






upd:完整代码 ZZiAnnn/complierLab2 (github.com)
git上代码增加了语法树生成,有部分代码进行过修改,不是很想改实验报告和帖子了,总的还是差不多的
一、实验目的
掌握计算机语言的语法分析程序设计与属性文法应用的实现方法。
二、实验内容
编制一个能够进行语法分析并生成三地址代码的微型编译程序。
三、实验要求
最低要求:
1、考虑下述语法制导定义中文法,采用递归子程序法,改写文法,构造语法分析程序,要求输出语法树,或者按照最左派生的顺序输出派生的产生式序列;
2、处理的源程序存放在文件中,它可以包含多个语句;
3、考虑下述语法制导定义中语义规则,改写语法分析程序,构造三地址代码生成程序
| 产生式 | 语义规则 |
|---|---|
| S → id = E; | S.code = E.code || gen(id.place ':=' E.place) |
| S → if C then S1; | C.true = newlabel; C.false = S.next; S1.next = S.next; S.code = C.code || gen(C.true ':' ) || S1.code |
| S → if C then S1 else S2; | C.true = newlabel; C.false = newlabel; S1.next = S2.next = S.next; S.code = C.code || gen(C.true ':') || S1.code || gen('goto' S.next) || gen(C.false ':' ) || S2.code; |
| S → while C do S1; | S.begin = newlabel; C.true = newlabel; C.false = S.next; S1.next = S.begin; S.code = gen(S.begin ':') || C.code || gen(C.true ':') || S1.code || gen('goto' S.next) || gen(C.false ':') || S2.code |
| C → E1 > E2 | C.code = E1.code || E2.code || gen('if' E1.place '>' E2.place 'goto' C.true) || gen('goto' C.false) |
| C → E1 < E2 | C.code = E1.code || E2.code || gen('if' E1.place '<' E2.place 'goto' C.true) || gen('goto' C.false) |
| C → E1 = E2 | C.code = E1.code || E2.code || gen('if' E1.place '=' E2.place 'goto' C.true) || gen('goto' C.false) |
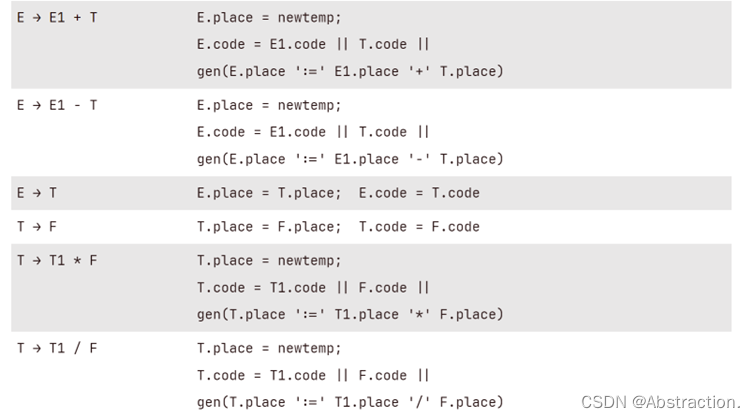
| E → E1 + T | E.place = newtemp; E.code = E1.code || T.code || gen(E.place ':=' E1.place '+' T.place) |
| E → E1 - T | E.place = newtemp; E.code = E1.code || T.code || gen(E.place ':=' E1.place '-' T.place) |
| E → T | E.place = T.place; E.code = T.code |
| T → F | T.place = F.place; T.code = F.code |
| T → T1 * F | T.place = newtemp; T.code = T1.code || F.code || gen(T.place ':=' T1.place '*' F.place) |
| T → T1 / F | T.place = newtemp; T.code = T1.code || F.code || gen(T.place ':=' T1.place '/' F.place) |
| F → ( E ) | F.place = E.place; F.code = E.code |
| F → id | F.place = id.name; F.code = ' ' |
| F → int8 | F.place = int8.value; F.code = ' ' |
| F → int10 | F.place = int10.value; F.code = ' ' |
| F → int16 | F.place = int16.value; F.code = ' ' |
四、实验环境
1、Windows操作系统
2、GCC(C99)编译器
五、实验步骤
1、考虑给定的文法,消除左递归,提取左因子
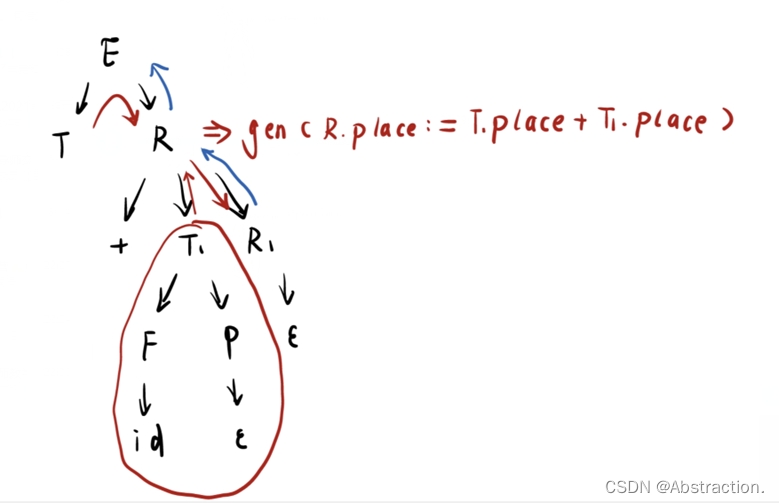
为了在后面使用LL(1)推导,因此先要消除所给文法中的左递归,对于加减乘除存在左递归的情况,采用引入新的非终结符消除左递归,根据语法树的关系可以知道对应的语义动作要引入继承属性

