,如果子线程里要进行大量的耗时运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后在结束,这个时候就要用到join方法了。
不加join()
public class NoJoinDemo extends Thread{
private String name;
public NoJoinDemo(String name){
super(name);
this.name=name;
}
public void run() {
System.out.println(Thread.currentThread().getName() + "线程运行开始!");
for (int i = 0; i < 5; i++) {
System.out.println("子线程" + name + "运行:" + i);
try {
sleep((int) Math.random()*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "线程运行结束!");
}
}
public class JoinTest {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName() + "主线程运行开始!");
NoJoinDemo NJD = new NoJoinDemo("子线程A");
NoJoinDemo NJD1 = new NoJoinDemo("子线程B");
Thread T1 = new Thread(NJD,"A");
Thread T2 = new Thread(NJD1,"B");
T1.start();
T2.start();
System.out.println(Thread.currentThread().getName() + "主线程运行结束!");
}
}加join()
public class JoinTest {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName() + "主线程运行开始!");
NoJoinDemo NJD = new NoJoinDemo("子线程A");
NoJoinDemo NJD1 = new NoJoinDemo("子线程B");
Thread T1 = new Thread(NJD,"A");
Thread T2 = new Thread(NJD1,"B");
T1.start();
T2.start();
try {
T1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
T2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "主线程运行结束!");
}
}线程优先级
Java线程有优先级,优先级高的线程会获得较多的运行机会。
Java线程的优先级用整数表示 ,取值范围是1-10,Thread类中有以下三个静态常量:
static int MAX_PRIORITY 线程可以具有的最高优先级,取值为10
static int MIN_PRIORITY 线程可以具有的最低优先级,取值为1
static int NORM_PRIORITY 线程可以具有的正常优先级,取值为5
Thread类的setPriority()和getPriority()方法分别用来设置和获取线程的优先级
每个线程都有默认的优先级,主线程的默认优先级为Thread。NORM_PRIORITY。
线程的优先级有继承关系,比如A线程中创建了B线程,那么B将和A具有相同的优先级。
public class Max_Priority implements Runnable{
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "正在输出" + i);
}
}
}
public class Min_Priority implements Runnable{
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "正在输出" + i);
}
}
}
public class PriorityTest {
public static void main(String[] args) {
Max_Priority MAP = new Max_Priority();
Min_Priority MIP = new Min_Priority();
Thread Thread1 = new Thread(MAP,"优先级较高的线程");
Thread Thread2 = new Thread(MIP,"优先级较低的线程");
Thread1.setPriority(10);
Thread2.setPriority(1);
Thread1.start();
Thread2.start();
}
}守护线程
线程分为用户线程和守护线程
虚拟机必须确保用户线程执行完毕
虚拟机不用等待守护线程执行完毕
-
用户线程:也叫工作线程,当线程的任务执行完后通知方式结束
-
守护线程:一般是为工作线程服务的,当所有的用户线程结束,守护线程自动结束
-
常见的守护线程:垃圾回收机制,后台记录操作日志,监控内存
public class TestDaemon {
public static void main(String[] args) {
User u = new User();
God g = new God();
Thread t1 = new Thread(g);
t1.setDaemon(true);//默认是false,表示是正常的线程,正常的线程都是用户线程
t1.start();
new Thread(u).start();
}
}
class User implements Runnable{
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("你生活了第" + i +"年");
}
System.out.println("GoodBye ------ World");
}
}
class God implements Runnable{
@Override
public void run() {
while (true){
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("上帝守护着你");
}
}volatile
java虚拟机提供的轻量级的同步机制。保证可见性,不保证原子性,禁止指令重排。
volatile的可见性
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(也叫栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行。操作过程有三步。
-
首先要将变量从主内存拷贝到自己的工作内存空间。
-
然后对变量进行操作。
-
操作完成后再将变量写回主内存,不能直接操作主内存中的变量。
各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成。
volatile的不保证原子性
原子性定义:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被加塞或者被分割,需要具体完成,要么同时成功,要么同时失败。
volatile禁止指令重排
单线程环境里面确保最终执行结果和代码顺序的结果一致
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
线程阻塞的几种状态
线程状态概述
当线程被创建并启动以后,它既不是⼀启动就进⼊了执⾏状态,也不是⼀直处于执⾏状态。在线程的⽣命 周期中,有⼏种状态呢?在 API 中 java.lang.Thread.State 这个枚举中给出了六种线程状态:
这⾥先列出各个线程状态发⽣的条件,下⾯将会对每种状态进⾏详细解析
我们不需要去研究这⼏种状态的实现原理,我们只需知道在做线程操作中存在这样的状态。那我们怎么去理解这⼏个状态呢,新建与被终⽌还是很容易理解的,我们就研究⼀下线程从 Runnable (可运⾏)状态与 ⾮运⾏状态之间的转换问题。
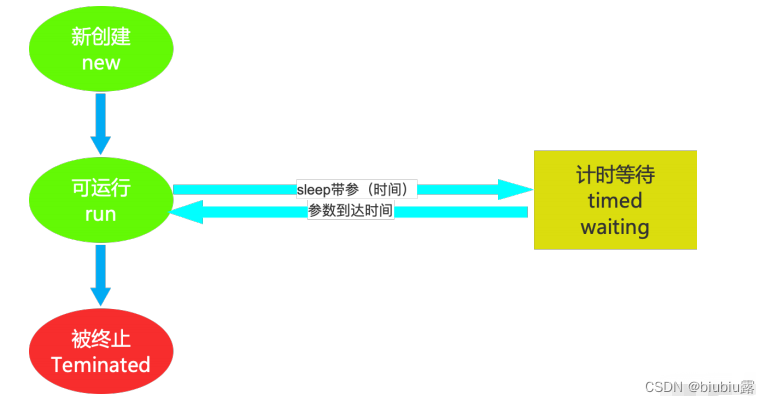
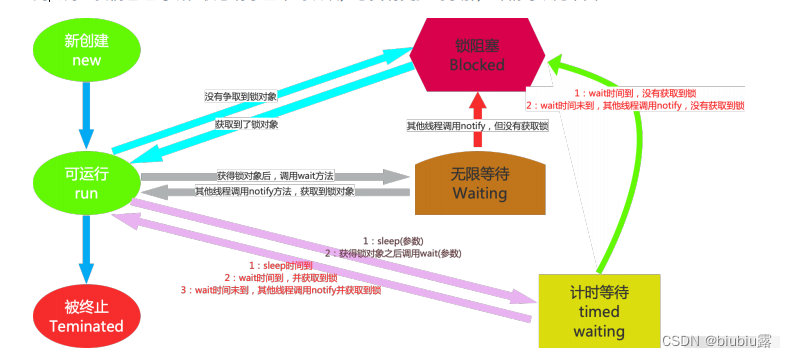
Timed Waiting(计时等待)
Timed Waiting 在 API 中的描述为:⼀个正在限时等待另⼀个线程执⾏⼀个(唤醒)动作的线程处于这⼀状态。单独的去理解这句话,真是⽞之⼜⽞,其实我们在之前的操作中已经接触过这个状态了,在哪⾥呢?
在我们写卖票的案例中,为了减少线程执⾏太快,现象不明显等问题,我们在 run ⽅法中添加了 sleep 语句,这样就强制当前正在执⾏的线程休眠 (暂停执⾏) ,以 “ 减慢线程 ” 。
其实当我们调⽤了 sleep ⽅法之后,当前执⾏的线程就进⼊到 “ 休眠状态 ” ,其实就是所谓的 Timed Waiting(计时等待),那么我们通过⼀个案例加深对该状态的⼀个理解。
实现⼀个计数器,计数到 100 ,在每个数字之间暂停 1 秒,每隔 10 个数字输出⼀个字符串
代码:
public class MyThread extends Thread {
public void run() {
for (int i = 0; i < 100; i++) {
if ((i) % 10 == 0) {
System.out.println("-------" + i);
}
System.out.print(i);
try {
Thread.sleep(1000);
System.out.print(" 线程睡眠1秒!\n");
} catch (InterruptedException e) {
e.printStackTrace(); }
}
}
public static void main(String[] args) {
new MyThread().start();
}
}通过案例可以发现, sleep ⽅法的使⽤还是很简单的。我们需要记住下⾯⼏点:
1. 进⼊ TIMED_WAITING 状态的⼀种常⻅情形是调⽤的 sleep ⽅法,单独的线程也可以调⽤,不⼀定⾮要有协作关系。
2. 为了让其他线程有机会执⾏,可以将 Thread.sleep() 的调⽤ 放线程 run() 之内 。这样才能保证该线程执⾏过程中会睡眠。
3. sleep 与锁⽆关,线程睡眠到期⾃动苏醒,并返回到 Runnable (可运⾏)状态。
⼩提示: sleep() 中指定的时间是线程不会运⾏的最短时间。因此, sleep() ⽅法不能保证该线程睡眠到期后就开始⽴刻执⾏。
Timed Waiting 线程状态图:
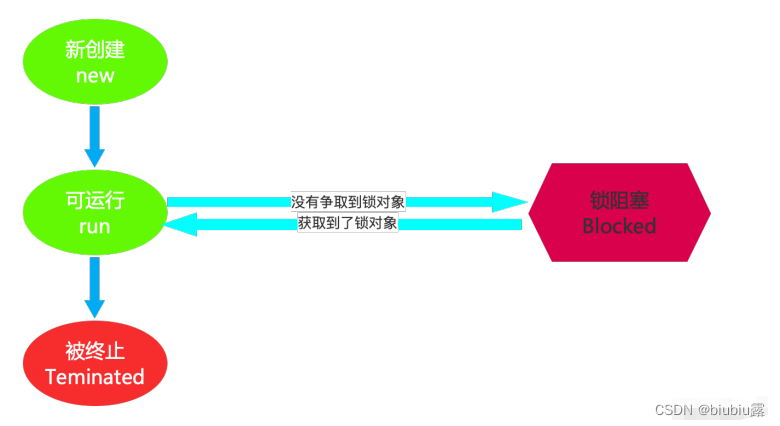
BLOCKED(锁阻塞)
Blocked 状态在 API 中的介绍为:⼀个正在阻塞等待⼀个监视器锁(锁对象)的线程处于这⼀状态。
我们已经学完同步机制,那么这个状态是⾮常好理解的了。⽐如,线程 A 与线程 B 代码中使⽤同⼀锁,如果 线程 A 获取到锁,线程 A 进⼊到 Runnable 状态,那么线程 B 就进⼊到 Blocked 锁阻塞状态。
