







一、集合
1、集合的理解和好处
-
数组
(1)长度开始时必须指定,而且一旦指定,不能更改
(2)保存的必须为同一类型的元素
(3)使用数组进行增加/删除元素的示意代码-比较麻烦 -
集合
(1)可以动态保存任意多个对象,使用比较方便
(2)提供了一系列方便的操作对象的方法:add、remove、set、get等
(3)使用集合添加,删除新元素的示意代码- 简洁
2、集合的框架体系
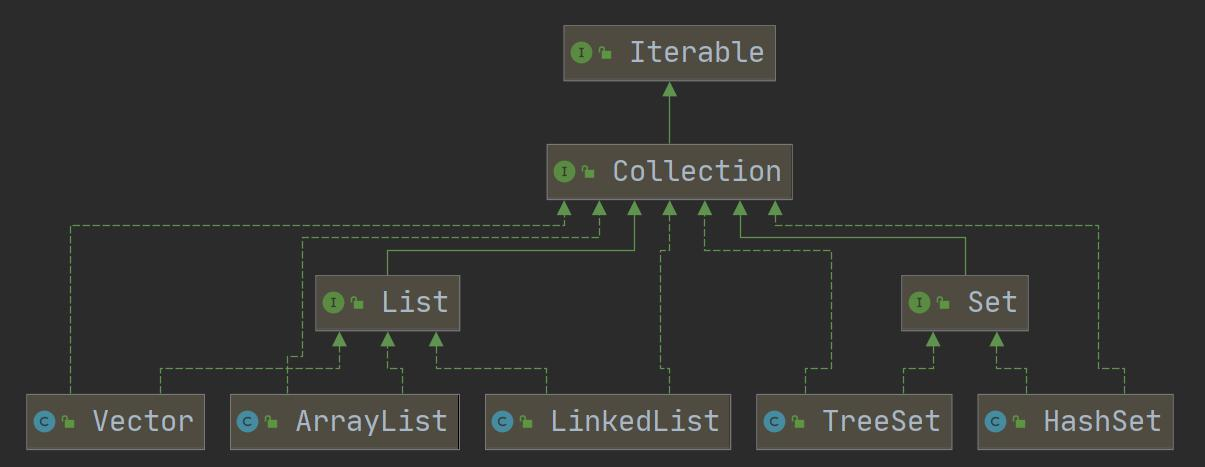
Java 的集合类很多,主要分为两大类
(1)Collection:单列集合
(2)Map:双列集合
3、Collection 接口和常用方法
-
Collection 接口实现类的特点
public interface Collection< E > extends lterable< E >
(1)collection实现子类可以存放多个元素,每个元素可以是Obiect
(2)有些Collection的实现类, 可以存放重复的元素,有些不可以
(3)有些Collection的实现类,有些是有序的(List),有些不是有序(Set)
(4)Collection接口没有直接的实现子类,是通过它的子接口Set 和 List 来实现的 -
Collection 接口遍历元素方式 1-使用 Iterator(迭代器)
(1)lterator对象称为迭代器,主要用于遍历 Collection 集合中的元素
(2)所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了lterator接口的对象,即可以返回一个选代器
(3)lterator 的结构
(4)Iterator 仅用于遍历集合,lterator 本身并不存放对象。
(5)Iterator接口的方法:
hasNext():判断集合内是否还有下一个元素,有则返回true
next():让迭代器下移一个位置,然后返回该位置上的元素
(6)迭代器的使用:
hasNext()方法和next()方法要配合使用。在调用iterator.next()方法之前必须要调用iterator.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next0)会抛出NoSuchElementException异常。Collection col = new ArrayList(); col.add(new Book("三国演义", "罗贯中", 10.1)); col.add(new Book("小李飞刀", "古龙", 5.1)); col.add(new Book("红楼梦", "曹雪芹", 34.6)); System.out.println("col=" + col); //现在希望能够遍历 col 集合 //1. 先得到 col 对应的 迭代器 Iterator iterator = col.iterator(); //2. 使用 while 循环遍历 //快捷键,快速生成 while => itit //显示所有的快捷键的快捷键 ctrl + j while (iterator.hasNext()) { Object obj = iterator.next(); System.out.println("obj=" + obj); } //3. 当退出 while 循环后 , 这时 iterator 迭代器,指向最后的元素 //4. 如果希望再次遍历,需要重置我们的迭代器 iterator = col.iterator(); System.out.println("===第二次遍历==="); while (iterator.hasNext()) { Object obj = iterator.next(); System.out.println("obj=" + obj); } -
Collection 接口遍历对象方式 2-for 循环增强
(1)增强for循环,可以代替iterator迭代器
(2)增强for就是简化版的iterator,本质一样
(3)增强for循环只能用于遍历集合或数组