以加法为例说明对应语义的改变方法,对于产生式E→TR,一开始先对T进行推导,T可能是一个乘除表达式,也可能是一个变量或者常数,但是无论如何最后的结果都会保存在T.place中,完成后将T的属性作为继承属性传递给R来完成R的推导
在进行R→+T1R1的时候同理应该先对T1进行推导,一样也会将结果保存在T1.place中,但这个时候先不继续解析R1,而是先生成该节点对应的三地址码,因为如果继续解析后面的R1那么右子树R1的三地址码先生成,这个时候就不符合同级别运算符的从左往右的运算顺序了(左结合性)
只要递归完左子树T1后就可以足够产生R节点对应的三地址语句,T1的运算结果保存在T1.place中,而上面传递下来T.place是前面语句的运算结果,为该节点生成一个临时变量temp保存在R.place,那么R这个节点对应的三地址码就是R.place = T.place + T1.place,将R作为继承属性往下传递,之后继续递归R1就会不断在后面生成新的三地址码,一旦推导到R→ε即到达递归的出口,将上一层递归中传递过来的继承属性转化为R的综合属性重新往上传递
减法和乘除同理,根据对应的语法推导规则,保证了乘除的递归层数要高于加减,因此会先生成乘除的三地址码,此时会满足对应的优先级关系
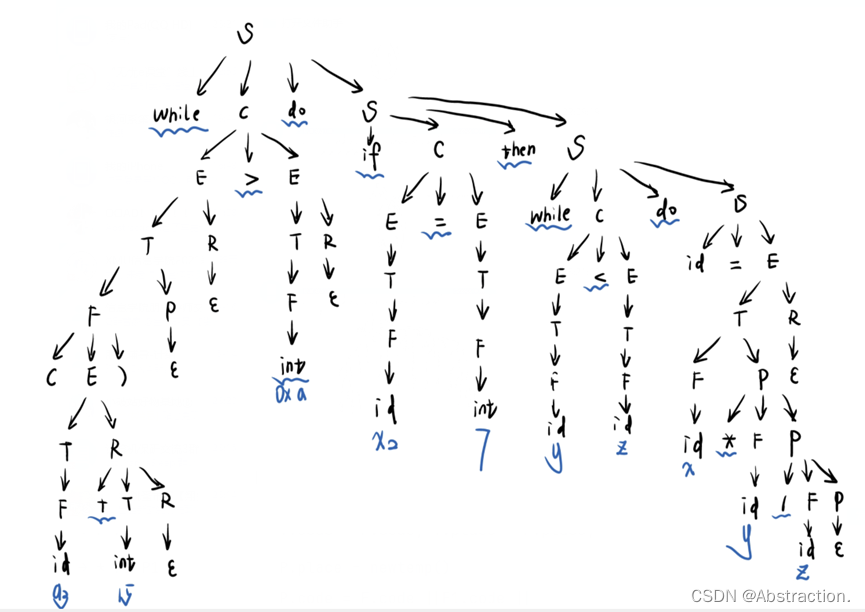
2、编制并化简语法图
测试数据对应的语法树如下图所示
3、编制递归子程序的算法
考虑语法解析的伪代码如下所示
function match(target)
if look_ahead == target
look_ahead = get_next_token()
else
error
function parse_S()
if look_ahead == "if"
match("if")
parse_C()
match("then")
parse_S()
if look_ahead == "else"
parse_S()
match(";")
else if look_ahead == "id"
match("id")
match("=")
parse_E()
match(";")
else if look_ahead == "while"
match("while")
parse_C()
match("do")
parse_S()
match(";")
else
error()
function parse_C()
parse_E()
if look_ahead == ">"
match(">")
else if look_ahead == "<"
match("<")
else if look_ahead == "="
match("=")
else
error()
parse_E()
function parse_E()
parse_T()
parse_R()
function parse_T()
parse_F()
parse_P()
function parse_P()
if look_ahead == "*"
match("*")
else if look_ahead == "/"
match("/")
else
return
parse_F()
parse_P()
function parse_R()
if look_ahead == "+"
match("+")
else if look_ahead == "-"
match("-")
else
return
parse_T()
parse_R()
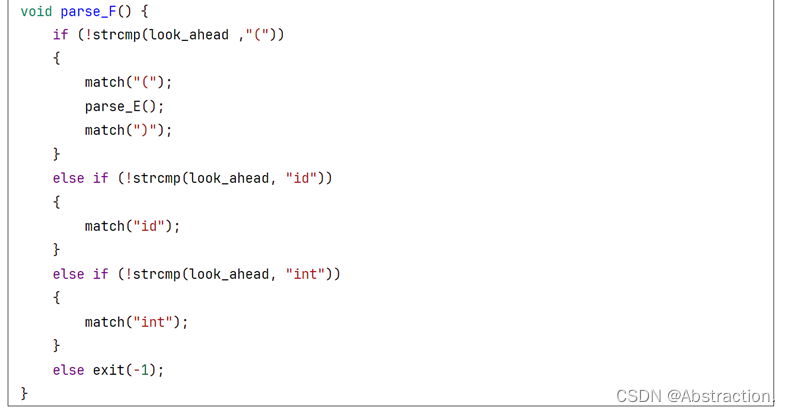
function parse_F()
if look_ahead == "("
match("(")
parse_E()
match(")")
else if look_ahead == "id"
match("id")
else if look_ahead == "int"
match("int")
else
error()
4、编制各个递归子程序函数
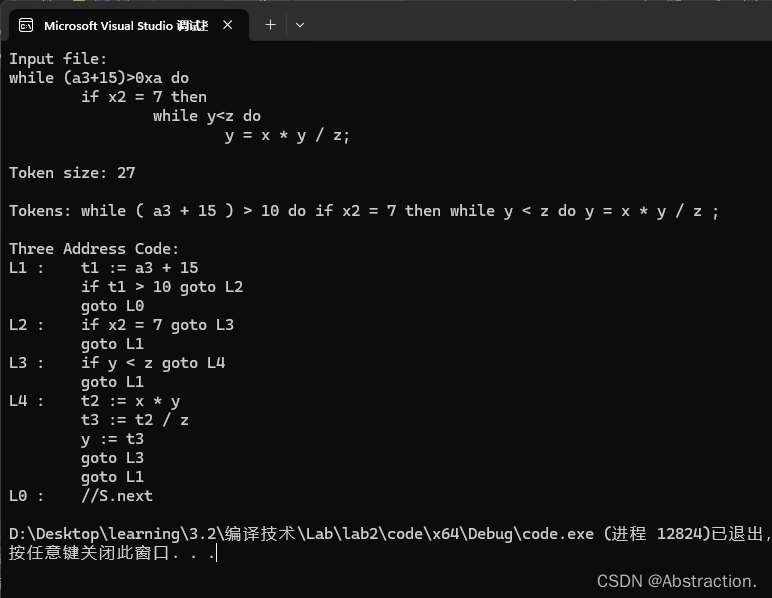
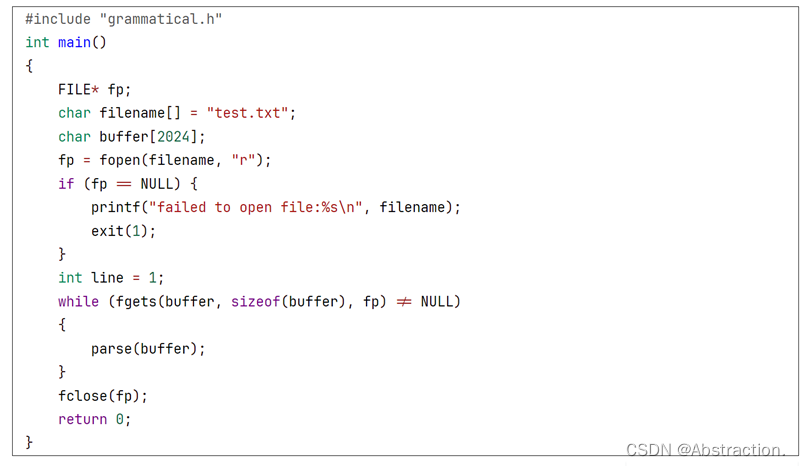
接下来逐步实现题目所要求的三地址生成程序,首先从编写一个LL(1)文法推导的递归下降子程序用于语法分析开始,在语法分析中输入是由词法分析得到的token序列串,为了更好的和实验一进行连接,这里约定在代码中出现的非十进制常量转换为十进制直接放在词法分析阶段进行,因为实验一在打印输出的时候已经实现了进制的转换,首先给出一个测试数据如下,这里暂时规定每一个token之间用一个空格分割(按照文法后面的确应该有四个分号):