这是由 Runnable 状态进⼊ Blocked 状态。除此 Waiting 以及 Time Waiting 状态也会在某种情况下进⼊阻塞状态,⽽这部分内容作为扩充知识点带领⼤家了解⼀下。
Blocked 线程状态图:
Waiting(⽆限等待)
Wating 状态在 API 中介绍为:⼀个正在⽆限期等待另⼀个线程执⾏⼀个特别的(唤醒)动作的线程处于这⼀状态。
那么我们之前遇到过这种状态吗?答案是并没有,但并不妨碍我们进⾏⼀个简单深⼊的了解。我们通过⼀段代码来学习⼀下:
package com.xinzhi.conntest;
public class WattingTest {
public static Object obj = new Object();
public static void main(String[] args) {
// 演示waiting
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
synchronized (obj) {
try {
System.out.println(Thread.currentThread().getName() +" === 获取到锁对象调⽤wait⽅法,进⼊waiting状态,释放锁对象");
obj.wait(); // ⽆限等待
// obj.wait(5000); // 计时等待, 5秒 时间到,⾃动醒来
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "=== 从waiting状态醒来,获取到锁对象,继续执⾏了");
}
}
}
}, "等待线程").start();
new Thread(new Runnable() {
@Override
public void run() {
// while (true) { // 每隔3秒 唤醒⼀次
try {
System.out.println(Thread.currentThread().getName() + "----- 等待3秒 钟");
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
System.out.println(Thread.currentThread().getName() + "----- 获取到锁对象,调⽤notify⽅法,释放锁对象");
obj.notify();
}
}
// }
}, "唤醒线程").start();
}
}
通过上述案例我们会发现,⼀个调⽤了某个对象的 Object.wait ⽅法的线程会等待另⼀个线程调⽤此对象的Object.notify() ⽅法 或 Object.notifyAll() ⽅法。
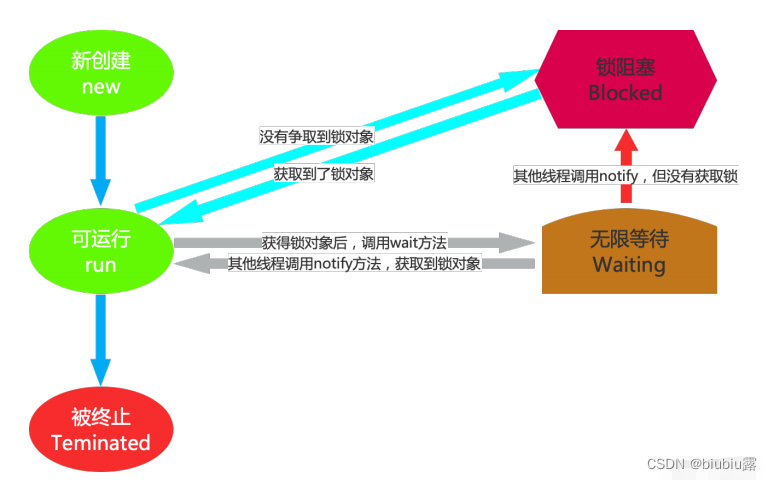
其实 waiting 状态并不是⼀个线程的操作,它体现的是多个线程间的通信,可以理解为多个线程之间的协作关系,多个线程会争取锁,同时相互之间⼜存在协作关系。就好⽐在公司⾥你和你的同事们,你们可能 存在晋升时的竞争,但更多时候你们更多是⼀起合作以完成某些任务。
当多个线程协作时,⽐如 A , B 线程,如果 A 线程在 Runnable (可运⾏)状态中调⽤了 wait() ⽅法那么 A 线程 就进⼊了 Waiting (⽆限等待)状态,同时失去了同步锁。假如这个时候 B 线程获取到了同步锁,在运⾏状 态中调⽤了 notify() ⽅法,那么就会将⽆限等待的 A 线程唤醒。注意是唤醒,如果获取到锁对象,那么 A 线 程唤醒后就进⼊ Runnable (可运⾏)状态;如果没有获取锁对象,那么就进⼊到 Blocked (锁阻塞状 态)。
Waiting 线程状态图:
⼀条有意思的 Tips :
我们在翻阅 API 的时候会发现 Timed Waiting (计时等待)与 Waiting (⽆限等待)状态联系还是很紧密的,⽐如 Waiting (⽆限等待)状态中 wait ⽅法是空参的,⽽ Timed Waiting (计时等待)中 wait ⽅ 法是带参的。这种带参的⽅法,其实是⼀种倒计时操作,相当于我们⽣活中的⼩闹钟,我们设定好时 间,到时通知,可是如果提前得到(唤醒)通知,那么设定好时间再通知也就显得多此⼀举了,那么 这种设计⽅案其实是⼀举两得。如果没有得到(唤醒)通知,那么线程就处于 Timed Waiting 状态, 直到倒计时完毕⾃动醒来;如果在倒计时期间得到(唤醒)通知,那么线程从 Timed Waiting 状态⽴刻唤醒。
小结:
线程状态观测
Thread.State
线程状态,线程可以处于一下状态之一:
New:尚未启动的线程处于此状态;
Runnable:在Java虚拟机中执行的线程处于此状态;
Blocked:被阻塞等待监视器锁定的线程处于此状态;
Waiting:正在等待另一个线程执行特定动作的线程出于此状态;
Timed_Waiting:正在等待另一个线程执行动作达到指定时间的线程处于此状态;
Terminated:已退出的线程处于此状态。
一个线程可以在给定时间点处于一个状态。这些状态是不反映任何操作系统线程状态的虚拟机状态。
//观察测试线程的状态
public class TestStat {
public static void main(String[] args) throws InterruptedException { Thread ts = new Thread(()->{
for (int i = 0; i < 5; i++) { try {
Thread.sleep(1000);
} catch (InterruptedException e) { e.printStackTrace(); System.out.println("睡眠异常");
}
}
System.out.println("线程结束");
}) ;
//观察状态
Thread.State state = ts.getState();
System.out.println(state);
//启动后观察ts.start();
state = ts.getState(); System.out.println(state);
//每0.5秒观测一次
while (state != Thread.State.TERMINATED){ //只要线程不终止,就一直输出
Thread.sleep(500); state = ts.getState();
System.out.println(state);
}
}
}线程同步
线程安全
1. 线程安全
如果有多个线程在同时运⾏,⽽这些线程可能会同时运⾏这段代码。程序每次运⾏结果和单线程运⾏的结果是⼀样的,⽽且其他的变量的值也和预期的是⼀样的,就是线程安全的。
我们通过⼀个案例,演示线程的安全问题:
电影院要卖票,我们模拟电影院的卖票过程。假设要播放的电影是 “ 葫芦娃⼤战奥特曼 ” ,本次电影的座位 共 100 个(本场电影只能卖 100 张票)。
我们来模拟电影院的售票窗⼝,实现多个窗⼝同时卖 “ 葫芦娃⼤战奥特曼 ” 这场电影票(多个窗⼝⼀起卖这100 张票)
需要窗⼝,采⽤线程对象来模拟;需要票, Runnable 接⼝⼦类来模拟
模拟票:
public class Ticket implements Runnable {
private int ticket = 100;
/*
* 执⾏卖票操作
*/
@Override
public void run() {
// 每个窗⼝卖票的操作
// 窗⼝ 永远开启
while (true) {
if (ticket > 0) {// 有票 可以卖
// 出票操作
// 使⽤sleep模拟⼀下出票时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
}
}
}测试类
public class Demo {
public static void main(String[] args) {
// 创建线程任务对象
Ticket ticket = new Ticket();
// 创建三个窗⼝对象
Thread t1 = new Thread(ticket, "窗⼝1");
Thread t2 = new Thread(ticket, "窗⼝2");
Thread t3 = new Thread(ticket, "窗⼝3");
// 同时卖票
t1.start();
t2.start();
t3.start();
}
}结果出现了这个现象


发现程序出现了两个问题:
1. 相同的票数,⽐如 1票被卖了两次,10票卖了3次
2. 不存在的票,⽐如 0 票,是不存在的。
这种问题,⼏个窗⼝(线程)票数不同步了,这种问题称为线程安全性问题。
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,⽽⽆写操作,⼀般来说,这个全局变量是线程安全的;若有多个线程同时执⾏写操作,⼀般都需要考 虑线程同步,否则的话就可能影响线程安全。
当我们使⽤多个线程访问同⼀资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题。
要解决上述多线程并发访问⼀个资源的安全性问题:也就是解决重复票与不存在票问题, Java 中提供了同 步机制 ( synchronized ) 来解决。
根据案例简述:
窗⼝1线程进⼊操作的时候,窗⼝2和窗⼝3线程只能在外等着,窗⼝1操作结束,窗⼝1和窗⼝2和窗⼝3才有机会进⼊代码去执⾏。也就是说在某个线程修改共享资源的时候,其他线程不能修改该资源,等待修改完毕同步之后,才能去抢夺CPU资源,完成对应的操作,保证了数据的同步性,解决了线程不安全的现象。
为了保证每个线程都能正常执⾏原⼦操作, Java 引⼊了线程同步机制。
那么怎么去使⽤呢?有三种⽅式完成同步操作:
1. 同步代码块。
2. 同步⽅法。
3. 锁机制。
同步代码块
同步代码块: synchronized 关键字可以⽤于⽅法中的某个区块中,表示只对这个区块的资源实⾏互斥访问。
同步锁:
对象的同步锁只是⼀个概念,可以想象为在对象上标记了⼀个锁。
1. 锁对象,可以是任意类型。
2. 多个线程对象,要使⽤同⼀把锁。
注意:在任何时候,最多允许⼀个线程拥有同步锁,谁拿到锁就进⼊代码块,其他的线程只能在外等 着( BLOCKED )。
public class Ticket implements Runnable {
private int ticket = 100;
Object lock = new Object();
/*
* 执⾏卖票操作
*/
@Override
public void run() {
// 每个窗⼝卖票的操作
// 窗⼝ 永远开启
while (true) {
synchronized (lock) {
if (ticket > 0) {// 有票 可以卖
// 出票操作
// 使⽤sleep模拟⼀下出票时间
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
}
}
}
}
同步⽅法
同步⽅法:使⽤ synchronized 修饰的⽅法,就叫做同步⽅法,保证A线程执⾏该⽅法的时候,其他线程只能在⽅法外等着。
同步锁是谁?