(4)基本语法:for(元素类型 元素名:集合名或数组名){访问元素}for (Object book : col) { System.out.println("book=" + book); }
4、List 接口和常用方法
-
List 接口基本介绍
(1)List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复
(2)List集合中的每个元素都有其对应的顺序索引,即支持索引
(3)JDK API中List接口的实现类有:

常用的有:ArrayList、LinkedList、Vector. -
List 接口的常用方法
List list = new ArrayList(); list.add("张三丰"); list.add("贾宝玉"); // 1. void add(int index, Object ele):在 index 位置插入 ele 元素 //在 index = 1 的位置插入一个对象 list.add(1, "韩顺平"); System.out.println("list=" + list); // 2. boolean addAll(int index, Collection eles):从 index 位置开始将 eles 中的所有元素添加进来 List list2 = new ArrayList(); list2.add("jack"); list2.add("tom"); list.addAll(1, list2); System.out.println("list=" + list); // 3. Object get(int index):获取指定 index 位置的元素 // 4. int indexOf(Object obj):返回 obj 在集合中首次出现的位置 System.out.println(list.indexOf("tom"));//2 // 5. int lastIndexOf(Object obj):返回 obj 在当前集合中末次出现的位置 list.add("韩顺平"); System.out.println("list=" + list); System.out.println(list.lastIndexOf("韩顺平")); // 6. Object remove(int index):移除指定 index 位置的元素,并返回此元素 list.remove(0); System.out.println("list=" + list); // 7. Object set(int index, Object ele):设置指定 index 位置的元素为 ele , 相当于是替换 list.set(1, "玛丽"); System.out.println("list=" + list); // 8. List subList(int fromIndex, int toIndex):返回从 fromIndex 到 toIndex 位置的子集合 // 注意返回的子集合 fromIndex <= subList < toIndex List returnlist = list.subList(0, 2);//0,1 System.out.println("returnlist=" + returnlist); -
List 的三种遍历方式 [ArrayList, LinkedList,Vector]
(1)方式一:使用iterator
(2)方式二:使用增强for
(3)方式三:使用普通forfor (int i=0;i<list.size();i+ +){ Object object = list.get(i); System.out.println(object); }
5、ArrayList 底层结构和源码分析
-
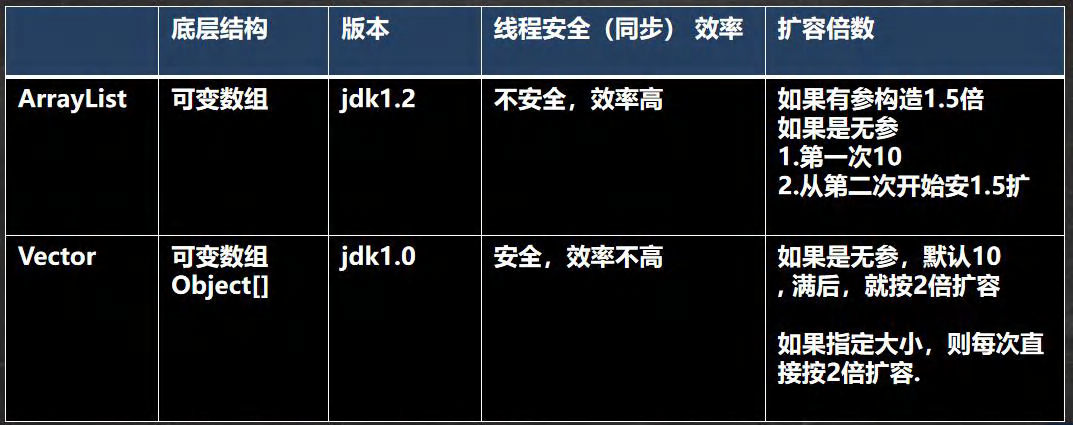
ArrayList 的注意事项
(1)permits all elements, including null ,ArrayList 允许加入多个null
(2)ArrayList 是由数组来实现数据存储的
(3)ArrayList 基本等同于Vector,除了 ArrayList是线程不安全(执行效率高),在多线程情况下,不建议使用ArrayList -
