







1.比赛内容:用户新增预测挑战赛教程
(原文转载自飞书云文档,本人笔记与实验代码也放到一起Docs https://datawhaler.feishu.cn/docx/HBIHd7ugzoOsMqx0LEncR1lJnCf)
https://datawhaler.feishu.cn/docx/HBIHd7ugzoOsMqx0LEncR1lJnCf)
赛题解析与解题思路
用户新增预测挑战赛:
举办方:科大讯飞
赛题背景
讯飞开放平台针对不同行业、不同场景提供相应的AI能力和解决方案,赋能开发者的产品和应用,帮助开发者通过AI解决相关实际问题,实现让产品能听会说、能看会认、能理解会思考。
用户新增预测是分析用户使用场景以及预测用户增长情况的关键步骤,有助于进行后续产品和应用的迭代升级。
赛事任务
本次大赛提供了讯飞开放平台海量的应用数据作为训练样本,参赛选手需要基于提供的样本构建模型,预测用户的新增情况。
赛题数据集
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
*这里需要认真读题,分析题目中的数据类型,特征数据,唯一标识等等
评价指标
本次竞赛的评价标准采用f1_score,分数越高,效果越好
---------------------------------------------------------------------------------------------------------------------------------
什么是F1-score
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
来自机器学习中的F1-score__Yucen的博客-CSDN博客
---------------------------------------------------------------------------------------------------------------------------------
解题思路
参赛选手的任务是基于训练集的样本数据,构建一个模型来预测测试集中用户的新增情况。这是一个二分类任务,其中目标是根据用户的行为、属性以及访问时间等特征,预测该用户是否属于新增用户。具体来说,选手需要利用给定的数据集进行特征工程、模型选择和训练,然后使用训练好的模型对测试集中的用户进行预测,并生成相应的预测结果。
我们Baseline选择使用机器学习方法,在解决机器学习问题时,一般会遵循以下流程:
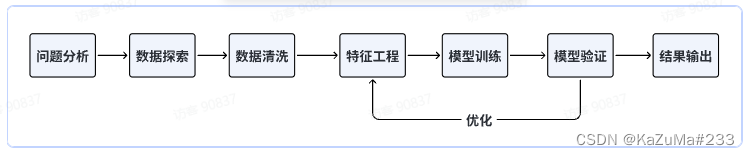
思考:这里为什么选择机器学习算法?为什么不考虑深度学习?
在许多机器学习问题中,特征工程的重要性不容忽视。如果特征工程能够充分捕捉数据的关键特征,那么机器学习算法也能够表现很好。深度学习在某种程度上可以自动学习特征,但对于特定问题,手动设计特征可能会更有效。(人工选择特征训练模型适用于特征较多,并且区分度不是非常高的时候)
思考:这里从逻辑回归和决策树中选择,哪一个模型更加合适?
-
决策树能够处理非线性关系,并且可以自动捕获特征之间的交互作用。(非关系型数据,捕获特征的相关性,可以与人工特征标注相辅相成)
-
它可以生成可解释的规则,有助于理解模型如何做出决策。
-
决策树能够处理不同类型的特征,包括分类和数值型。
---------------------------------------------------------------------------------------------------------------------------------
什么是决策树?(简单介绍)
决策树及其集成是分类和回归机器学习任务的流行方法。决策树被广泛使用,因为它们易于解释,处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征相互作用。随机森林和增强算法等树集成算法在分类和回归任务中表现最佳。
常应用于以下类型的场景:
预测用户贷款是否能够按时还款;
预测邮件是否是垃圾邮件;
预测用户是否会购买某件商品等等
官网:分类和回归
决策树的优缺点
优点:
决策树算法易理解,机理解释起来简单。
决策树算法可以用于小数据集。
决策树算法的时间复杂度较小,为用于训练决策树的数据点的对数。
相比于其他算法智能分析一种类型变量,决策树算法可处理数字和数据的类别。
能够处理多输出的问题。
对缺失值不敏感。
可以处理不相关特征数据。
效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
原文链接:https://blog.csdn.net/weixin_46389691/article/details/128103174
---------------------------------------------------------------------------------------------------------------------------------
任务1:跑通Baseline
快速跑通
快速跑通Baseline,我们基于百度AI Studio,将本教程Baseline部署在线上平台,可一键fork运行代码,提交结果,看到成绩。
一键运行:https://aistudio.baidu.com/aistudio/projectdetail/6618108?contributionType=1&sUid=1020699&shared=1&ts=1691406191660
-
运行时,可以选择
CPU2核8GV100 16G的配置 -
总运行时间大约需要 5min 或 1min,请耐心等待
实践步骤
-
导入库:首先,代码导入了需要用到的库,包括
pandas(用于数据处理和分析)和DecisionTreeClassifier(决策树分类器)等。 -
读取数据:代码通过使用
pd.read_csv函数从文件中读取训练集和测试集数据,并将其存储在train_data和test_data两个数据框中。 -
特征工程:
- udmap_onethot 函数将原始的 udmap 特征进行了预处理,将其转换为一个长度为9的向量,表示每个key是否存在。
- 对 udmap 特征进行编码,生成 udmap_isunknown 特征,表示该特征是否为空。