对于⾮ static ⽅法,同步锁就是 this 。
对于 static ⽅法,我们使⽤当前⽅法所在类的字节码对象(类名 .class )。
public class Ticket implements Runnable {
private int ticket = 100;
/*
* 执⾏卖票操作
*/
@Override
public void run() {
// 每个窗⼝卖票的操作
// 窗⼝ 永远开启
while (true) {
sellTicket();
}
}
/*
* 锁对象 是 谁调⽤这个⽅法 就是谁
* 隐含 锁对象 就是 this
*/
public synchronized void sellTicket() {
if (ticket > 0) { // 有票 可以卖
// 出票操作
// 使⽤sleep模拟⼀下出票时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
}
}Lock锁
java.util.concurrent.locks.Lock 机制提供了⽐ synchronized 代码块和 synchronized ⽅法更⼴泛的锁定操作,同步代码块 / 同步⽅法具有的功能 Lock 都有,除此之外更强⼤,更体现⾯向对象。
Lock 锁也称同步锁,创建对象 Lock lock = new ReentrantLock() ,加锁与释放锁⽅法如下:
public void lock() :加同步锁。
public void unlock() :释放同步锁。
public class Ticket implements Runnable {
private int ticket = 100;
// Object lock = new Object();
Lock lock = new ReentrantLock();
/*
* 执⾏卖票操作
*/
@Override
public void run() {
// 每个窗⼝卖票的操作
// 窗⼝ 永远开启
while (true) {
// synchronized (lock) {
lock.lock();
if (ticket > 0) {// 有票 可以卖
// 出票操作
// 使⽤sleep模拟⼀下出票时间
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
lock.unlock();
}
}
}
//}
Lock和synchronized的区别
-
Lock是显式锁(手动开启和关闭锁),synchronized是隐式锁
-
Lock只有代码块锁,synchronized有代码块锁和方法锁
-
Lock可以让等待锁的线程响应中断,使用synchronized只会让等待的线程一直等待下去,不能响应中断
-
synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生; 而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁
-
使用顺序Lock--->同步代码块(已经进入了方法体,分配了相应资源)--->同步方法(在方法体之外)
多线程的锁

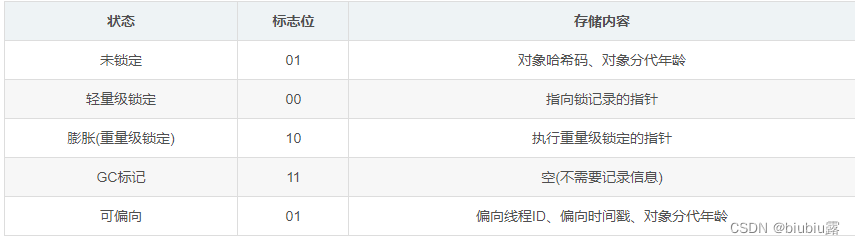
锁的状态
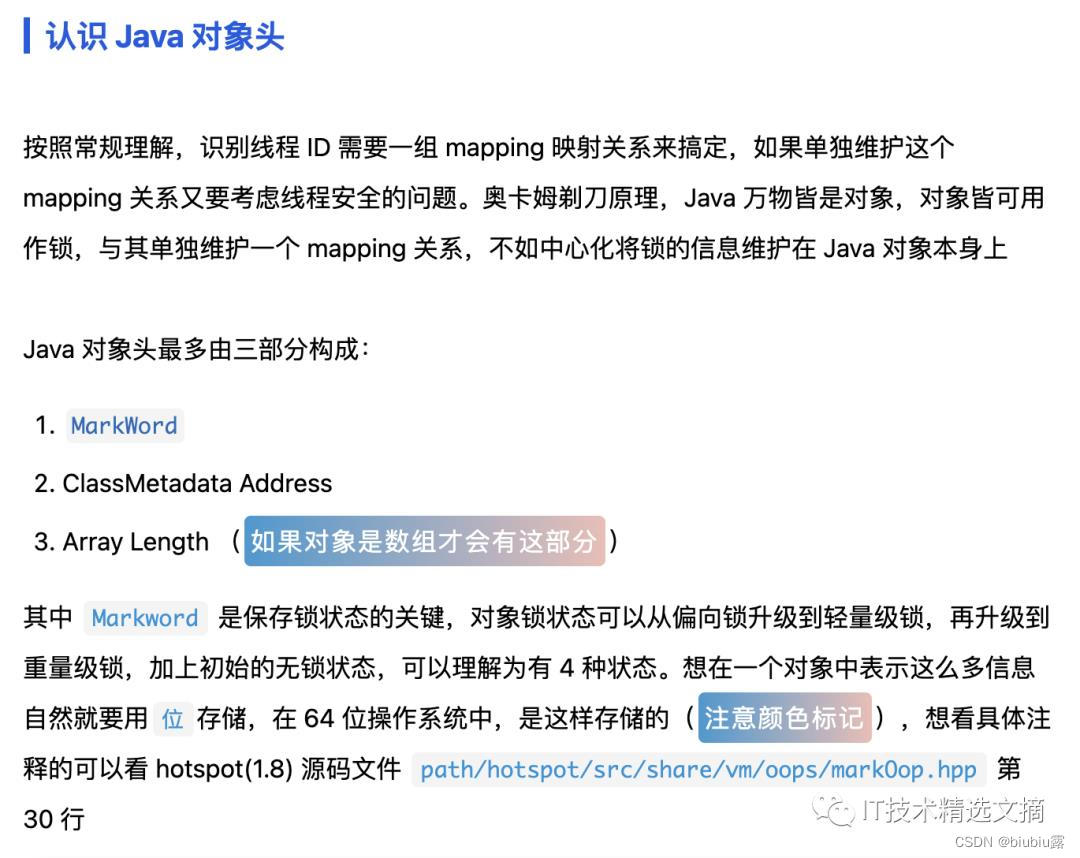
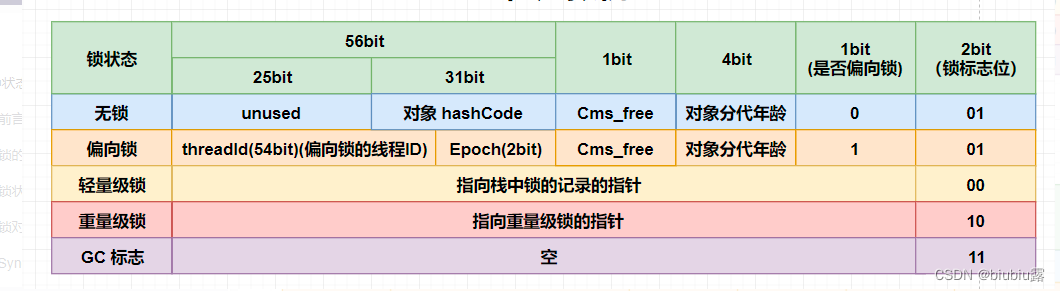
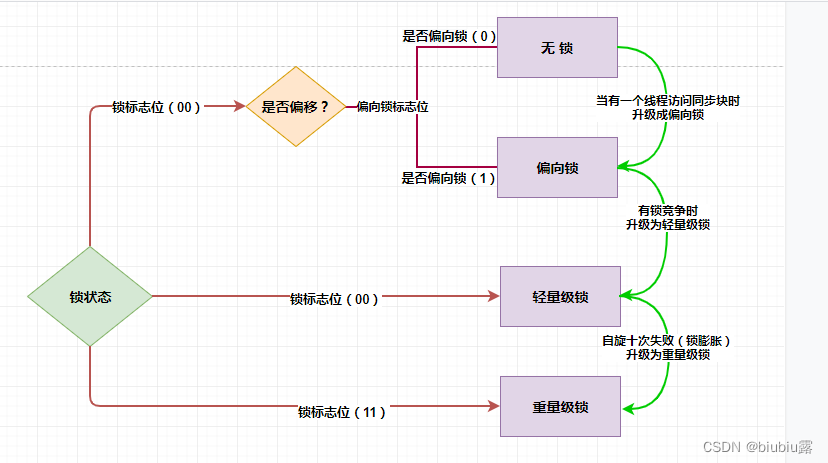
锁的状态总共有四种,级别由低到高依次为:无锁、偏向锁、轻量级锁、重量级锁,这四种锁状态分别代表什么,为什么会有锁升级?其实在 JDK 1.6之前,synchronized 还是一个重量级锁,是一个效率比较低下的锁,但是在JDK 1.6后,Jvm为了提高锁的获取与释放效率对(synchronized )进行了优化,引入了 偏向锁 和 轻量级锁 ,从此以后锁的状态就有了四种(无锁、偏向锁、轻量级锁、重量级锁),并且四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级,也就是说只能进行锁升级(从低级别到高级别),不能锁降级(高级别到低级别),意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
无锁
无锁是指没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点是修改操作会在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。
偏向锁
初次执行到synchronized代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位)
字面意思是“偏向于第一个获得它的线程”的锁。执行完同步代码块后,线程并不会主动释放偏向锁。当第二次到达同步代码块时,线程会判断此时持有锁的线程是否就是自己(持有锁的线程ID也在对象头里),如果是则正常往下执行。由于之前没有释放锁,这里也就不需要重新加锁。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高。
偏向锁是指当一段同步代码一直被同一个线程所访问时,即不存在多个线程的竞争时,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。
当一个线程访问同步代码块并获取锁时,会在 Mark Word 里存储锁偏向的线程 ID。在线程进入和退出同步块时不再通过 CAS 操作来加锁和解锁,而是检测 Mark Word 里是否存储着指向当前线程的偏向锁。轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令即可。
偏向锁的获取流程:
(1)查看Mark Word中偏向锁的标识以及锁标志位,若是否偏向锁为1 且锁标志位为01,则该锁为可偏向状态。
(2)若为可偏向状态,则测试Mark Word中的线程ID是否与当前线程相同,若相同,则直接执行同步代码,否则进入下一步。
(3)当前线程通过CAS操作竞争锁,若竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行同步代码,若竞争失败,进入下一步。
(4)当前线程通过CAS竞争锁失败的情况下,说明有竞争。当到达全局安全点时之前获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。
偏向锁的释放流程:
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁状态的线程才会释放锁,线程不会主动去释放偏向锁。