ArrayList 的底层操作机制源码分析
(1)ArrayList中维护了一个Object类型的数组elementData
transient Object[l elementData; //transient 表示瞬间,短暂的, 表示该属性不会被序列号
(2)当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
(3)如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容则直接扩容elementData为1.5倍
6、Vector 底层结构和源码剖析
-
Vector 的基本介绍
(1)Vector类的定义说明
public class Vector< E> extends AbstractList< E> implements List< E>, RandomAccess, Cloneable, Serializable
(2)Vector底层也是一个对象数组,protected Object [] lelementData;
(3)Vector 是线程同步的,即线程安全,Vector类的操作方法带有synchronized
public synchronized E get(int index){
if (index>= elementcount)
throw new ArraylndexOutOfBoundsException(index);
return elementData(index);
}
(4)在开发中,需要线程同步安全时,考虑使用Vector -
Vector 和 ArrayList 的比较
7、LinkedList 底层结构
-
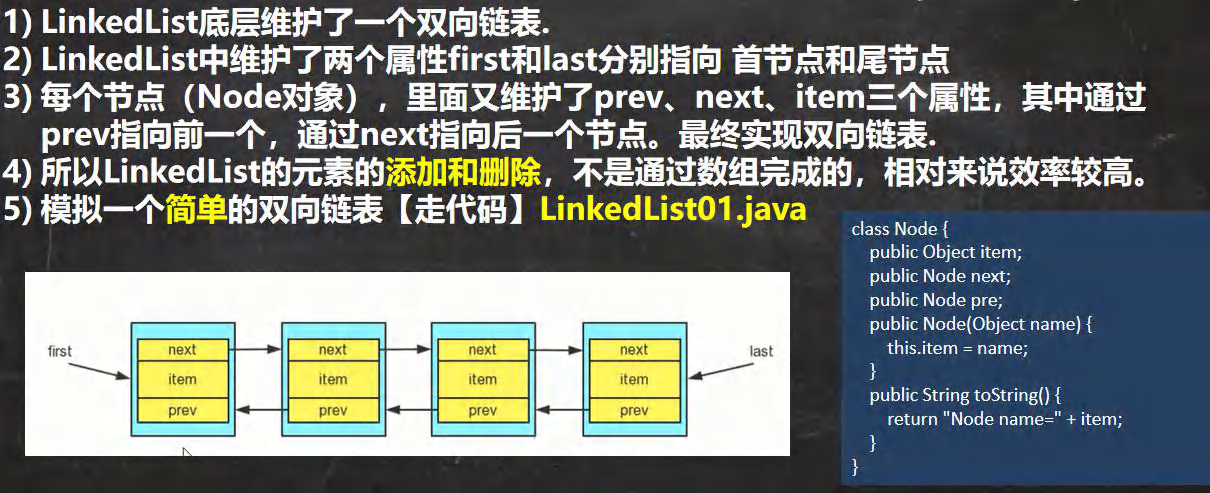
LinkedList 的全面说明
(1)LinkedList底层实现了双向链表和双端队列特点
(2)可以添加任意元素(元素可以重复),包括null
(2)线程不安全,没有实现同步 -
LinkedList 的底层操作机制
-
LinkedList 的增删改查
LinkedList linkedList = new LinkedList(); linkedList.add(1); linkedList.add(2); linkedList.add(3); linkedList.remove(); // 这里默认删除的是第一个结点 linkedList.remove(2); linkedList.set(1, 999); Object o = linkedList.get(1); -
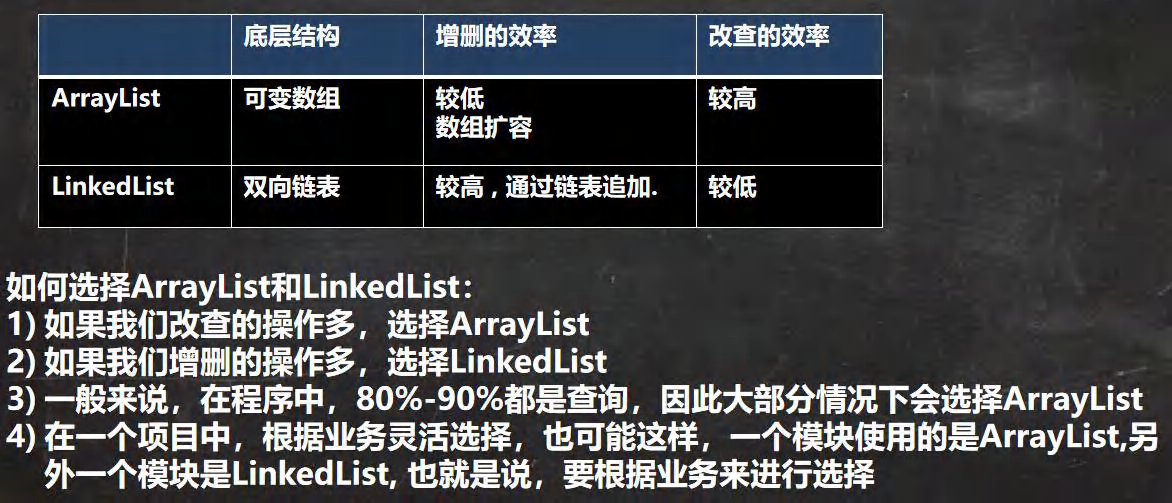
ArrayList 和 LinkedList 比较
8、Set 接口和常用方法
-
Set 接口基本介绍
(1)无序(添加和取出的顺序不一致),没有索引
(2)不允许重复元素,所以最多包含一个null
(3)JDK API中Set接口的实现类有:

-
Set 接口的常用方法
和 List 接口一样, Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样. -
Set 接口的遍历方式
同Collection的遍历方式一样,因为Set接口是Colection接口的子接口
(1)可以使用迭代器
(2)增强for
(3)不能使用索引的方式来获取,即不能使用普通for循环遍历
9、Set 接口实现类-HashSet
-
HashSet 的全面说明
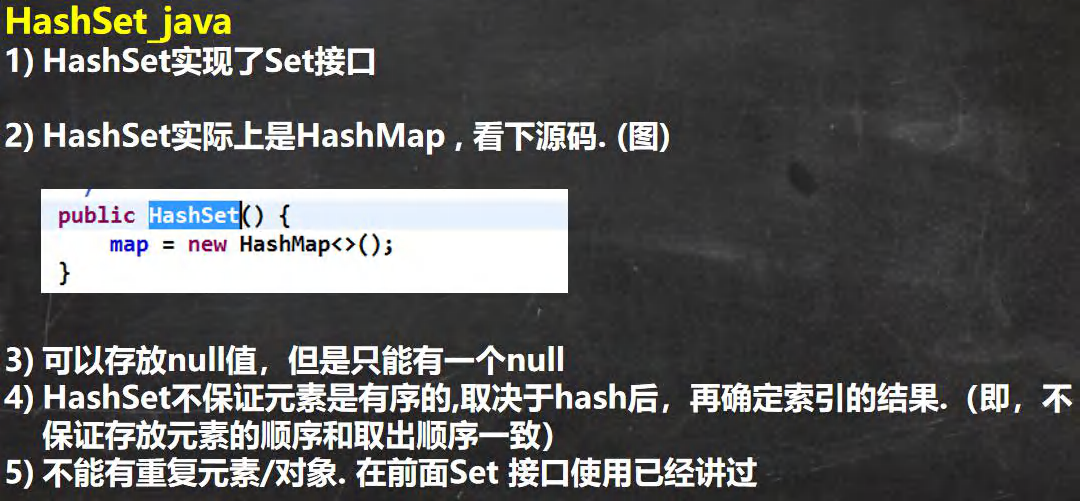
-
HashSet 底层机制说明
(1)HashSet 底层是 HashMap
(2)添加一个元素时,先得到hash值会转成->索引值
(3)找到存储数据表table,看这个索引位置是否已经存放的有元素
(4)如果没有,直接加入
(5)如果有, 调用 equals 比较,如果相同,就放弃添加,如果不相同,则添加到最后
(6)在Java8中,如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树) -