词法分析部分的入口为parse函数,其中s是一个该文件下的全局变量,在该部分环节就表示当前的token序列串,parse函数首先实现外界传入参数的拷贝,之后获取下一个token,最后即可开始产生式的推导

该部分环节的match和lookahead实现如下,在之后第4步开始将会定义新的数据结构token进行表示词法分析的结果,因此后续代码会进行修改,该文件中look_ahead也是全局变量,后续将在产生式中用于推导,因为在本环节中规定了token间用空格匹配,因此可以直接进行划分,在连接词法分析程序后词法分析会处理有无空格分割的问题,使得最终该部分的输入变为一个token数组 
match会对当前token和要求token进行匹配,如果不匹配说明语法上存在问题,可以直接进行后续的报错,如果匹配说明该token正确,继续向前匹配

根据第3步,可以直接得到非终结符对应的递归函数


最后对该部分进行单元测试,编写测试函数,运行后程序没有死循环并且没有出现报错可以暂时认为语法分析部分代码正确
5、连接实验一的词法分析函数scan( ),进行测试
接下来修改下实验一部分的代码,在实验一的时候当scan( )完成一个token识别的时候会进行输出,为了连接实验二部分代码,要将其修改成将结果保存在内存中,先定义token对应的数据结构

token_seq是词法分析之后得到的结果,其中包含整个序列的长度token_size和一整个token序列seq,而每一个token是由对应的类型和数据组成,这里数据都采用字符串进行存储
在scan中新建一个token数组,每次词法分析自动机到达终态的时候便会往该数组中新增一个识别出来的token
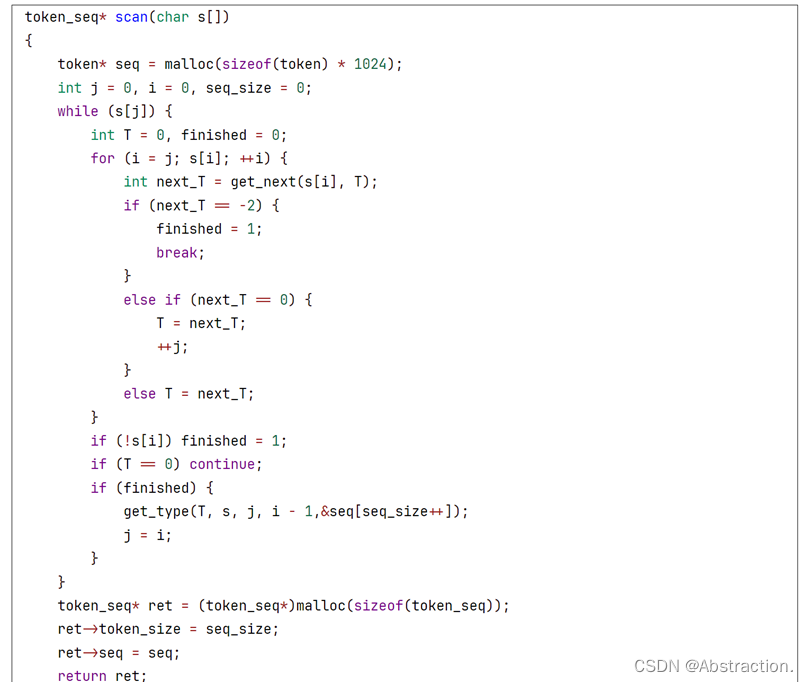
在到达终态之后应该根据当前的自动机状态识别出对应单词的属性,再往token序列中添加新识别出来的token,这里还需要进行进制转换和保留字的识别,其余细节详见源代码,这里仅粘贴部分代码



最后修改一下语法分析的get_next_token和match函数,这里重新定义了对token比较过程,在上一环节中是简单使用字符串比较,但是这里需要根据对应的类型进行详细判断,如果是key和split不仅需要保证类型正确,还需要进一步比较data部分是否相同,而对于int、float和id只要保证类型正确即可
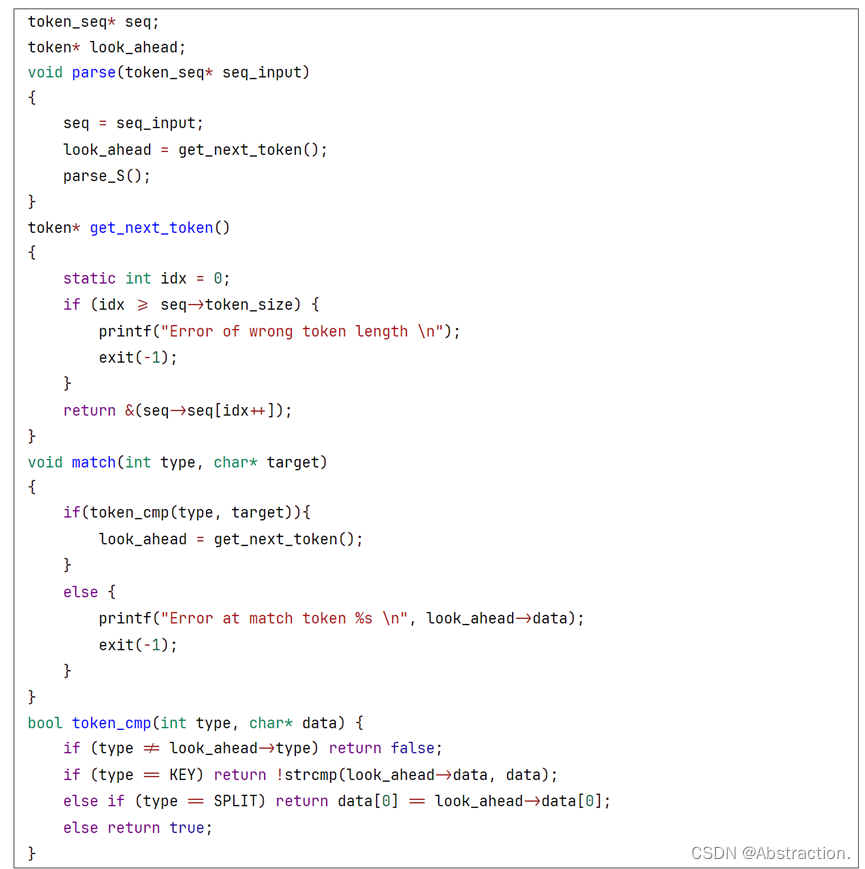
非终结匹配lookahead的时候也要修改成新的token比较函数