关于偏向锁的撤销,需要等待全局安全点,即在某个时间点上没有字节码正在执行时,它会先暂停拥有偏向锁的线程,然后判断锁对象是否处于被锁定状态。如果线程不处于活动状态,则将对象头设置成无锁状态,并撤销偏向锁,恢复到无锁(标志位为01)或轻量级锁(标志位为00)的状态。
轻量级
轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,线程不会阻塞,从而提高性能。
轻量级锁的获取主要由两种情况:
① 当关闭偏向锁功能时;
② 由于多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
一旦有第二个线程加入锁竞争,偏向锁就升级为轻量级锁(自旋锁)。这里要明确一下什么是锁竞争:如果多个线程轮流获取一个锁,但是每次获取锁的时候都很顺利,没有发生阻塞,那么就不存在锁竞争。只有当某线程尝试获取锁的时候,发现该锁已经被占用,只能等待其释放,这才发生了锁竞争。
在轻量级锁状态下继续锁竞争,没有抢到锁的线程将自旋,即不停地循环判断锁是否能够被成功获取。获取锁的操作,其实就是通过CAS修改对象头里的锁标志位。先比较当前锁标志位是否为“释放”,如果是则将其设置为“锁定”,比较并设置是原子性发生的。这就算抢到锁了,然后线程将当前锁的持有者信息修改为自己。
长时间的自旋操作是非常消耗资源的,一个线程持有锁,其他线程就只能在原地空耗CPU,执行不了任何有效的任务,这种现象叫做忙等(busy-waiting)。如果多个线程用一个锁,但是没有发生锁竞争,或者发生了很轻微的锁竞争,那么synchronized就用轻量级锁,允许短时间的忙等现象。这是一种折衷的想法,短时间的忙等,换取线程在用户态和内核态之间切换的开销。
轻量级锁的加锁过程:
(1) 当线程执行代码进入同步块时,若Mark Word为无锁状态,虚拟机先在当前线程的栈帧中建立一个名为Lock Record的空间,用于存储当前对象的Mark Word的拷贝,官方称之为“Dispalced Mark Word”
(2) 复制对象头中的Mark Word到锁记录中。
(3) 复制成功后,虚拟机将用CAS操作将对象的Mark Word更新为执行Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。如果更新成功,则执行4,否则执行5。;
(4) 如果更新成功,则这个线程拥有了这个锁(没有竞争发生),并将锁标志设为00,表示处于轻量级锁状态
(5) 如果更新失败,虚拟机会检查对象的Mark Word是否指向当前线程的栈帧,如果是则说明当前线程已经拥有这个锁,可进入执行同步代码。否则说明多个线程竞争,轻量级锁就会膨胀为重量级锁,Mark Word中存储重量级锁(互斥锁)的指针,后面等待锁的线程也要进入阻塞状态。
轻量级锁的解锁过程
1.通过CAS操作尝试把线程中复制的Displaced Mark Word对象替换当前的Mark Word。
2.如果替换成功,整个同步过程就完成了。
3.如果替换失败,说明有其他线程尝试过获取该锁(此时锁已膨胀),那就要在释放锁的同时,唤醒被挂起的线程。
重量级锁
(线程过多或长耗时操作,线程自旋过度消耗cpu)当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。

随着竞争不断的加剧,锁要不断的升级。
(1)无锁:适用于单线程
(2)偏向锁:适用于只有一个线程访问同步块的情况,因为多个线程同时访问同步块,给某一个线程特权是不合理的
(3)轻量级锁:竞争不是太多,循环等待消耗CPU资源的线程的数量在可接受的范围
(4)重量级锁:多个线程同时竞争资源,只让一个线程运行,其余的线程都阻塞
悲观锁和乐观锁
悲观锁和乐观锁是一种广义的概念,体现的是看待线程同步的不同的角度
悲观锁认为自己在使用数据的时候,一定有别的线程来修改数据,在获取数据的时候会先加锁,确保数据不会被别的线程修改。
锁实现:关键字synchronized、接口Lock的实现类
使用的场景:写操作较多,先加锁可以保证写操作是数据正确
乐观锁认为自己在使用数据的时候不会有其他的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据
锁实现:CAS算法
使用场景:读操作较多,不加锁的特点能够使其读操作的性能大幅提升
阻塞和自旋锁
阻塞:是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程就处于阻塞状态
自旋:是指当一个线程在获取锁的饿时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断判断是否能够被成功获取,自旋知道获取到锁才会退出循环。自旋是通过CAS算法进行的。何为CAS算法呢?
CAS(compare and swap):比较和交换,顾名思义就是先进行比较然后在进行交换。这里比较和交换是线程中的数据和内存中的数据之间的操作。
如下图所示:1 .线程1和线程2都读取内存中的数据V赋值给A
2. 线程1把V的值由0改为了1,并想把修改后的值写回到内存
3. 线程1将A的值和V的值进行比较
4 .两者相等,说明没有线程对V的值进行修改,直接把修改后的值(B=1)写入内存,此时,V=1。3 线程2进行将A的值和V的值进行比较
5 .两者不相等,说明有线程对V的值进行修改,此时线程2不能够把修改后的值写入内存,因为它获得的A的值不是最新的,由A得到的B的值也可能是错误的。线程2会读取A的值,重新计算出B的值,再尝试重新写入,如果还是不相等在继续尝试,不断的自旋。

我们发现CAS算法存在一个非常明显的缺陷,那就是ABA问题。何为ABA问题呢?
如下图所示:线程1 线程2 线程3 都获取A=V=0
1 线程1修改V的值为1 写入内存
2 线程2 把v的值改为2,但是没来的及写入,线程3 就开始运行
3 线程3 将V的值改为0 写入内存
4 线程2 比较A和V的值发现A=V,他自认为没有其他的线程对V进行修改,因而忽略了A->B->A的过程,形成了ABA问题。ABA的问题解决方法很简单:AtomicStampedReference在变量前面添加版本号,每次变量更新的时候都把版本号加一。

举一个例子:
小明在提款机,提取了50元,因为提款机问题,产生了两个修改账户余额的线程(可以看做是上面描述的线程1和线程2),假设小明账户原本有100元,因此两个线程同时执行把余额从100变为50的操作。
线程1(提款机):获取当前值100,期望更新为50。
线程2(提款机):获取当前值100,期望更新为50。
线程1成功执行,CPU并没有调度线程2执行,这时,某人给小明汇款50
,这一操作产生一个线程进行执行,命名为线程3。CPU调度线程3执行,