Hashset的扩容和转成红黑树机制
(1)HashSet底层是HashMap,第一次添加时,table 数组扩容到 16,临界值(threshold)是 16加载因子(loadFactor)是0.75=12
(2)如果table 数组使用到了临界值 12,就会扩容到 162=32,新的临界值就是32*0.75 =24,依次类推
(3)在Java8中,如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是 8)并且table的大小 >=MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
10、Set 接口实现类-LinkedHashSet
- LinkedHashSet 的全面说明
(1)LinkedHashSet是HashSet 的子类
(2)LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个数组+双向链表
(3)LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的。
(4)LinkedHashSet 不允许添重复元素 - 底层机制

11、Map 接口和常用方法
-
Map 接口实现类的特点 [很实用]
注意:这里讲的是JDK8的Map接口特点 Map .java
(1)Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
(2)Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node对象中
(3)Map 中的 key 不允许重复,原因和HashSet 一样
(4) Map 中的 value 可以重复
(5)Map 的key 和 value 可以为nul ,但key 为nul只能有一个,value 为null 可以多个
(6)常用String类作为Map的 key
(7) key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
(8)Map接口的常用实现类:HashMap、Hashtable和Properties. -
Map 接口常用方法
Map map = new HashMap(); map.put("邓超", new Book("", 100));//ok——增 map.put("邓超", "孙俪");//替换——改 map.put("王宝强", "马蓉");//OK map.put("宋喆", "马蓉");//OK map.put("刘令博", null);//OK map.put(null, "刘亦菲");//OK map.put("鹿晗", "关晓彤");//OK map.put("hsp", "hsp 的老婆"); System.out.println("map=" + map); // 1. remove:根据键删除映射关系——删 map.remove(null); System.out.println("map=" + map); // 2. get:根据键获取值——查 Object val = map.get("鹿晗"); System.out.println("val=" + val); // 3. size:获取元素个数 System.out.println("k-v=" + map.size()); // 4. isEmpty:判断个数是否为 0 System.out.println(map.isEmpty());//F // 5. clear:清除 k-v map.clear(); System.out.println("map=" + map); // 6. containsKey:查找键是否存在 System.out.println("结果=" + map.containsKey("hsp"));//T -
Map 接口遍历方法