最后修改下测试函数,这里稍微做了些修改,先一口气完成词法分析再进行语法分析,对于有换行缩进的情况也同样适用了
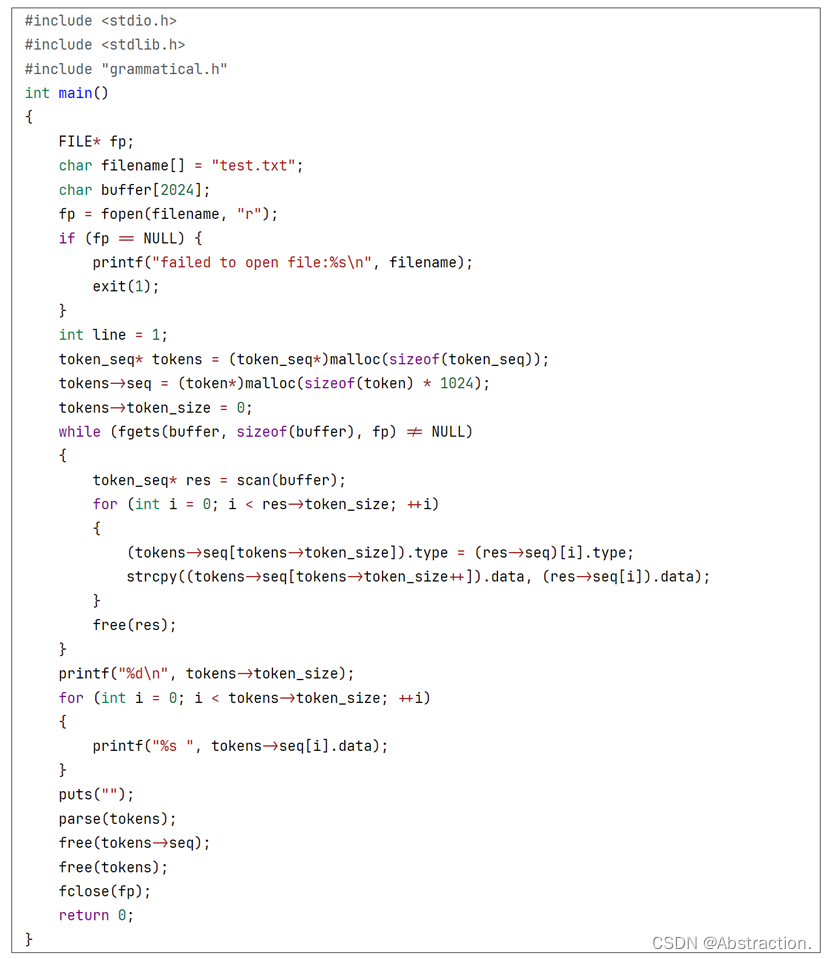
测试数据如下:

运行后没有死循环和报错,暂时可以认为该部分正确
6、设计三地址代码生成的数据结构和算法
接下来开始进行语义分析和三地址码生成,这里一开始使用纯C语言开发发现有些过于繁杂,因此为了方便重构成了C++代码,原来到语法分析部分的C语言可执行代码放在了GitHub中
先设计下三地址码生成的数据结构,根据属性文法的要求,S具有继承属性begin、next,C具有继承属性true和false,T和F具有继承属性place和code,其余非终结符的属性都为综合属性

在算法方面依旧沿用之前的递归下降子程序,在语法分析的同时进行语义分析生成三地址码
7、将各个递归子程序函数改写为代码生成函数
之后根据属性文法依次修改递归下降子程序,因为S.next是继承属性,因此在最开始进行解析之前应该先获取一个标号,之后将这个S作为入参进行推导

文法S -> if C then S1 else S2的解析如下,这 里稍微做了点调整,去掉了if和while语句后面的分号,只要删除对应的match即可,这样符合原来测试数据,避免出现尾部一堆分号


对比属性文法可以知道C的属性是继承属性,因此在解析C之前需要先得由S提供这些继承属性,同理S1.next也是,之后可以在该节点生成一条三地址语句,并且将其余的综合属性赋值给S.code
gen( )如下所示,其目的就是在三地址码生成时添加合适的换行,对于标号后面不用添加,而一个三地址码语句结束应该添加换行,这边code也就是三地址码是继承属性,会在递归的时候逐渐向上传播,最后解析完S后输出即可得到三地址码,无需在中间解析的时候输出

对于if-then语句和上面基本相似,但是这里有一个问题,就是C的false属性是继承属性,在解析C之前应该已经给出,但是可以发现对于if-then和if-then-else语句这个属性的值并不相同,而要知道是哪一个语句必须要在C解析完之后匹配else才能发现,这就出现问题了,此处采用回填的方式解决,根据所给文法的可以发现C.false属性只会在C.code中体现,不会在解析C的时候继续往下传递,因此在C解析完成后回来的C.code中必然只有一个C.false对应的字符子串,所以可以使用回填的方法,先给一个特殊值,之后在匹配else之后重新找回c.code中的这个特殊值,将其替换成正确的属性值


对于产生式S → id = E;的解析过程如下所示,这里需要一个临时变量保存下id的字面值,不然匹配后look_ahead就会往前移动,不方便找回对应的id,之后根据属性文法生成三地址码即可


再给出S → while C do S1的程序,这里根据属性文法进行翻译,但是会出现一种特殊的情况需要单独处理,即当while语句直接在if then语句中嵌套的时候会出现标号共用的情况,因为while会在第一个三地址码处生成标号,而if会在生成的三地址码第三个语句处生成一个标号,两者刚好是同一个位置,会出现共用,解决的方法是利用S.begin是继承属性这个特点,如果出现上述情况在解析if的时候给该属性对应的标号,在解析while发现这个标号非空就不用重新获取


非终结符C的解析如下所示,直接根据属性文法进行编写即可

非终结符E的程序如下所示,根据前面分析,这里T有继承属性要传给解析R的递归,因此将T作为参数传递到递归R的函数中


在R的递归函数中先进行运算符匹配,确定是加法还是减法或者是空串,如果是加法或者是减法根据属性文法先生成三地址码保证左结合性,再将R作为继承属性传递下去用于解析R1;如果是空串则到达递归的终点,将传下来的继承属性转换为综合属性往回传递即可