这时候线程3成功执行,余额变为100。
之后,线程2被CPU调度执行,此时,获取到的账户余额是100,CAS操作成功执行,更新余额为50!!!
此时可以看到,实际余额应该为100(100-50+50),但是实际上变为了50(100-50+50-50)这就是ABA问题带来的错误。
可重入锁和不可重入锁
可重入锁
也可称为可递归锁(recursive mutex),当线程获取某个锁后,还可以继续获取它,可以递归调用,而不会发生死锁;典型的就是Synchronized和Reentrantlock。
不可重入锁
也可称为非递归锁(non-recursive mutex),获取锁后不能重复获取,否则会死锁(自己锁自己)。
区别:二者唯一的区别是,同一个线程可以多次获取同一个递归锁,不会产生死锁。而如果一个线程多次获取同一个非递归锁,则会产生死锁。
隐式锁(即synchronized关键字使用的锁)默认是可重入锁,显式锁(即Lock)也有ReentrantLock这样的可重入锁。
公平锁和非公平锁
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
-
优点:所有的线程都能得到资源,不会饿死在队列中。
-
缺点:吞吐量()吞吐量是指对网络、设备、端口、虚电路或其他设施,单位时间内成功地传送数据的数量(以比特、字节、分组等测量)吞吐量()会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
-
优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
-
缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
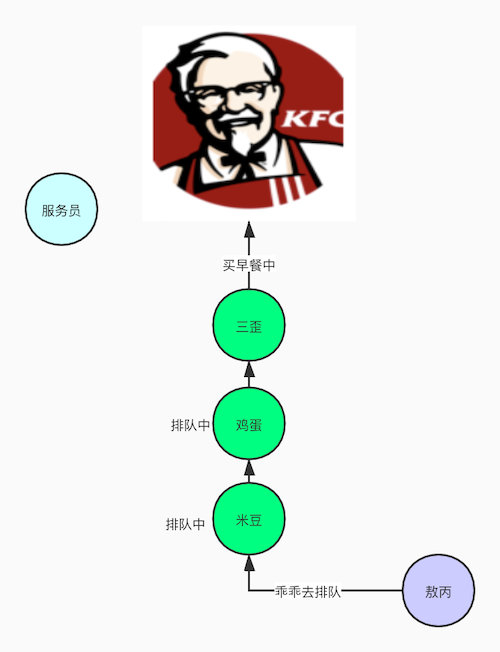
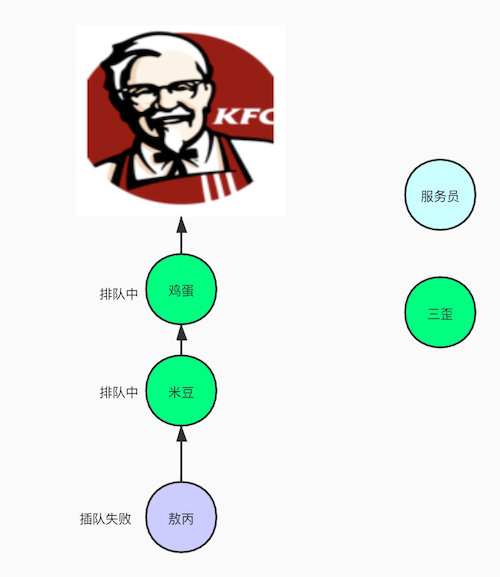
我举个例子给他家通俗易懂的讲一下的,想了好几天终于在前天跟三歪去肯德基买早餐排队的时候发现了怎么举例了。
现在是早餐时间,敖丙想去kfc搞个早餐,发现有很多人了,一过去没多想,就乖乖到队尾排队,这样大家都觉得很公平,先到先得,所以这是公平锁咯。
那非公平锁就是,敖丙过去买早餐,发现大家都在排队,但是敖丙这个人有点渣的,就是喜欢插队,那他就直接怼到第一位那去,后面的鸡蛋,米豆都不行,我插队也不敢说什么,只能默默忍受了。
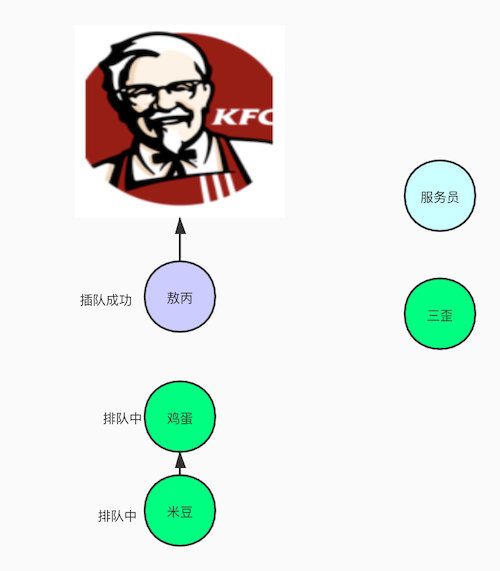
但是偶尔,鸡蛋也会崛起,叫我滚到后面排队,我也是欺软怕硬,默默到后面排队,就插队失败了。
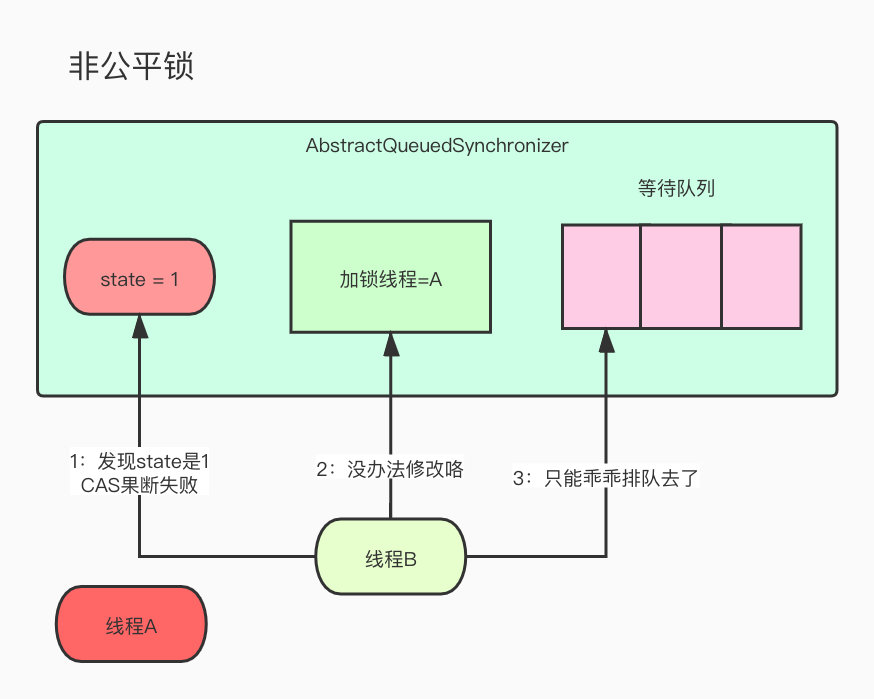
A线程准备进去获取锁,首先判断了一下state状态,发现是0,所以可以CAS成功,并且修改了当前持有锁的线程为自己。

这个时候B线程也过来了,也是一上来先去判断了一下state状态,发现是1,那就CAS失败了,真晦气,只能乖乖去等待队列,等着唤醒了,先去睡一觉吧。
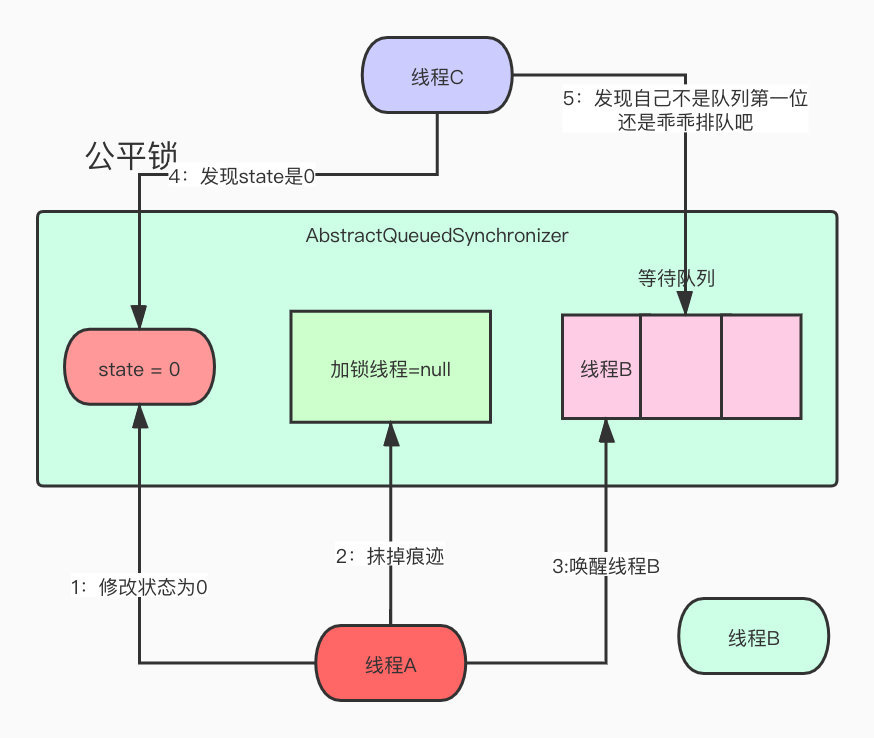
A持有久了,也有点腻了,准备释放掉锁,给别的仔一个机会,所以改了state状态,抹掉了持有锁线程的痕迹,准备去叫醒B。
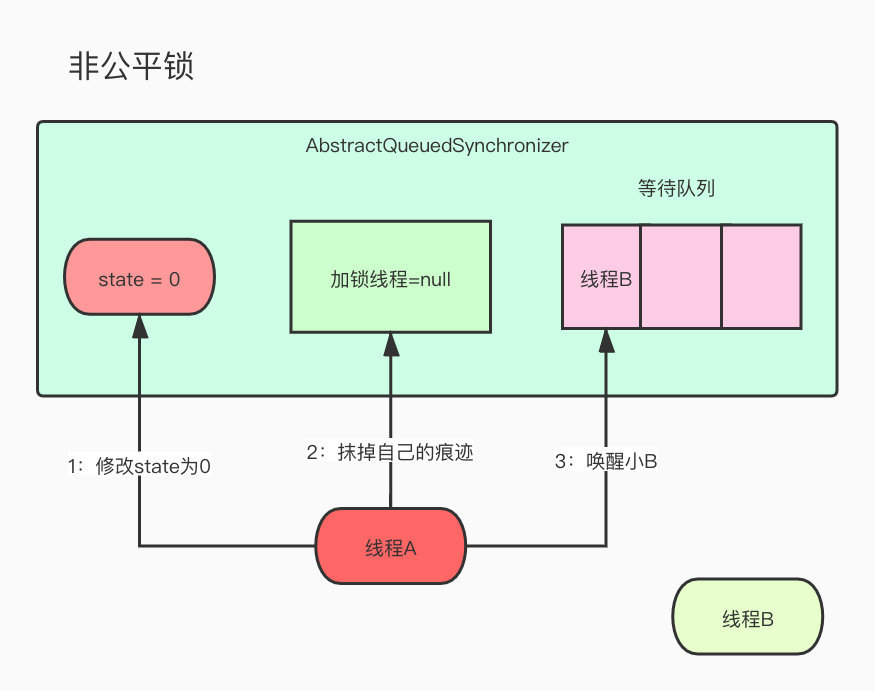
这个时候有个带绿帽子的仔C过来了,发现state怎么是0啊,果断CAS修改为1,还修改了当前持有锁的线程为自己。
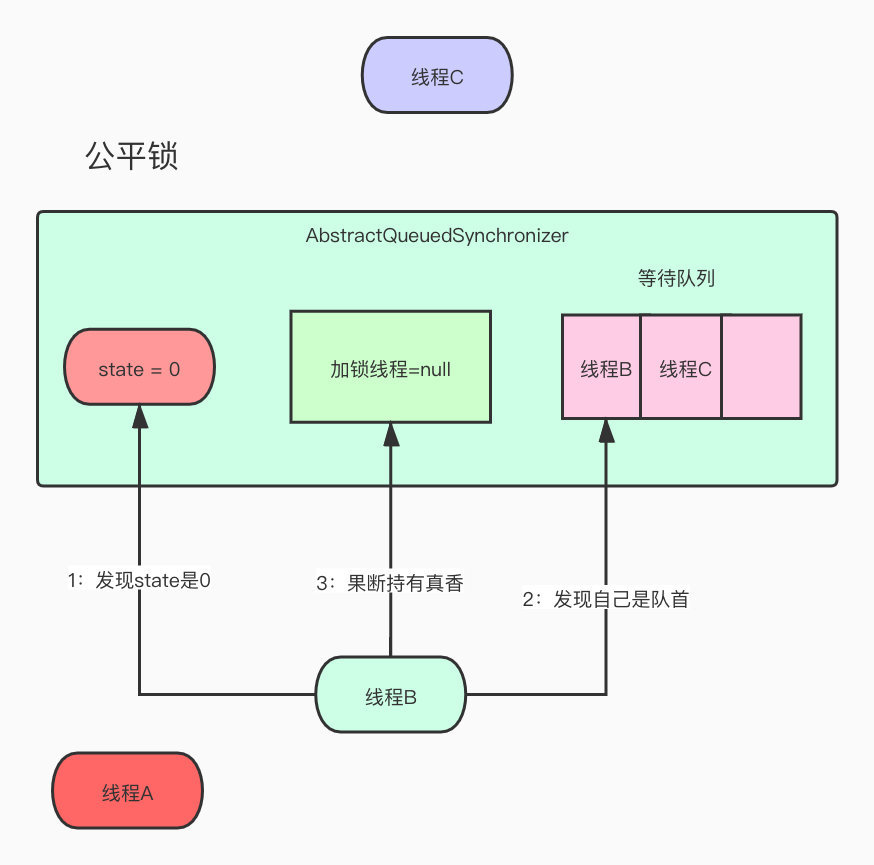
B线程被A叫醒准备去获取锁,发现state居然是1,CAS就失败了,只能失落的继续回去等待队列,路线还不忘骂A渣男,怎么骗自己,欺骗我的感情。
诺以上就是一个非公平锁的线程,这样的情况就有可能像B这样的线程长时间无法得到资源,优点就是可能有的线程减少了等待时间,提高了利用率。
现在都是默认非公平了,想要公平就得给构造器传值true。
ReentrantLock lock = new ReentrantLock(true);
说完非公平,那我也说一下公平的过程吧:
线A现在想要获得锁,先去判断下state,发现也是0,去看了看队列,自己居然是第一位,果断修改了持有线程为自己。

线程b过来了,去判断一下state,嗯哼?居然是state=1,那cas就失败了呀,所以只能乖乖去排队了。
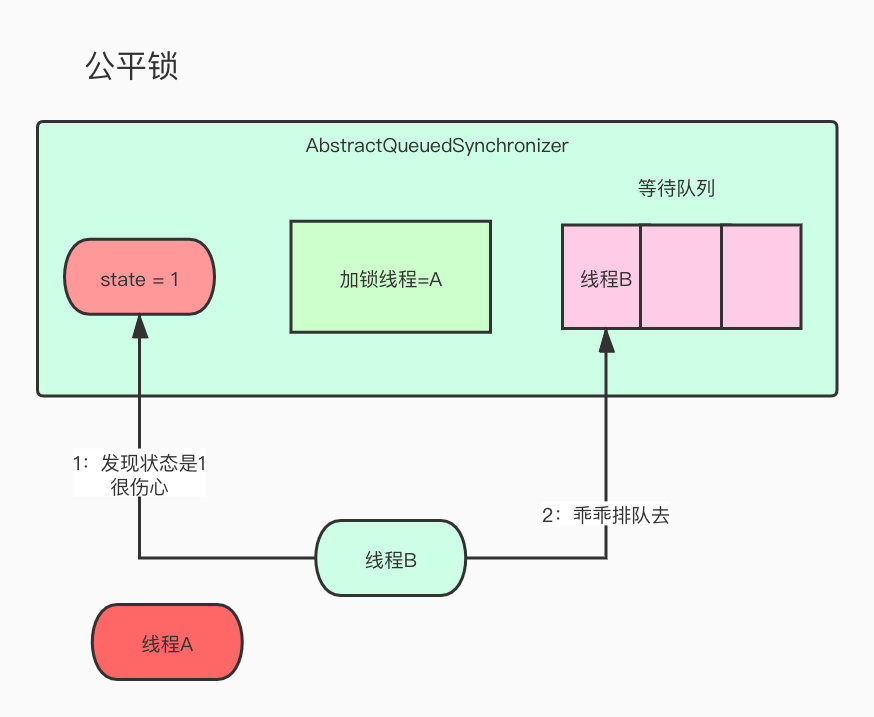 未命名文件 (https://tva1.sinaimg.cn/large/00831rSTly1gcxaojuen2j30oa0jxgmh.jpg)
未命名文件 (https://tva1.sinaimg.cn/large/00831rSTly1gcxaojuen2j30oa0jxgmh.jpg)
线程A暖男来了,持有没多久就释放了,改掉了所有的状态就去唤醒线程B了,这个时候线程C进来了,但是他先判断了下state发现是0,以为有戏,然后去看了看队列,发现前面有人了,作为新时代的良好市民,果断排队去了。
线程B得到A的召唤,去判断state了,发现值为0,自己也是队列的第一位,那很香呀,可以得到了。
互斥锁和共享锁
互斥锁:在访问共享资源之前对进行加锁操作,在访问完成之后进行解锁操作。 加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前进程解锁。
共享锁:共享锁从字面来看也即是允许多个线程共同访问资源。
互斥锁很容易理解,上锁之后,其他线程都阻塞了。
共享锁一个典型的例子就是读者写者模式,一个人写多个人去读,写者写出的东西,多个读者是可以一块去读的,这就是多个读者共享一个同步资源。
共享锁--用到共享锁的有Semapore信号量和ReadLock读锁
死锁
死锁是指两个或者两个以上的线程在执行的过程中,因争夺资源产生的一种互相等待的现象
产生死锁的原因
● 系统资源的竞争
通常系统中拥有的不可剥夺资源,其数量不足以满足多个进程运行的需要,使得进程在 运行过程中,会因争夺资源而陷入僵局,如磁带机、打印机等。只有对不可剥夺资源的竞争 才可能产生死锁,对可剥夺资源的竞争是不会引起死锁的。
● 进程推进顺序非法
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。例如,并发进程 P1、P2分别保持了资源R1、R2,而进程P1申请资源R2,进程P2申请资源R1时,两者都 会因为所需资源被占用而阻塞
产生死锁的四个必要条件
● 互斥条件(Mutual exclusion)
资源不能被共享,只能由一个进程使用。
● 请求与保持条件(Hold and wait)
进程已获得了一些资源,但因请求其它资源被阻塞时,对已获得的资源保持不放。
● 不可抢占条件(No pre-emption)