//第一组: 先取出 所有的 Key , 通过 Key 取出对应的 Value Set keyset = map.keySet(); //(1) 增强 for System.out.println("-----第一种方式-------"); for (Object key : keyset) { System.out.println(key + "-" + map.get(key)); } //(2) 迭代器 System.out.println("----第二种方式--------"); Iterator iterator = keyset.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(key + "-" + map.get(key)); } //第二组: 把所有的 values 取出 Collection values = map.values(); //这里可以使用所有的 Collections 使用的遍历方法 //(1) 增强 for System.out.println("---取出所有的 value 增强 for----"); for (Object value : values) { System.out.println(value); } //(2) 迭代器 System.out.println("---取出所有的 value 迭代器----"); Iterator iterator2 = values.iterator(); while (iterator2.hasNext()) { Object value = iterator2.next(); System.out.println(value); } //第三组: 通过 EntrySet 来获取 k-v Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>> //(1) 增强 for System.out.println("----使用 EntrySet 的 for 增强(第 3 种)----"); for (Object entry : entrySet) { //将 entry 转成 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); } //(2) 迭代器 System.out.println("----使用 EntrySet 的 迭代器(第 4 种)----"); Iterator iterator3 = entrySet.iterator(); while (iterator3.hasNext()) { Object entry = iterator3.next(); //System.out.println(next.getClass()); //HashMap$Node -实现-> Map.Entry (getKey,getValue) //向下转型 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); }
12、Map 接口实现类-HashMap
-
HashMap介绍
(1)HashMap是 Map 接口使用频率最高的实现类
(2)HashMap 是以 key-val 对的方式来存储数据(HashMap$Node类型)
(3)key 不能重复,但是值可以重复,允许使用null键和nul值
(4)如果添加相同的key,则会覆盖原来的key-val,等同于修改.(key不会替换,val会替换)
(5)与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的。(jdk8的hashMap 底层 数组+链表+红黑树)
(6)HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有synchronized -
HashMap 底层机制及源码剖析
(1)HashMap底层维护了Node类型的数组table,默认为null
(2)当创建对象时,将加载因子(loadfactor)初始化为0.75.
(3)当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,如果相等,则直接替换val;如果不相等需要判断是树结构还是链表结构,做出相应处理。
(4)如果添加时发现容量不够,则需要扩容。第1次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75)
