






目录
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开来的,后来在广泛运用于Scala 、PHP、C# 、Java、C++ 、Objective-c、Perl 、Swift、VBScript 、Javascript、Ruby 以及Python等等。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
正则元字符
正则:普通字符
当我们的正则表达式为一串普通字符(不包含元字符)时,校验字符串只有和正则一致时,才会校验通过。

正则:\d
\d 表示一个数字。
如:
a\d: 表示验证的字符串后面必须以 a 开头,且以一个数字结尾。

a\db:a和b中间有一个数字

a\d\d:a后面跟2个数字

注意:在Java定义的正则里,由于一个\表示的是字符串转义,因此在Java定义带有\的元字符时,还需要多写一个\,即\\
如:
package Regex;
import java.util.regex.Pattern;
/**
* @Author ztc
* Date on 2022/12/13 14:36
*/
public class RegexTest {
public static final String regex = "a\\d\\d";
public static void main(String[] args) {
System.out.println("正则表达式:" + regex);
checkRegex("aa1");
checkRegex("aabb1");
checkRegex("a11");
}
private static void checkRegex(String input){
boolean result = Pattern.matches(regex, input);
System.out.println(input + ":" + result);
}
}
正则:\D
\D 表示一个非数字,它和上面 \d 的意思恰好相反。
如:
\D\D\D\D: 则表示一个长度为4,不包含数字的字符串。

正则:\w
Matches any letter, digit or underscore. Equivalent to [a-zA-Z0-9_].
表示一个字母(大小写均可)、数字,或下划线

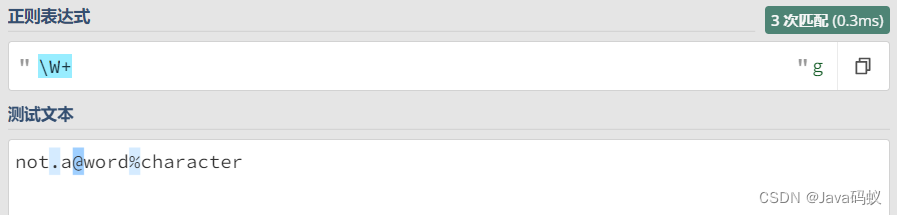
正则:\W
Matches anything other than a letter, digit or underscore. Equivalent to [^a-zA-Z0-9_]
\W 与 \w 相反,表示这个位置的字符既不是字母、数字,也不是下划线。
也就是:特殊符号(除下划线),或者空格等满足。
正则:\s
匹配空格、制表符和换行符等空白字符。

正则:\S
匹配除空格、制表符和换行符以外的字符。

正则:.

正则:|
| (竖线) 则表示或的关系,表示检测的字符串须满足其中一个时,才符合条件。
如:aa|bb|cc:则表示输入的字符串须是aa,或bb,或cc其中的一个

注意,如果我们或者关系的前后还有其它字符时,需要用()将他们包裹起来。
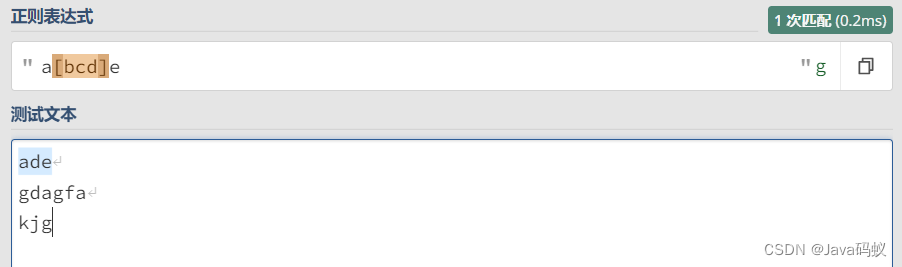
正则:[ ]
[ ] 表示匹配其中任意一个字符。
如:
a[bcd]e:则表示a和e的中间须是b,或c,或d其中的一个
正则:[^abc]
[^ ] 表示不与中括号里的任意字符匹配。
如:
a[^bcd]e:则表示a和e的中间除b,c,d这三个字符外,其他的字符都满足。

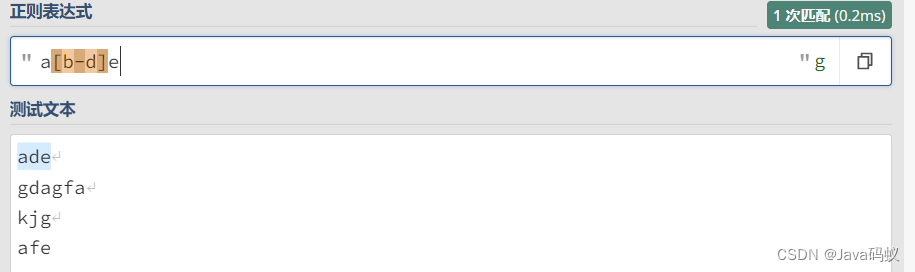
正则:[a-z]
[值1-值2] 则表示值1到值2中间的所有字符都满足(包括值1和值2)。常用该正则来表示大小写字母范围,数字范围。
如:
a[b-d]e:等同于 a[bcd]e,因为 b-d 其实就是b,c,d三个数
a[0-9]e:则表示a和e中间是一个数字