有些系统资源是不可抢占的,当某个进程已获得这种资源后,系统不能强行收回,只能由进程使用完时自己释放。
● 循环等待条件(Circular wait)
若干个进程形成环形链,每个都占用对方申请的下一个资源。
死锁的解决方式
● 加锁顺序
线程按照一定的顺序加锁,只有获得了从顺序上排在前面的锁之后,才能获取后面的锁
● 加锁时限
线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁
● 死锁检测
判断系统是否处于死锁状态
● 死锁避免
指进程在每次申请资源时判断这些操作是否安全。例如银行家算法:在分配资源之前先看清楚,资源分配后是否会导致系统死锁。如果会死锁,则不分配,否则就分配。
银行家算法是操作系统的经典算法之一,用于避免死锁情况的出现。
它最初是为银行设计的(因此得名),通过判断借贷是否安全,然后决定借不借。
在银行中,客户申请贷款的数量是有限的,每个客户在第一次申请贷款时要声明完成该项目所需的最大资金量,在满足所有贷款要求时,客户应及时归还。银行家在客户申请的贷款数量不超过自己拥有的最大值时,都应尽量满足客户的需要。
用在操作系统中,银行家、出借资金、客户,就分别对应操作系统、资源、申请资源的进程。每一个新进程进入系统时,必须声明需要每种资源的最大数目,其数目不能超过系统所拥有的的资源总量。当进程请求一组资源时,系统必须首先确定是否有足够的资源分配给该进程,若有,再进一步计算在将这些资源分配给进程后,是否会使系统处于不安全状态如果不会才将资源分配给它,否则让进程等待。
线程池
基本概念
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。
在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗
通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度
当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性
线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
为了更好的理解线程池的概念我们引入下边这个例子:
在我们找工作时,面试结束之后会面临两个结果,1是已经通过oc(offer call),2是没有通过,但是公司不会直接告诉你你没有通过,而是完全不通知(公司会把你放到“人才储备池”里),此时假设A公司要招100人而目前只招够了60个人,剩下的40个名额公司将会从“人才储备池”中直接挑选hc(head count),直接发offer,从而避免了需要再次笔试面试等一系列的流程来招纳新人。
用户态与内核态
用户态就是应用程序执行的代码,内核态就是操作系统内核执行的代码,一般认为,用户态和内核态之间的切换,是一个开销比较大的操作。
比如我们去银行办理业务时,需要去复印一份文件,如果我们自己去复印,就能够很快的完成并交给工作人员,但如果让工作人员去完成这个打印文件的工作就会比较耗费时间(工作人员需要完成的工作很多,不能及时调度去完成打印文件工作)。
此时的我们便是用户态,工作人员便是内核态。
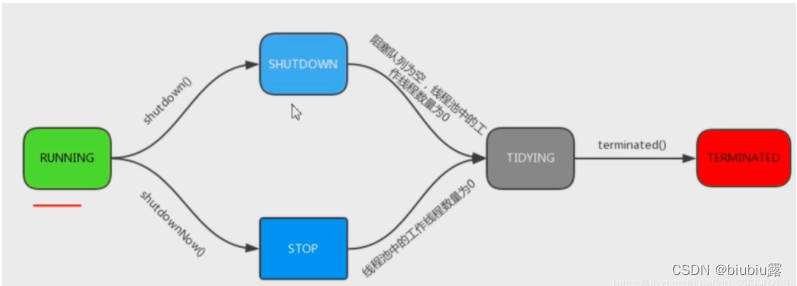
线程池的五种状态
1. Running 能接受新任务以及处理已添加的任务
2. Shutdown 不接受新任务,可以处理已经添加的任务
3. Stop 不接受新任务,不处理已经添加的任务,并且中断正在处理的任务
4. Tidying 所有的任务已经终止,ctl记录的”任务数量”为0, ctl负责记录线程池的运行状态与活动线程数量
5. Terminated 线程池彻底终止,则线程池转变为terminated状态
java自带线程池工具
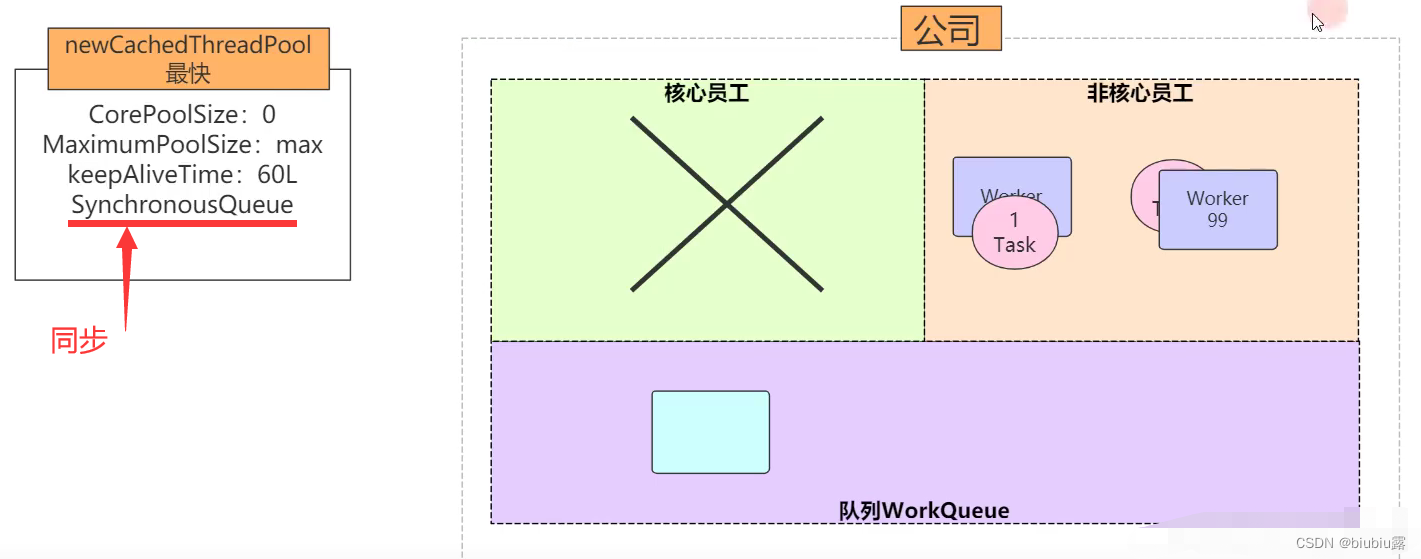
newCachedThreadPool——不推荐使用
源码
底层使用ThreadPoolExector
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点
没有核心线程,等待队列使用同步队列,出现一个任务就创建一个临时线程去执行任务
问题
不会出现内存溢出,但是会浪费CPU资源,导致机器卡死。
newFixedThreadPool——不推荐使用
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点
特定核心线程,无临时线程。等待队列使用链表,等待队列无限长度
问题
会导致内存溢出,因为等待队列无限长。

newSingleThreadExecutor——不推荐使用
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
特点
创建一个单线程化的线程池, 它只会用唯一的工作线程来执行任务, 保证所有任务按照指定顺序(FIFO,LIFO, 优先级)执行。
只有一个核心线程,依次执行任务。

newscheduledThreadPool
创建一个定长线程池, 支持定时及周期性任务执行。
延时执行
下面例子是4s之后执行run方法
public static void pool4() {
ScheduledExecutorService newScheduledThreadPool =
Executors.newScheduledThreadPool(5);
//延时执行的线程池
//参数:任务 延时时间 时间单位
newScheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println("i:" + 1);
}
}, 4, TimeUnit.SECONDS);
}
周期性执行任务
下面例子中,设置了一个定时任务,线程开启后,3s后执行任务,每4s执行一次
public static void pool4() {
ScheduledExecutorService newScheduledThreadPool =
Executors.newScheduledThreadPool(5);
//延时执行的线程池
//参数:任务 延时时间 间隔时间 时间单位
newScheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("i:" + 1);
}
}, 3, 4, TimeUnit.SECONDS);
}线程池核心方法与体系结构
线程池最基础的框架

public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
ThreadPoolExecutor
ThreadPoolExecutor参数说明
corePoolSize :核心线程数(正式员工的数量)
