







🔥 信仰:一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去
🎶 博客主页:程序喵正在路上 的博客主页
🦋 欢迎关注🖱点赞👍收藏🌟留言🐾
🦄 本文由 程序喵正在路上 原创,CSDN首发!
💖 系列专栏:Python学习
🌠 首发时间:2022年5月9日
✅ 如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦
jieba库概述
jieba 库演示
对于一段英文文本, 例如 “China is a great country”,如果希望提取其中的单词,只需要使用字符串处理的 split() 方法即可,例如:
print("China is a great country".split())
程序执行结果如下:
[‘China’, ‘is’, ‘a’, ‘great’, ‘country’]
然而,对于一段中文文本,例如,“中国是一个伟大的国家”,获得其中的单词 (不是字符) 十分困难,因为英文文本可以通过空格或者标点符号分隔,而中文单词之间缺少分隔符,这是中文及类似语言独有的“分词”问题。上例中, 分词能够将 “中国是一个伟大的国家” 分为"中国”、“是”、 “一个”、“伟大”、“的”、 "国家"等一系列词语。
jieba (“结巴”) 是 Python 中一个重要的第三方中文分词函数库,例如:
import jieba
print(jieba.lcut("中国是一个伟大的国家"))
程序执行结果如下:
[‘中国’, ‘是’, ‘一个’, ‘伟大’, ‘的’, ‘国家’]
jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组。除了分词,jieba 还提供增加自定义中文单词的功能。