剩余乘除的推导和加减同理,不再赘述,具体可以查看源代码,最后递归F根据属性文法直接进行即可

几个工具函数在CPP重构后如下所示,使用C11的拷贝构造可略微提高效率

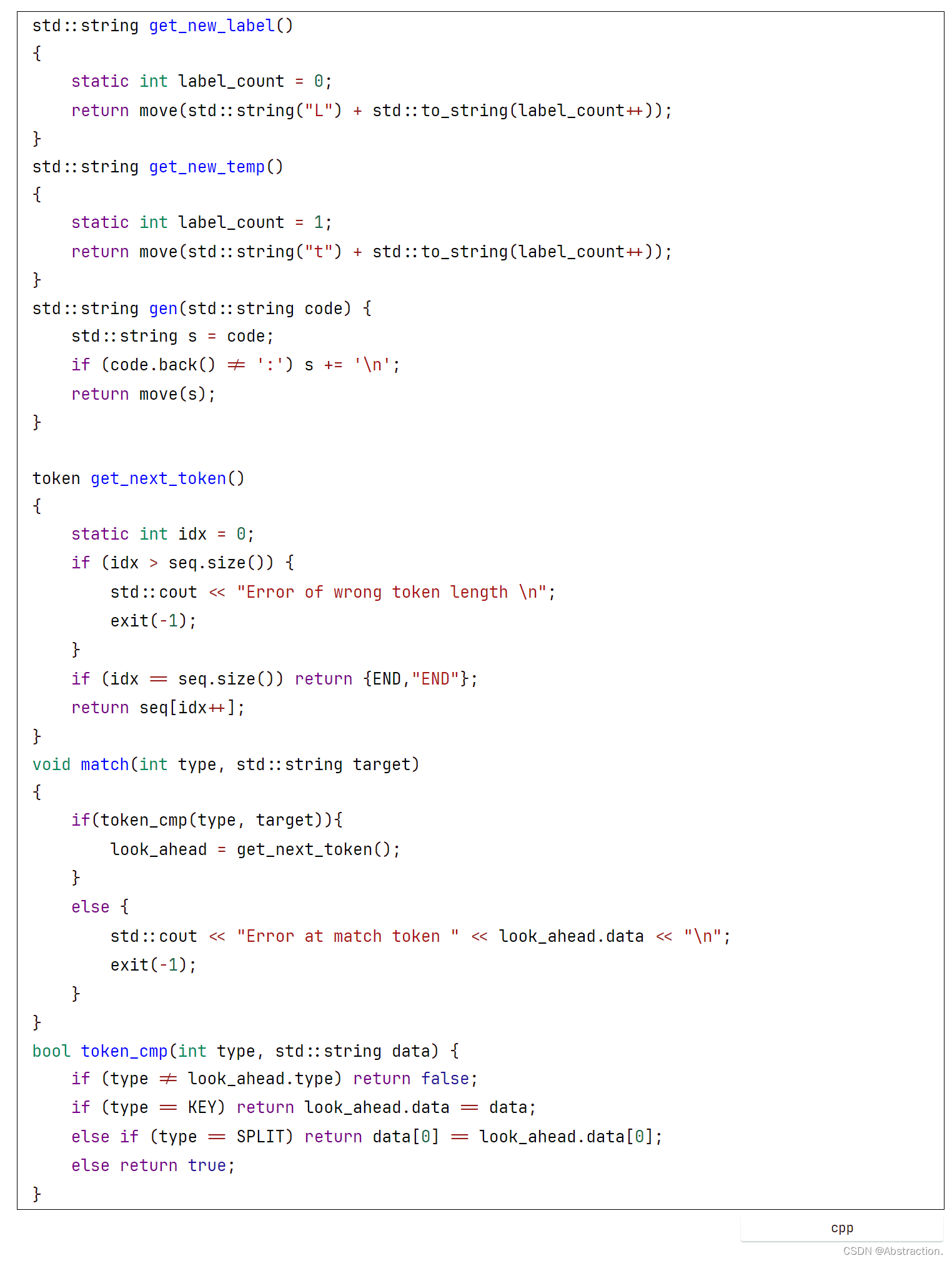
parse函数最后递归完当前的开始符号S后会再去进行匹配“;”,之后如果序列没有推导完会再次进入循环继续推导直到全部完成,从而支持多个语句

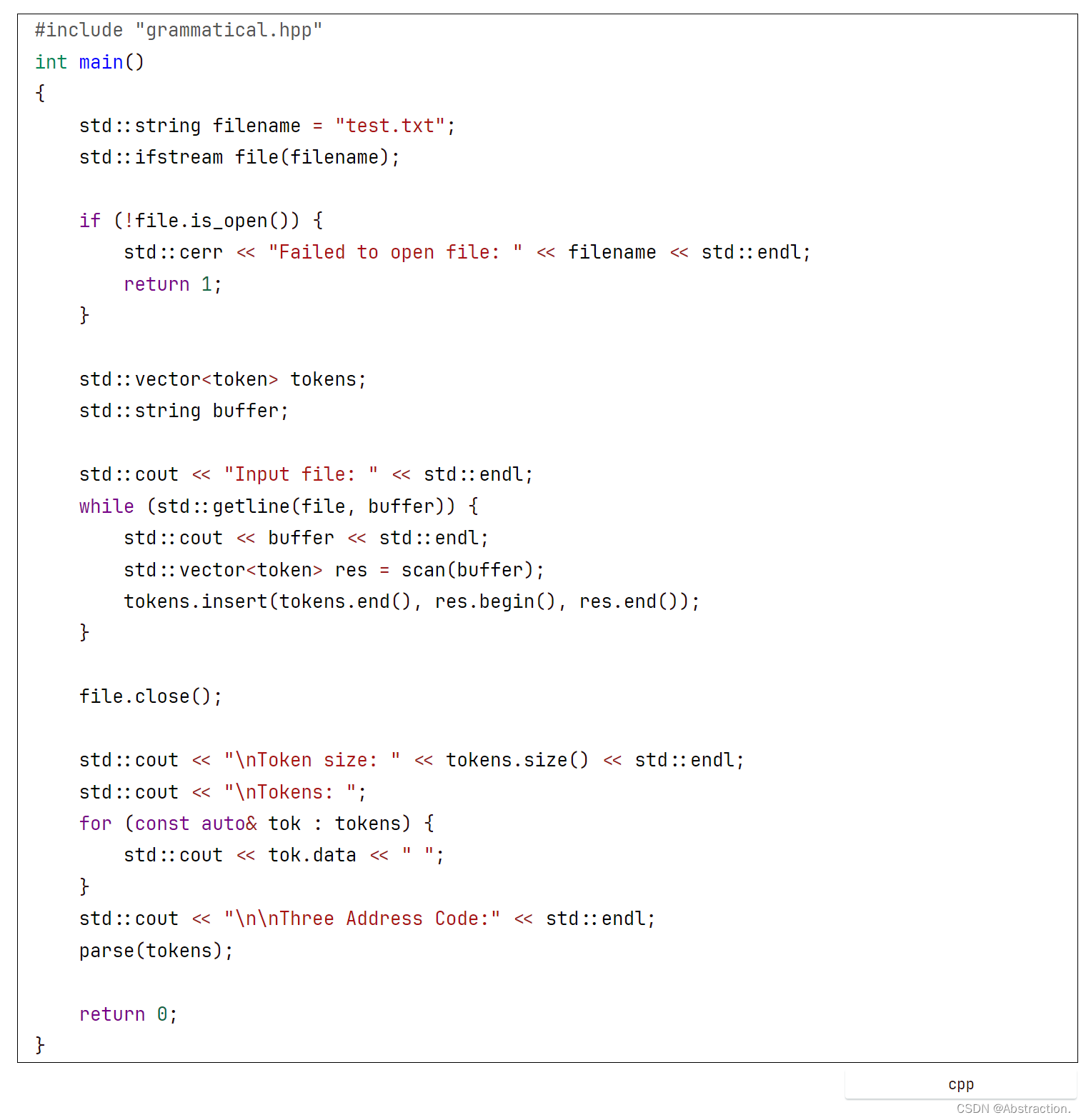
8、编制测试程序(main函数)
main函数与之前的相同,这里为了统一也使用C++的写法进行了重构,也是先对全文进行词法分析生成token序列,之后再进行语法分析和三地址码生成
9、调试程序:输入一个语句,检查输出的三地址代码
六、基本测试数据
输入数据示例:
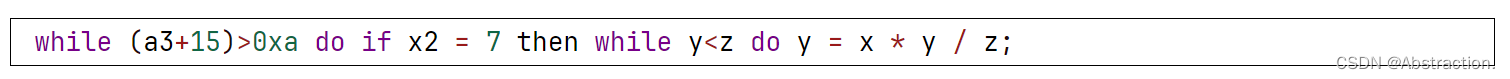 正确结果:等效的三地址代码序列
正确结果:等效的三地址代码序列