maximumPoolSize:最大线程数(正式工+临时工)
keepAliveTime:线程保持活动的时间(描述临时工摸鱼可以摸多久)
unit:keepAliveTime的时间单位(ms,s,minute)
workQueue:阻塞队列,组织了线程池要执行的任务
threadFactory:线程的创建方式,通过这个参数,来设定不同的线程的创建方式
RejectedExecutionHandler:拒绝策略,当任务队列满了的时候,又来了新的任务,要根据具体的业务场景来选取具体的拒绝策略
我们可以把线程池想象成一个“公司”,公司里面的每个员工,就相当于是一个线程。
员工分为两类:
1,正式工(corePoolSize):签了劳动合同的,不能随便辞退
2,临时工:没有签劳动合同,随时可以踢掉
正式员工允许摸鱼(这样的线程即使是空闲,也不会被销毁)
临时工不允许摸鱼(如果临时工线程摸鱼的时间到了一定程度,就会被销毁)
如果我们要解决的任务场景任务量比较稳定,就可以设置corePoolSize和maximumPoolSize尽量接近(临时工就可以少一些)
如果我们要解决的任务场景任务量波动较大,既可以设置corePoolSize和maximumPoolSize相差大一些(临时工就可以多一些)
线程池的数目如何确定?或者说设置成几比较合适?
我们并不能给出确定的具体个数,原因有以下两点:
1.主机的CPU配置不确定
2.程序的执行特点不确定
所以只有针对程序进行性能测试,分别给线程池设置成不同的数目,分别记录每种情况,才能最终选一个合适的配置。
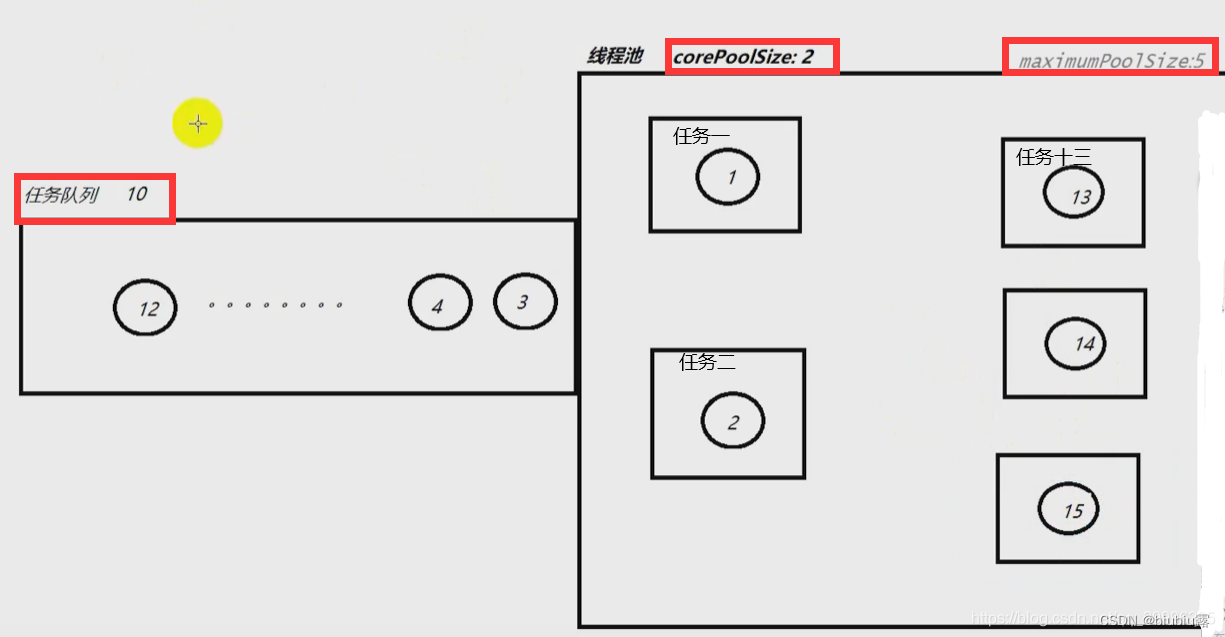
假设ThreadPoolExecutor创建的核心线程数为2,等待队列长度为10,最大线程数为5 .则每个任务来的时候,线程的创建顺序如下:任务一和任务二来的时候,分别会创建一个核心线程并执行该任务
任务三到十二来的时候,核心线程已满,需要进入等待队列等待
任务十三到十五来的时候,核心线程和等待队列均已满,所以创建额外线程去执行任务
任务十六来的时候,由于整个线程池都已沾满,因此根据饱和(拒绝)策略做出反馈
SynchronousQueue
synchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
使用synchronousQueue阻塞队列一般要求maximumRoolsizes为无界,避免线程拒绝执行操作。
当队列中没有任务时,获取任务的动作会被阻塞;
当队列中有任务时,存入任务的动作会被阻塞
LinkedBlockingQueue
LinkedBlockingQueue是个无界缓存等待队列。
当前执行的线程数量达到corePoolsize的数量时,剩余的元素会在阻塞队列里等待。(所以在使用此阻塞队列时max imumPoolsizes就相当于无效了),每个线程完全独立于其他线程。
生产者和消费者使用独立的锁来控制数据的同步,即在高并发的情况下可以并行操作队列中的数据。
ArrayBlockingQueue
ArrayBlockingQueue是一个有界缓存等待队列,可以指定缓存队列的大小
当正在执行的线程数等于corePoolsize时,多余的元素缓存在ArrayBlockingQueue队列中等待有空闲的线程时继续执行
当ArrayBlockingQueue已满时,加入ArrayBlockingQueue失败, 会开启新的线程去执行
当线程数已经达到最大的maximumPoolsizes时, 再有新的元素尝试加入ArrayBlocki ngQueue时会报错。
线程池四种拒绝策略

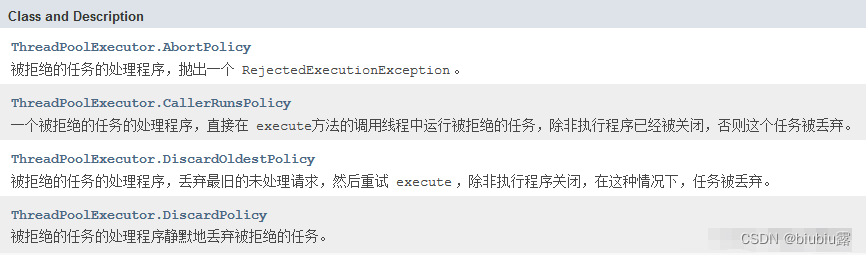
以老板给员工分配工作的任务为例,来引出这四种拒绝策略:(员工相当于线程池)
1.老板给员工分配了很多任务,员工即使加班也无法完成工作,导致情绪崩溃,所有的工作都不干了。(AbortPolicy 线程池会抛出异常并中止执行此任务;)
2.老板给员工分配了很多任务,员工完不成的老板接手,如果老板也无法完成,就丢弃任务。(CallerRunsPolicy 把任务交给添加此任务的线程来执行;)
3.老板给员工安排了工作1、2、3、4,此时员工搞不定了,就可以先丢弃工作1(最旧的),去干其他的工作。(DiscardOldestPolicy 忽略最先加入队列的任务(最老的任务);)
4.老板给员工安排了工作1、2、3、4,此时员工搞不定了,就可以先丢弃工作4(最新的),去干其他的工作。(DiscardPolicy 忽略此任务(最新加入的任务)。)
/* Predefined RejectedExecutionHandlers */
/**
* A handler for rejected tasks that runs the rejected task
* directly in the calling thread of the {@code execute} method,
* unless the executor has been shut down, in which case the task
* is discarded.
*/
// 不抛弃任务,请求调用线程池的主线程(比如main),帮忙执行任务
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
/**
* A handler for rejected tasks that throws a
* {@link RejectedExecutionException}.
*
* This is the default handler for {@link ThreadPoolExecutor} and
* {@link ScheduledThreadPoolExecutor}.
*/
// 抛出异常,丢弃任务
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
/**
* A handler for rejected tasks that silently discards the
* rejected task.
*/
// 直接丢弃任务,丢弃等待时间最短的任务
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
/**
* A handler for rejected tasks that discards the oldest unhandled
* request and then retries {@code execute}, unless the executor
* is shut down, in which case the task is discarded.