jieba 库支持 3 种分词模式:精确模式,将句子最精确地切开,适合文本分析;全模式,把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
在 PyCharm 中添加 jieba 库
jieba 库是第三方库,不是 Python 安装包自带的,因此,需要进行安装,因为我们利用的是 PyCharm 进行开发,所以只要简单地把 jieba 库添加进来就行,下面是具体步骤。
(1) 在菜单栏中点击【File】——【Settings】
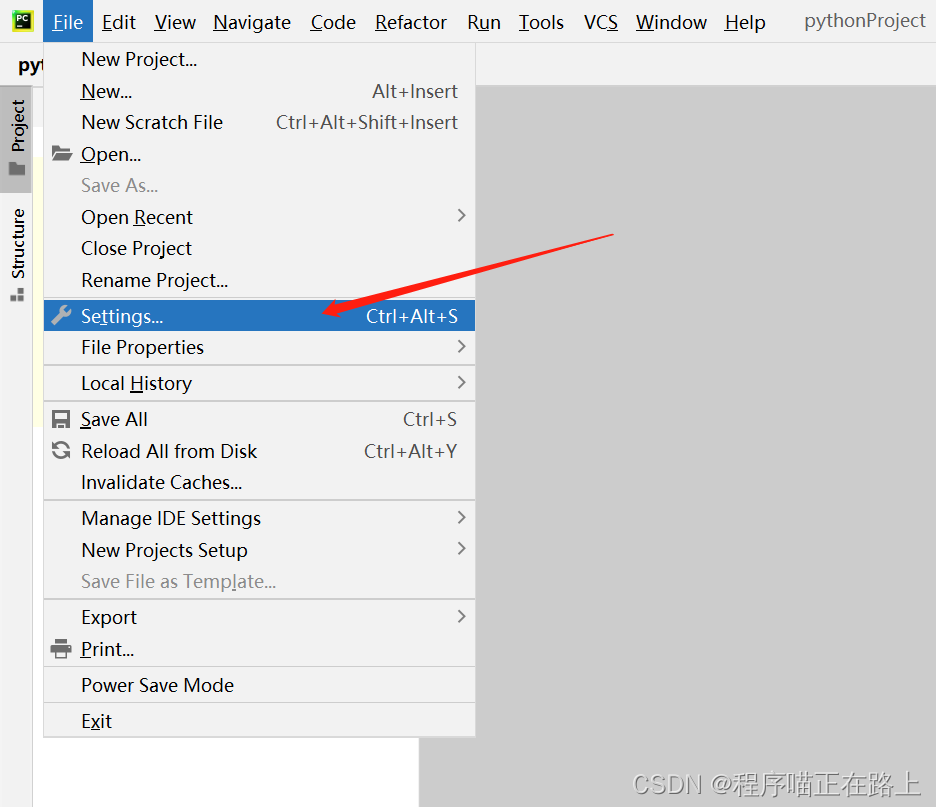
(2) 在接下来的界面中找到【Project: pythonProject】——【Project Interpreter】,点击界面中的加号
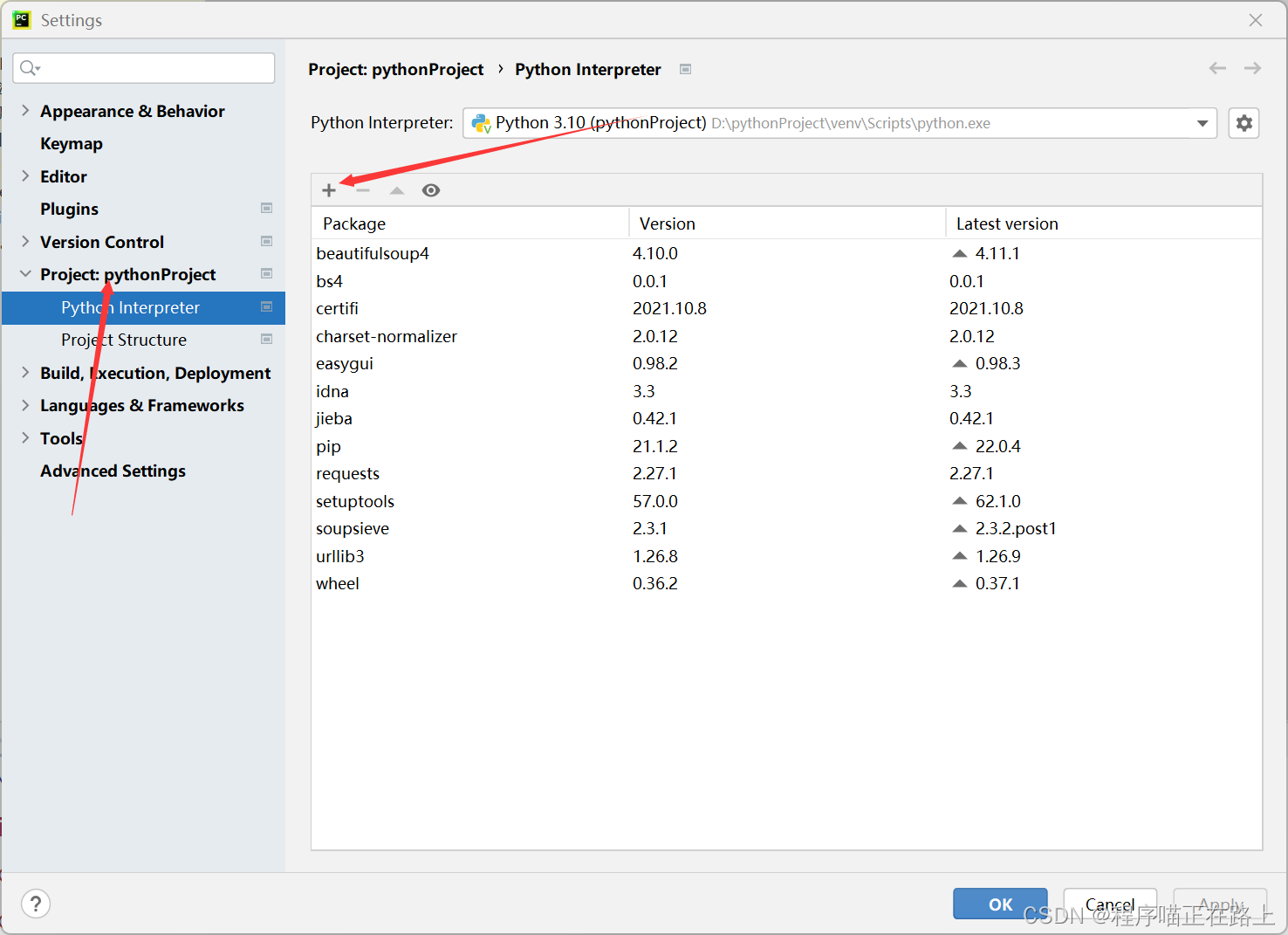
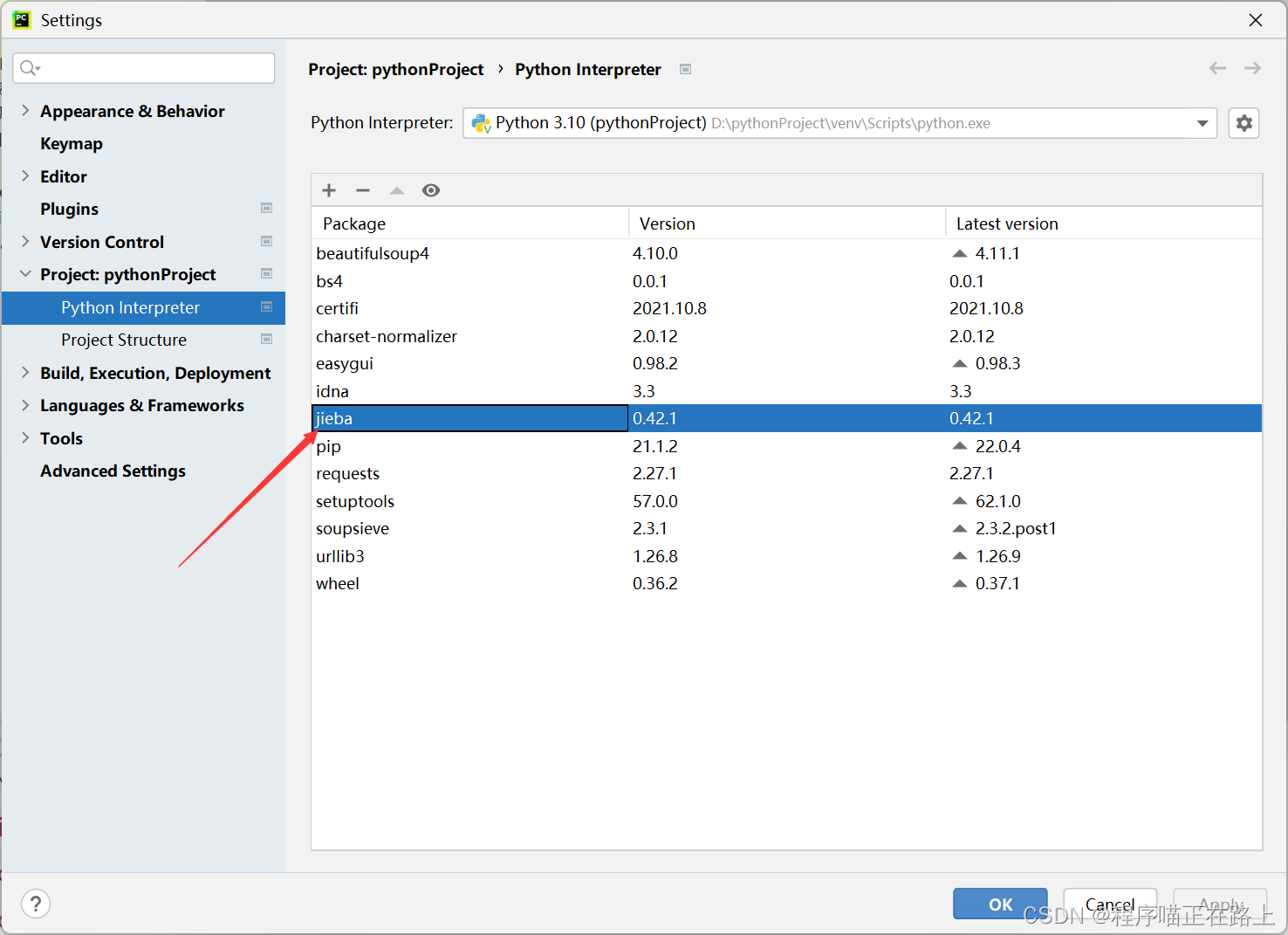
(3) 输入 “jieba"搜索,找到 jieba,然后点击 ”Install Package“,等待一会儿即可

(4) 安装完可以返回之前的界面查看
使用jieba 库
jieba 库支持 3 种分词模式:精确模式,将句子最精确地切开,适合文本分析;全模式,把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba 库主要提供分词功能,可以辅助自定义分词词典。jieba 库中包含的主要函数如下表所示:
| 函数 | 描述 |
|---|---|
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s, cut_all=True) | 全模式,输出文本 s 中所有可能的单词 |