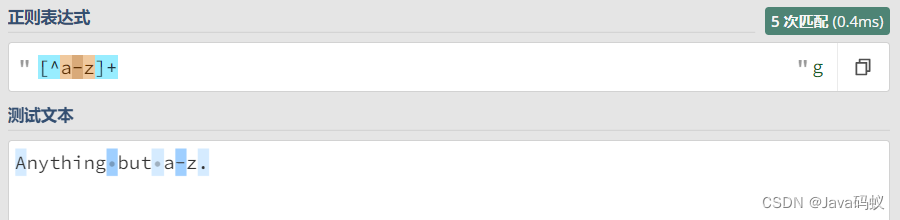
正则:[^a-z]
匹配不在a到z范围内的任意字符。
正则:\num
这里的num指number,也就是数字,当\后面跟数字,表示匹配第几个括号中的结果。
比如:现在有 abcd 字符串,当我们用小括号把 c 包裹起来后,然后在字符串后面写上 \1,即 ab(c)d\1,则这里的 \1 就指 c,因为 \1 表示第1个小括号中的结果。
ab(c)d\1:等同于 abcdc 。

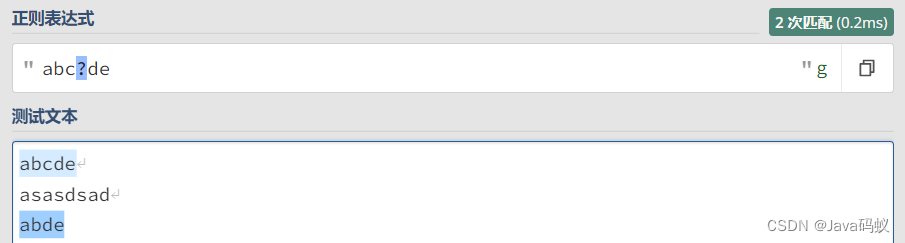
正则:?
? 表示匹配前面的子表达式零次或一次。
如:
abc?de: 表示可匹配的字符串为 abde (匹配0次c) 或 abcde (匹配1次c)。
正则:+
匹配前面的子表达式一次或多次 (次数 >= 1,即至少1次)
abc+de:ab 和 de 之前至少有一个 c 。

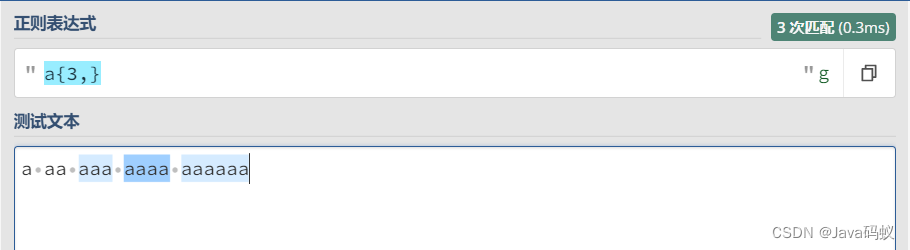
正则:{n}
这里的 n 是一个非负整数。匹配确定的前面的子表达式 n 次。
如:
a{3}
匹配三个连续的"a"字符

a{3,}
匹配三个以上连续的"a"字符。
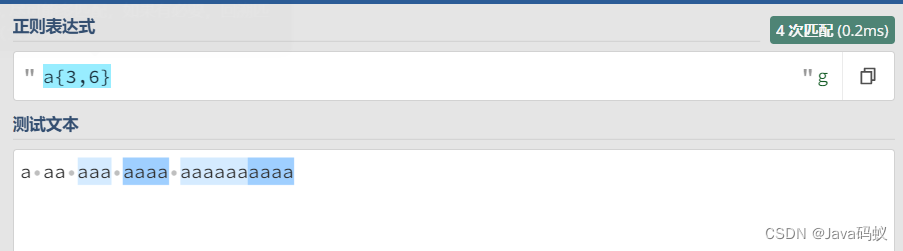
a{3,6}
匹配三到六个连续的"a"字符。
正则:*
a*
匹配零个以上连续的"a"字符。

正则:$
匹配文本末尾的位置(不占用字符)。多行模式下亦匹配换行符前的位置,即行尾。

正则:^
匹配字符串的开头而不使用任何字符。如果使用/m多行模式,这也将在换行符之后立即匹配。

















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