(5)以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推
(6)在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且table的大小>= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
13、Map 接口实现类-Hashtable
-
HashTable 的基本介绍
(1)存放的元素是键值对: 即 K-V
(2)hashtable的键和值都不能为null,否则会抛出NulPointerException
(3)hashTable 使用方法基本上和HashMap一样
(4)hashTable 是线程安全的(synchronized),hashMap 是线程不安全的 -
Hashtable 和 HashMap 对比

14、Map 接口实现类-Properties
- 基本介绍
(1)Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据。
(2)Properties类继承 Hashtable,使用特点和Hashtable类似
(3)Properties 还可以用于 从 xxx.properties 文件中,加载数据到Properties类对象,并进行读取和修改
(4)xxx.properties 文件通常作为配置文件
15、总结-开发中如何选择集合实现类

16、Collections 工具类
-
Collections 工具类介绍
(1)Collections 是一个操作 Set、List 和 Map 等集合的工具类
(2)Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作 -
排序操作:(均为 static 方法)
(1)reverse(List):反转 List 中元素的顺序
(2)shuffle(List):对 List 集合元素进行随机排序
(3)sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
(4)sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
(5)swap(List,int, int):将指定 list 集合中的i处元素和j处元素进行交换Collections.sort(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o2).length() - ((String) o1).length(); } }); -
查找、替换
(1)Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
(2)Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
(3)Object min(Collection)
(4)Object min(Collection, Comparator)A)
(5)int frequency(Collection,Object):返回指定集合中指定元素的出现次数
(6)void copy(List dest,List src):将src中的内容复制到dest中
(7)boolean replaceAll(List list, Object oldVal, Object newVal):使用新值替换 List 对象的所有旧值
二、泛型
1、泛型的理解和好处
- 泛型的好处

2、泛型介绍
(1)泛型又称参数化类型,是Jdk5.0 出现的新特性,解决数据类型的安全性问题
(2)在类声明或实例化时只要指定好需要的具体的类型即可
(3)Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生ClassCastException异常。同时,代码更加简洁、健壮
(4)泛型的作用是:可以在类声明时通过一个标识表示类中某个属性的类型或者是某个方法的返回值的类型,或者是参数类型