| jieba.cut_for_ search(s) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| jieba.lcut(s) | 精确模式,返回一个列表类型,建议使用 |
| jieba.lcut(s, cut_all=True) | 全模式,返回一个列表类型,建议使用 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,建议使用 |
| jieba.add_word(w) | 向分词词典中增加新词 w |
针对上述分词函数,举例如下:
import jieba
print(jieba.lcut("中华人民共和国是一个伟大的国家"))
print(jieba.lcut("中华人民共和国是一个伟大的国家", cut_all=True))
print(jieba.lcut_for_search("中华人民共和国是一个伟大的国家"))
程序执行结果如下:
[‘中华人民共和国’, ‘是’, ‘一个’, ‘伟大’, ‘的’, ‘国家’]
[‘中华’, ‘中华人民’, ‘中华人民共和国’, ‘华人’, ‘人民’, ‘人民共和国’, ‘共和’, ‘共和国’, ‘国是’, ‘一个’, ‘伟大’, ‘的’, ‘国家’]
[‘中华’, ‘华人’, ‘人民’, ‘共和’, ‘共和国’, ‘中华人民共和国’, ‘是’, ‘一个’, ‘伟大’, ‘的’, ‘国家’]
jieba. lcut() 函数返回精确模式,输出的分词能够完整且不多余地组成原始文本;jieba. lcut(,True) 函数返回全模式,输出原始文本中可能产生的所有问题,冗余性最大;jieba.lcut_ for_search() 函数返回搜索引擎模式,该模式首先执行精确模式,然后再对其中的长词进一步切分获得结果。