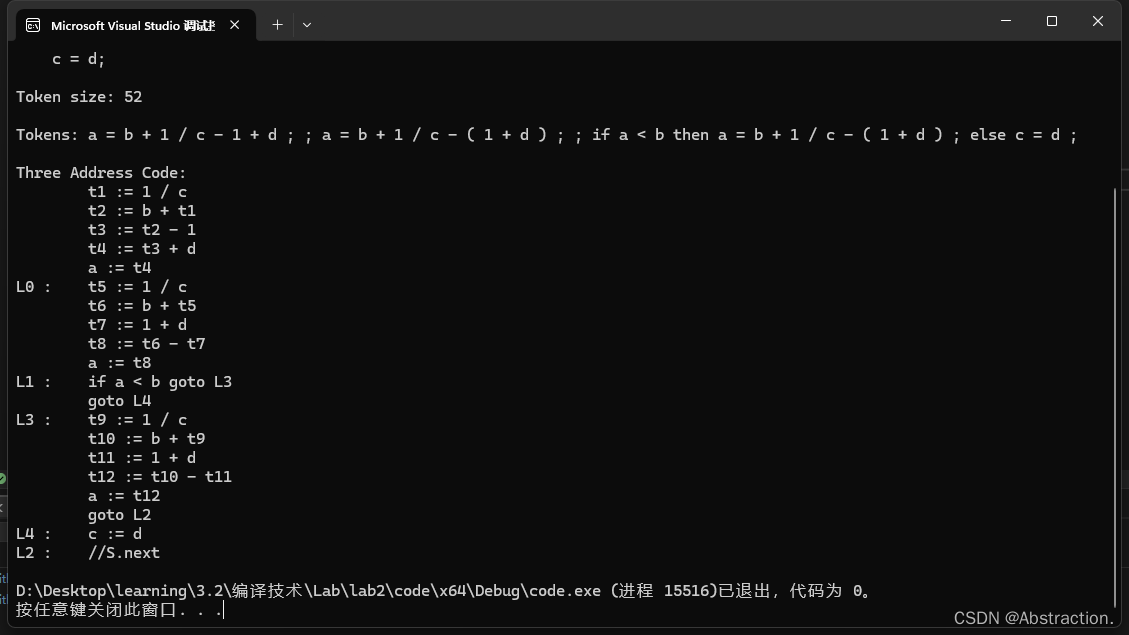
运行后如下,结果正确:
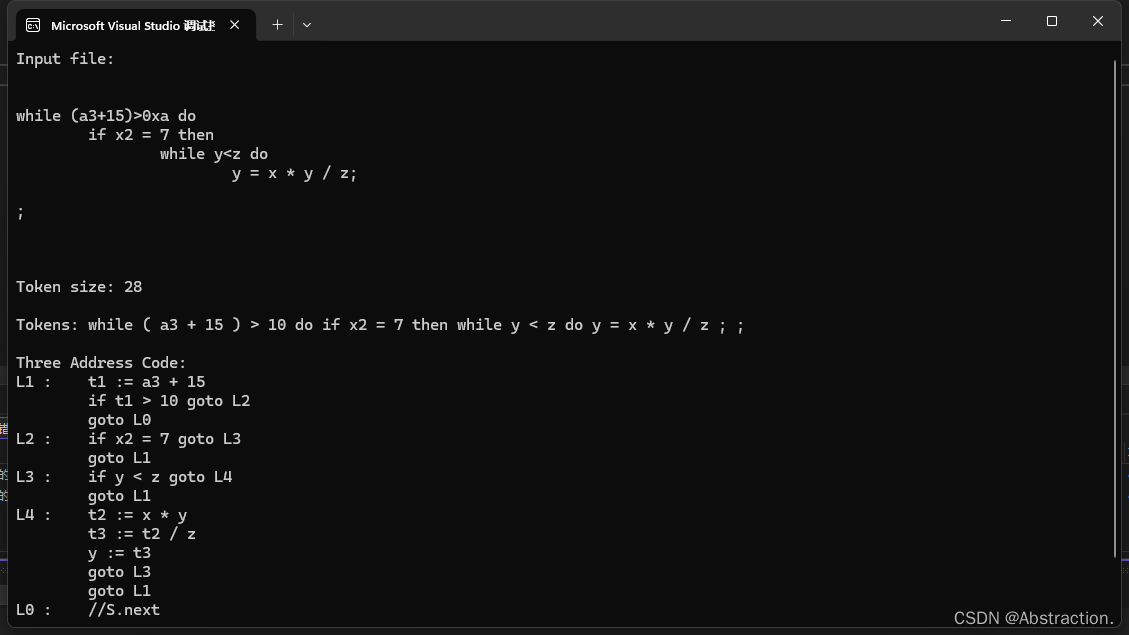
另外再附加了几组新的测试数据测试下四则运算和其余语句的正确性,可以发现添加括号前后的优先级是正确的

七、思考题
1. 生成的三地址代码可否直接输出(不采用数据结构来实现属性code)?
不可以直接输出,因为不采用数据结构实现code属性会导致无法确定标号对应的三地址码语句究竟是哪一句,不过可以先生成完三地址码,在生成标号的时候记录对应的三地址码语句序号,之后重新扫一遍生成的三地址码来确定标号对应的三地址码
2. 如何保证四则运算的优先关系和左结合性?
优先级:通过改造文法,引入中间变量T来确保乘除的递归深度更大,从而先递归掉乘法和除法再递归加法和减法,保证优先级正确
左结合性:根据之前分析,在解析完T1后先生成R节点对应的三地址码再继续递归R1,保证先生成R的三地址码,这个时候便可满足左结合性