*/
// 直接丢弃任务,丢弃等待时间最长的任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}关闭线程池
可以通过调用线程池的shutdown()或者shutdownNow()来关闭线程池,它的原理是遍历线程池中所有的线程,然后逐个调用线程的interrupt()方法中断线程,所以无法响应中断的任务有可能永远无法终止。
二者的区别是:
shutdownNow()首先iang线程池的状态设为STOP,然后尝试停止所有正在执行或暂停的线程,并返回等待执行任务的列表。
shutdown()知识将线程池的状态设置为SHUTDOWN,然后中断所有没有正在执行的任务。
通常调用shutdown()方法关闭线程池,如果线程池中的任务不一定要执行完,可以调用shutdownNow()方法。
//等待任务队列所有的任务执行完毕后才关闭
executor.shutdown();
//立刻关闭线程池
executor.shutdownNow();
实现线程池
核心操作为 submit, 将任务加入线程池阻塞队列中,并创建线程
使用一个 BlockingQueue 组织所有的任务
一个线程池可以同时提交N个任务,对应的线程池中有M个线程来负责完成这N个任务,利用生产者消费者模型,把N个任务分配给M个线程
使用ThreadPoolExecutor自定义创建线程池
public class ThreadPool {
//设置核心池大小
int corePoolSize = 5;
//设置线程池最大能接受多少线程
int maximumPoolSize =20;
//当前线程数大于corePoolSize、小于maximumPoolSize时,
超出corePoolSize的线程数的生命周期
long keepActiveTime = 200;
//设置时间单位,秒
TimeUnit timeUnit = TimeUnit.SECONDS;
//设置线程池缓存队列的排队策略为FIFO,并且指定缓存队列大小为5
BlockingQueue<Runnable> workQueue =
new ArrayBlockingQueue<Runnable>(5);}public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool();
//创建ThreadPoolExecutor线程池对象,并初始化该对象的各种参数
ThreadPoolExecutor executor = new ThreadPoolExecutor(threadPool.corePoolSize,
threadPool.maximumPoolSize,threadPool.keepActiveTime,
threadPool.timeUnit,threadPool.workQueue);
for (int i = 0; i < 15; i++) {
MyTask myTask = new MyTask(i);
//开启线程
executor.execute(myTask);
System.out.println("线程池中线程数目"+executor.getPoolSize()+
",队列中等待执行的任务数目:"+executor.getQueue().size()+
"已执行完的任务数目"+executor.getCompletedTaskCount());
}
//关闭线程池
executor.shutdown();
}
}
class MyTask implements Runnable{
private int num ;
public MyTask(int num) {
this.num = num;
}
@Override
public void run() {
System.out.println("正在执行task"+num);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task"+num+"执行完毕");
}
}线程池工作流程
线程池的工作流程
判断核心线程数
判断任务能否加入到任务队列
判断最大线程数量
根据线程池的拒绝策略处理任务
提交优先级和执行优先级
提出问题
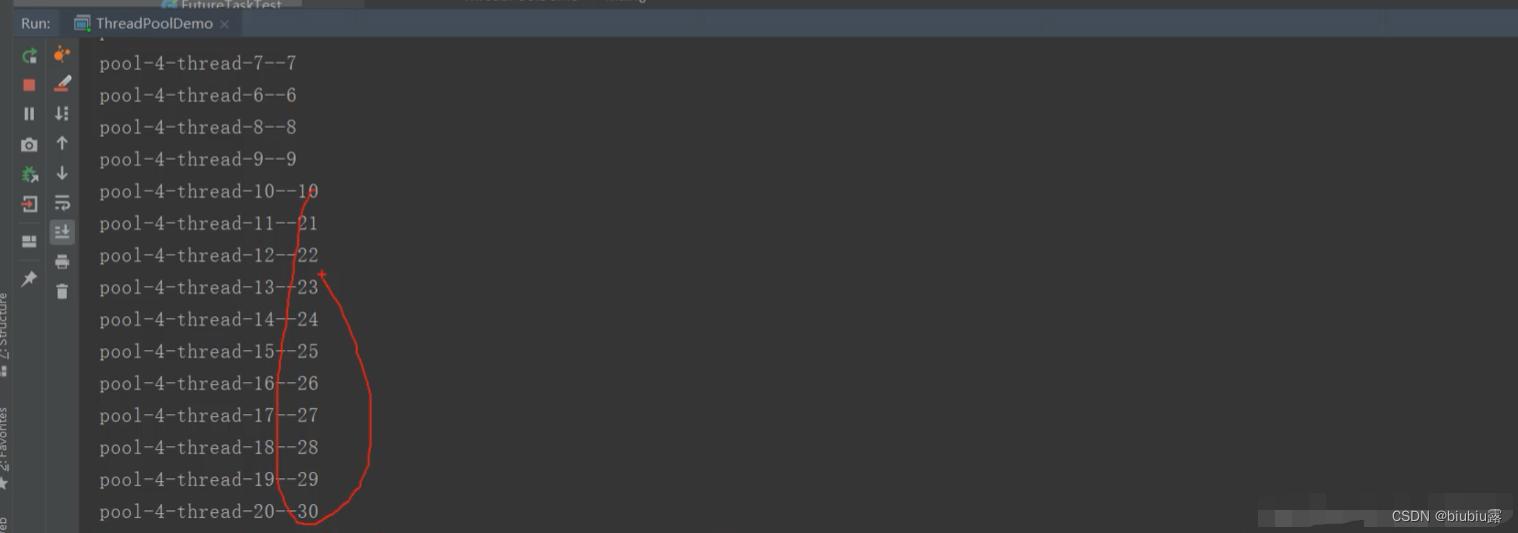
使用线程池,设置核心线程数为10,最大额外线程数为20,执行任务时,输出结果不是按序输出,而是如图,10之后直接跳到21。:
线程池的提交优先级和执行优先级
线程池的提交优先级顺序为 核心线程>等待队列>额外线程

执行优先级为: 核心线程>额外线程>等待队列
因此输出数据顺序是 1-10,21-30,11-19
源码验证
ThreadPoolExector类中的execute方法源码
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
代码分析
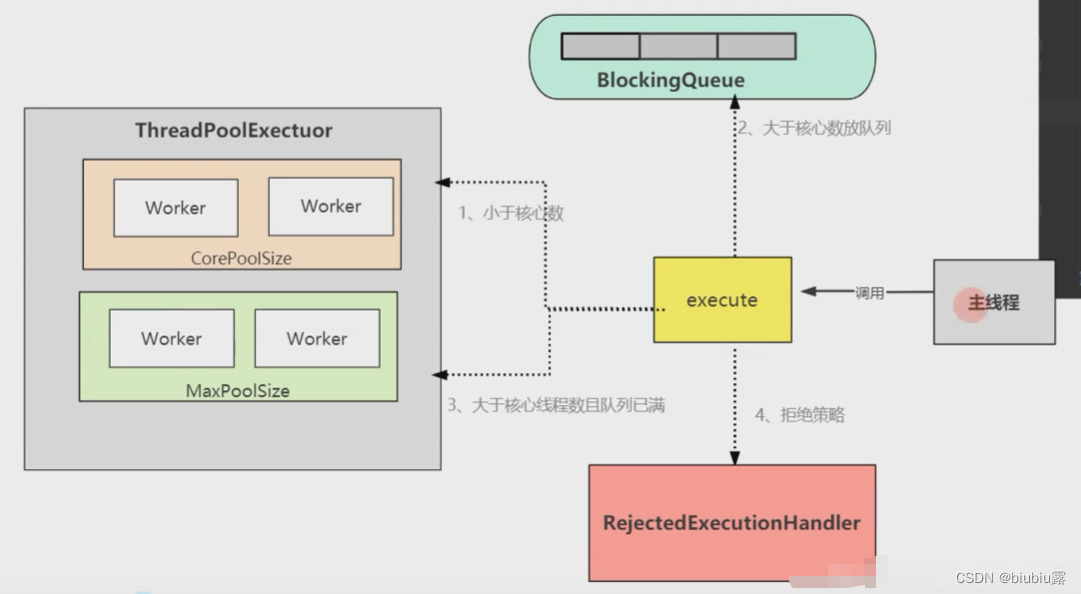
线程池处理流程
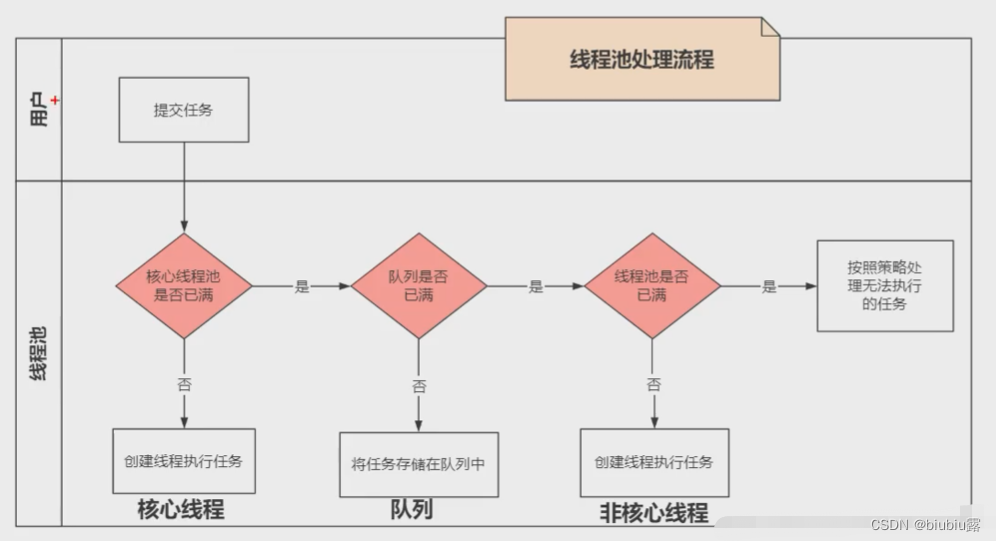
1.当新加入一个任务时,先判断当前线程数是否大于核心线程数,如果结果为false,则新建线程并执行任务;
2.如果结果为true,则判断任务队列是否已满,如果结果为false,则把任务添加到任务队列中,等待线程执行
3.如果结果为true,则判断当前线程数量是否超过最大线程数;如果结果为false,则新建线程执行此任务
4.如果结果为true,执行拒绝策略。















 5609
5609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