- 将处理后的 udmap 特征与原始数据拼接起来,形成新的数据框。
- 提取 eid 特征的频次(出现次数)和均值,并添加为新的特征。
- 使用时间戳 common_ts 提取小时部分,生成 common_ts_hour 特征。
-
决策树模型训练和预测:
- 创建了一个 DecisionTreeClassifier 的实例,即决策树分类器。
- 使用 fit 函数对训练集中的特征和目标进行拟合,训练了决策树模型。
- 对测试集使用已训练的模型进行预测,得到预测结果。
- 将预测结果和相应的 uuid 组成一个DataFrame,并将其保存到 submit.csv 文件中。
实践代码:
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 sklearn.tree 模块中导入 DecisionTreeClassifier 类
# DecisionTreeClassifier 用于构建决策树分类模型
from sklearn.tree import DecisionTreeClassifier
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
# 3. 将 'udmap' 列进行 One-Hot 编码
# 数据样例:
# udmap key1 key2 key3 key4 key5 key6 key7 key8 key9
# 0 {'key1': 2} 2 0 0 0 0 0 0 0 0
# 1 {'key2': 1} 0 1 0 0 0 0 0 0 0
# 2 {'key1': 3, 'key2': 2} 3 2 0 0 0 0 0 0 0
# 在 python 中, 形如 {'key1': 3, 'key2': 2} 格式的为字典类型对象, 通过key-value键值对的方式存储
# 而在本数据集中, udmap实际是以字符的形式存储, 所以处理时需要先用eval 函数将'udmap' 解析为字典
# 具体实现代码:
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 4. 编码 udmap 是否为空
# 使用比较运算符将每个样本的 'udmap' 列与字符串 'unknown' 进行比较,返回一个布尔值的 Series
# 使用 astype(int) 将布尔值转换为整数(0 或 1),以便进行后续的数值计算和分析
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# 5. 提取 eid 的频次特征
# 使用 map() 方法将每个样本的 eid 映射到训练数据中 eid 的频次计数
# train_data['eid'].value_counts() 返回每个 eid 出现的频次计数
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 6. 提取 eid 的标签特征
# 使用 groupby() 方法按照 eid 进行分组,然后计算每个 eid 分组的目标值均值
# train_data.groupby('eid')['target'].mean() 返回每个 eid 分组的目标值均值
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 7. 提取时间戳
# 使用 pd.to_datetime() 函数将时间戳列转换为 datetime 类型
# 样例:1678932546000->2023-03-15 15:14:16
# 注: 需要注意时间戳的长度, 如果是13位则unit 为 毫秒, 如果是10位则为 秒, 这是转时间戳时容易踩的坑
# 具体实现代码:
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({
'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
# 10. 保存结果文件到本地
# 将结果DataFrame保存为一个CSV文件,文件名为 'submit.csv'
# 参数 index=None 表示不将DataFrame的索引写入文件中
result_df.to_csv('submit.csv', index=None)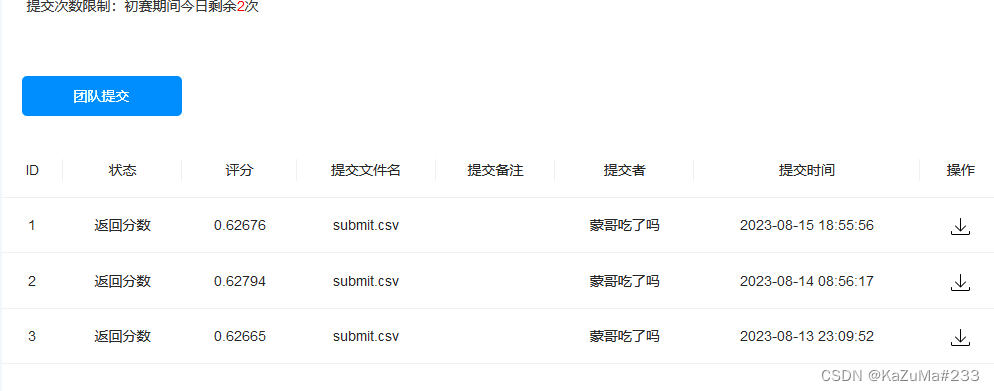
实操并回答下面问题:
-
如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
-
答:0.62676
-
代码中如何对udmp进行了人工的onehot?
-
答:定义函数为(Key,Value)键值对(python数据为字典类型)而在本数据集中, udmap实际是以字符的形式存储, 所以处理时需要先用eval 函数将'udmap' 解析为字典,机器学习输入的数据,不能是字符串类型,需要分割数据类型为(向量,数组等等)
2.学习收获:
因为我有一些机器学习,数据分析,数据可视化的基础,所以觉得整个项目的处理流程,算法选择等等还是很有指向性的,目标还是精准快速的通过ai来处理数据。第一节课还是注重于体验实际项目的处理流程,从一个问题提出,到使用机器学习技术处理问题再到结果的提交,验证正确率精准度等等,整个流程严谨可靠,当然我个人还是感觉需要下来多看看算法。还是想要优化目前的决策树结构。感谢Datawhale贡献者团队与科大讯飞的帮助,能够参与夏令营和各地的同学们一起愉快的学习,提升自己是一件很美好的事~!也希望大家能够度过一段快乐的学习时光!
3.目前的疑问:
代码的内容基本上都理解了,关于下一步的优化还是有很多疑问的,可能还是因为基础不够扎实,做过的项目不多吧哈哈,希望群内大神可以多讲讲优化算法相关的内容!
4.内容拓展:
我的学习材料已经打包上传(包含机器学习的大部分主流算法的案例等等,浅显易懂,简单操作,在环境下可以复制直接运行,代码含义已经标注在pdf内)会同步发到CSDN,供给大家学习!帮助大家更好的了解机器学习。
下载链接:https://download.csdn.net/download/weixin_62439683/88219257
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