//注意,特别强调: E 具体的数据类型在定义 Person 对象的时候指定,即在编译期间,就确定 E 是什么类型
Person<String> person = new Person<String>("韩顺平教育");
person.show(); //String
class Person<E> {
E s ;//E 表示 s 的数据类型
//该数据类型在定义 Person 对象的时候指定,即在编译期间,就确定 E 是什么类型
public Person(E s) {//E 也可以是参数类型
this.s = s;
}
public E f() {//返回类型使用 E
return s;
}
public void show() {
System.out.println(s.getClass());//显示 s 的运行类型
}
}
理解泛型:
类比变量,变量用来表示不同数值,比如int变量被赋值1,则表示1,被赋值2则表示2
泛型,被设置为String类型,则表示String类型,被设置为Integer类型,则表示Integer类型
3、泛型的语法
-
泛型的声明
interface 接囗{}
class 类<K,V>{}
说明:
(1)其中,T,K,V不代表值,而是表示类型
(2)任意字母都可以。常用T表示,是Type的缩写 -
泛型的实例化
在类名后面指定类型参数的值(类型)。如:
(1)List strList = new ArrayList();
(2)lteratoriterator = customers.iterator(); -
泛型使用的注意事项和细节
(1)泛型的具体类型只能是引用类型
(2)在给泛型指定具体类型后,可以传入该类型或者其子类类型
(3)泛型的使用形式:
List list1 = new ArrayList();
List list2 = new ArrayList<>(); //推荐简写
List list3 = new ArrayList(); //默认给它的 泛型是< E>,E就是 Object
4、自定义泛型
- 自定义泛型类
- 基本语法
class 类名<T, R…>{//…表示有多个泛型
成员
} - 注意细节
(1)普通成员可以使用泛型(属性、方法)
(2)使用泛型的数组,不能初始化
(3)静态方法中不能使用类的泛型
(4)泛型类的类型,是在创建对象时确定的
(5)如果在创建对象时,没有指定类型,默认为Object
- 自定义泛型接口
-
基本语法
interface 接囗名<T, R…>{
} -
注意细节
(1)接口中,静态成员也不能使用泛型
(2)泛型接口的类型,在继承接口或者实现接口时确定
(3)没有指定类型,默认为Object
- 自定义泛型方法
-
基本语法
修饰符 <T,R…> 返回类型 方法名(参数列表){
} -
注意细节
(1)泛型方法,可以定义在普通类中,也可以定义在泛型类
(2)当泛型方法被调用时,类型会确定
(3)public void eat(E e){},修饰符后没有<T.R…>,eat方法不是泛型方法,而是使用了泛型
5、泛型的继承和通配符
(1)泛型不具备继承性Listlist = new ArrayList(); // 对吗?
(2)<?>:支持任意泛型类型
(3)<?extends A>:支持A类以及A类的子类,规定了泛型的上限
(4)<?super A>:支持A类以及A类的父类,不限于直接父类,规定了泛型的下限
6、扩展:JUnit
-
为什么需要 JUnit
(1)一个类有很多功能代码需要测试,为了测试,就需要写入到main方法中
(2)如果有多个功能代码测试,就需要来回注销,切换很麻烦
(3)如果可以直接运行一个方法,就方便很多,并且可以给出相关信息,就好了——JUnit -
基本介绍
(1)JUnit是一个Java语言的单元测试框架
(2)多数Java的开发环境都已经集成了JUnit作为单元测试的工具@Test public void m1() { System.out.println("m1 方法被调用"); }















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