3. 如何采用代码段相对地址代替三地址代码序列中的标号?
可以重新扫描一遍生成的三地址码,从而确定每一个标号对应的相对地址,之后进行替换即可
八、完整代码
//lexical.hpp
#pragma once
#include <stdio.h>
#include <string>
#include <stdlib.h>
#include <vector>
#include <stdbool.h>
#include <ctype.h>
#include <string.h>
extern enum {
INT, FLOAT, IDN, KEY, SPLIT, END
};
typedef struct {
int type;
std::string data;
}token;
bool is_split(char );
int get_next(char , int );//return -1 means error,return -2 means terminal
token ret_str(const std::string&, int, int);
token ret_int(const std::string&, int, int, int);
token ret_float(const std::string&, int, int, int);
token ret_split(const std::string&, int);
token get_type(int, const std::string&, int, int);
std::vector<token> scan(const std::string);//lexical.cpp
#include "lexical.hpp"
#include <stdexcept>
std::string split = "\\+-*/><=();";
std::vector<std::string> keywords= {
"if",
"then",
"else",
"while",
"do"
};
bool is_split(char c)
{
for (int i = 0; i < split.size(); ++i)
{
if (split[i] == c) return true;
}
return false;
}
int get_next(char c, int T)//return -1 means error,return -2 means terminal
{
switch (T)
{
case 0:
if (c == '0') return 3;
else if (isdigit(c) && c != '0') return 4;
else if (isupper(c) || islower(c)) return 1;
else if (is_split(c)) return 15;
else if (c == '\n' || c == ' ' || c == '\t') return 0;
break;
case 1:
if (isdigit(c) || isupper(c) || islower(c)) return 1;
else if (c == '.' || c == '_') return 2;
else return -2;
break;
case 2:
if (isdigit(c) || isupper(c) || islower(c)) return 2;
else return -2;
break;
case 3:
if (c == 'o' || c == 'O') return 7;
else if (c == 'x' || c == 'X') return 11;
else if (c == '.') return 5;
else return -2;
break;
case 4:
if (isdigit(c)) return 4;
else if (c == '.') return 5;
else return -2;
break;
case 5:
if (isdigit(c)) return 6; break;
case 6:
if (isdigit(c)) return 6;
else return -2;
break;
case 7:
if (c >= '0' && c <= '7') return 8;
break;
case 8:
if (c == '.') return 9;
else if (c >= '0' && c <= '7') return 8;
else return -2;
break;
case 9:
if (c >= '0' && c <= '7') return 10; break;
case 10:
if (c >= '0' && c <= '7') return 10;
else return -2; break;
case 11:
if ((c >= '0' && c <= '9') || (c <= 'f' && c >= 'a')) return 12; break;
case 12:
if (c == '.') return 13;
else if ((c >= '0' && c <= '9') || (c <= 'f' && c >= 'a')) return 12;
else return -2; break;
case 13:
if ((c >= '0' && c <= '9') || (c <= 'f' && c >= 'a')) return 14; break;
case 14:
if ((c >= '0' && c <= '9') || (c <= 'f' && c >= 'a')) return 14;
else return -2;
break;
case 15:
return -2; break;
default:
return -1; break;
}
return -1;
}
token ret_str(const std::string& str, int i, int j)
{
token ret;
std::string sub = str.substr(i, j - i + 1);
int is_keyword = 0;
for (int k = 0; k < keywords.size(); k++) {
if (sub == keywords[k]) {
is_keyword = 1;
break;
}
}
if (is_keyword) {
for (int k = 0; k < sub.size(); ++k) sub[k] = tolower(sub[k]);
ret.type = KEY;
ret.data = sub;
}
else {
ret.type = IDN;
ret.data = sub;
}
return ret;
}
token ret_int(const std::string& s, int i, int j, int p)
{
token ret;
if (p != 10) i += 2;
int x = 0;
for (int k = i; k <= j; ++k) {
x = x * p + s[k] - (isdigit(s[k]) ? '0' : ('a' - 10));
}
ret.type = INT;
ret.data = std::to_string(x);
return ret;
}
token ret_float(const std::string& s, int i, int j, int p)
{
token ret;
ret.type = FLOAT;
std::string sub = s.substr(i, j - i + 1);
int idx = i + 2;
for (; idx <= j; ++idx) {
if (s[idx] == '.') break;
}
double x = 0, y = 0;
for (int k = i + 2; k < idx; ++k) {
x = x * p + s[k] - (isdigit(s[k]) ? '0' : ('a' - 10));
}
for (int k = idx + 1; k <= j; ++k) {
y = y / p + s[k] - (isdigit(s[k]) ? '0' : ('a' - 10));
}
ret.data = std::to_string(x);
return ret;
}
token ret_split(const std::string& s, int idx)
{
token ret;
ret.type = SPLIT;
ret.data = s[idx];
return ret;
}
token get_type(int T, const std::string& s, int i, int j)
{
int base = 10;
switch (T)
{
case 1:
case 2:
return ret_str(s, i, j);
case 3:
case 4:
case 6:
return (T == 6) ? ret_float(s, i, j, base) : ret_int(s, i, j, base);
case 8:
case 10:
base = 8;
return (T == 10) ? ret_float(s, i, j, base) : ret_int(s, i, j, base);
case 12:
case 14:
base = 16;
return (T == 14) ? ret_float(s, i, j, base) : ret_int(s, i, j, base);
case 15:
return ret_split(s, i);
default:
throw std::invalid_argument("Unsupported type");
}
}
std::vector<token> scan(const std::string s)
{
std::vector<token> seq;
int j = 0, i = 0;
while (j < s.size()) {
int T = 0, finished = 0;
for (i = j; i < s.size(); ++i) {
int next_T = get_next(s[i], T);
if (next_T == -2) {
finished = 1;
break;
}
if (next_T == -1) {
printf("\nLexical error in line, column %d:\n", i + 1);
printf("| %s\n", s);
for (int k = 0; k <= i + 1; ++k) putchar(' ');
printf("^\n\n");
exit(0);
}
else if (next_T == 0) {
T = next_T;
++j;
}
else T = next_T;
}
if (i == s.size()) finished = 1;
if (T == 0) continue;
if (finished) {
seq.push_back(get_type(T, s, j, i - 1));
j = i;
}
}
return move(seq);
}
//grammatical.hpp
#pragma once
#include <string>
#include <iomanip>
#include <iostream>
#include "lexical.hpp"
class S{
public :
std::string place, code, begin, next;
};
class C {
public:
std::string _true,_false,code;
};
typedef class {
public:
std::string code, place;
}E, T, F, R, P;
token get_next_token();
void parse(std::vector<token>);
void match(int, std::string);
std::string get_new_label();
std::string gen(std::string);
S parse_S(S);
void error();
bool token_cmp(int,std::string);
C parse_C(C);
E parse_E();
T parse_T();
P parse_P(F f);
R parse_R(T t);
F parse_F();
//grammatical.cpp
#include "grammatical.hpp"
std::vector<token> seq;
token look_ahead;
void parse(std::vector<token> seq_input)
{
std::string res;
seq = seq_input;
look_ahead = get_next_token();
S s;
do
{
s.next = get_new_label();
s = parse_S(s);
res += s.code;
if (look_ahead.type != END)
{
match(SPLIT, ";");
}
res += s.next + " :";
} while (look_ahead.type != END);
res += "\t//S.next";
std::cout << "\n\nThree Address Code:" << std::endl;
std::cout << res;
}
std::string get_new_label()
{
static int label_count = 0;
return move(std::string("L") + std::to_string(label_count++));
}
std::string get_new_temp()
{
static int label_count = 1;
return move(std::string("t") + std::to_string(label_count++));