由于列表类型通用且灵活,建议读者使用上述 3 个能够返回列表类型的分词函数。
默认情况下,jieba.cut() 等 6 个分词函数能够较高概率识别自定义的新词,比如名字或缩写。对于无法识别的分词,也可以通过 jieba.add_ word() 函 数向分词库添加,例如:
import jieba
print(jieba.lcut("程序喵正在路上"))
jieba.add_word("程序喵")
print(jieba.lcut("程序喵正在路上"))
程序执行结果如下:
[‘程序’, ‘喵’, ‘正在’, ‘路上’]
[‘程序喵’, ‘正在’, ‘路上’]
第三方库
Python 语言的第三方库指不在 Python 安装包中的函数库,也是非标准函数、库。这类函数库一般由全球各领域专业人士结合专业特点和兴趣开发。Python 语言构建了一个开放和自由的生态环境,对第三方库的开发没有强制要求,因此,Python 语言的第三方库发展十分迅速。截至 2016 年 9 月,Python 官方网站注册的第三方库已经达到 9 万多个。如果说强大的标准库奠定了 Python 语言发展的基石,丰富的第三方库则是 Python 不断发展的保证。随着 Python 语言的发展,一些稳定的第三方库不断被加入标准库。
🧸这次的分享就到这里啦,继续加油哦^^
🍭有出错的地方欢迎在评论区指出来,共同进步,谢谢啦
















 6163
6163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