}
std::string gen(std::string code) {
std::string s = code;
if (code.back() != ':') s += '\n';
return move(s);
}
token get_next_token()
{
static int idx = 0;
if (idx > seq.size()) {
std::cout << "Error of wrong token length \n";
exit(-1);
}
if (idx == seq.size()) return {END,"END"};
return seq[idx++];
}
void match(int type, std::string target)
{
if(token_cmp(type, target)){
look_ahead = get_next_token();
}
else {
std::cout << "Error at match token " << look_ahead.data << "\n";
exit(-1);
}
}
bool token_cmp(int type, std::string data) {
if (type != look_ahead.type) return false;
if (type == KEY) return look_ahead.data == data;
else if (type == SPLIT) return data[0] == look_ahead.data[0];
else return true;
}
S parse_S(S s)
{
if (token_cmp(KEY, "if")) {
match(KEY, "if");
C c ;
c._true = get_new_label();
c._false = "@";//回填
c = parse_C(c);
match(KEY, "then");
S s1;
s1.next = s.next;
s1.begin = c._true; //解决if语句后面直接跟随while语句会出现应该共用标号的情况
s1 = parse_S(s1);
if(token_cmp(KEY, "else")) {
match(KEY, "else");
// S -> if C then S1 else S2
//std::cout << "s -> if C then s1 else s2" << std::endl;
S s2;
s2.next = s.next;
s2 = parse_S(s2);
c._false = get_new_label();
c.code.replace(c.code.find('@'), 1, c._false);
s.code = c.code + gen(c._true + " :") + s1.code + gen("\tgoto " + s.next) + gen(c._false + " :") + s2.code;
}
else {
// S -> if C then S1
//std::cout << "s -> if C then s1" << std::endl;
c._false = s.next;
s1.next = s.next;
c.code.replace(c.code.find('@'), 1, c._false);
s.code = c.code + gen(c._true + " :") + s1.code;
}
}
else if (token_cmp(IDN, "id")) {
std::string id = look_ahead.data;
match(IDN, "id");
match(SPLIT, "=");
E e = parse_E();
match(SPLIT, ";");
s.code = e.code + gen("\t" + id + " := " + e.place);
}
else if (token_cmp(KEY, "while")) {
//S -> while C do S1
//std::cout << "S -> while C do S1 " << std::endl;
bool s_begin_empty = s.begin == "";
if(s_begin_empty) s.begin = get_new_label();
match(KEY, "while");
C c;
c._true = get_new_label();
c._false = s.next;
c = parse_C(c);
match(KEY, "do");
S s1;
s1.next = s.begin;
s1 = parse_S(s1);
s.code = (s_begin_empty ? gen(s.begin + " :") : "") + c.code + gen(c._true + " :") + s1.code + gen("\tgoto " + s.begin);
}
return s;
}
C parse_C(C c)
{
E e1 = parse_E();
if (token_cmp(SPLIT, ">")) {
//std::cout << "C -> E1 > E2" << std::endl;
match(SPLIT, ">");
E e2 = parse_E();
c.code = e1.code + e2.code + gen("\tif " + e1.place + " > " + e2.place + " goto " + c._true) + gen("\tgoto " + c._false);
}
else if (token_cmp(SPLIT, "<")) {
//std::cout << "C -> E1 < E2" << std::endl;
match(SPLIT, "<");
E e2 = parse_E();
c.code = e1.code + e2.code + gen("\tif " + e1.place + " < " + e2.place + " goto " + c._true) + gen("\tgoto " + c._false);
}
else if (token_cmp(SPLIT, "=")) {
//std::cout << "C -> E1 = E2" << std::endl;
match(SPLIT, "=");
E e2 = parse_E();
c.code = e1.code + e2.code + gen("\tif " + e1.place + " = " + e2.place + " goto " + c._true) + gen("\tgoto " + c._false);
}
else {
error();
}
return c;
}
E parse_E()
{
// E -> TR
//std::cout << "E -> TR" << std::endl;
E e;
T t = parse_T();
R r;
r = parse_R(t);
e.code = r.code;
e.place = r.place;
return e;
}
T parse_T()
{
// T -> FP
//std::cout << "T -> FP" << std::endl;
T t;
F f = parse_F();
P p = parse_P(f);
t.code = p.code;
t.place = p.place;
return t;
}
P parse_P(F f)
{
P p;
if (token_cmp(SPLIT, "*")) {
//P -> * FP1
//std::cout << "P -> * FP1" << std::endl;
match(SPLIT, "*");
F f1 = parse_F();
p.place = get_new_temp();
p.code = f.code + f1.code + gen("\t" + p.place + " := " + f.place + " * " + f1.place);
P p1 = parse_P(p);
p.code = p1.code;
p.place = p1.place;
}
else if (token_cmp(SPLIT, "/")) {
//P -> / FP1
//std::cout << "P -> / FP1" << std::endl;
match(SPLIT, "/");
F f1 = parse_F();
p.place = get_new_temp();
p.code = f.code + f1.code + gen("\t" + p.place + " := " + f.place + " / " + f1.place);
P p1 = parse_P(p);
p.code = p1.code;
p.place = p1.place;
}
else {
//std::cout << "P -> ε" << std::endl;
p.code = f.code;
p.place = f.place;
}
return p;
}
R parse_R(T t)
{
R r;
if (token_cmp(SPLIT, "+")) {
//R -> + TR1
//std::cout << "R -> + TR1" << std::endl;
match(SPLIT, "+");
T t1 = parse_T();
r.place = get_new_temp();
r.code = t.code + t1.code + gen("\t" + r.place + " := " + t.place + " + " + t1.place);
R r1 = parse_R(r);
r.code = r1.code;
r.place = r1.place;
}
else if (token_cmp(SPLIT, "-")) {
//R -> - TR1
//std::cout << "R -> - TR1" << std::endl;
match(SPLIT, "-");
T t1 = parse_T();
r.place = get_new_temp();
r.code = t.code + t1.code + gen("\t" + r.place + " := " + t.place + " - " + t1.place);
R r1 = parse_R(r);
r.code = r1.code;
r.place = r1.place;
}
else {
//std::cout << "R -> ε" << std::endl;
r.code = t.code;
r.place = t.place;
}
return r;
}
F parse_F() {
F f;
if ((token_cmp(SPLIT, "(")))
{
// F -> (E)
//std::cout << "F -> (E)" << std::endl;
match(SPLIT, "(");
E e = parse_E();
f.place = e.place;
f.code = e.code;
match(SPLIT, ")");
}
else if ((token_cmp(IDN, "id")))
{
// F -> id
//std::cout << "F -> id" << std::endl;
std::string id = look_ahead.data;
match(IDN, "id");
f.place = id;
f.code = "";
}
else if (token_cmp(INT, "int"))
{
std::string data = look_ahead.data;
//F -> int
//std::cout << "F -> int" << std::endl;
match(INT, "int");
f.place = data;
f.code = "";
}
else {
error();
}
return f;
}
void error()
{
std::cout << "Error at parse, the next token is " << look_ahead.data << std::endl;
exit(-1);
}
//main.cpp
#include <iostream>
#include <fstream>
#include "grammatical.hpp"
int main()
{
std::string filename = "test.txt";
std::ifstream file(filename);
if (!file.is_open()) {
std::cerr << "Failed to open file: " << filename << std::endl;
return 1;
}
std::vector<token> tokens;
std::string buffer;
std::cout << "Input file: " << std::endl;
while (std::getline(file, buffer)) {
std::cout << buffer << std::endl;
std::vector<token> res = scan(buffer);
tokens.insert(tokens.end(), res.begin(), res.end());
}
file.close();
std::cout << "\nToken size: " << tokens.size() << std::endl;
std::cout << "\nTokens: ";
for (const auto& tok : tokens) {
std::cout << tok.data << " ";
}
std::cout << std::endl;
parse(tokens);
return 0;
}
















 5676
5676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









